







学习原文在此,但是讲解RNN入门最好的三篇文章在知乎:一、一文搞懂RNN(循环神经网络)基础篇;二、循环神经网络(RNN)为什么能够记忆历史信息;三、浅析循环神经网络RNN的两种应用。
这篇也可以参考:如何深度理解RNN?——看图就好!
全连接神经网络和卷积神经网络,他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理 序列 的信息,即前面的输入和后面的输入是有关系的。
由此引出:循环神经网络(Recurrent Neural Network)。RNN
语言模型就是这样的东西:给定一个一句话前面的部分,预测接下来最有可能的一个词是什么。
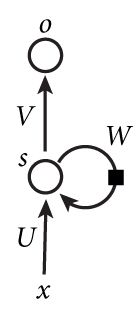
x是一个向量,它表示输入层的值;s是一个向量,它表示隐藏层的值;U是输入层到隐藏层的权重矩阵。o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
展开图如下:
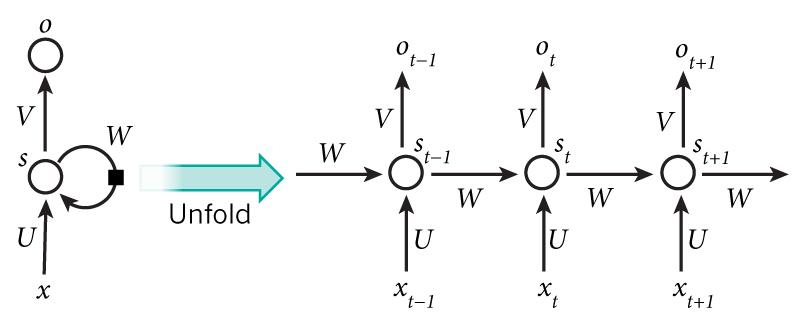
用公式表示循环神经网络的计算方法:
式一
式二
式一:输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。
式二:隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值作为这一次的输入的权重矩阵,f也是激活函数。
循环层和全连接层的区别就是循环层多了一个权重矩阵 W。
将式二反复带入式一:得到

从展开式可知:循环神经网络的输出值是受前面历次输入值
影响的,这也是为何循环神经网络可以往前看任意多个输入值的原因。
总结小文:
Input layer 输入x是一个向量,Hidden Layer也是一个向量。权重是向量之间变换的矩阵。
双向循环网络

深度循环神经网络
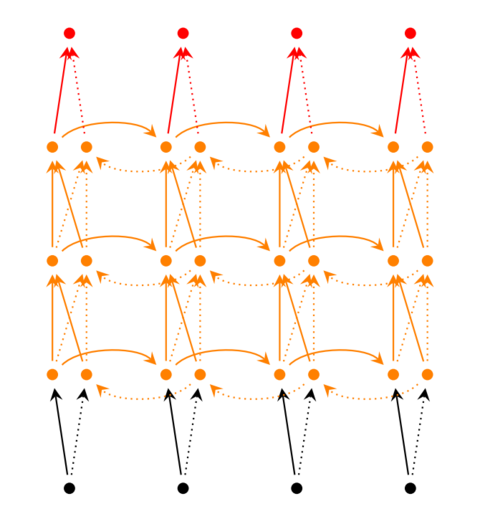

循环神经网络的训练算法:BPTT(back-propagation through time)
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项值,它是误差函数E对神经元j的加权输入Netj的偏导数;
- 计算每个权重的梯度;
- 用随机梯度下降算法更新权重。
1、前向计算:
使用前面的式2对循环层进行前向计算:。将公式展开成矩阵的样子:

2、误差项计算

3、权重梯度的计算:
计算误差函数E对权重矩阵W的梯度。
RNN的梯度爆炸和消失问题
梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会受到NaN错误。我们也可以设定一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
-
1:合理的初始化权重值,初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
-
2:使用relu代替sigmoid和tanh作为激活函数。
-
3:使用其他结构的RNNs,比如长短时记忆网络(LSTM)和Gated Recurrent Unit(GRU),这就是最流行的做法。
向量化:
RNN的输入是向量。
向量化过程:
-
建立一个包含所有词的词典,每个词在词典里面有一个唯一的编号。
-
任意一个词都可以用一个N维的one-hot向量来表示。其中,N是词典中包含的词的个数。假设一个词在词典中的编号是i,v是表示这个词的向量,Vj是向量的第j个元素,则:

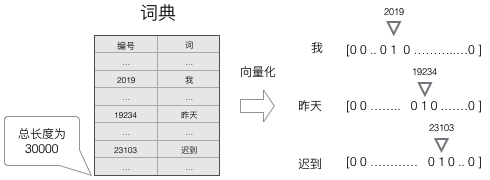
产生的向量是高维、稀疏的向量(稀疏是指绝大部分元素的值都是0)。处理这样的向量会导致我们的RNN神经网络有很多的参数,带来庞大的计算量。因此,往往会需要使用一些降维方法,将高维的稀疏向量转变为低维的稠密向量。
RNN的输出也是向量:
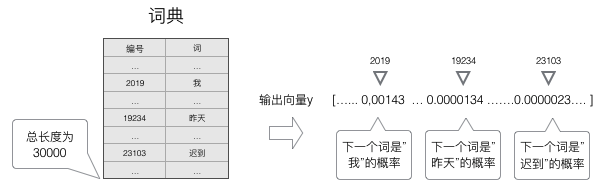
采用softmax作为RNN的输出层。交叉熵误差函数作为优化目标。















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









