







参考来源:《超标量处理器设计》——姚永斌
基础概念
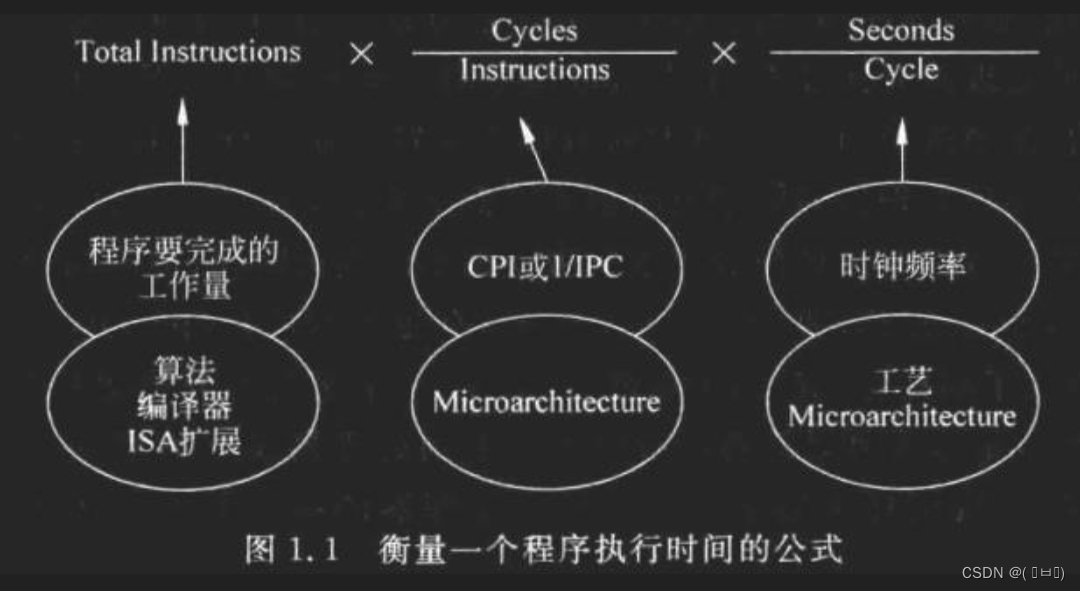
CPI (Cycle Per Instruction)- 每条指令需要的周期数量。
加快处理器速度方法:
- 减少指令数量
- 减少CPI -每个周期执行更多指令
- 减少单个周期时间-超频
其中CPI和时钟频率相互约束。
超标量处理器
拥有以下优势:
- 可以通过硬件或者软件配合编译器支持决定哪些指令可以并行执行
- 每个周期可以从Instruction Cache中取出n条指令送到CPU流水线,CPU每个周期也可以执行n条指令(n-way超标量处理器)
- 支持超长指令字(Very Long Instruction Word, VLIW)
流水线
理想情况下,流水线具有以下特征:
- 每个阶段所需要的时间近似
- 每个阶段操作重复执行(实际存在依赖空档期)
- 各个操作阶段之间相互独立、互不干扰(实际RAW场景是相互依赖的)
不同指令集的流水线实现复杂度也不同:
CISC指令长度以及执行时间不等,实现流水线较为复杂。
RISC指令长度相等,指令执行任务较为规整,比较容易实现流水线。
| 阶段 | 任务 |
|---|---|
| Fetch | 取指令,使用PC寄存器的数值作为地址,从I-Cache取指令并存储在指令寄存器中 |
| Decode & RegFile read | 指令解码,根据结果读取寄存器堆(register file)获取指令源操作数 |
| Execute | 根据指令类型,完成计算任务。例如算数类型进行算数运算,访存类型完成地址计算 |
| Memory | 访问D-Cache,主要面向读load/写store指令,其他指令类型此阶段不执行 |
| Write Back | 若指令存在目的寄存器,将最终结果写到目的寄存器 |
流水线指令相关性
RAW-先写后读
Read指令操作数来自之前指令Write的,此场景下是强依赖关系。
Write: R1 = R2 + R3
Read: R5 = R1 + R4
WAR-先读后写
Write指令需要将结果写到某个寄存器中,但是这个寄存器还在被其他指令Read,无法立即写入。
Read: R1 = R2 + R3
Write: R2 = R5 + R4
这种情况可以后通过修改下一条指令写入位置(不写入R2寄存器)避免依赖。
控制相关性
分支指令引起,只有分支结果确定后,才知道从哪里取得后续指令执行。只能通过预测的方法取指。
存储器相关性
当两个寄存器存储的数值来源的内存地址一样时,会存在隐蔽的相关性。
sw r1, 0(r5) // 将寄存器r1数值保存到MEM[r5]
lw r2, 0(r6) // 将MEM[r6]数值读取到r2寄存器















 1849
1849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









