







Abstract
我们提出了一种无监督学习框架,用于从非结构化视频序列中估计单目深度和摄像机运动。与最近的工作[10,14,16]一样,我们使用端到端学习方法,将视图合成作为监督信号。与之前的工作相比,我们的方法是完全无监督的,只需要单目视频序列进行训练。我们的方法使用单视图深度和多视图姿态网络,使用计算的深度和姿态将附近的视图扭曲到目标上,从而造成损失。因此,网络在训练期间通过损失耦合,但可以在测试时独立应用。对KITTI数据集的经验评估证明了我们的方法的有效性:1)单目深度与使用真实姿态或深度进行训练的监督方法相比,2)在可比较的输入设置下,姿态估计与已建立的SLAM系统相比表现良好。
1. Introduction
即使在很短的时间尺度内,人类也能推断出自我运动和场景的3D结构。
例如,在街道上导航时,我们可以很容易地找到障碍物,并迅速做出反应以避开它们。几何计算机视觉的多年研究未能为现实世界场景(例如,存在非刚性,遮挡和缺乏纹理的场景)重建类似的建模能力。那么,为什么人类擅长这项任务呢?一种假设是,我们通过过去的视觉经验对世界形成了丰富的、结构性的理解,这些经验主要包括四处走动和观察大量的场景,并对我们的观察结果建立一致的模型。从数百万次这样的观察中,我们已经了解了世界的规律——道路是平的,建筑物是直的,汽车是由道路支撑的等等,我们可以在感知新场景时应用这些知识,即使是从单个单目图像。
在这项工作中,我们通过训练一个模型来模拟这种方法,该模型观察图像序列,旨在通过预测可能的相机运动和场景结构来解释其观察结果(如图1所示)。我们采用端到端方法,允许模型直接从输入像素映射到自我运动的估计(参数化为6自由度变换矩阵)和底层场景结构(参数化为参考视图下的逐像素深度图)。我们特别受到先前工作的启发,该工作建议将视图合成作为度量[44],以及最近在端到端框架中处理校准的多视图3D情况的工作[10]。我们的方法是无监督的,可以简单地使用图像序列进行训练,而无需手动标记甚至相机运动信息。
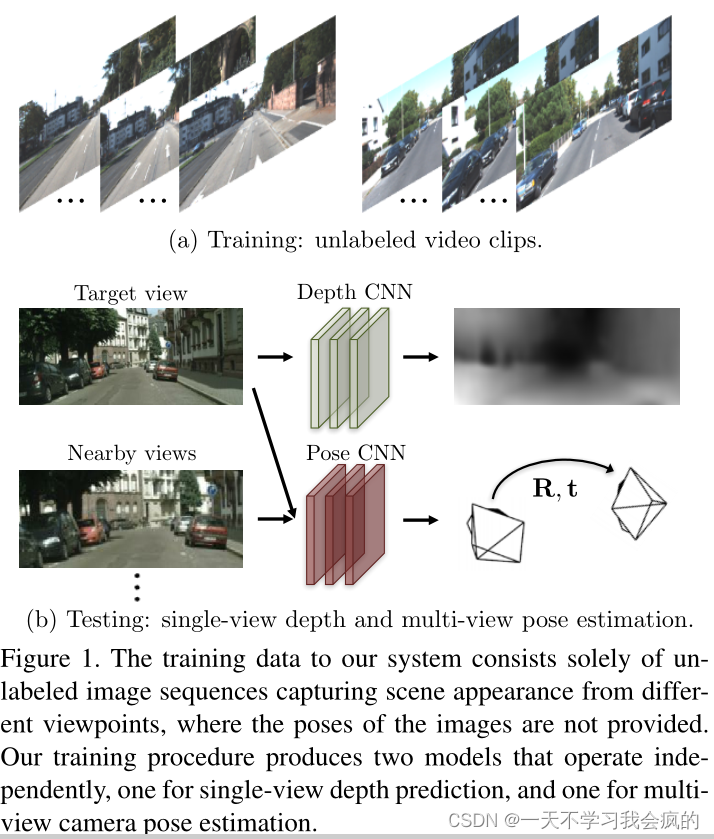
图1 我们系统的训练数据仅由未标记的图像序列组成,这些图像序列从不同的角度捕获场景外观,其中不提供图像的姿势。我们的训练过程产生了两个独立运行的模型,一个用于单视图深度预测,另一个用于多视图相机姿态估计。
我们的方法建立在这样一种见解之上,即几何视图合成系统只有在其对场景几何和相机姿势的中间预测与物理地面相对应时才能始终表现良好。虽然不完美的几何和/或姿态估计可以欺骗某些类型场景(例如,无纹理)的合理合成视图,但当呈现另一组具有更多样化布局和外观结构的场景时,相同的模型将惨败。因此,我们的目标是将整个视图合成管道作为卷积神经网络的推理过程,这样,通过在大规模视频数据上训练网络来完成视图合成的“元”任务**,网络被迫学习深度和相机姿态估计的中间任务,以便对视觉世界做出一致的解释**。在KITTI[15]基准上的经验评估证明了我们的方法在单视图深度和相机姿态估计上的有效性。我们的代码将在https://github.com/tinghuiz/SfMLearner上提供。
2. Related work
Structure from motion
结构和运动的同时估计是一个研究得很好的问题,已经建立了一系列技术工具链[12,50,38]。虽然传统的工具链在许多情况下是有效和高效的,但它对精确图像对应的依赖可能会在低纹理、复杂几何/光度、薄结构和遮挡等领域造成问题。为了解决这些问题,最近已经使用深度学习解决了几个管道阶段,例如特征匹配[18],姿态估计[26]和立体[10,27,53]。这些基于学习的技术很有吸引力,因为它们能够在训练期间利用外部监督,并且在应用于测试数据时可能克服上述问题。
Warping-based view synthesis
几何场景理解的一个重要应用是新视图合成任务,其目标是合成从新摄像机视点看到的场景外观。视图合成的一个经典范例是首先明确估计底层3D几何或在输入视图之间建立像素对应关系,然后通过合成来自输入视图的图像补丁来合成新的视图(例如,[4,55,43,6,9])。最近,端到端学习已被应用于通过基于深度或流量转换输入来重建新的视图,例如DeepStereo [10], Deep3D[51]和Appearance Flows[54]。在这些方法中,底层几何分别由量化深度平面(DeepStereo)、概率视差图(Deep3D)和视相关流场(Appearance Flows)表示。与直接从输入视图映射到目标视图的方法(例如,[45])不同,基于翘曲的方法被迫学习几何和/或对应的中间预测。在这项工作中,我们的目标是从cnn训练中提取这种几何推理能力,以执行基于翘曲的视图合成。
Learning single-view 3D from registered 2D views
我们的工作与最近一系列关于从注册的2D观测中学习单视图3D推断的研究密切相关。Garg等人[14]提出使用投影误差学习单视图深度估计CNN到校准的立体孪生体进行监督。
同时,Deep3D[51]使用立体电影片段作为训练数据,从输入图像中预测第二个立体视点。Godard等人[16]采用了类似的方法,增加了左右一致性约束,以及更好的架构设计,从而获得了令人印象深刻的性能。与我们的方法一样,这些技术只从对世界的图像观察中学习,而不像需要明确训练深度的方法,例如[20,42,7,27,30]。
这些技术与结构和运动估计的直接方法有一些相似之处[22],其中调整相机参数和场景深度以最小化基于像素的误差函数。然而,基于cnn的方法不是直接最小化误差来获得估计,而是对每批输入实例只采取梯度步骤,这使得网络可以从大量相关图像的语料库中学习隐式先验。一些作者已经探索了在他们的模型中构建可微分的渲染操作,例如[19,29,34]。
虽然上述大多数技术(包括我们的)主要集中在推断深度图作为场景几何输出,但最近的工作(例如,[13,41,46,52])也显示出基于类似射影几何原理从2D观测中学习3D体积表示的成功。Fouhey等人[11]进一步表明,利用场景规律性,甚至可以在没有3D标签(或注册的2D视图)的情况下学习3D推理。
Unsupervised/Self-supervised learning from video
我们的另一项相关工作是从视频中学习视觉表示,其总体目标是设计借口任务,从视频数据中学习通用的视觉特征,这些特征以后可以重新用于其他视觉任务,如对象检测和语义分割。这类借口任务包括自我运动估计[2,24]、跟踪[49]、时间相干性[17]、时间顺序验证[36]和目标运动掩模预测[39]。
虽然我们在这项工作中专注于推断明确的场景几何和自我运动,但直观地说,深度网络(尤其是单视图深度CNN)学习的内部表示应该捕获某种程度的语义,这些语义也可以推广到其他任务。
在我们工作的同时,Vijayanarasimhan等人[48]独立地提出了一个框架,用于从视频中联合训练深度、摄像机运动和场景运动。虽然这两种方法在概念上相似,但我们的方法侧重于无监督方面,而他们的框架增加了纳入监督的能力(例如,深度,相机运动或场景运动)。在训练过程中,场景动态建模的方式存在显著差异,在训练过程中,它们明确地解决了物体运动,而我们的可解释性掩盖了正在进行运动、遮挡和其他因素的区域。
3. Approach
在这里,我们提出了一个框架,用于从未标记的视频序列中联合训练单视图深度CNN和相机姿态估计CNN。尽管深度模型和姿态估计模型是联合训练的,但在测试时间推理中可以独立使用。我们模型的训练示例由移动摄像机捕获的场景的短图像序列组成。虽然我们的训练程序在某种程度上是稳健的运动,我们假设我们感兴趣的场景大多是刚性的,即场景在不同帧间的外观变化主要由摄像机的运动决定。
3.1. View synthesis as supervision
我们的深度和姿态预测cnn的关键监督信号来自于新视图合成任务:给定一个场景的输入视图,合成从不同相机姿态看到的场景的新图像。我们可以合成目标视图,给定该图像的每像素深度,加上附近视图中的姿态和可见性。正如我们接下来将展示的,这个合成过程可以用cnn作为几何和姿态估计模块以完全可微的方式实现。可见性可以与非刚性和其他非建模因素一起处理,使用“可解释性”掩码,我们稍后将讨论(第3.3节)。

注意,视图合成作为监督的想法最近也被用于学习单视图深度估计[14,16]和多视图立体[10]。然而,据我们所知,之前的所有工作都需要在训练期间(以及在DeepStereo的情况下的测试)姿态图像集,而我们的框架可以应用于没有姿态信息的标准视频。此外,它预测姿势作为学习框架的一部分。图2展示了深度和姿态估计的学习管道。
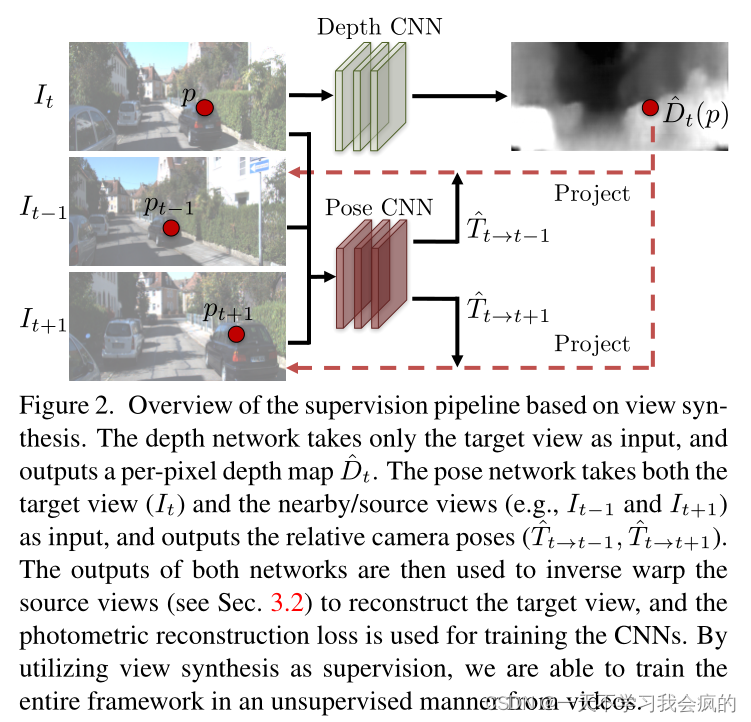
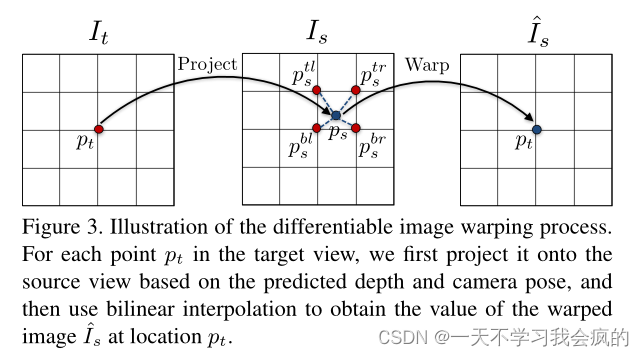
3.2. Differentiable depth image-based rendering


3.3. Modeling the model limitation
注意,当应用于单目视频时,上述视图合成公式隐含地假设1)场景是静态的,没有移动的物体;2)目标视图与源视图之间不存在遮挡/去遮挡;3)表面是朗伯曲面,因此光一致性误差是有意义的。如果在训练序列中违反了这些假设中的任何一个,梯度可能会被破坏,并可能抑制训练。为了提高我们的学习管道对这些因素的鲁棒性,我们额外训练了一个可解释性预测网络(与深度和姿态网络联合并同时),该网络为每个目标-源对输出一个逐像素的软掩码E,表明网络的信念在哪里直接观察合成将成功地为每个目标像素建模。根据预测的e值,对视图综合目标进行相应的加权
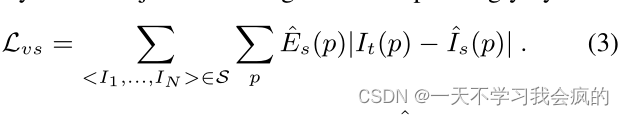
由于我们没有对e的直接监督,使用上述损失进行训练将导致网络的平凡解总是预测e为零,这完美地最小化了损失。为了解决这个问题,我们添加了一个正则化项Lreg(res),通过在每个像素位置上使用常数标签1最小化交叉熵损失来鼓励非零预测。换句话说,鼓励网络最小化视图综合目标,但允许一定的松弛来贴现模型未考虑的因素。
3.4. Overcoming the gradient locality
上述学习管道的一个遗留问题是,梯度主要来自I(pt)和I(ps)的四个邻居之间的像素强度差,如果正确的ps(使用ground-truth depth和pose投影)位于低纹理区域或远离当前估计,则会抑制训练。这是运动估计中一个众所周知的问题[3]。
根据经验,我们发现有两种策略可以有效地克服这个问题:1)使用卷积编码器-解码器架构,该架构具有深度网络的小瓶颈,该瓶颈隐含地约束输出全局平滑,并促进梯度从有意义的区域传播到附近的区域;2)明确的多尺度和平滑损失(例如,如[14,16]),允许直接从更大的空间区域导出梯度。我们在这项工作中采用了第二种策略,因为它对架构选择不太敏感。为了平滑,我们最小化了预测深度图的二阶梯度的L1范数(类似于[48])。

3.5. Network architecture
Single-view depth
对于单视图深度预测,我们采用了[35]中提出的disnet架构,该架构主要基于具有跳过连接和多尺度侧预测的编码器-解码器设计(见图4)。除预测层外,所有转换层之后都有ReLU激活,其中我们使用α = 10和β = 0.01的1/(α∗sigmoid(x) + β)来约束预测深度在合理范围内始终为正。我们还尝试使用多个视图作为深度网络的输入,但没有发现这可以改善结果。这与[47]中的观察结果一致,其中需要强制执行光流约束以有效地利用多个视图。
Pose
姿态估计网络的输入是与所有源视图连接的目标视图(沿着颜色通道),输出是目标视图和每个源视图之间的相对姿态。该网络由7个stride-2卷积组成,随后是一个具有6 * (N−1)输出通道的1 × 1卷积(对应于每个源视图的3个欧拉角和3- d平移)。最后,将全局平均池化应用于所有空间位置的汇总预测。除了最后一层没有应用非线性激活外,所有的转换层后面都有ReLU。
Explainability mask
可解释性预测网络与姿态网络共享前5个特征编码层,随后是5个具有多尺度侧预测的反卷积层。除没有非线性激活的预测层外,所有conv/deconv层后面都有ReLU。每个预测层的输出通道数为2 * (N−1),每两个通道通过softmax归一化以获得相应源-目标对的可解释性预测(归一化后的第二个通道为E,用于计算Eq. 3中的损失)。
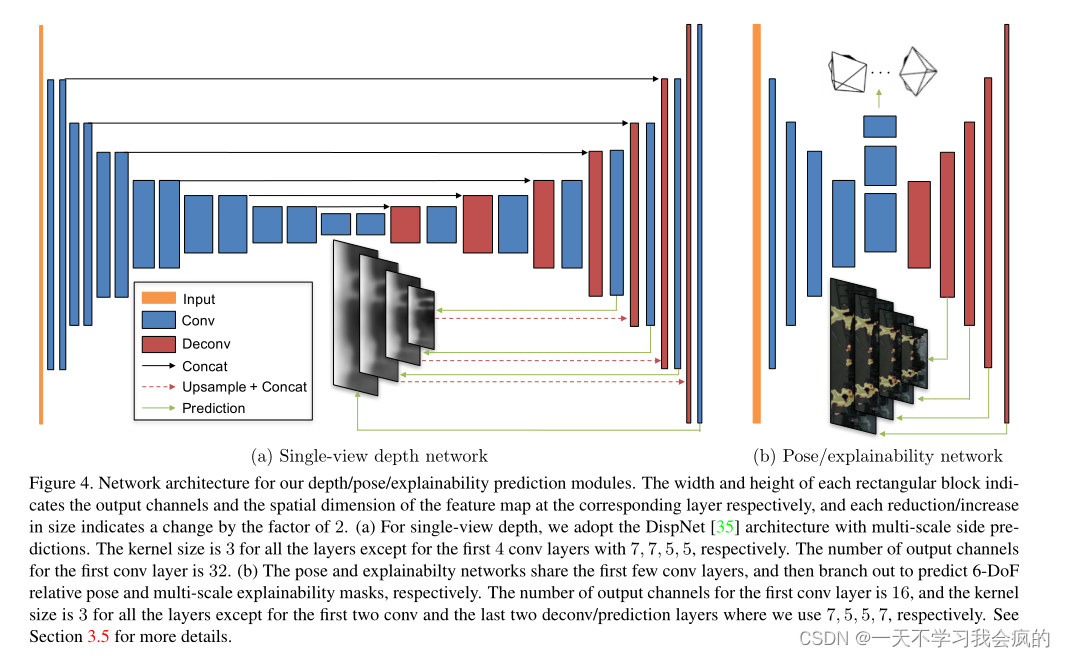
图4 深度/姿态/可解释性预测模块的网络架构。每个矩形块的宽度和高度分别表示对应层的输出通道和特征图的空间维度,大小每减少/增加一次表示变化2倍。(a)对于单视图深度,我们采用具有多尺度侧预测的disnet[35]架构。除了前4个conv层(分别为7,7,5,5)外,所有层的内核大小为3。第一转换层的输出通道数为32。(b)姿态和可解释性网络共享前几个转换层,然后分支分别预测6-DoF相对姿态和多尺度可解释性掩模。第一个conv层的输出通道数为16,所有层的内核大小为3,除了前两个conv和最后两个deconv/预测层,我们分别使用7,5,5,7。参见3.5节了解更多细节。
4. Experiments
在这里,我们评估了系统的性能,并与先前的方法在单视图深度和自运动估计方面进行了比较。我们主要使用KITTI数据集[15]进行基准测试,也使用Make3D数据集[42]评估跨数据集泛化能力。
Training Details
我们使用公开可用的TensorFlow[1]框架实现了该系统。对于所有实验,我们设置λs = 0.5/l (l为相应尺度的降尺度因子),λe = 0.2。在训练过程中,我们对除输出层外的所有层使用批归一化[21],并使用Adam[28]优化器,其β1 = 0.9, β2 = 0.999,学习率为0.0002,mini-batch size为4。训练通常在大约150K次迭代后收敛。所有的实验都是用单目摄像机拍摄的图像序列进行的。我们在训练期间****将图像大小调整为128 × 416,但深度和姿态网络都可以在测试时对任意大小的图像进行全卷积运行。
4.1. Single-view depth estimation
我们在[7]提供的分割上训练我们的系统,并从测试场景中排除所有帧以及平均光流量级小于1像素的静态序列进行训练。我们将图像序列的长度固定为3帧,并将中心帧作为目标视图,将±1帧作为源视图。我们使用两个彩色摄像机捕获的图像,但在形成训练序列时独立处理它们。结果总共有44,540个序列,其中40,109个用于训练,4,431个用于验证。
据我们所知,以前没有系统以无监督的方式从单目视频中学习单视点深度估计。尽管如此,我们还是比较了之前的深度监督方法[7]和最近使用校准立体图像(即姿势监督)的方法训练[14,16]。由于我们的方法预测的深度被定义为一个比例因子,因此为了进行评估,我们将预测的深度图乘以一个与中位数与真值相匹配的标量d s,即d s = median(Dgt)/median(Dpred)。
与[16]类似,我们也首先在更大的cityscape数据集上对系统进行预训练5,然后在KITTI上进行微调,这导致性能略有提高。

KITTI
在这里,我们评估了来自[7]的测试分割的697张图像的单视图深度性能。如表1所示,我们的无监督方法与几种有监督方法(如Eigen等人[7]和Garg等人[14])的表现相当,但与Godard等人[16]使用校正后的立体图像(即带有姿态监督)进行训练相比,我们的无监督方法表现不佳。对于未来的工作,看看将类似的循环一致性损失纳入我们的框架是否可以进一步改善结果,这将是很有趣的。图6提供了我们的结果与各种示例上的一些监督基线之间的可视化比较示例。可以看到,虽然以无监督的方式训练,但我们的结果与有监督的基线相当,有时可以更好地保留深度边界和薄结构,如树木和路灯。
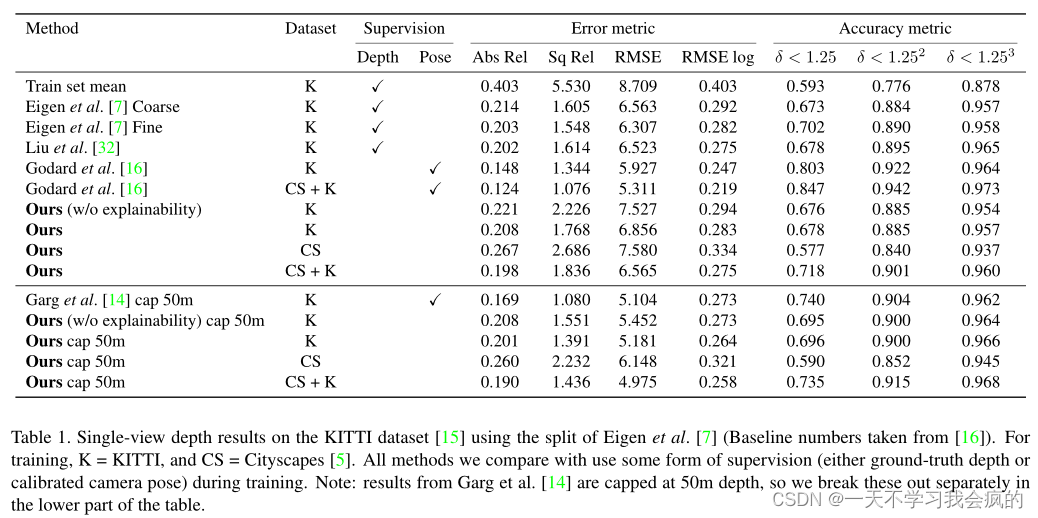

图6 Eigen等人7、Garg等人14和我们的(无监督)单视图深度估计的比较。为了可视化目的,从稀疏测量中插值地真深度图。最后两行显示了我们模型的典型失败案例,有时在巨大的开放场景和靠近相机前方的物体中挣扎。
我们在图7中展示了由初始cityscape模型和最终模型(在cityscape上进行预训练,然后在KITTI上进行微调)做出的样本预测。由于两个数据集之间的域差距,我们的cityscape模型有时难以恢复汽车/灌木丛的完整形状,并将它们与远处的物体混淆。















 2242
2242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









