







卷积神经网络可视化
深度学习模型很多很难可视化,但卷积神经网络学到的表示非常适合可视化
1.可视化中间激活
可视化中间激活,指对于给定输入,展示网络中各个卷积层,池化层的输出特征图,(输出通常被称为该层的激活,即激活函数的输出)
首先加载之前的‘cats_and_dogs_smal_2.h5’模型
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
model.summary()

#导入模型
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
#model.summary()
#预处理单张图片
img_path = 'E:\\dataset\\cats_and_dogs_small\\test\\cats\\cat.1700.jpg'
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path,target_size = (150,150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor,axis = 0)
img_tensor /=255.
#print(img_tensor.shape)#其形状为(1,150,150,3)
#显示图片
import matplotlib.pyplot as plt
plt.imshow(img_tensor[0])#显示的是一个三维张量(150,150,3),即一张rgb图片
plt.show()

#用一个输入张量和一个输出张量列表将模型实例化
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]]#提取前八层的输出
activation_model = models.Model(inputs = model.input,outputs = layer_outputs)
#Model与Sequential模型不一样,Sequantial模型是n输入对应n输出,Model是一输入也可以n输出
#以预测模式运行模型
activations = activation_model.predict(img_tensor)
#返回八个Numpy数组组成的列表,每个层激活对应一个Numpy数组

first_layer_activation = activations[0]#第一个卷积层
print(first_layer_activation.shape)
(1, 148, 148, 32)
第一层的输出,一个大小为(148,148)的特征图,有32个通道
现在我们将第四个通道可视化:
#将第四个通道可视化
import matplotlib.pyplot as plt
plt.matshow(first_layer_activation[0,:,:,4],cmap = 'viridis')

可视化第七个通道:
#将第七个通道可视化
plt.matshow(first_layer_activation[0,:,:,7],cmap = 'viridis')

每个通道都是一个检测器,对不同的特征进行检测
下面对八层输出的所有通道可视化:
#对八层的输出的所有通道可视化
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name) #对八层的名称进行储存,作为画图的时候使用
images_per_row = 16#一行画16个
for layer_name,layer_activation in zip(layer_names,activations):
n_features = layer_activation.shape[-1]#取shape的最后一个数,即通道数
size = layer_activation.shape[1]#取shape的第二个数,就是图片大小
#layer_activation.shape表示为(n_features,size,size,3)
n_cols = n_features//images_per_row #一行16个看能有多少列
display_grid = np.zeros((size*n_cols,images_per_row*size))
#构造一个大矩阵全为0,再往里铺图,像铺瓷砖一样
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,:,:,col*images_per_row + row]
#选中第col行row列的图片,就是当前通道的输出
#对特征进行后处理,使其看上去美观
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image,0,255).astype('uint8')
#显示网格
display_grid[col*size:(col + 1)*size,row*size:(row + 1)*size] =channel_image
scale = 1./size
plt.figure(figsize = (scale * display_grid.shape[1],scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid,aspect = 'auto',cmap = 'viridis')








可以得到深度神经网络的重要特征,随着层数增加,层所提取的特征越来越抽象,更高层的激活包括对特定输入的信息越来越少,关于目标的信息越来越多(猫或狗的类别)
2.可视化卷积神经网络过滤器
3.可视化类激活的热力图
类激活图: 类激活图(CAM,class activation map)是与特定输出类别相关的二维分数网格,对于输入图像的每个位置进行计算,它表示每个位置对该类别的重要程度。
类激活图可视化:
类激活图可视化有助于了解一张图像的哪一部分让卷积神经网络做出了最终的分类决策。这有助于对卷积神经网络的决策过程进行调试,特别是分类错误的情况下。
同时,这种方法可以定位图像中的特定目标。
具体实现方法是:给定一张输入图像,对于一个卷积层的输出特征图,用类别相对于每一个通道的梯度对这个特征图中的每个通道进行加权。
###加载带有预训练权重的VGG16网络
from keras.applications.vgg16 import VGG16
model = VGG16(weights = 'imagenet')
###为VGG16模型预处理输入图像
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input,decode_predictions
import numpy as np
import matplotlib.pyplot as plt
img_path = 'E:/elephant.jpg'#图像存储路径
img = image.load_img(img_path,target_size = (224,224))#将图像大小调整为(224,224)
plt.imshow(img)
x = image.img_to_array(img)#将图片变成(224,224,3)的numpy数组
x = np.expand_dims(x,axis = 0)#添加一个维度,axis表示添加的维度的位置,这里是指在第一个位置加一个维度
#print(x.ndim)#添加维度后的维度,得到的是(1,224,224,3)形状的批量,一个批量包含一张图片
x = preprocess_input(x)
preds = model.predict(x)
print('这张图片可能是:',decode_predictions(preds,top = 1)[0][0][1])
print('可能性为:',decode_predictions(preds,top = 1)[0][0][2])
print('索引为:',np.argmax(preds[0]))


这里用的VGG16模型与前面特征提取时的VGG16模型不一样:
.keras\models文件夹下重新下载了一个模型:
vgg16_weights_tf_dim_ordering_tf_kernels.h5大概有500多M
元组的索引参考

top = 1,说明这里只看了可能性最大的一个分类
为了知道图像中哪部分信息是的最终识别出来非洲象,我们使用Grad-CAM算法
在这里插入代码片
**K.gradients(y,x)**用于求y关于x 的导数(梯度),(y和x可以是张量tensor也可以是张量列表,形如 [tensor1, tensor2, …, tensorn]),返回的是一个张量列表,列表长度是张量列表y的长度,列表元素是与x具有一样shape的张量。
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]
african_elephant_output是(1,)张量,last_conv_layer.output是(1,7,7,512)张量,所以返回的是只有一个元素的(1,7,7,512)张量列表,grads取了列表中唯一一个元素。
###Grad-CAM算法,看哪些部分看起来最像非洲象
african_elephant_output = model.output[:,386]#预测向量中的‘非洲象’元素
last_conv_layer = model.get_layer('block5_conv3')#这是VGG16的最后一层
#'非洲象'类别相对于block5_conv3输出特征图的梯度,形状为(1,7,7,512)
grads = K.gradients(african_elephant_output,last_conv_layer.output)[0]
pooled_grads = K.mean(grads,axis = (0,1,2))
#得到的是一个形状为(512,)的向量,每个元素的前三个数(索引为0,1,2)的平均梯度大小
interate = K.function([model.input],[pooled_grads,last_conv_layer.output[0]])
pooled_grads_value,conv_layer_output_value = interate([x])
#pooled_grads_value是通道对‘大象’的重要程度
#conv_layer_output_value是特征图数组的512个通道,(14,14,512)
for i in range(512):
conv_layer_output_value[:,:,i] *= pooled_grads_value[i]
#将特征图数组的每个通道乘以“这个通道对‘大象’的重要程度”
heatmap = np.mean(conv_layer_output_value,axis = -1)
#得到的特征图的通道平均值为类激活的热力图(14,14)
###热力图处理
heatmap = np.maximum(heatmap,0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
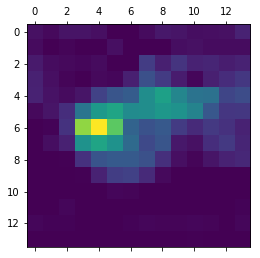
思路就是:
先得到’非洲象’类别相对于block5_conv3输出特征图的梯度,形状为(1,7,7,512)
该梯度前三个数取平均值得到(512,)

得到pooled_grads_value是通道对‘大象’的重要程度;conv_layer_output_value是特征图数组的512个通道,(14,14,512),对应相乘,取所有通道的平均值得到heatmap,heatmap为一个(14,14)的图:

这里,因为我的当前环境下没有安装opencv,所以我们先将热力图保存下来:
#把热力图保存起来
import pickle
with open('E:/heatmap.pickle','wb')as f: #python路径要用反斜杠
pickle.dump(heatmap,f) #将变量dump进f里面
热力图与原始图叠加:
###热力图与原始图叠加
#下载heatmap变量
import pickle
with open('E:/heatmap.pickle','rb') as f:
heatmap = pickle.load(f)#从f文件中提取出heatmap
#叠加
import cv2
import numpy as np
import matplotlib.pyplot as plt
img_path = 'E:/elephant1.jpeg'
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap,(img.shape[1],img.shape[0]))#将heatmap调整为和img一样的大小
heatmap = np.uint8(255*heatmap)#将热力图转换为RGB格式
heatmap = cv2.applyColorMap(heatmap,cv2.COLORMAP_JET)#将热力图应用于原始图像
superimposed_img = heatmap * 0.4 + img #热力强度因子0.4
save_path = 'E:/elephant1_and_heatmap.jpg'
cv2.imwrite(save_path,superimposed_img)
img_and_heatmap = plt.imread(save_path)
plt.imshow(img_and_heatmap)

可以看到小象耳朵的激活强度较大,这是分辨为非洲象的关键地方















 3016
3016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









