







任务介绍
什么是关系抽取(RE)?
以往的研究:从同一文本中抽取出的两个实体,分别作为头实体 (Peter Kappesser) 和尾实体 (U.S.) ,然后判别这两个实体之间是效忠关系 (allegiance)。
表现形式: (head entity, relation, tail entity) ——> e.g. (Peter Kappesser, allegiance, U.S.)
那么跨文档关系抽取(CodRE)其实指的是一个包中含有多个路径,每个路径有包含头实体和尾实体两篇文章,从中抽取头实体 (Peter Kappesser) 和尾实体 (U.S.) 是忠诚关系 (allegiance)。
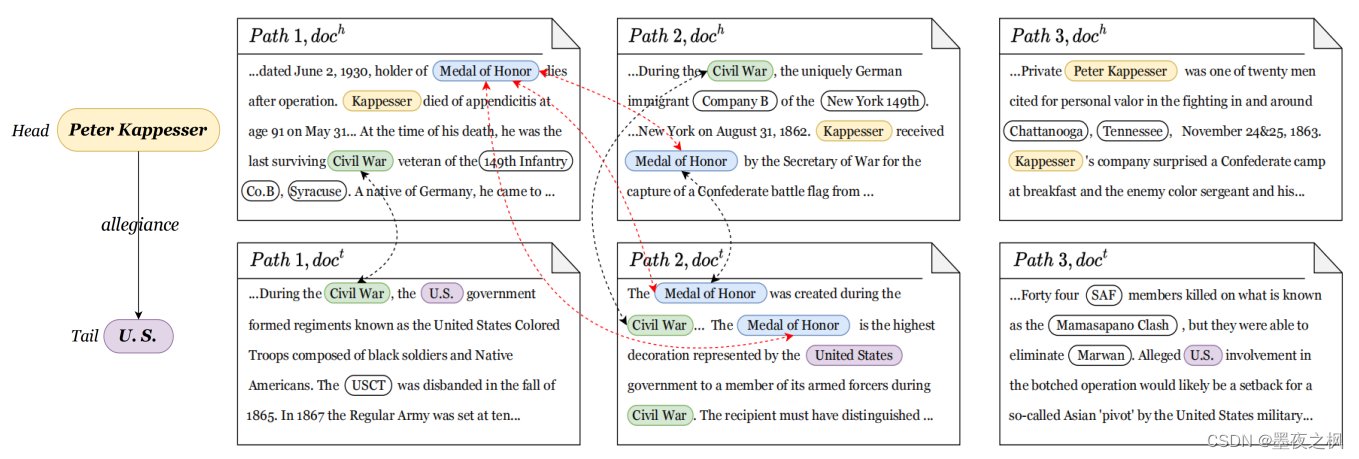
上面案例中 “Medal of Hornor” 和 “Civil War” 作为桥实体为不同的文本路径提供了一个额外的链接,帮助解释 “Peter Kappesser” 和 “U.S.” 之间的 “allegiance” 关系。
其中,CodRE是2019年清华刘知远实验室提出CodRED 数据集。
实现:首先检索相关文档,然后识别这些文档中的关键文本路径,最后进行关系推理。
但是跨文档关系抽取的研究中会遇到两个问题:
- 两个实体周围的非实体文本信息会引入许多不相关的上下文信息;
- 忽略了文本路径中重要的桥实体,导致跨文档关系抽取的部分信息的丢失。
包含桥实体的句子是推理目标实体之间关系的必要条件,缺少它们会严重影响推理过程。
在此基础上作者提出:Entity-based Cross-path Relation Inference Method (ECRIM)方法
- 应用一个基于实体的文档上下文过滤器来保留有用的上下文信息和桥实体;
- BERT编码器生成token级表示;
- 建立一个关系矩阵,用于捕获包中实体和关系之间的全局依赖关系,并输出所有文本路径的实体关系表示;
- 使用一个分类器来聚合这些表示,并预测头部和尾部实体之间的关系。
ECRIM模型
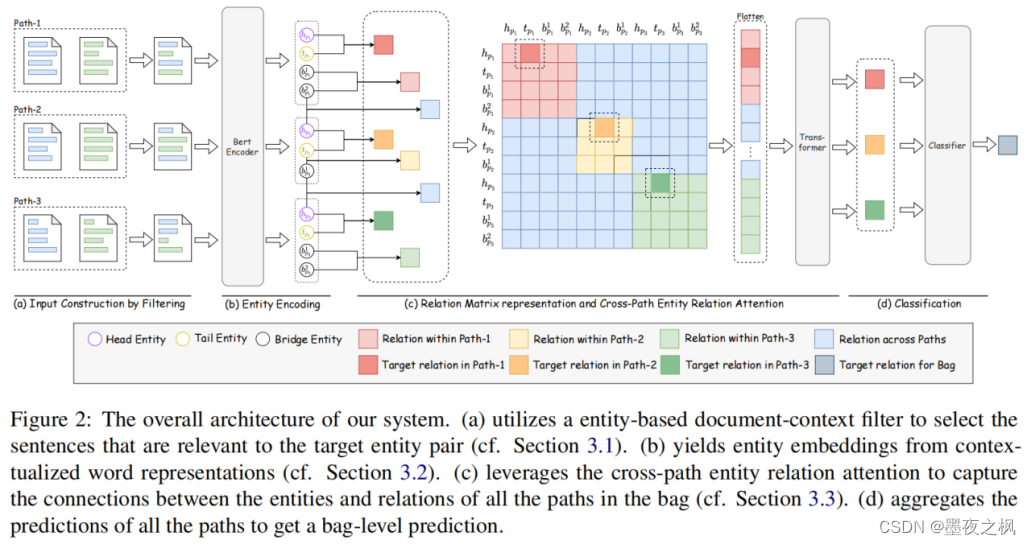
(a) Entity-based Document-context Filter
数据中的每一个文档长度过长,所以无法直接使用BERT处理。为了解决这个问题,作者提出了一个基于实体的文档上下文过滤器,在文档中为每个路径选择显著的句子。
每一个路径 p 都有一个由这个文本路径的两个文档(dh, dt) 共享的实体 Eb 的集合。Eb 包括头实体、尾实体、桥实体以及其他实体,其中桥实体可以作为推理头尾实体之间关系的链接并且可以作为衡量不同文本路径之间分布相似性的潜在指标。
具体实现:
① 根据它们的分数过滤掉一些句子,这些句子是由三个启发式条件计算出来的。
Direct co-occur (Γ1):桥实体是否在同一句子中与头/尾实体共现。
Indirect co-occur (Γ2):桥实体与另一个实体桥实体及头/尾实体共存共现。
Potential co-occur (Γ3):桥实体是否存在于其他文本路径中。
形式上,对于N个文本路径的包,我们为每个文本路径 pi 中的每个桥实体 eb 评分:
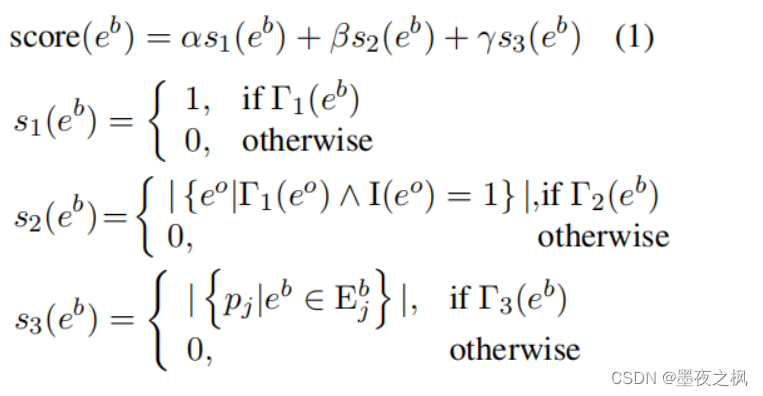
eo 和 eb 同时出现在同一个句子时 
eo 属于其他实体,pj 表示该包中的其他路径。
通过总结它所包含的桥实体的所有分数来计算每个句子的重要性分数
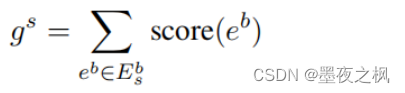
其中E-s-b表示句子 s 中的桥实体。
根据句子的重要性分数从大到小对句子进行排序,并选择前 K 个句子作为候选集:
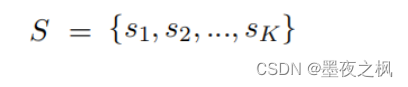
② 将过滤出来的句子再重新排序,目的是构建一个长度小于512的连贯文档。
具体实现:
从候选句子集 S 中获得信息最丰富的上下文 S*,用于推理目标实体之间的关系。
注意:如果序列 S* 的长度大于512,将删除相似度得分较低的句子,直到序列的长度满足 BERT 的要求。

(b) Encoder Module
在构建输入序列后,从每个文本路径中过滤句子集 S*,然后将 S* 中的句子连接在一起,构建模型的输入:
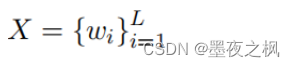
然后,我们利用BERT作为编码器来产生token表示:
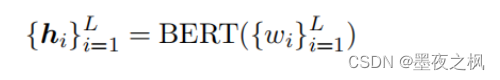
然后通过最大池化操作获得实体表示:

© Cross-Path Entity Relation Attention
Cross-path entity relation attention module based on the Transformer:捕获跨路径的关系之间的相互依赖关系。
具体实现:首先收集一个包中的所有实体提到表示,然后为实体对生成关系表示:

为了建模路径间关系之间的相互作用,建立了包级关系矩阵: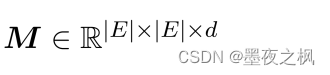
为了捕获路径内和路径间的依赖关系,利用了一个多层 transformer 对拉直的关系矩阵进行自注意: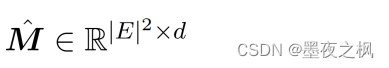
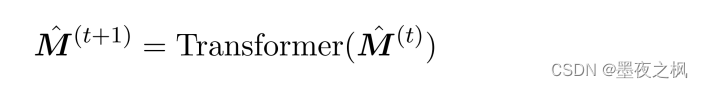
最后,我们从 transformer 的最后一层得到每个路径 pi 的目标关系表示r
(d) Classifier
使用 r 作为分类特征,并将其输入一个MLP分类器,以计算每个关系的得分:
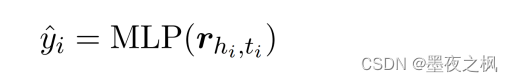
为了得到包级预测,我们在每个关系标签上使用最大池操作来得到每个关系类型的最终分数:
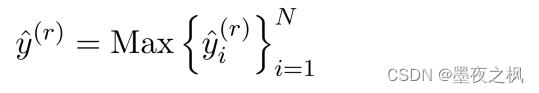
损失函数:
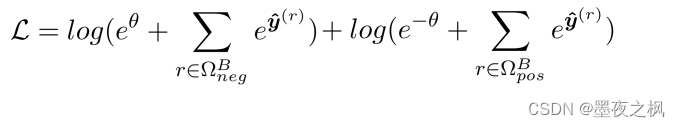
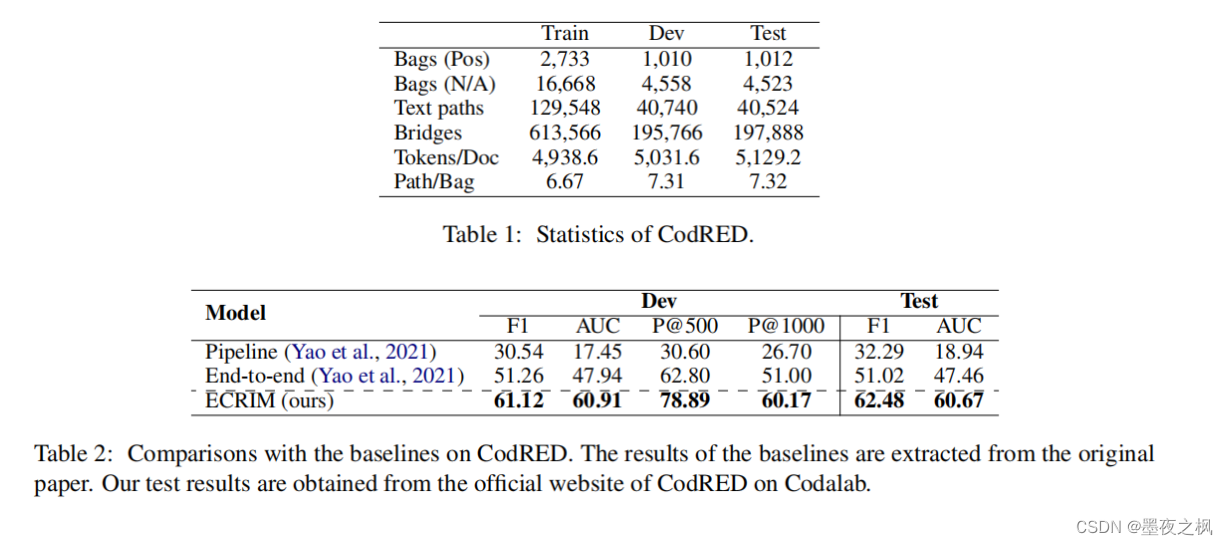
实验
CodRED数据集从英文维基百科中构建,涵盖276种关系类型。
总结
提出了一个基于实体的文档上下文过滤器来提取与跨文档检索的目标信息相关的重要片段。 关系预测中考虑了跨多个文本路径的全局依赖关系,并同时执行一个细粒度的推理过程。 实验结果表明,该方法大大提高了交叉文档关系提取的性能。
















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











