







CVM-Net: Cross-View Matching Network for Image-Based Ground-to-Aerial Geo-Localization
-
CVM-Net: Cross-View Matching Network for Image-Based Ground-to-Aerial Geo-Localization
-
时间 2018
-
作者Sixing Hu
-
motivation
-
地面拍的照片通常来讲并不能涵盖所有的地区,天空拍的照片相对来讲能覆盖整个大地
-
地域和空域之间的巨大的视角差异给匹配造成了很大的困扰和挑战
-
Vo 和 Hays使用一个额外的网络分支,来估计空域的朝向,但是在训练和测试的时候的开销巨大
-
max - margin triplet loss的margin value需要仔细挑选, Vo和Hay虽然选了一个soft-margin triplet loss,这个被证明了是很有效果的,但是
-
-
idea
-
将NetVLAD 嵌入在一个CNN的头部,使用NetVLAD来聚合从CNN 获得的局部特征,然后形成独立于局部特征的全局特征值
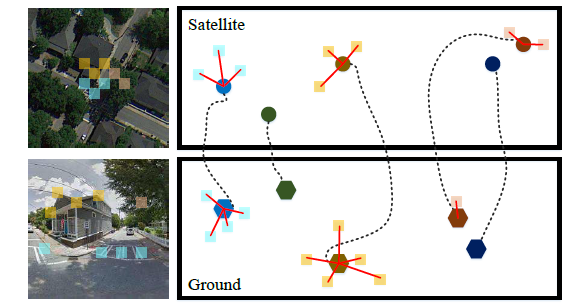
- Specifically, we embed the NetVLAD layer [3] on top of a CNN to extract descriptors that are invariant against large viewpoint changes. Figure 1 shows an illustration of our approach. The key idea is that NetVLAD aggregates the local features obtained from the CNN to form global representations that are independent of the locations of the local features.
-
-
结论
- 搭建了CVM-NET-I, CVM-NET-II, 引入了weighted soft-margin ranking loss 有权重的软边界,通过这些方法,显著提升了效率
-
可能的延申和扩展
-
关注一些不同的跨视角视觉定位的任务,比如白天和夜间,比如不同的风格的照片
-
其他的扩展延申的搜索,比如字到图像的搜索。
-
-
提到的之前的论文
-
Vo Hay 引入了二分类神经网络,孪生神经网络,triplet network 三重网络
-
核心的点在于,找到一个图像的可以快速区分和比较的描述子。
-
Sivic提出了一个描述子算法,把一系列的局部特征聚合成视觉单词直方图 Histogram of visual words
-
Nister and Stewenius 创建了一个树状的词汇,可以支持更多的可视化单词‘
-
Jegou 引入了VLAD 描述子,不同于直方图,这个可以将局部特征的残差聚合为聚类质心
-
Arandjelovic 首次引入了NetVLAD,这个就是嵌入到深度网络中来进行端到端的训练的
- NetVLAD was better than multiple fully connected layers, max pooling and VLAD. 应该是作用类似最大连接层,最大池化等内容,并且效用更好,
-
在图像检索中,最常使用的损失函数是 max-margin triplet loss,可以保证positive pairs 之间的距离比negative pairs 之间的距离更短
-
-
开始阐述这篇论文的方法
-
Goal
- 在给定的遥感图片库里,找到检索的地面图片的最近匹配
-
细节:
-
选用了Siamese like architecture 孪生神经网络
-
每个框架都包含了两个网络分支
-
包括本地特征提取local feature extraction
- 用了FCN全卷积神经网络
-
global descriptor generation全局描述子生成
-
用了NetVLAD,FCN的参数被传输到NetVLAD里去处理
-
CVM-Net-I and CVM-Net-II 两个框架方案被生成
-
CVM Net 1
-
Two independent NetVLADs, 两个分离的NetVLAD被采用
-
每个里面都有两组参数群
-
two groups of parameters in Gi - (1) K cluster centroids; 以及一个distance metric 距离矩阵
-
两个NetVLAD的clusters的数量都是一样的
-
每个层都生成一个VLAD vector,就是全局描述子,这个是同等向量空间的
-
具体的大概是这个样子,通过训练,卫星的图的中心点和地面图的中心点被连接起来
-
最终,每个聚类的描述子是这个中心点的所有的残差的加和;卫星图像的计算方式和地面图像的计算方式如下,两种分支的结构是一样的,参数不一样
-
-
CVM Net 11 NetVLADs with shared weights,参数共享
-
通过孪生神经网络结构搭建;同时,提取local features的特征值的网络也是一样的。提取过了之后,提取出来的特征值被传输给参数共享的两个全连接的层。
-
选取参数共享的方式是因为这个已经被证实可以提升
-
-
-
-
-
Weighted Soft-Margin Ranking Loss 加权软边界排名损失
-
triplet loss 三元损失函数常常被用作图像匹配以及检索任务的目标函数
-
可以让阳性样本更接近锚点,而非阴性样本
-
还可以避免决定边界问题,常见的是这样的,但是有个问题就是收敛过于慢,所以赶紧了一下,加了一个权重
-
后面又做了quadruplet loss
-
-
-
实施
-
数据集:
-
CVUSA , Vo and Hays
-
对于三元和四元的Loss, α\alphaα选了10
-
VGG16的参数是ImageNet预训练好的,NetVLAD 以及全连接层是预先随机生成的
-
用的Tensorflow,以及Adam 优化器,学习速率是10−510^{-5}10−5, dropout 设置 0.9
-
-
对于M对的阳性对,有M-1的对应的阴性对
-
一开始采用了exhaustive mini-batch strategy,可以在一个批里
-
实验结果
-
用了top 1%作为评估结果,只要前1%里有正确结果,就算有
-
结果表明了孪生神经网络参数共享在跨视角视觉定位里是不必要的,并且也是不适合的 CVMNet-1的成绩远超CVMNet-2
-
-
添加distractor image干扰图像
- 添加了很多很多的干扰的新加坡的卫星图片,原数据库是美国的,结果和没加差异不大,可以表明结构的鲁棒性
-
-
讨论
-
本地特征提取方面VGG16远超过AlexNet
- 因为VGG16更深
-
孪生神经网络参数共享这一套在这个跨视角视觉定位里不管用
-
quadruplet loss 比 triplet loss 表现更好,不过差异比较小在用VGG的时候
- 在使用更浅的网络的时候,Quadruplet loss的效果更好
-
作者后续又在其他的数据集上测算了
-
-
-
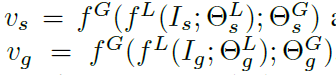

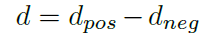
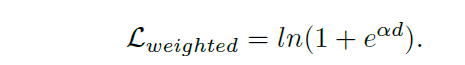
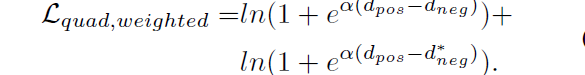
















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











