







知识建模
知识建模是指建立知识图谱的数据模型,即采用什么样的方式来表达知识,构建一个本体模型对知识进行描述。在本体模型中需要构建本体的概念,属性以及概念之间的关系。知识建模的过程是知识图谱构建的基础,高质量的数据模型能避免许多不必要、重复性的知识获取工作,有效提高知识图谱构建的效率,降低领域数据融合的成本。不同领域的知识具有不同的数据特点,可分别构建不同的本体模型。
知识建模一般有自顶向下和自底向上两种途径:1.自顶向下的方法(如下图所示)是指在构建知识图谱时首先定义数据模式即本体,一般通过领域专家人工编制。从最顶层的概念开始定义,然后逐步细化,形成结构良好的分类层次结构。2.自底向上的方法则相反(如下图所示),首先对现有实体进行归纳组织,形成底层的概念,再逐步往上抽象形成上层的概念。自底向上的方法则多用于开放域知识图普的本体构建,因为开放的世界太过复杂,用自顶向下的方法无法考虑周全,且随着世界变化,对应的概念还在增长,自底向上的方法则可满足概念不断增长的需要。
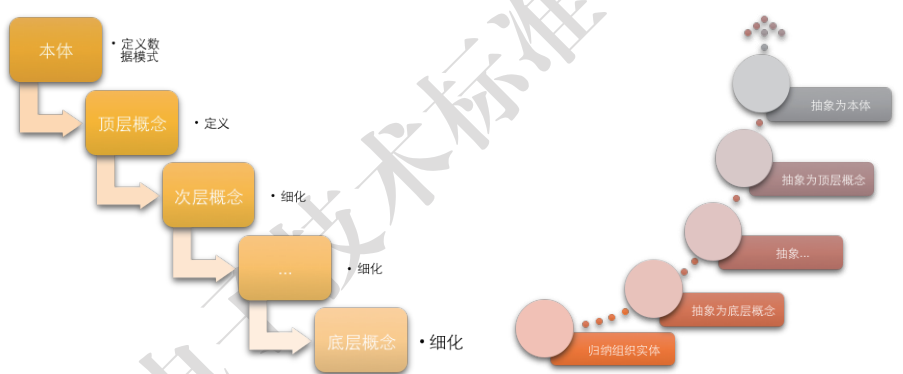
知识建模方法
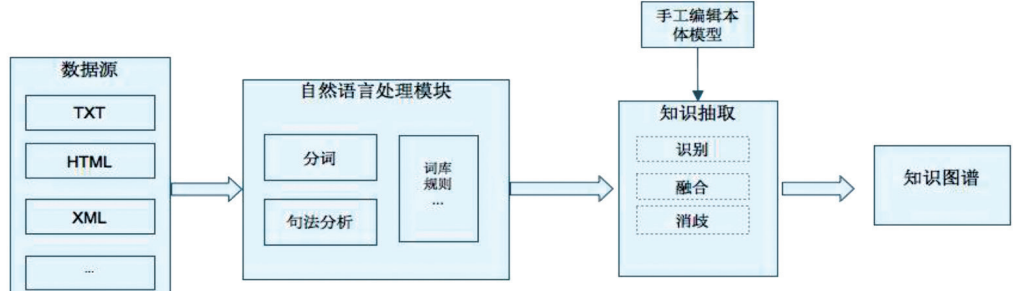
知识建模目前的实际操作过程,可分为手工建模方式和半自动建模方式。手工建模方式适用于对知识建模容量小、质量高的要求,但是无法满足大规模的知构建,是一个耗时、昂贵、需要专业知识的任务;混合方式将自然语言处理与手工方式结合,适于规模大且语义复杂的图谱。
手工建模方式过程主要可以分为以下的六个步骤:明确领域本体及任务、模型复用、列出本体涉及领域中的元素、明确分类体系、定义属性及关系、定义约束条件。在人工建模的过程中,以上的六个步骤并不是一一顺序执行的,可以根据知识建模的具体需求,组合其中的步骤达到知识建模的目的。下面分别对这些步骤作详细的介绍,如下图所示。
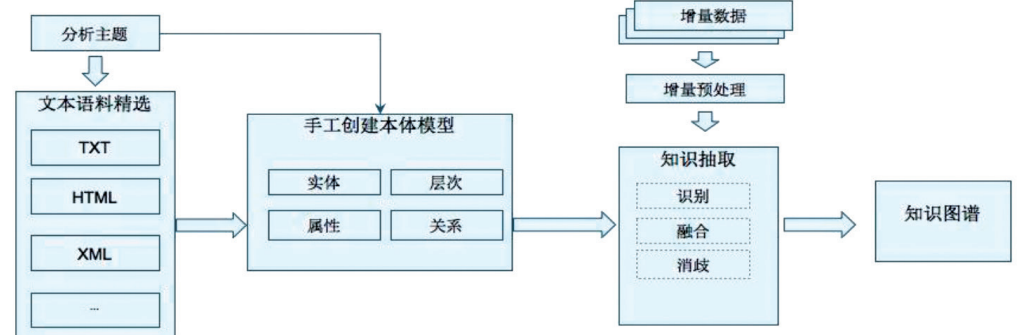
半自动建模方式先通过自动方式获取知识图谱,然后进行大量的人工干预过程,如下图所示。运用自然语言处理技术先自动建模的方法可以分为三大类:基于结构化数据的知识建模方法,基于半结构化数据的知识建模方法和基于非结构化数据的知识建模方法。近年来,对于非结构化数据的知识建模方法研究较多,涌现出一批优秀的基于非结构化数据的知识建模方法的高水平研究成果。
知识建模评价
对知识建模质量评价也是知识建模的重要组成部分,通常与实体对齐任务一起进行的。质量评价的作用在于可以对知识模型的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。一个合理的本体模型宜满足以下标准:
- 明确性和客观性:用自然语言对所定义术语给出明确的、客观的语义定义。
- 完全性:定义是完整的,完全能表达所描述领域内术语的含义。
- 一致性:正确一致地展示数据、对象和信息,由术语得出的推论 与术语本身含义不会产生矛盾。
- 最大单调可扩展性:添加通用或专用的术语时,不需要修改己有 的内容,便于知识图谱扩展。
- 最小承诺:尽可能少的约束,指本体约定应该最小,对建模对象 尽可能少的约束。 易用性:有效地支撑业务的分析和决策需求。
技术发展趋势
知识建模核心解决了采用什么样的形式高效组织和表达知识的问题,偏向于知识建模的方法论,在未来的发展趋势中,将会解决知识建模的规范化和标准化。同时随着大数据时代的到来,知识建模将会朝着对大规模数据的进行建模的方向发展,届时多人在线编辑,并且实时更新知识建模将成为可能。针对传统人工知识建模耗时、耗力、效率低下等弊端,知识建模可与自动语义处理算法进行结合,实现全自动建模方式,避免人工干预和操作;另外,快速集成现有的结构化知识模型,支撑起事件、时序等复杂知识形式的表达模式,建立功能更加完善、表达更加强大的知识模型。
















 3002
3002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











