







机器学习有三宝:
一、模型
二、策略
三、算法
模型:
先来一波简介:
K-NN是一种基本分类和回归方法,这篇博客我们只讨论分类问题中的k近邻法,kNN的输入为实例的特征向量,对应于特征空间的点;输出为实例的分类类别。
假设给定一个训练数据集,其中类别已定。分类时,给定测试点,选定k个离测试点最近的点,得到k个结果,对结果进行投票,选择票数最高的结果作为分类结果。
因此,k近邻法不像感知机一般,具有显式的学习过程,它只是利用训练数据集对特征空间进行划分

其实,KNN的原理很简单,可以理解为近朱者赤近墨者黑。
KNN的三个基本要素:k值的选定,距离度量,分类决策规则
准备:训练集T={(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)}
其中,xi∈X∈Rn,为实例的特征向量,yi∈Y={c1,c2,c3,…,cn}为分类类别
输出为实例x所属的类y
接下里便是上文所提到的投票机制了
k近邻的特殊情况是k=1时,成为最近邻算法,对于输入实例x的最近邻的点作为输入实例的类别
距离度量:
常见的距离度量有欧式距离,但也可以是更常见的Lp距离,Minkowski 距离
这次,我们聊聊Lp距离:
设特征空间X是n维实数的向量空间Rn,xi,xj∈X,xi =(xi1,xi2,xi3,…xin)T,
xj =(xj1,xj2,xj3,…xjn)T,则xi,xj的Lp距离定义为
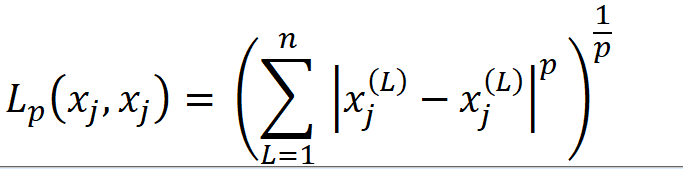
当p=2时,就是我们常说的欧式距离
当p=1时,就是曼哈顿距离
当p=无穷大时,就是各个坐标距离的最大值,即
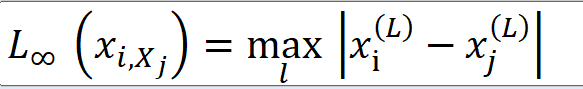
为什么P取无穷时,会是这个结果?
这个我用python代码证明:
通过绘制散点图可以看到, 当p=无穷时,是一个直线,当p = 2时,会是一个圆


python代码证明走起:
import matplotlib.pyplot as plt
import numpy as np
def Sum(p,xi,xj):#xj始终为0,0,0....
sum = 0
if(len(xi)!=len(xj)):
print("their len has to be same!")
else:
temp_sum = 0
for i in range(len(xi)):
temp_sum += (xi[i]-xj[i])**p
sum = pow(temp_sum,1/p)
return sum
if __name__=="__main__":
yi = [0,0]
i = 0.01
zi = []
xi = [i,0]
while i < 1.01:
temp = 0
while abs(Sum(2,xi,yi)-1)>0.08: #设定阈值,这个浮点数0.08的设置关系到散点图能不能很好的模拟图像
temp = temp + 0.01
xi = [i,temp]
print(Sum(2,xi,yi))
print(xi)
zi.append(xi[1])
i += 0.01
xi=[i,temp]
print(i)
Xj = np.arange(0,1,0.01)
Xi = zi
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title('Lp')
# 设置X轴标签
plt.xlabel('Xj')
# 设置Y轴标签
plt.ylabel('Xi')
# 画散点图
ax1.scatter(Xj, Xi, c='r', marker='o')
plt.show()
假定|xi|=2,xj=[0,0],距离为1
则绘图如下:

上面的代码只有第一象限的结果,关于p=无穷时,代码里实现的也是基于xi1的图像,同理,当我们基于xi2进行绘图时,将产生一条垂直于x轴的直线。
关于k值的选择,这里再提一下:这篇博客只考虑k=1时的情况。但是我们实际应用的时候,可能还要考虑取其他k值,k值一般取一个比较小的数值,通常采用交叉验证来选取最优的k值
分类决策规则:
kNN往往是是多数表决,即由输入实例的k个邻近的训练例子中的多数类决定输入实例的类,多数表决等价于经验风险最小化
证明如下:P(Y ≠ f(x))= 1 - P(Y = f(x)),则误分类率:(I是指示函数,当yi=cj时,取值为1,否则为0)
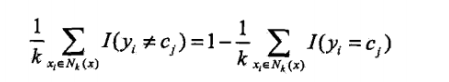
要使误分类率最小,等价于要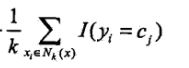
最大,所以多数表决等价于经验风险最小化
实现:
构建kd树,搜索kd树
开始种树 忄忄忄忄忄:
kd 树是二叉树,表示对k维空间的划分,构建kd树相当于不断地用垂直坐标轴的超平面将k维空间进行划分,构成一系列的k维超矩形区域,kd树的每一个结点对应于一个k维超矩形区域。
算法:


捡个栗子来看看:
T ={(2,3)T,(5,4)T,(9,6)T,(4,7)T,(8,1)T,(7,2)T} (后面的T表示转置矩阵)
构建第一步: 以xi1作为判断标准:
排序后,取(5,4)T, (7,2)T, 按照上面算法来说,应该取5和7的中位数,但是我们还是取偏大的(7,2)作为根节点,小于xi1小于7的做左节点,反之,则作右节点
后面根据 L= J(mod k)+1决定比较的顺序。
以此类推,便很快构建出kd树

知道你们懒得推,我把图放出来了
接下来,我们开始kd树的最近邻搜索
- 测试点首先从根节点出发,按照不同深度不同的xi比较标准,决定往左还是往右,最后到达叶节点
- 以当前叶节点作为最近邻点,递归的往上推,对每一个节点做以下操作
(a)查看父节点,分别比较父节点、当前最近邻节点 与 测试点的距离,如果前者较小,则最近邻节点更新为该父节点。
(b)当前最近邻节点一定存在于该父节点的一个子节点的区域,检查该父节点的另一个子节点,看是否有更近的节点,如果有,就更新当前最近邻点,如果没有,则接着向上递归
如何判断是否可能有最近邻节点呢?
原理很简单:
以测试点作为超球体的球心,以“当前最近邻节点”到球心的距离作为半径,若这个若另一个子节点的区域与超球体相交,则可能有“最近邻节点”,否则觉悟可能 - 当回归到根节点时,停止搜索,最后的当前“最近邻节点”为最近节点。
还是捡个栗子:

搜索路径:S->D->B->F->A->C->E
代码后续补上:
KNN线性扫描版:
这里我们只测试了一个例子,main增加添加for循环便可以多次测试了
import numpy as np
import collections
import matplotlib.pyplot as plt
class KNN:
def __init__(self,X_train,y_train,K = 3):
self.X_train = X_train
self.y_train = y_train
self.K = K
def predict(self,X_new):
#计算欧式距离,ord对应于Lp距离中的p
dist_list = [(np.linalg.norm(X_new-self.X_train[i],ord = 2),self.y_train[i]) for i in range(self.X_train.shape[0])]
#得到(d0,-1),(d1,1)....
dist_list.sort(key = lambda x:x[0])
#由于dist_list内部存储的一个元祖,所以排序的时候,需要加入参数key,也就是关键词, lambda是一个隐函数,是固定写法 ;x表示列表中的一个元素,在这里,表示一个元组,x只是临时起的一个名字,你可以使用任意的名字;x[0]表示元组里的第一个元素,当然第二个元素就是x[1];所以这句命令的意思就是按照列表中第一个元素排序
y_list = (dist_list[i][-1] for i in range(self.K))
y_counter = collections.Counter(y_list).most_common()
#得到前K个类别(从大到小)
return y_counter[0][0]
def draw(self,X_train,y_train,X_new,y_predict):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set_title('the Knn')
plt.xlabel("X_train1")
plt.ylabel("X_train2")
for i in range(self.X_train.shape[0]):
if y_train[i] == -1: # 如果取反例,则以”-“画点
ax.scatter(X_train[i][0],X_train[i][1],c = 'r',marker = '_')
else:#如果取正例,则以”+“画点
ax.scatter(X_train[i][0],X_train[i][1],c = 'r',marker = '+')
if y_predict == 1: #根据不同判断结果决定绘图结果,蓝色的点为测试点
ax.scatter(X_new[0][0],X_new[0][1],c= 'b',marker = '+')
else:
ax.scatter(X_new[0][0], X_new[0][1], c='b', marker='_')
plt.show()
if __name__ =="__main__":
X_train = np.array([[5,4],
[9,6],
[4,7],
[2,3],
[8,1],
[7,2]])
y_train = [1,1,1,-1,-1,-1]
X_new = np.array([[5,3]])
#此处添加for就可以多组测试了
#设置不同的K值,决定取K个最近邻点(1,3,5)
for k in range(1,6,2):
clf = KNN(X_train,y_train,K = k)
y_predict = clf.predict(X_new)
print(" k = {},the most possible kind is {}".format(k,y_predict))
clf.draw(X_train,y_train,X_new,y_predict)
sk_learn 实现:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
if __name__ =="__main__":
X_train = np.array([[5, 4],
[9,6],
[4,7],
[2,3],
[8,1],
[7,2]])
y_train = np.array([1,1,1,-1,-1,-1])
X_new = np.array([[5,3]])
for k in range(1,6,2):
#构建实例,函数内部参数介绍
#n_neighbors近邻数,默认是5,可选[1,N]
#weights近邻权重,默认是uniform-权重一样,可选distance-越近权重越大
#algorithm,默认auto,可选brute-暴力求解,kd_tree-KD树,ball_tree-球树,当数据量小时,一定运行暴力求解
#leaf_size,默认是30,可选叶子节点数量的阈值
#p,默认是2,可选距离度量:欧式距离
#metric,默认是mincowski,可选距离定义:欧式距离(上面参数同下,一般都是选默认值就可以)
#n_jobs,默认值是None,可选None:一个进程;-1;所有进程。一般都设置成-1,当数据量较大时,多个进程在运行,但数据量
#较小时,只有一个进程在运行,相当于None
clf = KNeighborsClassifier(n_neighbors=k,weights="distance",n_jobs=-1)
#挑选模型
clf.fit(X_train,y_train)
#预测结果
y_predict = clf.predict(X_new)
print(y_predict)
#预测不同测试点的分类概率
y_predict_rate = clf.predict_proba(X_new)
print(y_predict_rate)
#对训练结果进行打分
print("the accrucy is :{:.0%}".format(clf.score(X_train,y_train)))
#返回k近邻点
#print(clf.kneighbors())















 2096
2096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









