







导读
深度学习已在面向自然语言处理等领域的实际业务场景中广泛落地,对它的推理性能优化成为了部署环节中重要的一环。推理性能的提升:一方面,可以充分发挥部署硬件的能力,降低用户响应时间,同时节省成本;另一方面,可以在保持响应时间不变的前提下,使用结构更为复杂的深度学习模型,进而提升业务精度指标。
本文针对地址标准化服务中的深度学习模型开展了推理性能优化工作。通过高性能算子、量化、编译优化等优化手段,在精度指标不降低的前提下,AI模型的模型端到端推理速度最高可获得了4.11倍的提升。
1. 模型推理性能优化方法论
模型推理性能优化是AI服务部署时的重要环节之一。一方面,它可以提升模型推理的效率,充分释放硬件的性能。另一方面,它可以在保持推理延迟不变的前提下,使得业务采用复杂度更高的模型,进而提升精度指标。然而,在实际场景中推理性能优化会遇到一些困难。
1.1 自然语言处理场景优化难点
典型的自然语言处理(Natural Language Processing, NLP)任务中,循环神经网络(Recurrent Neural Network, RNN)以及BERT[7](Bidirectional Encoder Representations from Transformers.)是两类使用率较高的模型结构。为了便于实现弹性扩缩容机制和在线服务部署的高性价比,自然语言处理任务通常部署于例如Intel® Xeon®处理器这样的x86 CPU平台。然而,随着业务场景的复杂化,服务的推理计算性能要求越来越高。以上述RNN和BERT模型为例,其在CPU平台上部署的性能挑战如下:
- RNN
循环神经网络是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络。实际使用中常见的RNN有LSTM,GRU以及衍生的一些变种。在计算过程中,如下图所示,RNN结构中每一次的后级输出都依赖于相应的输入和前级输出。因此,RNN可以完成序列类型的任务,近些年在NLP甚至是计算机视觉领域被广泛使用。RNN相较于与BERT而言,计算量更少,模型参数共享,但其计算时序依赖性会导致无法对序列进行并行计算。
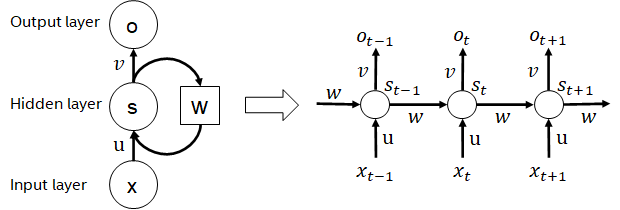
RNN结构示意图
- BERT
BERT[7]证明了能够以较深的网络结构在大型数据集上完成无监督预训练(Unsupervised Pre-training),进而供给特定任务进行微调(finetune)的模型。它不仅提升了这些特定任务的精度性能,还简化了训练的流程。BERT的模型结构简单又易于扩展,通过简单地加深、加宽网络,即可获得相较于RNN结构更好的精度。而另一方面,精度提升是以更大的计算开销为代价的,BERT模型中存在着大量的矩阵乘操作,这对于CPU而言是一种巨大的挑战。
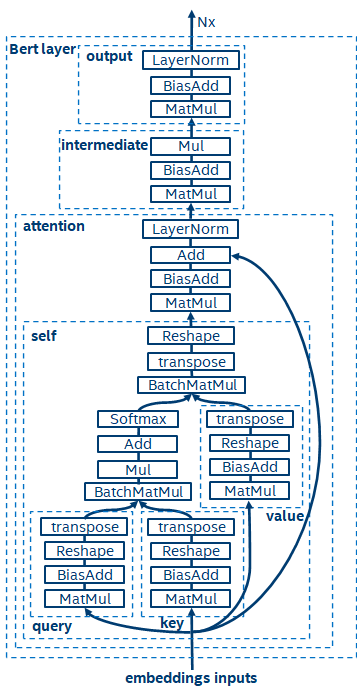
BERT模型结构示意图
1.2 模型推理优化策略
基于上述推理性能挑战的分析,我们认为从软件栈层面进行模型推理优化,主要有如下策略:
- 模型压缩:包括量化、稀疏、剪枝等
- 特定场景的高性能算子
- AI编译器优化
量化
模型量化是指将浮点激活值或权重(通常以32比特浮点数表示)近似为低比特的整数(16比特或8比特),进而在低比特的表示下完成计算的过程。通常而言,模型量化可以压缩模型参数,进而降低模型存储开销;并且通过降低访存和有效利用低比特计算指令(如Intel® Deep Learning Boost Vector Neural Network Instructions,VNNI),取得推理速度的提升。
给定浮点值,我们可以通过如下公式将其映射为低比特值:
其中和是通过量化算法所得。基于此,以Gemm操作为例,假设存在浮点计算流程:
我们可以在低比特域完成相应的计算流程:
高性能算子
在深度学习框架中,为了保持通用性,同时兼顾各种流程(如训练),算子的推理开销存在着冗余。而当模型结构确定时,算子的推理流程仅是原始全量流程个一个子集。因此,当模型结构确定的前提下,我们可以实现高性能推理算子,对原始模型中的通用算子进行替换,进而达到提升推理速度的目的。
在CPU上实现高性能算子的关键在于减少内存访问和使用更高效的指令集。在原始算子的计算流程中,一方面存在着大量的中间变量,而这些变量会对内存进行大量的读写操作,进而拖慢推理的速度。针对这种情况,我们可以修改其计算逻辑,以降低中间变量的开销;另一方面,算子内部的一些计算步骤我们可以直接调用向量化指令集,对其进行加速,如Intel® Xeon®处理器上的高效的AVX512指令集。
AI编译器优化
随着深度学习领域的发展,模型的结构、部署的硬件呈现出多样化演进的趋势。将模型部署至各硬件平台时,我们通常会调用各硬件厂商推出的runtime。而在实际业务场景中,这可能会遇到一些挑战,如:
- 模型结构、算子类型的迭代的速度会高于厂家的runtime,使得一些模型无法快速基于厂商的runtime完成部署。此时需要依赖于厂商进行更新,或者利用plugin等机制实现缺失的算子。
- 业务可能包含多个模型,这些模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









