






CRF(条件随机场)与Viterbi(维特比)算法原理详解
Data_driver 2019-04-17 10:36:52 4013 收藏 11
展开
摘自:https://mp.weixin.qq.com/s/GXbFxlExDtjtQe-OPwfokA
https://www.cnblogs.com/zhibei/p/9391014.html
CRF(Conditional Random Field),即条件随机场。经常被用于序列标注,其中包括词性标注,分词,命名实体识别等领域。
Viterbi算法,即维特比算法。是一种动态规划算法用于最可能产生观测时间序列的-维特比路径-隐含状态序列,特别是在马尔可夫信息源上下文、隐马尔科夫模型、条件随机场中
一、CRF基本概念
我们以命名实体识别NER为例,先介绍下NER的概念:

这里的label_alphabet中的b代表一个实体的开始,即begin;m代表一个实体的中部,即mid;e代表一个实体的结尾,即end;o代表不是实体,即None;和分表代表这个标注label序列的开始和结束,类似于机器翻译的和。

这个就是word和label数字化后变成word_index,label_index。最终就变成下面的形式:
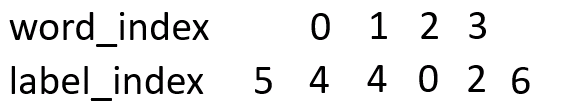
因为label有7种,每一个字被预测的label就有7种可能,为了数字化这些可能,我们从word_index到label_index设置一种分数,叫做发射分数emit:
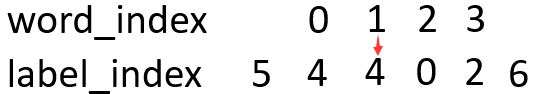
看这个图,有word_index 的 1 -> 到label_index 的 4的小红箭头,像不像发射过来的?此时的分数就记作emit[1][4]。
另外,我们想想,如果单单就这个发射分数来评价,太过于单一了,因为这个是一个序列,比如前面的label为o,那此时的label被预测的肯定不能是m或s,所以这个时候就需要一个分数代表前一个label到此时label的分数,我们叫这个为转移分数,即T:
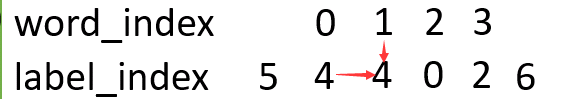
如图,横向的label到label箭头,就是由一个label到另一个label转移的意思,此时的分数为T[4][4]。
此时我们得出此时的word_index=1到label_index=4的分数为emit[1][4]+T[4][4]。但是,CRF为了全局考虑,将前一个的分数也累加到当前分数上,这样更能表达出已经预测的序列的整体分数,最终的得分score为:
score[1][4] = score[0][4]+emit[1][4]+T[4][4]
所以整体的score就为:
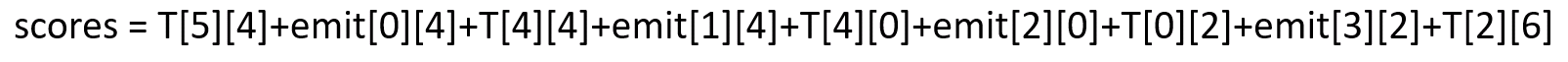
最后的公式为这样的:
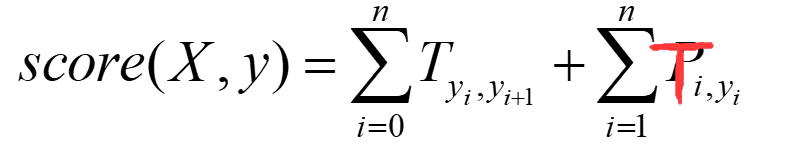
其中X为word_index序列,y为预测的label_index序列。
因为这个预测序列有很多种,种类为label的排列组合大小。其中只有一种组合是对的,我们只想通过神经网络训练使得对的score的比重在总体的所有score的越大越好。而这个时候我们一般softmax化,即:
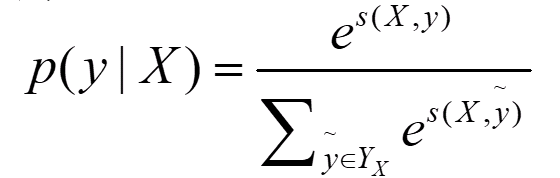
其中分子中的s为label序列为正确序列的score,分母s为每中可能的score。
这个比值越大,我们的预测就越准,所以,这个公式也就可以当做我们的loss,可是loss一般都越小越好,那我们就对这个加个负号即可,但是这个最终结果手机趋近于1的,我们实验的结果是趋近于0的,这时候log就派上用场了,即:

当然这个log也有平滑结果的功效。
二、计算过程
就是为了求得所有预测序列可能的得分和。我们第一种想法就是每一种可能都求出来,然后累加即可。可是,比如word长为10,那么总共需要计算累加10^7次,这样的计算太耗时间了。那么怎么计算的时间快呢?这里有一种方法:

因为刚开始为即为5,然后word_index为0的时候的所有可能的得分,即s[0][0],s[0][1]…s[0][6]中间的那部分。然后计算word_index为1的所有s[1][0],s[1][1]…s[1][6]的得分,这里以s[1][0]为例,即红箭头的焦点处:这里表示所有路径到这里的得分总和。

这里每个节点,都表示前面的所有路径到当前节点路径的所有得分之和。所以,最后的s[4][6]即为最终的得分之和,即:
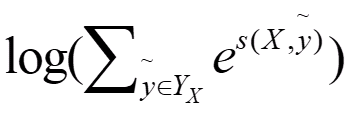
计算gold分数,即:S(X,y) 这事只要通过此时的T和emit函数计算就能得出,计算公式上面已经给出了:
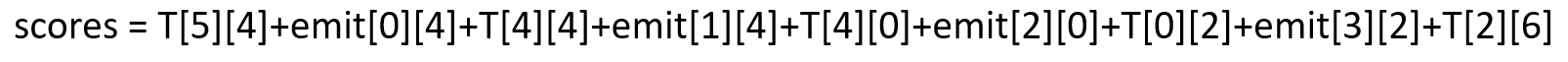
然后就是重复上述的求解所有路径的过程,将总和和gold的得分都求出来,得到loss,然后进行更新T,emit即可。(实现的话,其实emit是隐层输出,不是更新的对象,之后的实现会讲)
解码过程,就是动态规划,但是在这种模型中,通常叫做维特比算法。如图:

大概思路就是这次的每个节点不是求和,而是求max值和记录此max的位置。就是这样:

最后每个节点都求了出来,结果为:

最后,根据最后的节点,向前选取最佳的路径。过程为:、















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









