






论文阅读:Span-based Joint Entity and Relation Extraction with Transformer Pre-training
0. Summary
文章提出了SpERT,一种基于注意力机制的联合实体关系抽取模型。主要贡献有:
- 基于bert embedding的轻量级推理(?),可以实现实体识别、过滤。
- 通过局部,无标注的上下文表征,实现关系分类(无标注marker-free?)
- 采用强句间负样本(?),提高模型效率
- 在多个数据集上的联合实体关系抽取的F1得到了提高。
1. Research Objective
以bert为核心,同时进行实体和关系抽取。对于实体抽取:摒弃传统的BIO标注方法,采用基于跨度的方法(span based);对于关系抽取,假定关系出现在两个实体之间。由于bert训练的昂贵性,文章对每个句子只进行一次前向传播,并且在微调的时候只是加入浅层的分类器(相比较于其他深层模型而言)。
2. Background and Problems
联合实体关系抽取利用神经网络如RNN,CNN等。但是这些都依赖于预先标签,而文章中提出的模型则不依赖于预先标签。
对于联合实体关系抽取:
因为实体和关系之间往往相互之间影响,所以联合实体抽取可能效果更好。有学者将之转化为一个关系矩阵的填空,对角线为标签,其余元素为实体之间的关系。也有学者采用堆叠神经网络模型,首先用LSTM识别实体,然后用双向RNN对语义依存树进行分析,判断实体类别。但是关系有可能出现一对多的形式,这是这些模型没有考虑到的。也有采用注意力机制的联合实体关系抽取模型。也有利用bert作为核心的模型,利用QA抽取实体。
对于基于跨度的方法,由于传统的BIO标注无法解决交叠实体的问题,比如一个实体有多个标签。应用包括关联分析,语义角色标注,以及通过学习预测跨度而不是单个单词来改进LM。束搜索,与训练模型都可以和span结合起来。也有学者利用图传播来捕获span之间的交互。DyGIE++既利用了bert也利用和图模型,而本文的模型更简洁,不需要任何的图模型而是利用局部语义表征和负采样进行改进。
3. Method
模型如下所示:

模型结构:
1.输入text通过分割形成token,得到n个BPE token。BPE是指字节对编码,也可以叫做digram coding双字母组合编码,主要目的是为了数据压缩,算法描述为字符串里频率最常见的一对字符被一个没有在这个字符中出现的字符代替的层层迭代过程
2.经过BERT层得到(e1; e2; …en; c)(n+1)embedding向量,c是。
3.Span classficication(实体分类)
在模型图中的(a)部分,首先是选取一个span(ei; ei+1; … ei+k)(图中红色部分),然后用一个fusion函数融合在一起,此处选用的是maxpool最大池化的方法。然后在和width embeddings拼接起来。比如span中包含三个单词,那么选择width embeddings的第三个向量。蓝色的矩阵是通过反向传播学习到的。

输入到span classifier的向量最终x是:


最后通过一个softmax层得到分类结果
4.Span Filtering
就是将softmax分类后得到none类的过滤掉。并不对所有的实体/关系进行搜素,将实体和关系的长度控制在10个token以内。
5.Relation Classification 关系分类

关系分类器的输入包括两个部分
-
两个候选实体(红蓝色)。
-
由于整个句子的表达c(绿色)不太适合长句子对于多关系的表达,所以摒弃c。所以采用局部语义信息来进行关系分类,作者认为头实体的结束到尾实体的开始这一段span可以看做是关系(黄色部分)c(s1,s2)(虽然存在问题,但是效果较好)。考虑到逆关系的存在,所以关系分类的输入为

然后经过一个sigmoid函数,设置一个阈值,当分数大于这个阈值的时候,可以认为这个关系时成立的(但如何判断是哪种关系呢?,感觉像是二分类)【更正,并不是二分类,是对每个class进行阈值判断】
4. Training
参数及损失函数:
需要学习width embedding矩阵还有两个分类函数的w,b,以及bert的finetune。整个损失函数L = Ls + Lr包括实体分类损失和关系分类损失【更正:binary crossentropy可以用于多分类问题,通常需要在网络的最后一层添加sigmoid进行配合使用,其期望输出值(target)需要进行one hot编码】。
负采样:
-
对于实体识别,采用一定量的随机不含实体的span作为负样本。
-
对于关系识别,采用一定量的真正的实体但是实体之间没有关系作为负样本。相较于随机采样的实体对而言,这种强负样本采样很有用(?为什么呢)
负采样是如何使得效果提升的?
5. Experiments
数据集:
-
CoNLL04
-
SciERC
-
ADE:有重叠实体,只能被span based的方法识别,传统BIO不能识别。例如
结果:SOTA
消融实验:
负采样:

横轴代表Ne/Nr,Ne是实体负采样,Nr是关系负采样。从图中可以看出充足的负采样有利于提高F1,并且使得表现更加稳定。
局部语义特征:
与整个句子和用cls来对比:

随着token数量的增加,局部语义特征与其他方法的表现差距越大。
预训练:
BERT预训练是很重要的,fine-tune比train from scratch更好。还有实验分析了最大池化,平均池化,sum池化的效果。
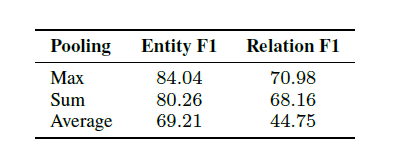
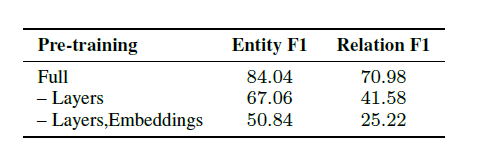
错误分析:
- 实体跨度错误,多一个单词或者少一个单词
- 没有关系的两个实体强行赋予关系
- 隐含关系挖掘困难(这个涉及到推理了吧)
- 关系分类错误
- ground truth标签缺失的问题。
6. References
1.David Wadden, Ulme Wennberg, Yi Luan, and Hannaneh Hajishirzi, ‘Entity, Relation, and Event Extraction with Contextualized Span Representations’, ArXiv, abs/1909.03546, (2019).基于图和BILSTM的抽取,本文就是从这篇文章衍生的。
2.Rico Sennrich, Barry Haddow, and Alexandra Birch, ‘Neural machine translation of rare words with subword units’, in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1715–1725, Berlin, Germany, (August 2016). Association for Computational Linguistics. BPE字节码,可以看一看
3.Kenton Lee, Luheng He, Mike Lewis, and Luke Zettlemoyer, ‘Endto- end Neural Coreference Resolution’, in Proc. of EMNLP 2017, pp. 188–197, Copenhagen, Denmark, (September 2017). ACL. Width Embedding的来源















 1215
1215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









