








前言
云原生(Cloud Native)[1]是云计算领域过去 5 年发展最快、关注度最高的方向之一。CNCF(Cloud Native Computing Foundation,云原生计算基金会)2021年度调查报告[2]显示,全球已经有超过 680 万的云原生技术开发者。同一时期,人工智能 AI 领域也在“深度学习算法+GPU 大算力+海量数据”的推动下持续蓬勃发展。有趣的是,云原生技术和 AI,尤其是深度学习,出现了很多关联。
大量 AI 算法工程师都在使用云原生容器技术调试、运行深度学习 AI 任务。很多企业的 AI 应用和 AI 系统,都构建在容器集群上。为了帮助用户更容易、更高效地在基于容器环境构建 AI 系统,提高生产 AI 应用的能力,2021 年阿里云容器服务 ACK 推出了云原生 AI 套件产品。本文将介绍和梳理我们对云原生 AI 这个新领域的思考和定位,介绍云原生 AI 套件产品的核心场景、架构和主要能力。
AI 与云原生极简史
回顾 AI 的发展历史,我们会发现这早已不是一个新的领域。从 1956 年达特茅斯学术研讨会上被首次定义,到 2006 年 Geoffery Hinton 提出了“深度信念网络”(Deep Believe Network),AI 已历经 3 次发展浪潮。尤其是近 10 年,在以深度学习(Deep Learning)为核心算法、以 GPU 为代表的大算力为基础,叠加海量生产数据积累的推动下,AI 技术取得了令人瞩目的进展。与前两次不同,这一次 AI 在机器视觉、语音识别、自然语言理解等技术上实现突破,并在商业、医疗、教育、工业、安全、交通等非常多行业成功落地,甚至还催生了自动驾驶、AIoT 等新领域。
然而,伴随 AI 技术的突飞猛进和广泛应用,很多企业和机构也发现想要保证“算法+算力+数据”的飞轮高效运转,规模化生产出有商业落地价值的 AI 能力,其实并不容易。昂贵的算力投入和运维成本,低下的 AI 服务生产效率,以及缺乏可解释性和通用性的 AI 算法,都成为横亘在 AI 用户面前的重重门槛。
与 AI 的历史类似,云原生领域的代表技术 —— 容器(container),也不是一个新的概念。其最早可追溯到 1979 年诞生的 UNIX chroot 技术,就开始显现出容器的雏型。接下来又出现了 FreeBSD Jails,Linux VServer,OpenVZ,Warden 等一系列基于内核的轻量级资源隔离技术。直到 2013 年 Docker 横空出世,以完善的容器对象封装、标准的 API 定义和友好的开发运维体验,重新定义了使用数据中心计算资源的界面。随后的故事大家都知道了,Kubernetes 在与 Docker Swarm 和 Mesos 的竞争中胜出,成为容器编排与调度的事实标准。Kubernetes 和容器(包括 Docker,Containerd,CRI-O 等多种容器运行时和管理工具)构成了 CNCF 定义的云原生核心技术。经过 5 年高速发展,云原生技术生态已经覆盖了容器运行时、网络、存储和集群管理、可观测性、弹性、DevOps、服务网格、无服务器架构、数据库、数据仓库等 IT 系统的方方面面。
为何出现云原生 AI
据 CNCF 2021 年度相关调查报告显示, 96% 的受访企业正在使用或评估 Kubernetes,这其中包括了很多 AI 相关业务的需求。Gartner 曾预测,到 2023 年 70% 的 AI 应用将基于容器和 Serverless 技术开发。
现实中,在研发阿里云容器服务 ACK[3](Alibaba Container service for Kubernetes)产品过程中,我们看到越来越多用户希望在 Kubernetes 容器集群中管理 GPU 资源,开发运行深度学习和大数据任务,部署和弹性管理 AI 服务,且用户来源于各行各业,既包括互联网、游戏、直播等快速增长的公司,也有自动驾驶、AIoT 这类新兴领域,甚至不乏政企、金融、制造等传统行业。
用户在开发、生成、使用 AI 能力时碰到很多共性的挑战,包括 AI 开发门槛高、工程效率低、成本高、软件环境维护复杂、异构硬件管理分散、计算资源分配不均、存储接入繁琐等等。其中不少用户已经在使用云原生技术,并成功提升了应用和微服务的开发运维效率。他们希望能将相同经验复制到 AI 领域,基于云原生技术构建 AI 应用和系统。
在初期,用户利用 Kubernetes,Kubeflow,nvidia-docker 可以快速搭建 GPU 集群,以标准接口访问存储服务,自动实现 AI 作业调度和 GPU 资源分配,训练好的模型可以部署在集群中,这样基本实现了 AI 开发和生产流程。紧接着,用户对生产效率有了更高要求,也遇到更多问题。比如 GPU 利用率低,分布式训练扩展性差,作业无法弹性伸缩,训练数据访问慢,缺少数据集、模型和任务管理,无法方便获取实时日志、监控、可视化,模型发布缺乏质量和性能验证,上线后缺少服务化运维和治理手段,Kubernetes 和容器使用门槛高,用户体验不符合数据科学家的使用习惯,团队协作和共享困难,经常出现资源争抢,甚至数据安全问题等等。
从根本上解决这些问题,AI 生产环境必然要从“单打独斗的小作坊”模式,向“资源池化+AI 工程平台化+多角色协作”模式升级。为了帮助有此类诉求的“云原生+AI”用户实现灵活可控、系统化地演进,我们在 ACK 基础上推出云原生 AI 套件[4]产品。只要用户拥有一个 ACK Pro 集群,或者任何标准 Kubernetes 集群,就可以使用云原生 AI 套件,快速定制化搭建出一个自己的 AI 平台。把数据科学家和算法工程师从繁杂低效的环境管理、资源分配和任务调度工作中解放出来,把他们更多的精力留给“脑洞”算法和“炼丹”。
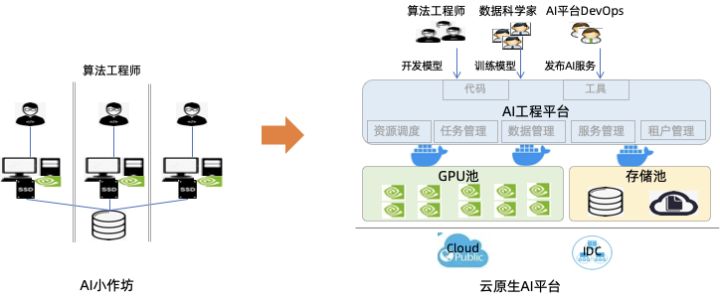
图0:AI 生产环境向平台化演进
如何定义云原生 AI
随着企业 IT 架构逐步深入地向云计算演进,以容器、Kubernetes、服务网格等为代表的云原生技术,已经帮助大量应用服务快速落地云平台,并在弹性、微服务化、无服务化、DevOps 等场景中获取很大价值。与此同时,IT 决策者们也在考虑如何通过云原生技术,以统一架构、统一技术堆栈支撑更多类型的工作负载。以避免不同负载使用不同架构和技术实现,带来“烟囱”系统、重复投入和割裂运维的负担。
深度学习和 AI 任务,正是社区寻求云原生支撑的重要工作负载之一。事实上,越来越多深度学习系统、AI 平台已经构建在容器和 Kubernetes 集群之上。在 2020 年,我们就明确提出“云原生 AI”的概念、核心场景和参考技术架构,以期为这个全新领域提供具象的定义,可落地的路线图和最佳实践。
阿里云容器服务 ACK 对云原生 AI 的定义 - 充分利用云的资源弹性、异构算力、标准化服务以及容器、自动化、微服务等云原生技术手段,为 AI/ML 提供工程效率高、成本低、可扩展、可复制的端到端解决方案。
核心场景
我们将云原生 AI 领域聚焦在两个核心场景:持续优化异构资源效率,和高效运行 AI 等异构工作负载。
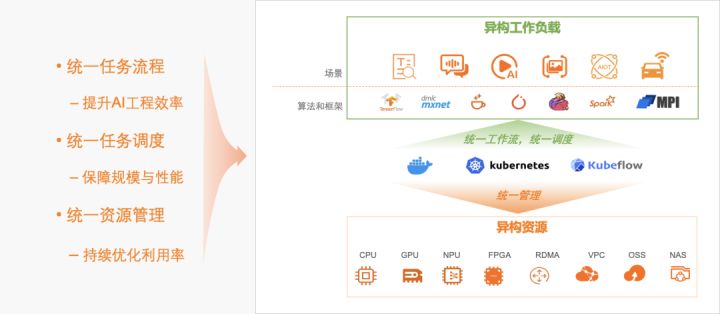
图1:云原生 AI 的核心场景
场景 1、优化异构资源效率
对阿里云 IaaS 或者客户 IDC 内各种异构的计算(如CPU,GPU,NPU,VPU,FPGA,ASIC)、存储(OSS,NAS, CPFS,HDFS)、网络(TCP, RDMA)资源进行抽象,统一管理、运维和分配,通过弹性和软硬协同优化,持续提升资源利用率。
场景 2、运行 AI 等异构工作负载
兼容 Tensorflow,Pytorch,Horovod,ONNX,Spark,Flink 等主流或者用户自有的各种计算引擎和运行时,统一运行各类异构工作负载流程,统一管理作业生命周期,统一调度任务工作流,保证任务规模和性能。一方面不断提升运行任务的性价比,另一方面持续改善开发运维体验和工程效率。
围绕这两个核心场景,可以扩展出更多用户定制化场景,比如构建符合用户使用习惯的 MLOps 流程;或者针对 CV 类(Computer Vision, 计算机视觉)AI 服务特点,混合调度 CPU,GPU,VPU(Video Process Unit)支持不同阶段的数据处理流水线;还可以针对大模型预训练和微调场景,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









