







1.实例化一个小型的卷积神经网络
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.summary()
神经网络的接受形状为(image_height,image_width,image_channels)
这里输入的形状是(28,28,1)是灰度图像,所以是一通道的,28*28是图片的大小
查看目前的卷积神经网络架构

可以看到每个神经层,不管是Conv2D还是MaxPooling的输出都是形状为(height,width,channels)的3D张量,随之而网络的加深,通道数会越来越大,而高度和宽度越来越小,输出的时候变成了(3,3,64)的形状
下一步是把这个神经网络接一个Dense层堆积起来的密集连接分类器而密集连接的分类器只能处理1D张量,这个时候,需要把3D的张量flatten:
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
#在卷积神经网络中添加分类器
model.add(layers.Flatten())
model.add(layers.Dense(64,activation = 'relu'))
model.add(layers.Dense(10,activation = 'softmax'))
model.summary()
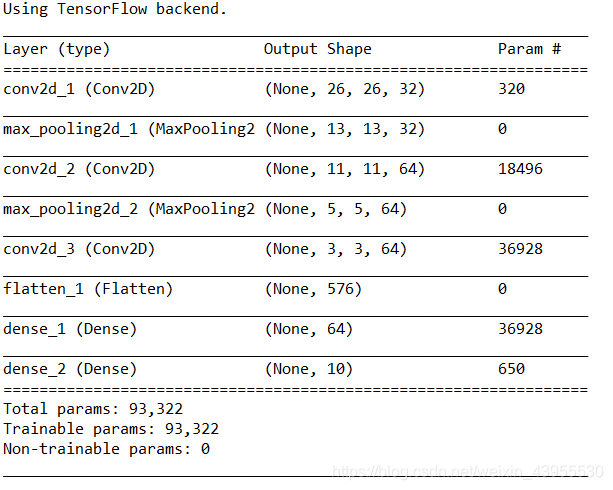
我们可以看到在进入Dense层之间,有一个Flatten的网络输出数据是1D张量,已将(3,3,64)展平为(576,)的向量了
经过两个Dense层最终输出是10个数的向量,表示分别为0-9的概率
最后一层的激活函数用了‘softmax’,使输出的都是概率,并且和为1
各种激活函数
2.用卷积神经网络处理MNIST数字图像分类
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
#在卷积神经网络中添加分类器
model.add(layers.Flatten())
model.add(layers.Dense(64,activation = 'relu'))
model.add(layers.Dense(10,activation = 'softmax'))
#model.summary()
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
train_images = train_images.reshape((60000,28,28,1))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000,28,28,1))
test_images = test_images.astype('float32')/255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer = 'rmsprop',loss = 'categorical_crossentropy',metrics = ['accuracy'])
model.fit(train_images,train_labels,epochs = 5,batch_size = 64)
#测试机上对模型评估
test_loss,test_acc = model.evaluate(test_images,test_labels)
print(test_loss)
print(test_acc)
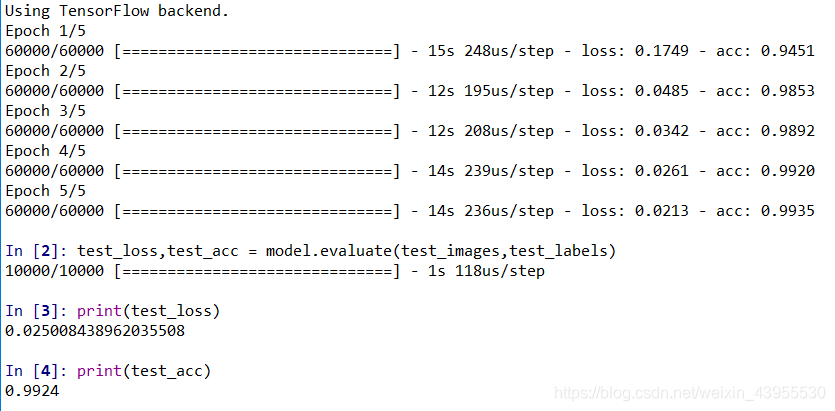
模型精度达到了99.24%,而用密集网络只能达到97.8%,效果非常好
总结该实验步骤:
1.下载数据集
2.将数据集reshape成可以输入神经网络的形状
3.搭建卷积神经网络
4.添加分类器(Dense层充当)
5.编译模型compile
6.训练模型fit
7.评估模型evaluate
分析原因
Dense层从输入特征空间中学到的是全局模式,即涉及所有像素的模式,卷积层Conv层学到的是局部模式,学到的是而二维小窗口(3,3)的大小
3.小型数据集上训练一个卷积神经网络
从kaggle官网https://www.kaggle.com/nafisur/dogs-vs-cats上下载下来数据,解压后:
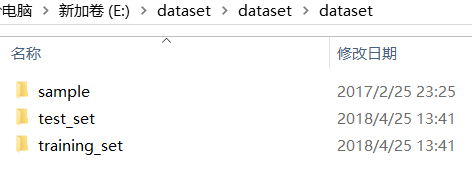
现在的test文件夹中是三个文件夹,而test_set,training_set文件夹里面是猫狗图片的文件夹:

训练集猫狗图像各4000张,测试集猫狗图片各1000张
将图像复制到训练,验证,测试三个目录下
这里我们取猫狗的前1000张照片为训练集,后面的500张为验证集,再后面的500张为测试集:
import os,shutil
#原始下载解压的数据集中猫狗地址的文件夹位置
original_dataset_dir_cats = 'E:/dataset/dataset/dataset/training_set/cats'
original_dataset_dir_dogs = 'E:/dataset/dataset/dataset/training_set/dogs'
#把较小的数据集保存出来叫‘cats_and_dogs_small’的文件夹
base_dir = 'E:/dataset/cats_and_dogs_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir,'train')#在cats_and_dogs_small的文件夹里加一个train的文件夹
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')#在cats_and_dogs_small的文件夹里加一个validation的文件夹
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')#在cats_and_dogs_small的文件夹里加一个test的文件夹
os.mkdir(test_dir)
#在train文件夹里面加cats的文件夹,dogs的文件夹
train_cats_dir = os.path.join(train_dir,'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
#在validation文件夹里面加cats,dogs文件夹
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
#在test文件夹里面加cats,dogs文件夹
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
先把文件夹都造好,这里造一个cats_and_dogs_small的数据集,里面三个文件夹,train,validation,test,三个文件夹里面有cats,dogs两个文件夹装图片

###把前1000张猫的图片复制到train_cats_dir
#将复制后的图片文件更改为cat.0.jpg
fnames_original = ['cat.{}.jpg'.format(i) for i in range(1,1001)]
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fnames_original,fnames in zip(fnames_original,fnames):
src = os.path.join(original_dataset_dir_cats,fnames_original)#选择原来文件里的猫图片
dst = os.path.join(train_cats_dir,fnames)#复制后的文件里的猫图片
shutil.copyfile(src,dst)#原来的猫图片复制到train_cats_dir文件夹里
###把接下来的500张猫图片作为验证集复制到validation_cats_dir
fnames_original = ['cat.{}.jpg'.format(i) for i in range(1001,1501)]
fnames =['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fnames_original,fnames in zip(fnames_original,fnames):
src = os.path.join(original_dataset_dir_cats,fnames_original)
dst = os.path.join(validation_cats_dir,fnames)
shutil.copyfile(src,dst)
###把再接下来的500张猫图片作为验证集复制到test_cats_dir
fnames_original = ['cat.{}.jpg'.format(i) for i in range(1501,2001)]
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fnames_original,fnames in zip(fnames_original,fnames):
src = os.path.join(original_dataset_dir_cats,fnames_original)
dst = os.path.join(test_cats_dir,fnames)
shutil.copyfile(src,dst)
###把前1000张狗的图片复制到train_dogs_dir
#将复制后的图片文件更改为dog.0.jpg
fnames_original = ['dog.{}.jpg'.format(i) for i in range(1,1001)]
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fnames_original,fnames in zip(fnames_original,fnames):
src = os.path.join(original_dataset_dir_dogs,fnames_original)#选择原来文件里的猫图片
dst = os.path.join(train_dogs_dir,fnames)#复制后的文件里的猫图片
shutil.copyfile(src,dst)#原来的猫图片复制到train_cats_dir文件夹里
###把接下来的500张猫图片作为验证集复制到validation_cats_dir
fnames_original = ['dog.{}.jpg'.format(i) for i in range(1001,1501)]
fnames =['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fnames_original,fnames in zip(fnames_original,fnames):
src = os.path.join(original_dataset_dir_dogs,fnames_original)
dst = os.path.join(validation_dogs_dir,fnames)
shutil.copyfile(src,dst)
###把再接下来的500张猫图片作为验证集复制到test_cats_dir
fnames_original = ['dog.{}.jpg'.format(i) for i in range(1501,2001)]
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fnames_original,fnames in zip(fnames_original,fnames):
src = os.path.join(original_dataset_dir_dogs,fnames_original)
dst = os.path.join(test_dogs_dir,fnames)
shutil.copyfile(src,dst)
print('total training cat images:',len(os.listdir(train_cats_dir)))
print('total training dog images:',len(os.listdir(train_dogs_dir)))
print('total test cats images:',len(os.listdir(test_cats_dir)))
print('total test dogs images:',len(os.listdir(test_dogs_dir)))
print('total validation cats images:',len(os.listdir(validation_cats_dir)))
print('total validation dogs images:',len(os.listdir(validation_dogs_dir)))

构建网络
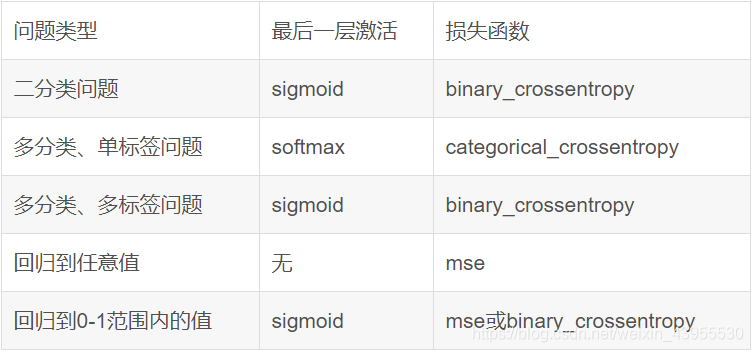
由于这是一个二分类问题,所以网络最后一层用sigmoid激活函数,返回出来是0或1
这里先随意选一个输入尺寸为150150,在flatten之前,将特征图处理到77的大小
###net
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.summary()
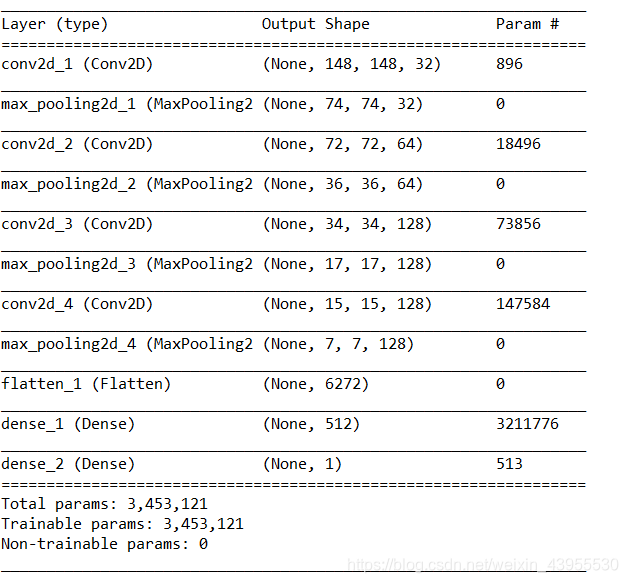
编译过程
###compile
from keras import optimizers
model.compile(loss = 'binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),metrics = ['acc'])
使用RMSprop优化器,因为网络最后一层是sigmoid所以使用交叉熵作为损失函数
输入神经网络之前对图像进行处理
###图像在输入神经网络之前进行数据处理
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_dir = 'E:/dataset/cats_and_dogs_small/train'
train_generator = train_datagen.flow_from_directory(train_dir,target_size = (150,150),batch_size = 20,class_mode = 'binary')
validation_dir = 'E:/dataset/cats_and_dogs_small/validation'
validation_generator = test_datagen.flow_from_directory(validation_dir,target_size = (150,150),batch_size = 20,class_mode = 'binary')
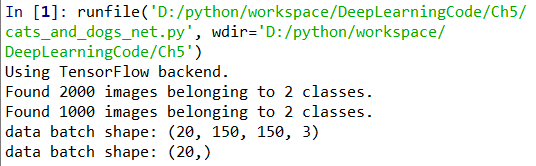
for data_batch,labels_batch in train_generator:
print('data batch shape:',data_batch.shape)
print('data batch shape:',labels_batch.shape)
break #生成器不会停止,会循环生成这些批量,所以我们就循环生成一次批量,打印大小出来看一下就可以了
注意,这个train_dir,validation_dir直接写train的文件地址,validation的文件地址就可以了,keras会自动检测里面有一个文件夹,就是几个类别(class)
用到一个生成器,批量生成(150,150,3)的图片,每20个为一批(batch_size=20),大小全都变成一样的150*150
发现报错了:
ImportError: Could not import PIL.Image. The use of array_to_img requires PIL.
少了pillow这个包,去安装一下,就可以了
训练模型
现在我们利用批量生成器来训练模型
###fit
history = model.fit_generator(train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50)
###save
model.save('cats_and_dogs_small_1.h5')
利用生成器,来训练模型就要用到fit_generator方法,他的第一个参数是一个python生成器,不断生成和输入组成的批量,第二个参数是从生成器中抽取多少个批量拟合,这里训练集里面2000张图,每个批量20张,所以一共需要100个批量才能读取完全部训练集
传入validation_data可以是一个生成器也可以是一个numpy数组组成的元组,这利用生成器,一样要限制读取的批量个数,1000张validation照片20个一批量,需要50个批量
这里要记录每一轮训练的acc,loss,所以用history记录历史记录
过程很漫长。。。
画出训练过程loss和acc的图像
###plot
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc) + 1)
plt.plot(epochs,acc,'bo',label = 'Training acc')
plt.plot(epochs,val_acc,'r',label = 'Validation acc')
plt.title('Training and Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'bo',label = 'Training loss')
plt.plot(epochs,val_loss,'r',label = "Validation loss")
plt.title('Training and Validation loss')
plt.legend()
plt.figure()
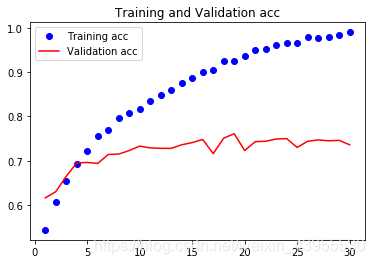
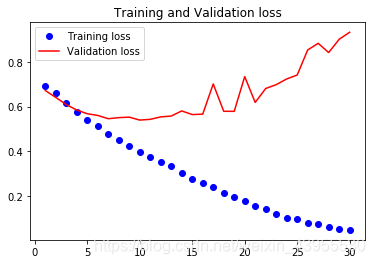
这些图说明模型过拟合了,在epoch = 5的时候就过拟合了,精确度只能达到70%左右,这是因为模型数目太少了,所以应该考虑如何降低过拟合的程度,比如dropout,正则化之类的
试着测试一张图片的预测效果
首先随便选一张照片,并将它缩小到(150,150,3)的形状,只有这样的形状才能往神经网络里面输入
#提取目录下所有图片,更改尺寸后保存到另一目录
import matplotlib.pyplot as plt
from PIL import Image
import os.path
def convertjpg(jpgfile,outdir,width=150,height=150):#将图片缩小到(150,150)的大小
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
except Exception as e:
print(e)
jpgfile = 'E:/dataset/dataset/dataset/test_set/cats/cat.4046.jpg'#读取原图像
convertjpg(jpgfile,"E:/")#图像大小改变到(150,150)
img_scale = plt.imread('E:/cat.4046.jpg')
plt.imshow(img_scale)#确实变到了(150,150)大小
然后加载训练好的模型,将图片输入到神经网络里面
###导入模型
from keras.models import load_model
model = load_model('cats_and_dogs_small_1.h5')
#model.summary()
img_scale = img_scale.reshape(1,150,150,3).astype('float32')
img_scale = img_scale/255 #归一化到0-1之间
result = model.predict(img_scale)
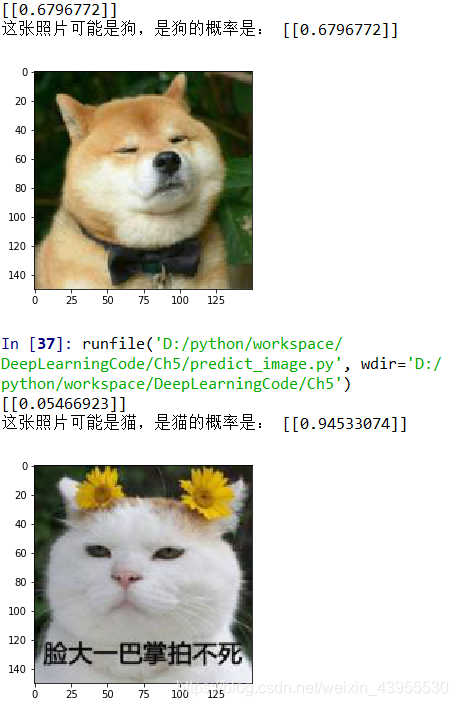
print(result)
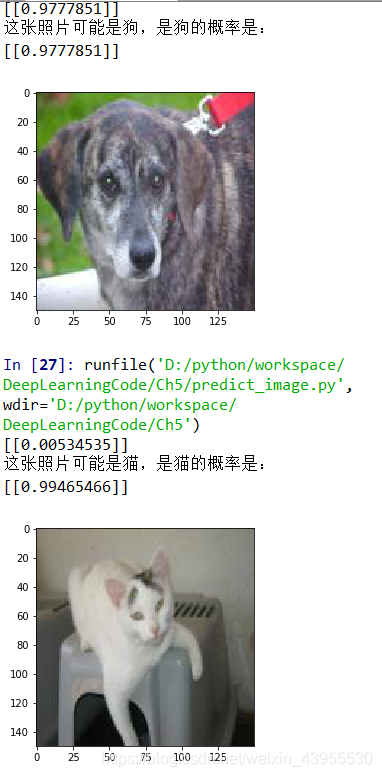
if result>0.5:
print('这张照片可能是狗,是狗的概率是:',result)
else:
print('这张照片可能是猫,是猫的概率是:',1-result)
因为之前训练的是用0-1之间的数进行训练的,所以这里也要对准备测试的图片进行归一化,得到的是一个概率值,是否为狗的概率值,如果这个概率大于0.5,说明更可能是狗,如果小于0.5,说明不太可能是狗,那么更可能是猫
img_scale = img_scale.reshape(1,150,150,3).astype('float32')
这句话非常重要,不写的话会报错:
ValueError: Error when checking input: expected conv2d_1_input to have 4 dimensions, but got array with shape (150, 150, 3),一张照片是一个3D张量,但是输入神经网络的得是4D张量,加了这句之后会发现:

随便测两张测试集里面的图片:
4.数据增强来降低过拟合
过拟合的原因是样本太少,通过对样本图像的随机变化呢,来增加样本个数,使训练的时候不会看到相同的图片,keras里的ImageDataGenerator方法可以实现
from keras.preprocessing import image
import os
import matplotlib.pyplot as plt
train_cats_dir = 'E:/dataset/cats_and_dogs_small/train/cats'
fnames = [os.path.join(train_cats_dir,fname) for fname in os.listdir(train_cats_dir)]
#print(fnames) #所有训练集中1000张猫的文件名
#利用ImageDataGenerator实例读取
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rotation_range = 40, #图像随机旋转角度范围
width_shift_range = 0.2, #图片在水平方向上平移的比例
height_shift_range = 0.2, #图像在垂直方向上平移的比例
shear_range = 0.2,#图像在垂直方向上平移的比例
zoom_range = 0.2, #图像随机缩放的范围
horizontal_flip = True,#随机将一半图像的水平翻转
fill_mode = 'nearest') #填充创建像素的一种办法
#选择一张图片进行图像增强
img_path = fnames[3]
img = image.load_img(img_path,target_size = (150,150))#度读取图像并调整图像大小为(150,150,3)
x = image.img_to_array(img)#将其转化为(150,150,3)的numpy数组
x = x.reshape((1,) + x.shape)#将其形状改变为(1,150,150,3)的形状
i = 0
plt.figure()
for batch in datagen.flow(x,batch_size = 1):
plt.subplot(2,2,i+1)
plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
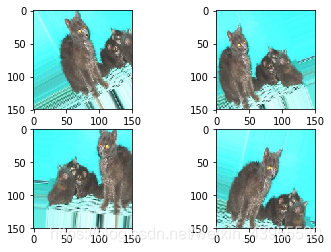
这就是通过随机数据增强生成的猫图片,但是这样网络看到的输入数据仍然是高度相关的,这些输入都来自少量原始图像,这样不足以完全消除过拟合,为了尽可能大的消除过拟合,这里想模型里面添加一个Dropout层,添加到密集连接分类器前
###定义一个包含Dropout的新卷积神经网络
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D(2,2))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))#添加的Dropout层
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
###编译模型
from keras import optimizers
model.compile(loss = 'binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),
metrics = ['acc'])
###训练模型
#图像的预处理
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255, #将图像乘1/255缩放到0-1之间的数
rotation_range = 40, #图像随机旋转角度范围
width_shift_range = 0.2, #图片在水平方向上平移的比例
height_shift_range = 0.2, #图像在垂直方向上平移的比例
shear_range = 0.2, #随机错切变换的角度
zoom_range = 0.2, #图像随机缩放的范围
horizontal_flip = True,) #随机将一半图像的水平翻转
validation_datagen = ImageDataGenerator(rescale = 1./255)##注意!!!验证集是不能数据增强的
#生成批量数据,32个为一批,使用二进制标签(class_mode)
train_dir = 'E:/dataset/cats_and_dogs_small/train'
train_generator = train_datagen.flow_from_directory(train_dir,
target_size = (150,150),
batch_size = 32,
class_mode = 'binary')
validation_dir = 'E:/dataset/cats_and_dogs_small/validation'
validation_generator = validation_datagen.flow_from_directory(validation_dir,
target_size = (150,150),
batch_size = 32,
class_mode = 'binary')
#利用批量生成器拟合模型,一共训练100轮
history = model.fit_generator(train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50)
model.save('cats_and_dogs_small_2.h5')
###画loss和acc在训练集和验证集上的对比图
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc) + 1)
plt.plot(epochs,acc,'bo',label = 'Training acc')
plt.plot(epochs,val_acc,'r',label = 'Validation acc')
plt.title('Training and Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'bo',label = 'Training loss')
plt.plot(epochs,val_loss,'r',label = "Validation loss")
plt.title('Training and Validation loss')
plt.legend()
plt.figure()
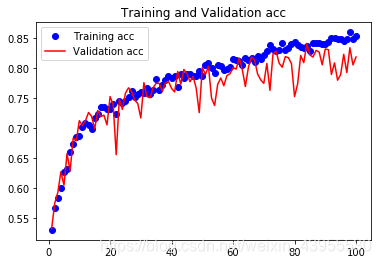
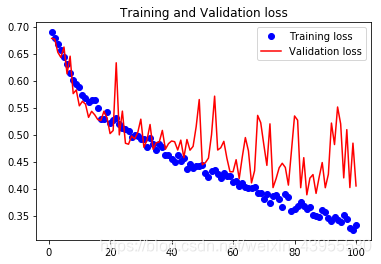

精度可以提高到80%多,精度明显提高了
同样的方法测试几张图片
















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









