







DEEP GRADIENT COMPRESSION:REDUCING THE COMMUNICATION BANDWIDTH FOR DISTRIBUTED TRAINING
顶会: ICLR,全称为「International Conference on Learning Representations」(国际学习表征会议)深度学习顶会
摘要
-
分布式SGD中99.9%的梯度交换是冗余的
-
Deep Gradient Compression (DGC) 深度梯度压缩方法减少通信带宽并且没有精度的损失,其包含一下四种方法:
- Momentum correction 动量修正
- Local gradient clipping 本地梯度裁剪
- Momentum factor masking 动量因子屏蔽
- Warm-up training 训练热身
前两个方法主要稀疏化梯度并维持模型的表现,后两个方法主要克服陈旧数据对梯度下降的影响
Introduce/Related Work
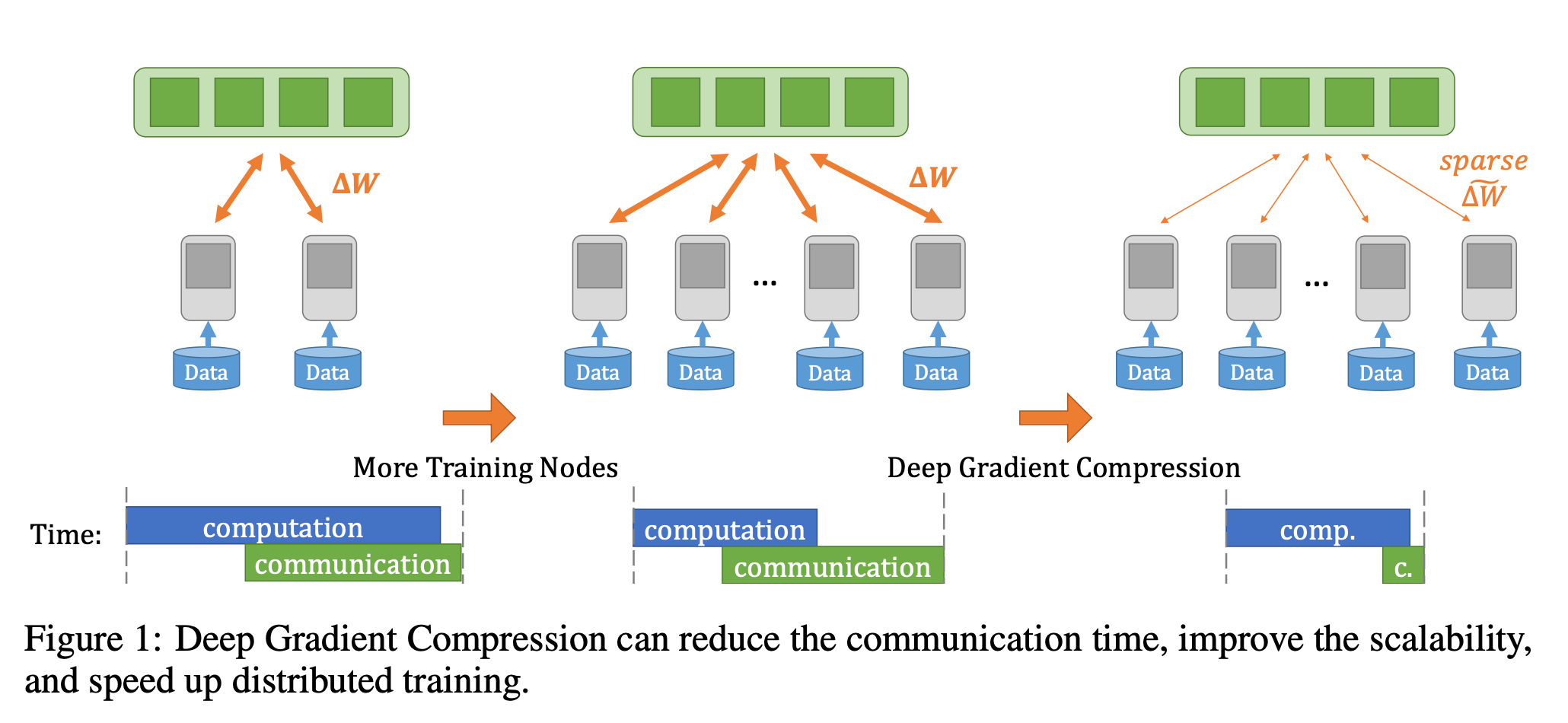
- 对比所有之前的梯度压缩方案,DGC的压缩比达到了600倍(所有层相同)
- DGC不需要额外的层规范化,因此不需要更改模型结构。
- DGC梯度压缩没有损失安全性
Deep Gradient Compression
Gradient Sparsification 梯度稀疏
只发送重要梯度(稀疏更新)来实现减少通信带宽
我们使用梯度大小作为重要程度的简单启发式: 只有梯度大于阈值的才可以发送.
为了避免信息损失,我们计算剩余的局部梯度,直到这些梯度成为一个较大的梯度(达到阈值)再发送
立即发送大的梯度, 小梯度累积发送, 但最终全部梯度都会发送,保证准确率

k: 节点k
G k G^k Gk: 节点k的梯度
M M M: 权重矩阵的个数
step 9: 分层阈值选择(hierarchical threshold selection)
step 10 ~ 12 : 动量因子遮蔽
⊙逐元素乘积(Hadamard乘积)它用两个具有相同维数的矩阵产生另一个具有相同维数的矩阵 作为操作数,其中每个元素i,j是原始两个矩阵的元素i,j的乘积
encode()函数打包了32位的非零梯度值和16位的0运行长度。
局部梯度累积相当于随着时间的推移增加批大小。
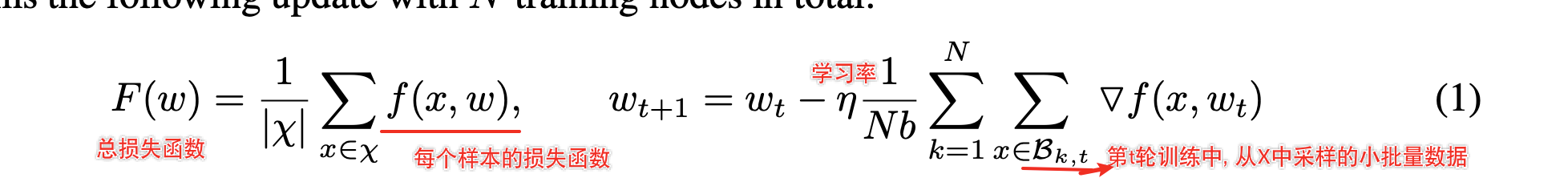
B k , t \Beta_{k, t} Bk,t是第 t t t次迭代中第 k k k个节点上读取的一个batch的数据样本,每个batch的大小为 b b b。
考虑到权重值 w ( i ) w^{(i)} w(i)在 w w w第i个位置,在第T轮迭代后,我们有:
w ( i ) w^{(i)} w(i)对应i层的权重矩阵
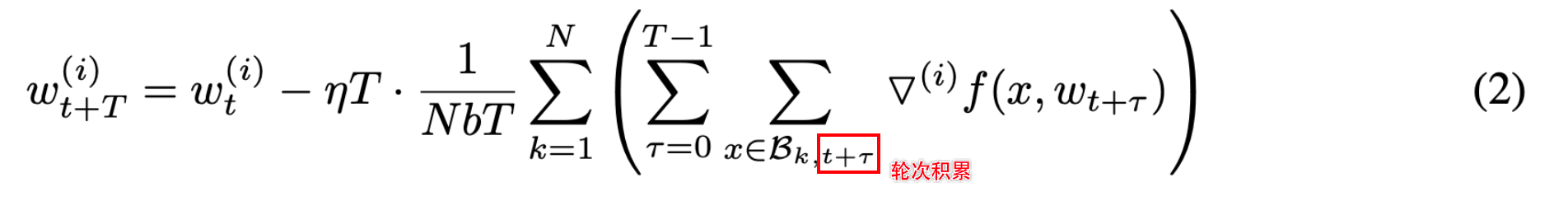
从公式中可以看出局部梯度积累可以看作是将批次量的大小从 N b Nb Nb增加到 N b T NbT NbT(对 τ \tau τ的二次求和), 其中 T T T是两次迭代之间的稀疏更新间隔的长度,即每进行 T T T次迭代就发送一次 w ( i ) w(i) w(i)的梯度
T T T: 当小梯度不满足时, 等待积累的时间间隔
学习率缩放是处理大量小批量下降的常用技术, η T \eta T ηT和 N b T NbT NbT中的 T T T将会自动抵消
同比率增大学习率让 T T T抵消?
Impoving the local gradient accumulation
如果不注意稀疏性,当稀疏度极高时,稀疏更新会极大地危害收敛
例如算法1导致了在数据集Cifar10中超过1%的精度损失,如下图:
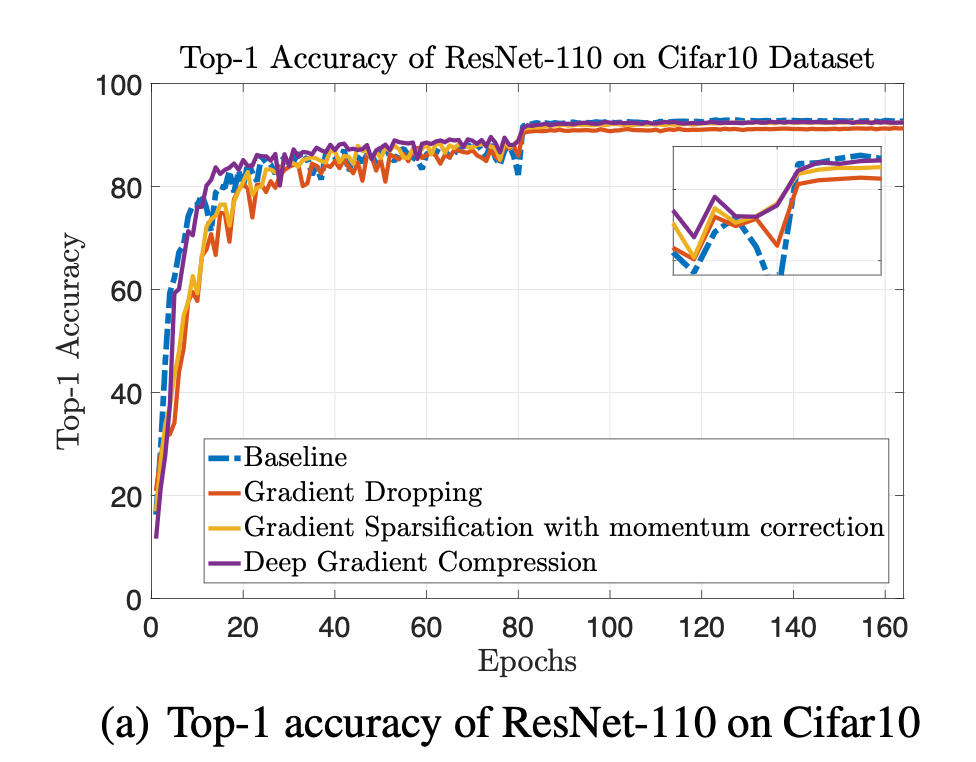
我们使用了动量修正和本地梯度裁剪方法来解决这个问题
1. Momentum Correction 动量修正
动量SGD(Momentum SGD:)被广泛用于代替普通SGD(vanilla SGD), 但是算法一(见上方)不直接适用于带有动量项的SGD,因为它忽略了稀疏更新间隔之间的折扣因子(discounting factor)
动量SGD Momentum SGD:
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
v t = ⋎ ⋅ v t − 1 + α ⋅ ∇ Θ J ( Θ ) v_t=\curlyvee \cdot v_{t-1} + \alpha \cdot \nabla_{\Theta}J(\Theta) vt=⋎⋅vt−1+α⋅∇ΘJ(Θ)
Θ = Θ − v t \Theta = \Theta - v_t Θ=Θ−vt
Momentum算法会观察历史梯度 v t − 1 v_{t-1} vt−1 ,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。**一种形象的解释是:**我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快, ⋎ \curlyvee ⋎可视为空气阻力,若球的方向发生变化,则动量会衰减。
N个节点的普通SGD的训练过程如下:
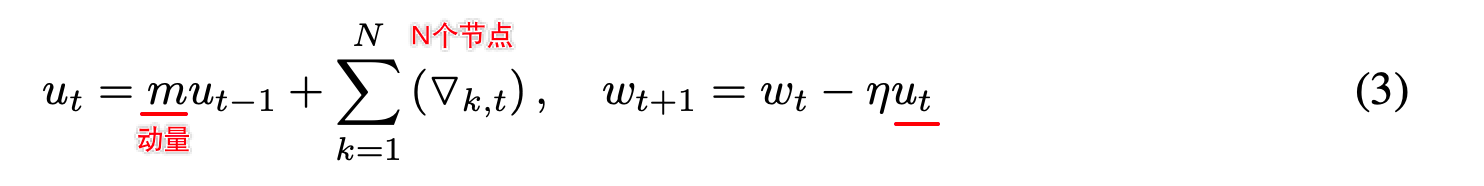
其中: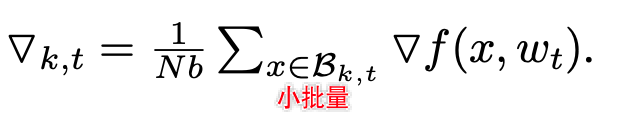
对比于上面的(1)式, 主要的改变就是增加了 m u t − 1 mu_{t-1} mut−1部分,使得梯度不断根据上一次迭代,如果与上次相同则m动量会加速梯度,反之减速
其 u t u_t ut为速度velocity
对于第i层位置的 w w w权重 w i w^{i} wi, 在 T T T迭代后,每个 w i w^{i} wi的改变为:
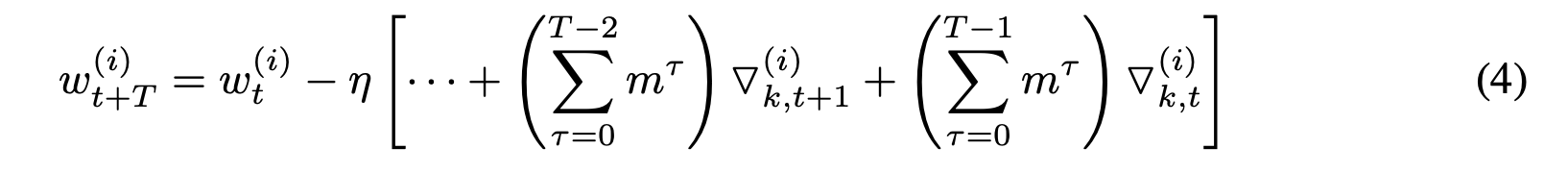
如果将带有动量的SGD直接应用于稀疏梯度情景: (算法(1)的第15行, 如下)
15 : w t − 1 ← S G D ( w t , G t ) 15: w_{t-1} \leftarrow SGD(w_t, G_t) 15:wt−1←SGD(wt,Gt)
那么更新规则不再等同于公式3:
首先节点k的多轮次积累小梯度公式为:
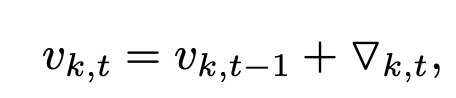
这一步就是与普通SGD的区别所在: 需要积累小梯度
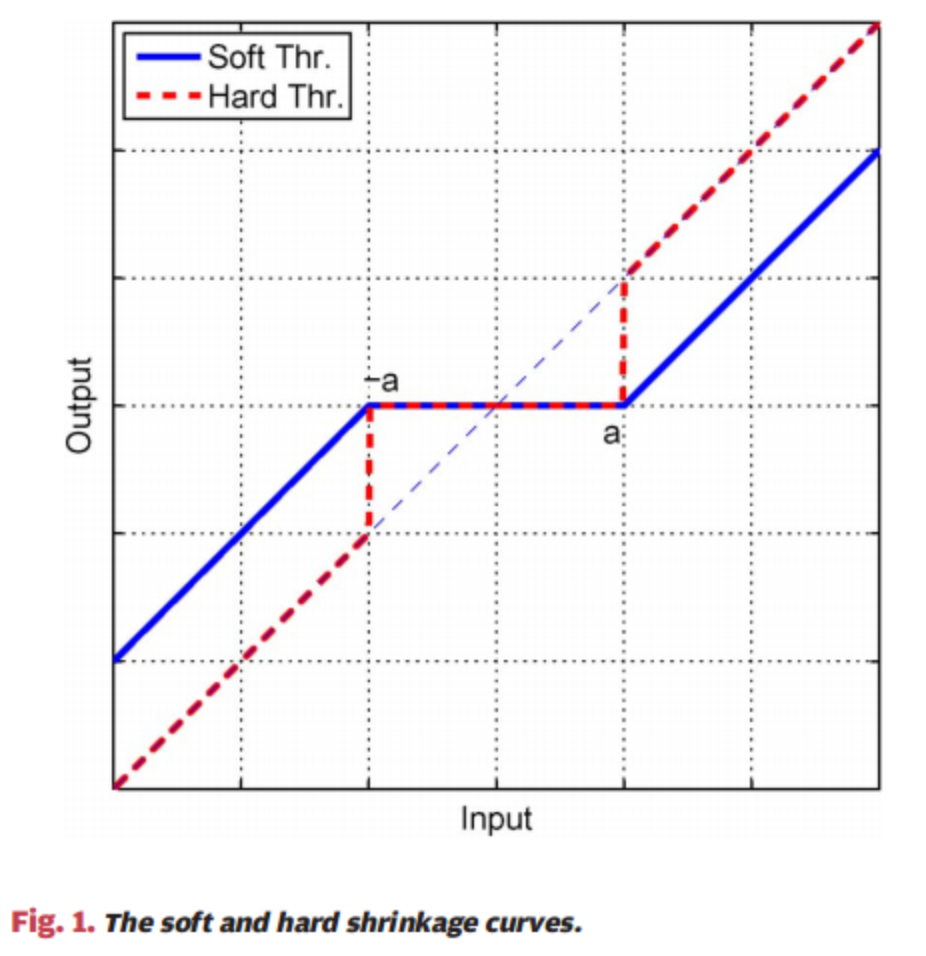
得到能够超过阈值的积累梯度: v k , t v_{k,t} vk,t, 它将在sparse()函数中通过硬阈值函数, 然后经过编码encode, 然后通过网络传递给第二部分:
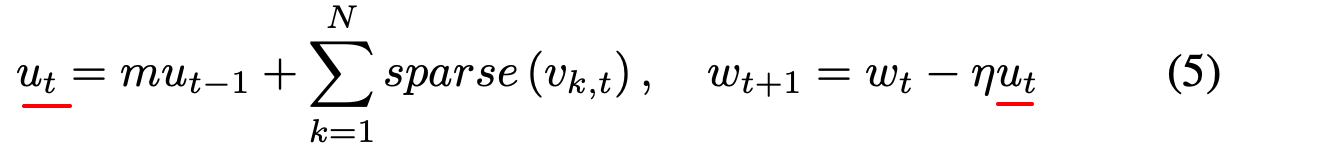
hard threshold function 硬阈值函数
https://blog.csdn.net/jbb0523/article/details/52103819
简单来说就是如下公式:
o u t p u t = { w ∣ w ∣ > λ 0 ∣ w ∣ < λ output = \begin{cases} w & |w| > \lambda \\ 0 & |w| < \lambda \end{cases} output={w0∣w∣>λ∣w∣<λ
接下来类似于算法(1)中的第12行:
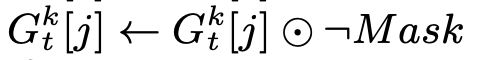
梯度积累结果 v k , t v_{k,t} vk,t被sparse()函数中的通过掩码被清空。
稀疏更新间隔T后权值w(i)的变化为:
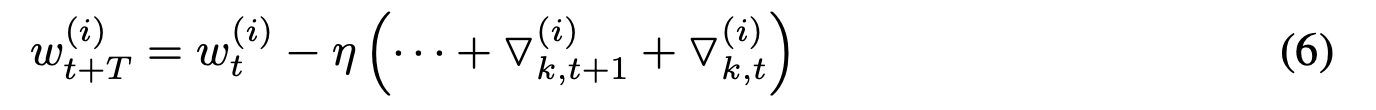
比较于公式(4)的区别在于取消掉了累积折扣因素 ∑ τ T − 1 m τ \sum_{\tau}^{T-1} m^\tau ∑τT−1mτ,导致收敛性能的损失
如图所示,公式(4)驱使从A到B的优化,但**随着局部梯度积累,**方程4到达点C
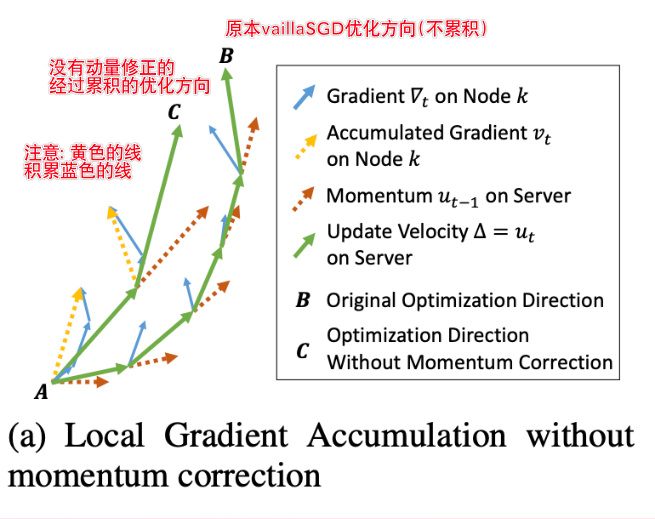
不使用动量修正的局部梯度梯度积累会导致改变最后的优化方向
注意: 棕色就是动量项的作用,保留了上一次绿色的方向,为这一次更新的方向(绿色)做出影响(模拟物理动量效果)
当梯度稀疏度较高时,更新间隔T显著增加,因此显著的副作用会损害模型性能。
图中A -> C应该是间隔了两个T, 如果间隔T越长那么这个偏离就越明显
为了避免这种错误,我们需要动量修正上方的公式(5), 确保稀疏更新等价于公式(3)中的密集更新
如果我们把公式(3)中的速度 u t u_t ut看作“梯度”, 那么公式(3)的第二项可以看作“梯度” u t u_t ut的普通SGD
局部梯度积累对3.1节中的普通SGD是有效的。
因此,我们可以在**局部累积速度 u t u_t ut,而不是实际梯度 ∇ k , t \nabla {k, t} ∇k,t**来迁移方程5以接近方程3:
!!!核心修改: 直接积累梯度会导致偏离问题(如上图), 所以不积累实际的梯度而是积累动量修正后的速度 u t u_t ut
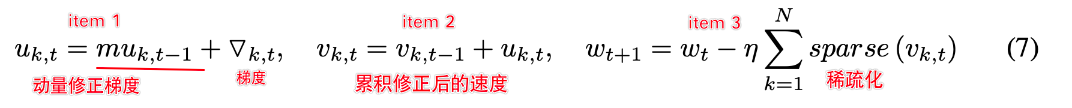
前两项是动量修正过的局部梯度积累, 积累结果用于后续的稀疏与通信. 通过这样简单的修改局部积累方式,我们能够推断出公式(7)包含公式(4)中的积累折扣因素 ∑ τ T − 1 m τ \sum_{\tau}^{T-1} m^\tau ∑τT−1mτ
从而不会导致类似图(a)那样的偏离
效果如下图所示:
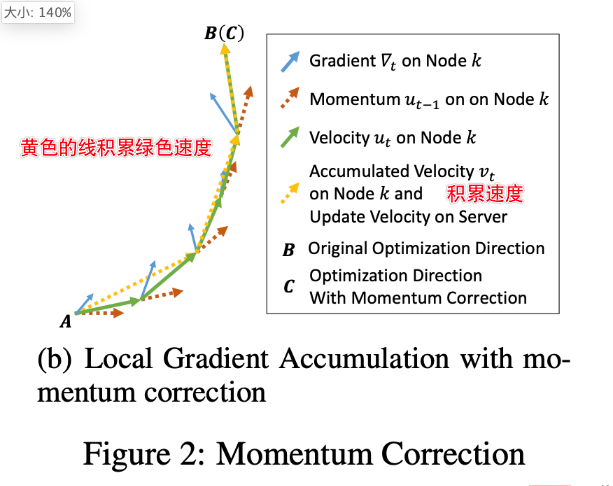
我们将这种迁移称之为monument correction动量修正,这是更新等式的一个微调,它不需要任何超参数。除了普通动量SGD,我们还在附录B中研究Nesterov动量SGD,它与动量SGD类似。
2. Local Gradient Clipping 本地梯度裁剪
为了避免梯度爆炸问题,梯度裁剪被广泛采用
该方法会在梯度的L2范数之和超过某一阈值时对梯度进行重缩放, 这一步通常在所有节点的梯度聚合之后执行。
训练全局模型过程中, 总体优化参数的时候进行
因为我们通过迭代在每个节点上独立地积累梯度, 所以我们在将当前梯度 G t G_t Gt添加到之前的累积(算法1中的 G t − 1 G_{t-1} Gt−1)之前执行本地梯度修剪
在附录C中介绍: 如果所有 N N N个节点具有相同的梯度分布,那么我们将阈值按 N − 1 2 N^{-\frac {1}{2}} N−21(当前节点占全局阈值的分数)缩放
在实践中,我们发现局部梯度裁剪的行为与训练中的普通梯度裁剪非常相似,这表明我们的假设可能在真实数据中有效。
梯度裁剪
用处: 防止梯度爆炸, 需要梯度裁剪,避免模型越过最优点。

正如我们在第4节中看到的,动量校正和本地梯度裁剪有助于将AN4语料库上的单词错误率从14.1%降低到12.9%,而训练曲线与动量SGD更接近。
Overcome the staleness effect 处理旧数据影响
因为我们延迟了小梯度的更新,当这些更新发生时,它们就过时了。
在我们的实验中,当梯度稀疏度为99.9%时,大多数参数每600到1000次迭代更新一次,这与每个epoch的迭代次数相比是相当长的时间。过时会降低收敛速度,降低模型性能。我们用动量因子掩蔽和热身训练来缓解旧数据影响。
过时: 累积小梯度的过程如果太慢(小梯度每一步都太小)会是相当长的时间, 从而会降低模型的性能
过慢的原因很可能是已经过时的小梯度的动量让梯度下降缓慢
Momentum Factor Masking 动量因子遮蔽
Mitliagkas等人(2016)讨论了由异步引起的陈旧梯度,并将其归结为一个术语,称为隐性动量。
受其激发我们提出了动量因子遮蔽,来缓和旧梯度影响
我们没有像Mitliagkas等人建议的那样寻找新的动量系数,而是简单地对公式(7)中的累积梯度 v k , t v_{k,t} vk,t和动量因子 u k , t u_{k,t} uk,t应用相同的掩模:
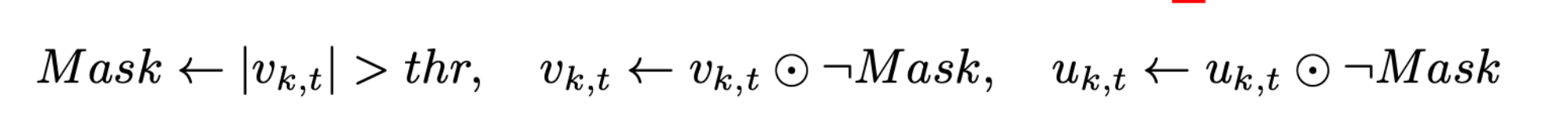
效果: 这个遮罩阻止延迟梯度的动量,防止陈旧的动量携带权重(weight)在错误的方向。
这部分原理描述较少, 还不是很明白…
Warm-up Training 热身训练
在训练的早期阶段,网络正在迅速变化,梯度更加多样化和激进(变化大)。稀疏梯度限制了模型的变化范围,从而延长了网络剧烈变化的周期。
同时,前期剩余的激进梯度在被选择为下一次更新之前被累积,因此可能会超过最新的梯度,从而误导优化方向。
在大型小批量训练中引入的热身训练方法(Goyal, 2017)是有帮助的。
在热身阶段,我们使用较低的激进性学习率来减缓神经网络在训练开始时的变化速度,并使用较低的激进性梯度稀疏性来减少被延迟的极端梯度的数量。
我们不是在前几个时期线性地提高学习率,而是指数地增加梯度稀疏度,从一个相对较小的值到最终的值,以帮助训练适应更大的稀疏度梯度。
前期变化大的梯度会导致网络剧烈化变化, 积累的话可能会超过最新的梯度,影响训练
所以使用指数型的梯度稀疏(包括前期使用较低学习率、减少稀疏性即增大累积速度)从而降低前期极端梯度的影响
稀疏度越来越高,最终稀疏度大于线性
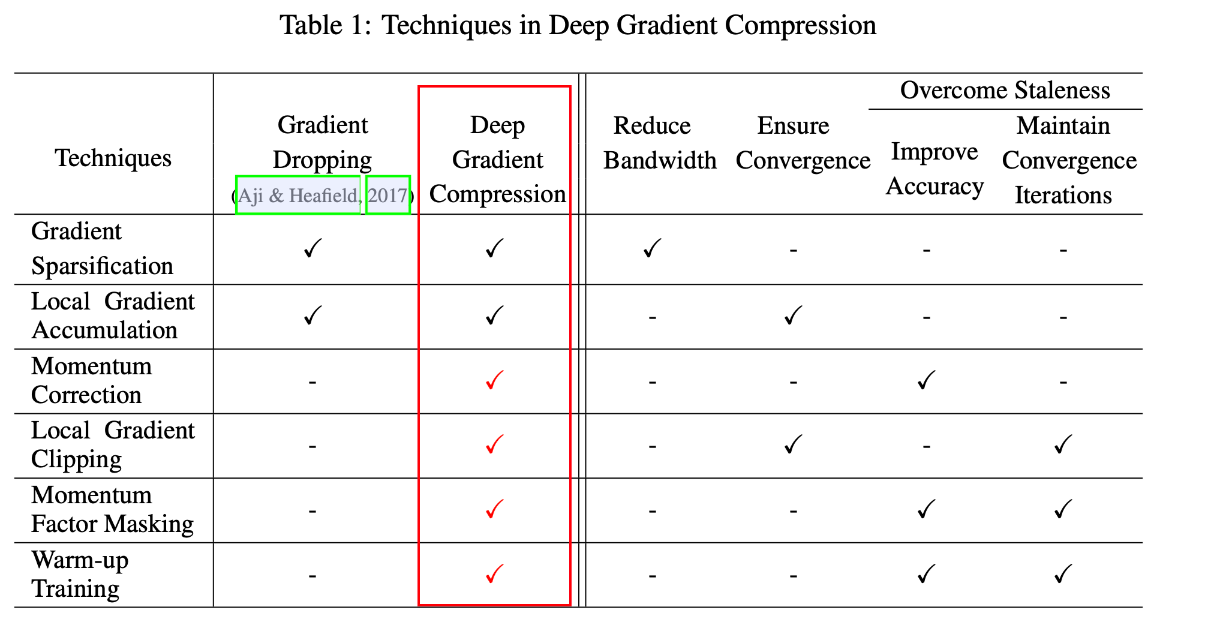
通过以上四种方法实现了DGC良好的性能, 对比表格如下:
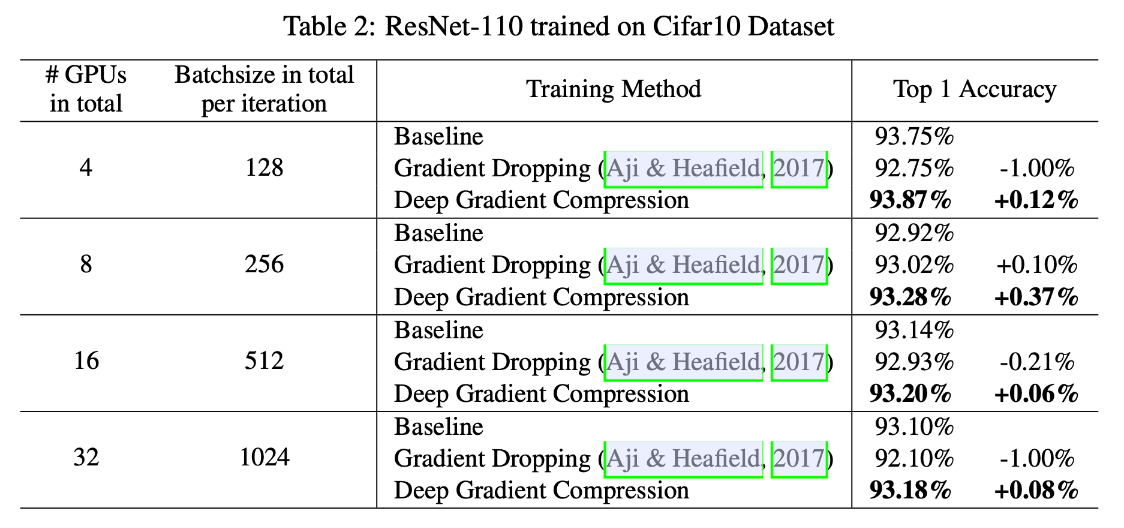
Experiments 实验效果、System Analysis and Performancemance
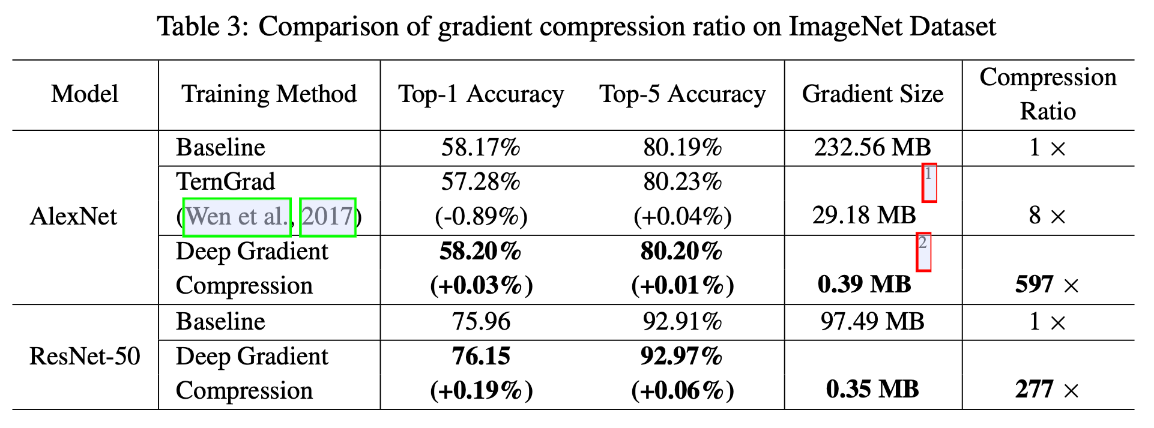
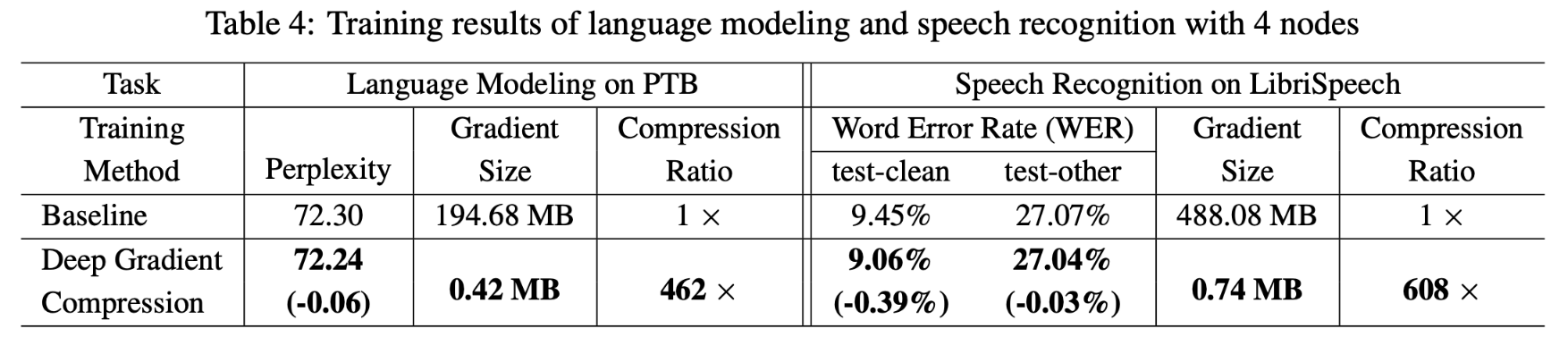
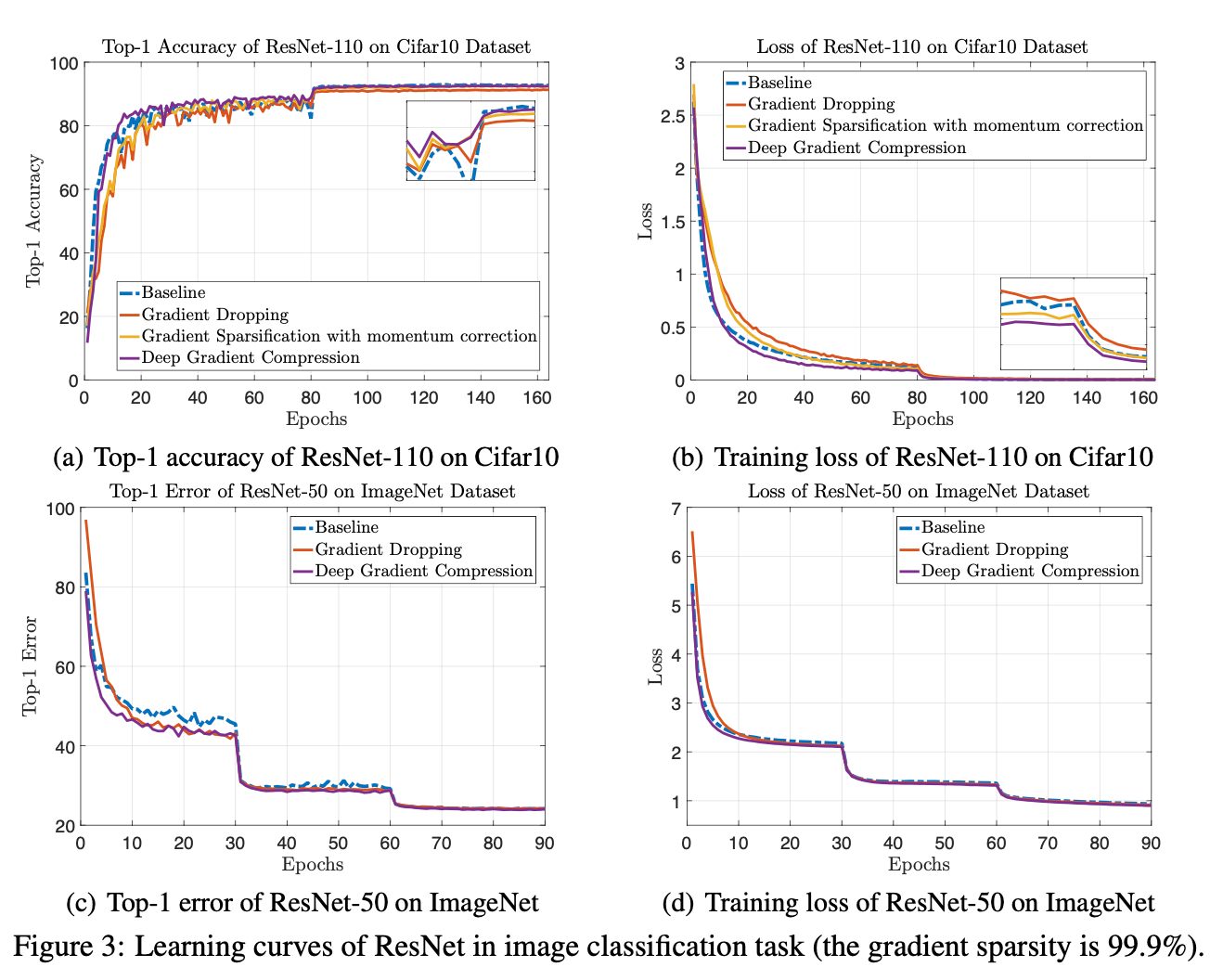
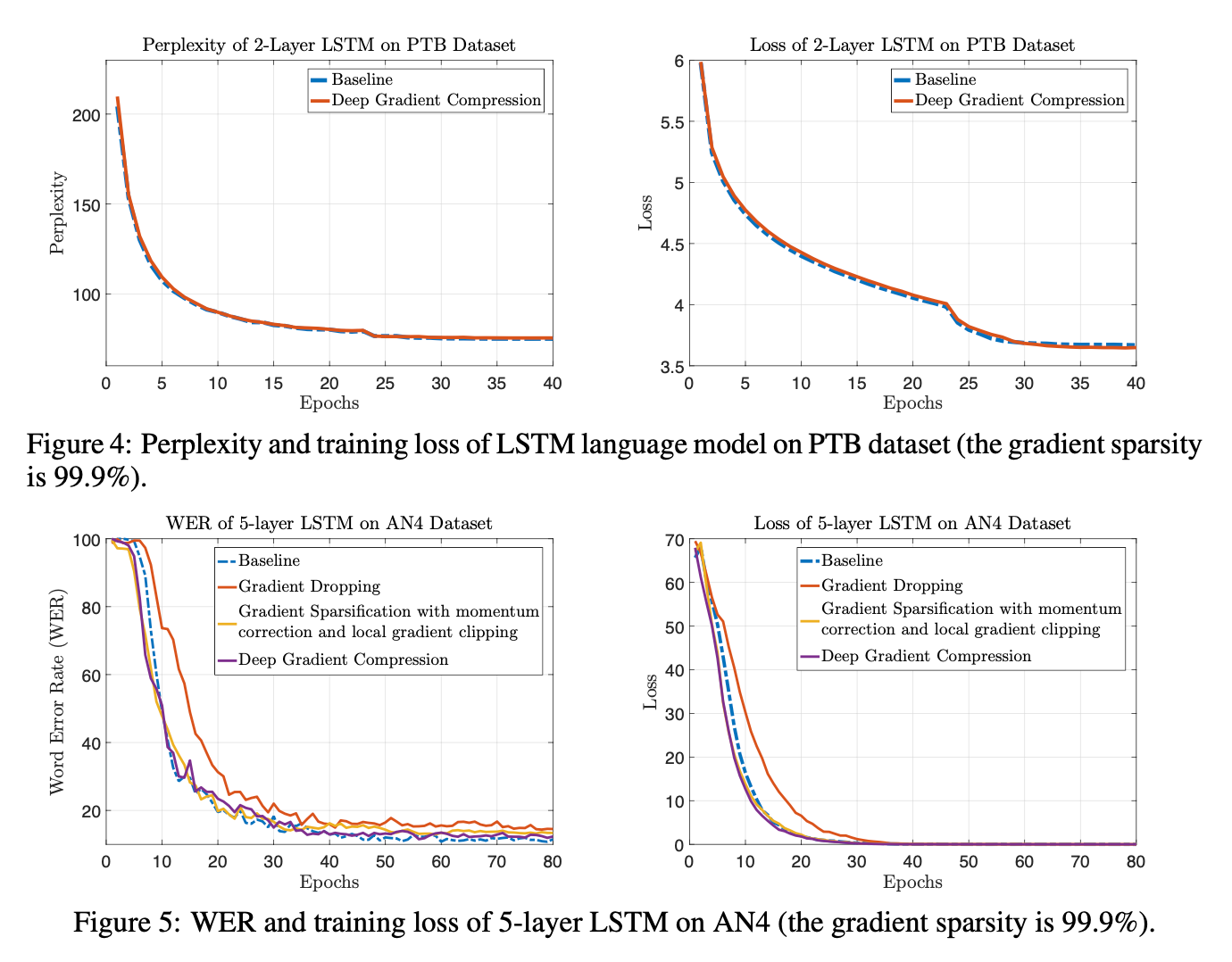
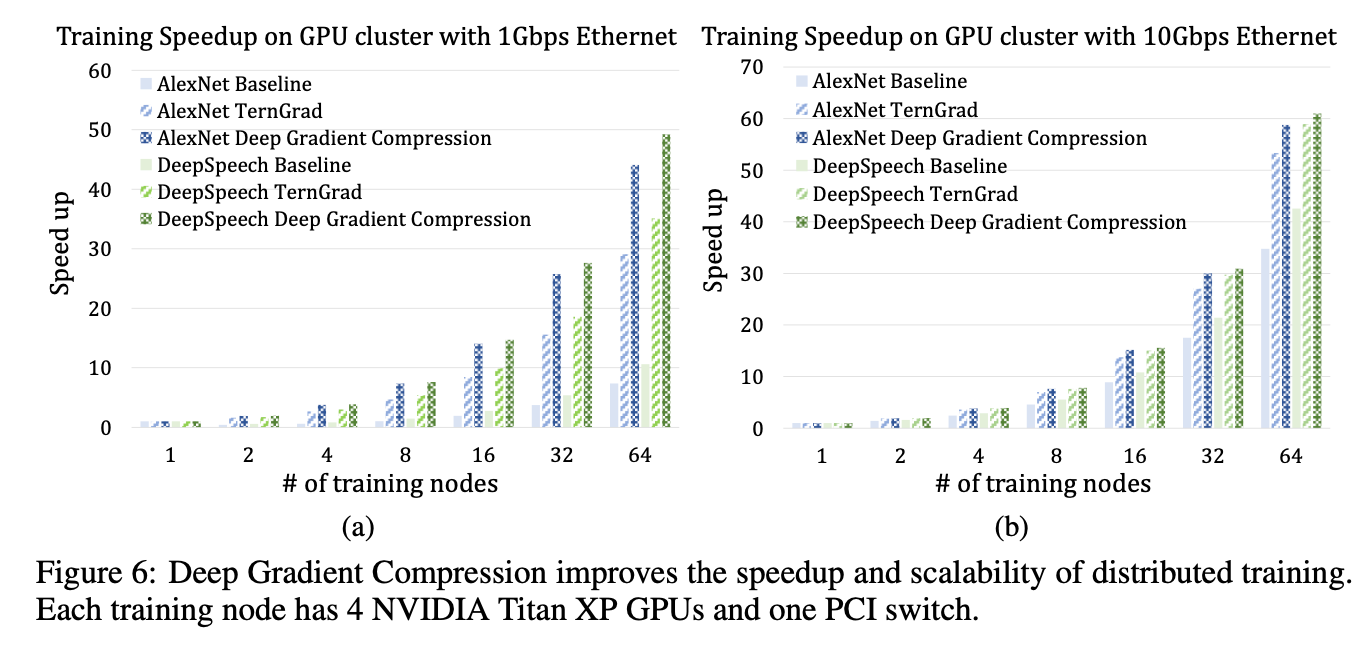
Conclusion
深度梯度压缩(DGC)对广泛的cnn和rnn进行270-600倍的梯度压缩。为了在不减慢收敛速度的情况下实现这种压缩,DGC采用了动量校正、本地梯度裁剪、动量因子掩藏和热身训练。我们进一步提出了分层阈值选择,以加快梯度稀疏过程。深度梯度压缩降低了所需的通信带宽,提高了分布式训练的可扩展性,使用廉价的、商品的网络基础设施。















 1992
1992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











