







Beam search搜索策略是贪心策略和穷举策略的一个折中方案,它在预测的每一步,都保留Top-k高概率的词,作为下一个时间步的输入。k称为beam size,k越大,得到更好结果的可能性更大,但计算消耗也越大。请注意,这里的Top-k高概率不仅仅指当前时刻的ytyt的最高概率,而是截止目前这条路径上的累计概率之和,如下图的公式所示。 举例如下,假设k=2k=2,第一个时间步保留Top-2的词为"he"和"I",他们分别作为下一个时间步的输入。“he"输入预测输出前两名是"hit"和"struck”,则"hit"这条路的累加概率是"he"的概率加上"hit"的概率=-1.7,类似的可以算出其他几个词对应路径的概率打分。最后在这4条路上保留k=2k=2条路,所以"hit"和"was"对应路径保留,作为下一个时间步的输入;"struck"和"got"对应路径被剪枝。
举例如下,假设k=2k=2,第一个时间步保留Top-2的词为"he"和"I",他们分别作为下一个时间步的输入。“he"输入预测输出前两名是"hit"和"struck”,则"hit"这条路的累加概率是"he"的概率加上"hit"的概率=-1.7,类似的可以算出其他几个词对应路径的概率打分。最后在这4条路上保留k=2k=2条路,所以"hit"和"was"对应路径保留,作为下一个时间步的输入;"struck"和"got"对应路径被剪枝。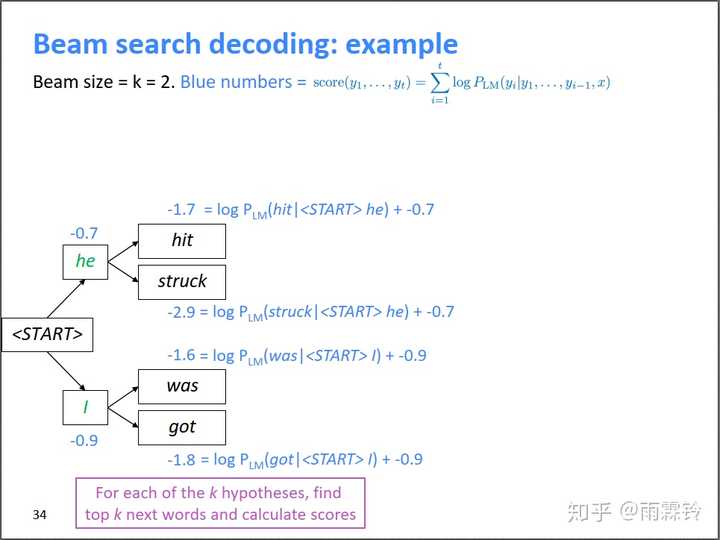 最终的搜索树如下图所示,可以看到在每个时间步都只保留了k=2k=2个节点往下继续搜索。最后"pie"对应的路径打分最高,通过回溯法得到概率最高的翻译句子。请注意,beam search作为一种剪枝策略,并不能保证得到全局最优解,但它能以较大的概率得到全局最优解,同时相比于穷举搜索极大的提高了搜索效率。
最终的搜索树如下图所示,可以看到在每个时间步都只保留了k=2k=2个节点往下继续搜索。最后"pie"对应的路径打分最高,通过回溯法得到概率最高的翻译句子。请注意,beam search作为一种剪枝策略,并不能保证得到全局最优解,但它能以较大的概率得到全局最优解,同时相比于穷举搜索极大的提高了搜索效率。 在beam search的过程中,不同路径预测输出结束标志符的时间点可能不一样,有些路径可能提前结束了,称为完全路径,暂时把这些完全路径放一边,其他路径接着beam search。beam search的停止条件有很多种,可以设置一个最大的搜索时间步数,也可以设置收集到的最多的完全路径数。当beam search结束时,需要从n条完全路径中选一个打分最高的路径作为最终结果。由于不同路径的长度不一样,而beam search打分是累加项,累加越多打分越低,所以需要用长度对打分进行归一化,如下图所示。那么,为什么不在beam search的过程中就直接用下面的归一化打分来比较呢?因为在树搜索的过程中,每一时刻比较的两条路径的长度是一样的,即分母是一样的,所以归一化打分和非归一化打分的大小关系是一样的,即在beam search的过程中就没必要对打分进行归一化了。
在beam search的过程中,不同路径预测输出结束标志符的时间点可能不一样,有些路径可能提前结束了,称为完全路径,暂时把这些完全路径放一边,其他路径接着beam search。beam search的停止条件有很多种,可以设置一个最大的搜索时间步数,也可以设置收集到的最多的完全路径数。当beam search结束时,需要从n条完全路径中选一个打分最高的路径作为最终结果。由于不同路径的长度不一样,而beam search打分是累加项,累加越多打分越低,所以需要用长度对打分进行归一化,如下图所示。那么,为什么不在beam search的过程中就直接用下面的归一化打分来比较呢?因为在树搜索的过程中,每一时刻比较的两条路径的长度是一样的,即分母是一样的,所以归一化打分和非归一化打分的大小关系是一样的,即在beam search的过程中就没必要对打分进行归一化了。
作者:知乎用户
链接:https://www.zhihu.com/question/54356960/answer/772392517
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 3257
3257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









