







模型训练中,不调用gpu比调用gpu更快的情况
背景
近来,跑语音情感识别和遗传算法的结合,需要大量的计算,一开始想着用gpu跑能快很多,结果发现调用gpu居然没有只用cpu更快。6代每代5个个体,合着总共30次训练,调用gpu居然比不调用gpu慢了接近一分钟。
不使用gpu:

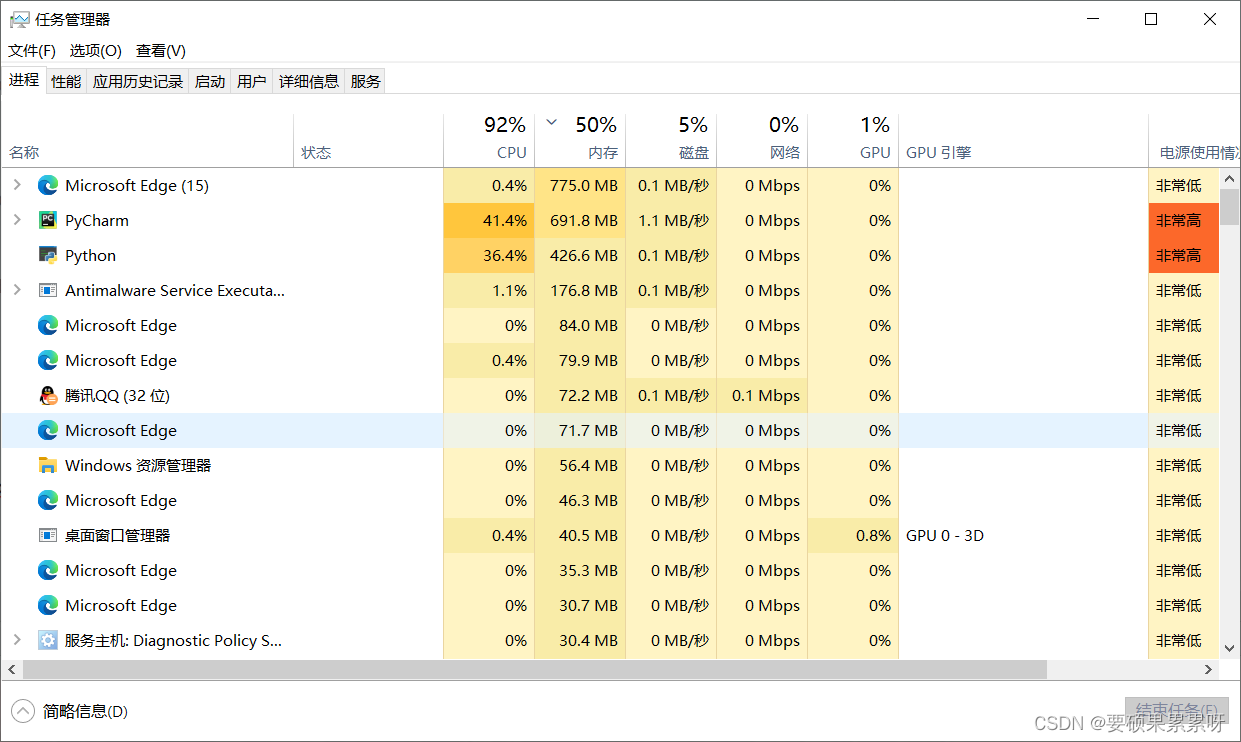
使用gpu:

原因
数据传输会有很大的开销,而GPU处理数据传输要比CPU慢,而GPU的专长矩阵计算在小规模神经网络中无法明显体现出来。
1.GPU擅长像卷积、填充的矩阵运算,常用于计算机视觉,在语音情感识别中没有太多卷积需要运算,导致时间短板在传输上,gpu节省的时间甚至没有弥补掉传输时间的损耗。
2.模型规模过小,看似和遗传算法相结合规模变大了。但是每一次单独训练的时间都是一样的,在计算时间上,遗传算法可以理解为多次运行同一个训练,即次数*单次训练时间。次数定好了,单次训练时间cpu>gpu.所以对整体来说使用cpu快于gpu。
个人实验测试
自己已经开启gpu的项目可以使用如下代码关闭gpu来进行对比:
import os
os.environ["CUDA_VISIBLE_DEVICES"]="-1" ###指定此处为-1即可
小规模神经网络模型(GPU比CPU慢)
#TensorFlow and tf.keras
import tensorflow as tf
#Helper libraries
import numpy as np
import matplotlib.pyplot as plt
from time import time
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
#用CPU运算
startTime1 = time()
with tf.device('/cpu:0'):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
t1 = time() - startTime1
#用GPU运算
startTime2 = time()
with tf.device('/gpu:0'):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
t2 = time() - startTime2
#打印运行时间
print('使用cpu花的时间:', t1)
print('使用gpu花的时间:', t2)
结果:
使用cpu花的时间: 52.422937631607056
使用gpu花的时间: 122.77410888671875
加深加宽隐藏层(GPU优势逐渐体现)
#TensorFlow and tf.keras
import tensorflow as tf
#Helper libraries
import numpy as np
import matplotlib.pyplot as plt
from time import time
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
#CPU运行
startTime1 = time()
with tf.device('/cpu:0'):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
t1 = time() - startTime1
#GPU运行
startTime2 = time()
with tf.device('/gpu:0'):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10)
model.evaluate(x_test, y_test)
t2 = time() - startTime2
#打印运行时间
print('使用cpu花的时间:', t1)
print('使用gpu花的时间:', t2)
结果:
使用cpu花的时间: 390.03080129623413
使用gpu花的时间: 224.40780639648438
补充
后来听师哥说,是语音模型调用调用gpu也会加快速度,怀疑是tensorflow而没用tensorflow-gpu原因。
但是tensorflow2.0以后不就是不区分gpu版本了,抱着试试看的态度,分别装了tensorflow2.80和tensorflow-gpu两个版本,结果没差。(但是以后以防万一,能按tensorflow-gpu尽量不要按tensorflow,毕竟多打三个字母又不费啥)
后来发现就是项目问题
一、如果加宽隐藏层,会减少时间。

二、同样看资源利用率
开启gpu是有一个python项目和pycharm来占用gpu的,只不过占用不多
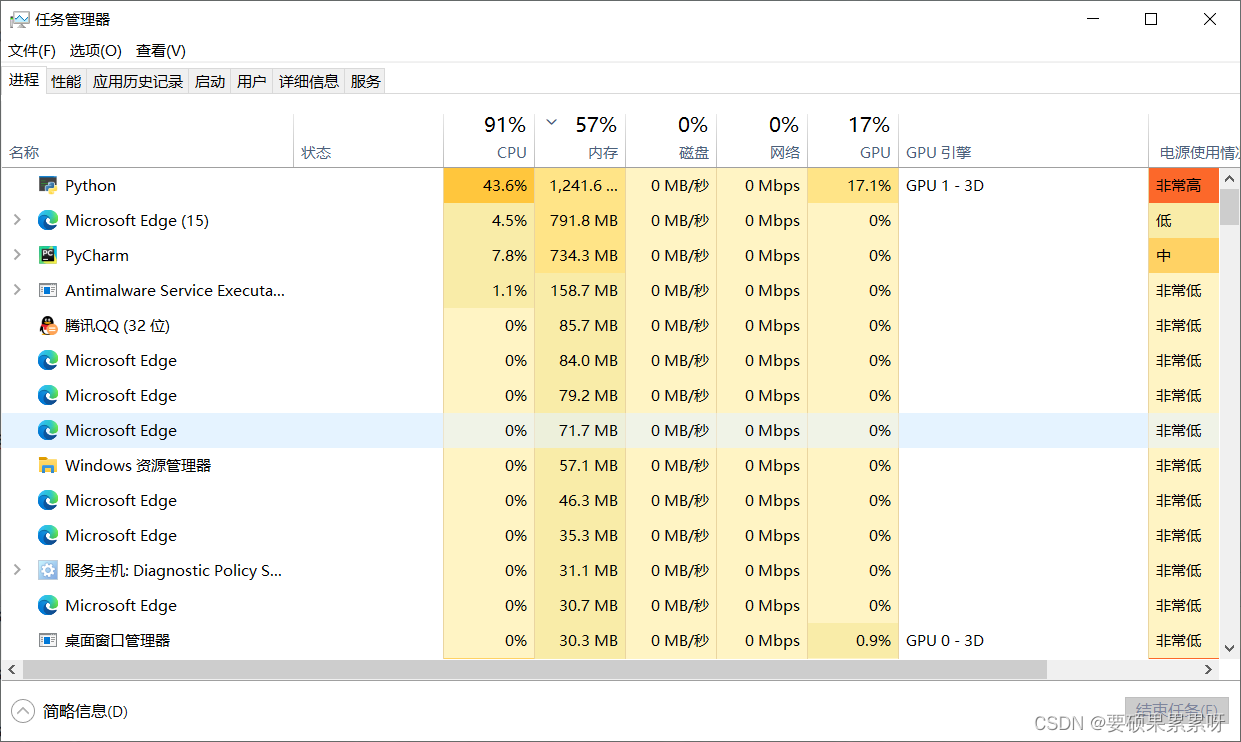
不开启gpu的话,python项目和pycharm一点gpu资源也没有















 6501
6501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









