







企业在 Kubernetes 上运行 AI、大数据应用已成主流,资源弹性和开发运维效率得到显著提升的同时,计算存储分离架构也带来了挑战:网络延迟高、网络费用贵、存储服务带宽不足等。
以 AI 训练、基因计算、工业仿真等高性能计算场景为例,需要在短时间内并发执行海量计算,多计算实例共享访问文件系统的同一数据源。很多企业使用阿里云文件存储 NAS 或 CPFS 服务,挂载到阿里云容器服务 ACK 运行的计算任务上,实现数千台计算节点的高性能共享访问。
然而,随着算力规模和性能提升、以及模型规模和工作负载复杂度的增加,在云原生的机器学习和大数据场景下,高性能计算对并行文件系统的数据访问性能和灵活性要求也越来越高。
如何能更好地为容器化计算引擎提供弹性和极速的体验,成为了存储的新挑战。
为此,我们推出了弹性文件客户端 EFC(Elastic File Client),基于阿里云文件存储服务的高扩展性、原生 POSIX 接口和高性能目录树结构,打造云原生存储系统。并且,EFC 与云原生数据编排和加速系统 Fluid 结合,实现数据集的可见性、弹性伸缩、数据迁移、计算加速等,为云原生的 AI、大数据应用共享访问文件存储提供了可靠、高效、高性能的解决方案。
1 Fluid,云原生之数据新抽象
Fluid[1]是一个云原生分布式数据编排和加速系统,主要面向数据密集型应用(如大数据、AI等应用)。
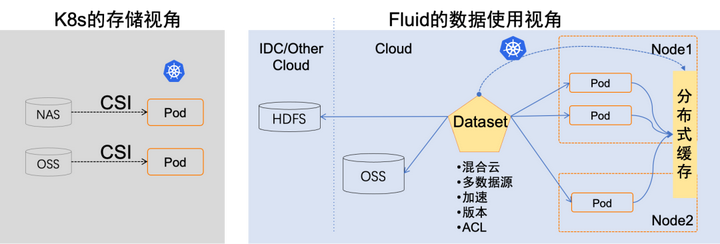
与传统的面向存储的PVC不同,Fluid 从应用角度出发,提出弹性数据集(Dataset)概念,对“在 Kubernetes 上使用数据的过程”进行抽象。Fluid 是 Kubernetes 生态的开源项目,由南京大学、阿里云以及 Alluxio 开源社区联合发起,已于 2021 年捐献给 CNCF 社区。
Fluid 让数据像流体一样,在各种存储源(如 NAS、CPFS、OSS 和 Ceph 等)和 Kubernetes 上层应用之间来去自如,灵活高效地移动、复制、驱逐、转换和管理。
Fluid 可以实现数据集的 CRUD 操作、权限控制和访问加速等功能,用户可以像访问 Kubernetes 原生数据卷一样直接访问抽象出来的数据。Fluid 当前主要关注数据集编排和应用编排这两个重要场景:
- 在数据集编排方面,Fluid 可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点,以提高数据访问速度。
- 在应用编排方面,Fluid 可以将指定应用调度到已经存储了指定数据集的节点上,以减少数据传输成本和提高计算效率。
两者还可以组合协同编排,即协同考虑数据集和应用需求进行节点资源调度。
Fluid 为云原生 AI 与大数据应用提供一层高效便捷的数据抽象,并围绕抽象后的数据提供以下核心功能:
面向应用的数据集统一抽象
数据集抽象不仅汇总来自多个存储源的数据,还描述了数据的迁移性和特征,并提供可观测性,例如数据集总数据量、当前缓存空间大小以及缓存命中率。用户可以根据这些信息评估是否需要扩容或缩容缓存系统。
可扩展的数据引擎插件
虽然 Dataset 是统一的抽象概念,但不同的存储有不同的 Runtime 接口,实际的数据操作需要由不同的 Runtime 实现。Fluid 的 Runtime 分为两类:CacheRuntime 实现缓存加速(包括开源分布式缓存AlluxioRuntime、JuiceFSRuntime,阿里云 EFCRuntime、JindoRuntime 和腾讯云 GooseFSRuntime);ThinRuntime 提供统一访问接口(如 s3fs、nfs-fuse 等分布式存储系统),方便接入第三方存储。
自动化的数据操作
以 CRD 的方式提供数据预热,数据迁移,数据备份等多种操作,并且支持一次性、定时和事件驱动等多种模式,方便用户结合到自身自动化运维体系中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









