






Where am I looking at? Joint Location and Orientation Estimation by Cross-View Matching
-
Where am I looking at? Joint Location and Orientation Estimation by Cross-View Matching
-
时间
- 2020 CVPR
-
作者
- Shi Yujiao
-
idea
-
这里面提到的,这个领域的最大的问题
-
就是巨大的视角差异,不同的视角之间的,包括外观和物体的位置的区别
-
方向如果不确定,那么就会引起地理位置上的模糊并且加大了搜寻的范围
-
标准的相机是有限的视角,那么就是减少了地域图片的辨别能力
-
-
两个值得注意的点
-
(i)图像中的水平线(平行于方位轴)具有近似恒定的深度,因此对应于航空图像中的同心圆;
-
(ii)图像中的垂直线深度随y坐标增加,因此对应于航空图像中的径向线。
-
简单来说,就是水平线,横着的线,在空域里是一个圆,然后竖着的线,就是 radial line 经向线,类似下面这个,就是经线纬线
-
然后他用了一个及坐标转换
-
-
部署了一个two - stream CNN 来学习一些联系,提出了一个DSM 模块,可以来实现这个目标,具体来说,就是计算了空地特征之间的关系
-
-
Contribution
-
无论Field of View 如何,第一种可以估计位置和朝向的,第一个同时考虑location和orientation的方法
-
提出了Dynamic Similarity Matching module去计算feature的相似度,从而得到ground images的orientation
-
achieves significant performance improvements
-
-
一些相关的
-
Liu & Li
- 朝向提供了一些重要的线索,可以用来决定地面图像的位置
-
-
理论细节
-
流程图
-
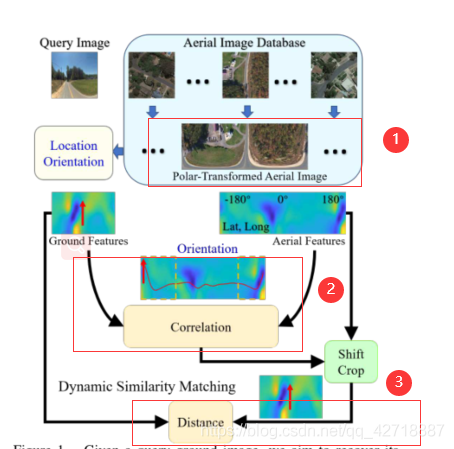
-
如上图所示,整个方法的流程主要分为3个部分。首先第①部分,本论文利用Polar Transform将aerial images全部转为ground images。然后,本论文使用vgg16作为backbone提取feature maps,这里不像以前的方法把图像变成一个向量的representation,而是最后输出一对feature volume。这样做的目的就是为后续进行圆周卷积提取orientation做准备。
-
第②部分就是计算这对feature volume的correlation。这里采用的计算方式就是圆周卷积。最后correlation最大的地方就是ground images的朝向。
-
第③部分就是根据前一步得到的orientation将Aerial Features进行裁剪,然后与Ground Features进行距离计算。
-
-
细节
-
地面的摄像头是垂直于地面的,然后空域的摄像头是平行于地面
-
因为是水平方向旋转的,那么就要确保CNN 将变换图像的最左侧和最右侧视为水平并列
-
用VGG16作为底层框架,主要用前十层
-
因为极坐标转化是水平方向的转化,那么就会带来垂直方向的volume失真,所以修改了后面三层的参数,降低了特征图的高度,保留了宽度
- 对垂直方向的失真更加宽容
-
降低乐feature channel number 到16
-
Dynamic Similarity Matching
-
拥有了朝向,就可以比较特征
-
但是,朝向并不是永远可以得到,并且朝向的错误会提升定位的困难程度,尤其是视域是有限的时候,
-
人类在地图上给自己定位的时候,是通过自己已经看到的东西定位的
-
通过azimuth angle axis方位角来计算,简单来说就是用inner product
- 得分最大的那个位置,就是这个地面图片和空域图片的相对角度
-
当地面的图片是一个全景图的时候,不论朝向知不知道,相似度结果就是L2Distance 2(1-max([Fa*Fg](i))
-
如果有多个相同的最高分,那么随机选择一个,因为这说明,这个空域的图像有不可避免的对称性
-
-
-
表现
-
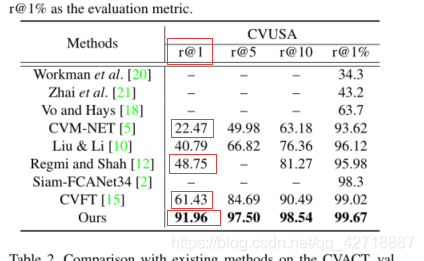
-
提升相当显著
-
-
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











