







清华大学的NLP研究团队又提出了一个新的任务:Cross document relation extraction。相应地,他们给出了任务的定义和数据集的构造、格式、说明等,也给出了两种baseline来进行跨文档关系抽取。期待能为跨文档关系抽取起到一个基石的作用。
想要获得更详细的资料,可以进入-> github链接:CodRED。
Abstract
关系抽取是构建知识图谱、智能问答的基础任务,目前存在句子关系抽取(从单个句子抽取实体之间的关系)、文档级关系抽取(从一篇文章中抽取多个实体对之间的关系)这两种主流任务。但是现实生活中,往往需要从多个文档来推测关系(比如智能问答),所以提出了一个新的任务和数据集(CodRED)。再给定实体的情况下,主要有两个任务:
- 文档检索:首先找到可以提供实体关系的文章,
- 关系推理:通过上述文章来进行多条推理,进而抽取出实体之间的关系。
Background
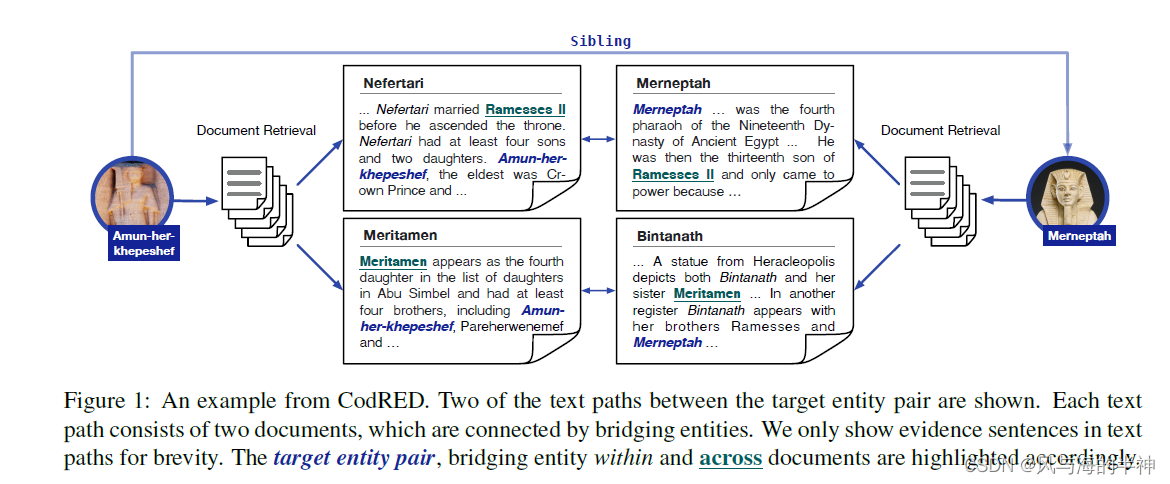
比如,通过多篇文章抽取Amun和Merneptah是姊妹关系。
Data Collection
对英文维基百科语料进行收集、分析、打标等工作来构建CodRED数据集。主要分为以下三个步骤:
- 首先对文章进行远程监督打标,为后续人工打标作为支撑
- 对关系和相关的证明(evidence)进行人工打标
- 生成实体对和关系路径的负样本
远程监督打标
首先利用BERT模型抽取文章中的实体,然后将实体的指代汇合到同一实体ID中。由于直接使用远程监督进行关系打标会带来很多噪声,所以文章设置了额外的条件:目标实体对之间至少存在一条推理路径(比如经过一个中间实体得到关系)。
人工打标
人工打标对远程监督抽取出的结果进行矫正。打标的内容包括:
- 内容路径:可以从这些路径推理出实体之间的关系
- 支撑(evidence)句子:可以做为关系路径的支撑内容。
实体对和关系路径的负样本
以前的一些RE数据集都有很致命的一个问题:实体之间的关系和实体的名称有明显的联系,所以模型通过这些数据集学到的并不是实体之间真正的关系,而是关系和名称的对应(也就泛化能力不行,记住了刻板的套路),所以文章加入了大量的负样本来减轻这一问题。
包括实体关系负样本和路径负样本。其中实体关系负样本占比15.6%,
Post-Processing and Benchmarks
将数据集、负样本划分为训练、测试、验证集。并且有两种设置,分别来实现不同的功能。
Closed Setting
只用在给定的数据集中抽取实体的关系,并不需要先检索出相关文章,再进行关系抽取。主要用来检测模型抽取关系的能力。其任务定义为:给定实体对,给定正样本的内容路径和负样本的内容路径来进行推理,进而抽取出关系。
Open Setting
该任务设定为首先检索出相关文章、内容路径,然后在进行关系抽取。可想而知,第二种设置的任务更难,但是也更贴近实际情况。
Baselines
文章中提出了两种方法作为baseline。一是pipline的方法,二是end-to-end的方法。
-
pipline
首先对含有头实体或者尾实体的文章进行编码,然后在实体两侧插入特殊标识符(BERT的常用操作了)。然后选择文章内容,由于文章很长,所以挑选出与实体相关的内容(周围512个token),长尾依赖广泛存在于NLP任务重,亟待解决。将CLS作为实体对的表征输入到全连接层中,进行关系分类。文章说用到了“Intra-document Relational Graph Extraction”,但是并没有看到具体的图模型,仍然是序列模型。 -
end-to-end
pipline模型有误差传播这一不足(如果只使用一个损失函数,pipline模型也没有误差传播。上述pipline模型应该也只有一个损失函数,后续看了代码之后再来更改),所以采用端到端的方式(文本翻译常用模型)来进行抽取。
分为文章内关系抽取和跨文档关系抽取。文章内关系抽取和pipline模型一致。跨文档关系抽取首先对内容路径进行编码,然后将文章拼接起来进行编码、插入实体标识,通过BERT获得实体表征。再用注意力机制来对路径进行融合,得到最终路径再进行分类。
Experiments
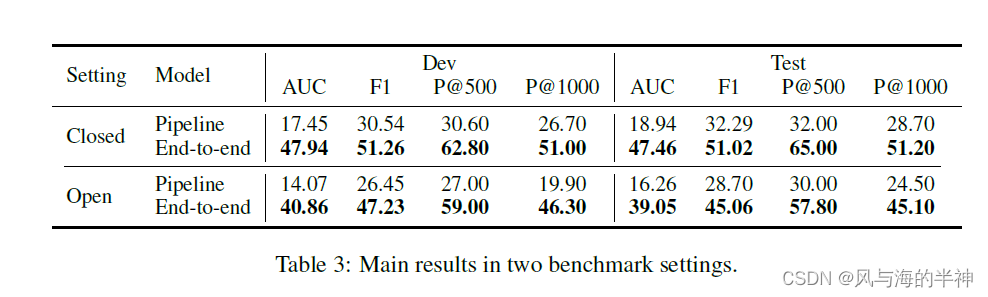
end-to-end效果更好。
一些想法
首先CodRED对比与DocRED而言,没有清晰的数据格式说明,看了github的数据,不太看得懂。比如下图,不太清楚前面字符的意思,是指文档编号吗。

然后对于该任务而言,跨文档关系抽取和智能问答/检索的差异性,因为给人感觉这两个任务是有一定的相似性的,文章说的不是很明确。
用CLS来表征实体对不太准确,会给模型带来噪音,因为CLS一般用于表征整个句子。
如何解决长尾依赖是个很大的问题。














 2097
2097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









