







CPU的主要指标是主频和线程。
- Intel:后缀F表示无核显,后缀K代表可以超频,H代表移动端;
- AMD:后缀G代表有核显,后缀X代表加强版,后缀XT代表超级加强版。
CPU 常见计算操作:
数据加载、数据预处理、模型保存、loss 计算、评估指标计算、日志打印、指标上报、进度上报。
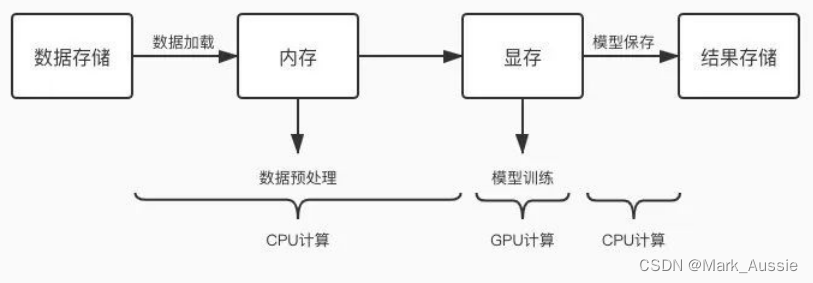
GPU任务处理流程
GPU 任务交替使用 CPU 和 GPU 进行计算,当 CPU 计算成为瓶颈时,GPU 会等待,GPU 利用率降低了。
GPU 性能主要依靠制程技术(nm)、GPU架构、线路设计、数字表示方式;
通常制程技术的进步只能让GPU的性能提高到原来的1.5或2倍,
GPU性能的提升主要是靠GPU架构和线路设计、数字表示方式的完善。
GPU的架构适合集群,GPU架构的更新同时更新集群方案。
- 计算量:即一个深度学习模型需要多少次计算才能完成一次前馈。
- 内存带宽:带宽影响计算速度,即GPU内存带宽是深度学习性能提升的主要瓶颈。
一般的算力评价指标:TFLOPS(具体分单精度、双精度、Tensor);
在硬件架构相同的条件下,核越来以及带宽越高,性能就越好。
影响GPU性能:
英特尔的 CPU 有AVX,一条指令可以做 512bit 的浮点操作,换算成32位浮点就是16个OPs,CPU 每个时钟周期可以做一次浮点乘加,相当于两个浮点运算,一个时间周期有 32 个FLOP,乘以 CPU 频率及核数,12 核,3GHz 的英特尔 CPU 运算性能 12 * 32 * 3G = 1152GFLOPS,论文显示 GPU 可达到 200GFLOPS,性能瓶颈并不在计算单元上,而是访存;CPU 的访存比GPU 大,只要 CPU 的访存能放得下,CPU 完全可能比GPU快。当访存放不下时,就要比较内存带宽,GPU 比 CPU快,对小规模数据,CPU 处理快,大规模数据,GPU 处理快。
数据加载问题:
1. 数据存储与计算资源间物理距离过远;
2. 数据存储介质导致读写能力不同,不同存储介质读写性能:SSD > ceph > cfs-1.5 > hdfs > mdfs
优化:将数据先同步到本机 SSD,读本机 SSD 训练。本机 SSD 盘为“/dockerdata”,可先将其他介质下的数据同步到此盘下进行测试,排除存储介质的影响。
3. 小文件太多,文件 io 耗时太长;多个小文件是不连续存储,读取会浪费很多时间在寻道上,
优化:将数据打包成大文件,如将许多图片文件转成一个 hdf5/pth/lmdb/TFRecord 等大文件。
4. 未启用多进程并行读取数据;未设置 num_workers 等参数或设置不合理,导致 cpu 性能为发挥,卡住 GPU;优化:设置 torch.utils.data.DataLoader 方法的 num_workers 参数、tf.data.TFRecordDataset 方法的 num_parallel_reads 参数或者 tf.data.Dataset.map 的 num_parallel_calls 参数。
5. 未启用提前加载机制来实现 CPU 和 GPU 的并行;未设置 prefetch_factor 等参数或设置不合理,使 CPU 与 GPU 串行,CPU 运行时 GPU 利用率直接掉 0;优化:设置 torch.utils.data.DataLoader 方法的 prefetch_factor 参数 或者 tf.data.Dataset.prefetch()方法。prefetch_factor 表示每个 worker 提前加载的 sample 数量,Dataset.prefetch() 方法的参数 buffer_size 一般设置为:tf.data.experimental.AUTOTUNE,由TensorFlow 自动选择合适数值。
6. 未设置共享内存 pin_memory;未设置 torch.utils.data.DataLoader 方法的 pin_memory 或者设置成 False,则数据需从 CPU 传入到缓存 RAM 里面,再传输到 GPU 上;优化,如内存富裕,可设置 pin_memory=True,直接将数据映射到 GPU 的相关内存块上,省掉一点数据传输时间。
数据预处理问题:
1. 数据预处理逻辑复杂;数据预处理部分超过一个 for 循环,都不予 GPU 训练放到一起;
优化:设置 tf.data.Dataset.map 的 num_parallel_calls 参数,提高并行度,一般设置为 tf.data.experimental.AUTOTUNE,由 TensorFlow 自动选择合适的数值。
将部分数据预处理挪出训练任务,如对图片的归一化操作,提前开启一个 spark 分布式任务或者 cpu 任务处理好,再进行训练。
提前将预处理部分需要用到的配置文件加载到内存中,不需要每次计算读取。
关于查询操作,多使用 dict 加速查询操作,减少 for、while 循环,降低预处理复杂度。
利用 GPU 进行数据预处理;Nvidia DALI 是专门用于加速数据预处理过程的库,既支持 GPU 又支持 CPU;采用 DALI,将基于 CPU 的数据预处理流程改造成用 GPU 来计算。
模型保存问题:
1. 模型保存频繁;模型保存为 CPU 操作,频繁操作会导致 GPU 等待。
指标问题:
1. loss 计算复杂;含有 for 循环的复杂 loss 计算,导致 CPU 计算时间长,阻塞 GPU,该用低复杂度的 loss 或者使用多进程或多线程进行加速。
2. 指标上报频繁;CPU 和 GPU 频繁切换导致 GPU 利用率低;可抽样上报,如每 100/step 上报
日志问题:
1. 日志打印频繁;日志打印操作太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低;使用抽样打印,如每 100/step 打印一次。
分布式任务中 GPU 利用率低问题
分布式任务相比单机任务多了机器间通信环节。如扩展到多机后出现 GPU 利用率低,运行速度慢等问题,很可能是机器间通信时间太长导致的,可检测如下几项:
1. 机器节点是否处在同一 modules:机器节点处于不同 modules 时,多机间通信时间会长很多,deepspeed 组件已从平台层面增加调度到同一 modules 的策略,用户不需要操作。
2、多机时是否启用 GDRDMA:能否启用 GDRDMA 与 NCCL 版本有关,PyTorch1.7 自带 NCCL2.7.8 时,启动 GDRDMA 失败,此为 NCCL 高版本 bug,可使用的运行注入的方式来修复;使用 PyTorch1.6 自带 NCCL2.4.8 时,能够启用 GDRDMA。NCCL2.4.8 + 启用 GDRDMA 比 NCCL2.7.8 + 未启用 GDRDMA 提升了 4%。设置 export NCCL_DEBUG=INFO,查看日志中是否出现[receive] via NET/IB/0/GDRDMA 和 [send] via NET/IB/0/GDRDMA,出现则说明启用 GDRDMA 成功,否则失败。

3、pytorch 数据并行是否采用 DistributedDataParallel:PyTorch 里的数据并行训练,涉及 nn.DataParallel (DP) 和nn.parallel.DistributedDataParallel (DDP) ,推荐使用 nn.parallel.DistributedDataParallel (DDP)。
参考:

















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









