







 Mobile-Former是CVPR2022一篇论文提出的新型网络,旨在融合MobileNet的局部处理效率与Transformer的全局交互能力。通过并行结构和轻量级交叉注意模型,实现了在计算资源受限情况下的高性能。实验表明,Mobile-Former在图像分类和目标检测任务上表现出色,尤其是在低FLOP场景下超越了CNN和Transformer变体。
Mobile-Former是CVPR2022一篇论文提出的新型网络,旨在融合MobileNet的局部处理效率与Transformer的全局交互能力。通过并行结构和轻量级交叉注意模型,实现了在计算资源受限情况下的高性能。实验表明,Mobile-Former在图像分类和目标检测任务上表现出色,尤其是在低FLOP场景下超越了CNN和Transformer变体。

论文链接:https://arxiv.org/pdf/2108.05895.pdf
代码链接:无
1. 动机
vision transformer (ViT)可以很好地建模全局信息,并实现与CNN相比显著的性能提升。但是,当计算资源受限时,ViT的增益减少。而针对计算成本方面的挑战,MobileNet和它的变体仍然占据着主导地位,因为它们通过分解深度和点卷积在局部处理过滤器中的效率很高。这就引出一个问题,**能否有这样一个高效的网络,它可以有效地编码局部处理和全局交互?**虽然之前已有工作结合卷积和视觉Transformer的优势并获得了不错的性能,但是这些工作几乎都是将卷积和视觉Transformer进行串联!并联的性能如何呢?
2. 贡献
- 本文将设计模式由串联式转变为并联式,并提出一种新的网络,将MobileNet与Transformer并联,并在两者之间架设双向桥接,该网络命名为Mobile-Former,其中Mobile指的是MobileNet, Former代表Transformer。
- 提出了一种轻量级的交叉注意模型来建模MobileNet与Transformer之间的双向桥。
3. 方法
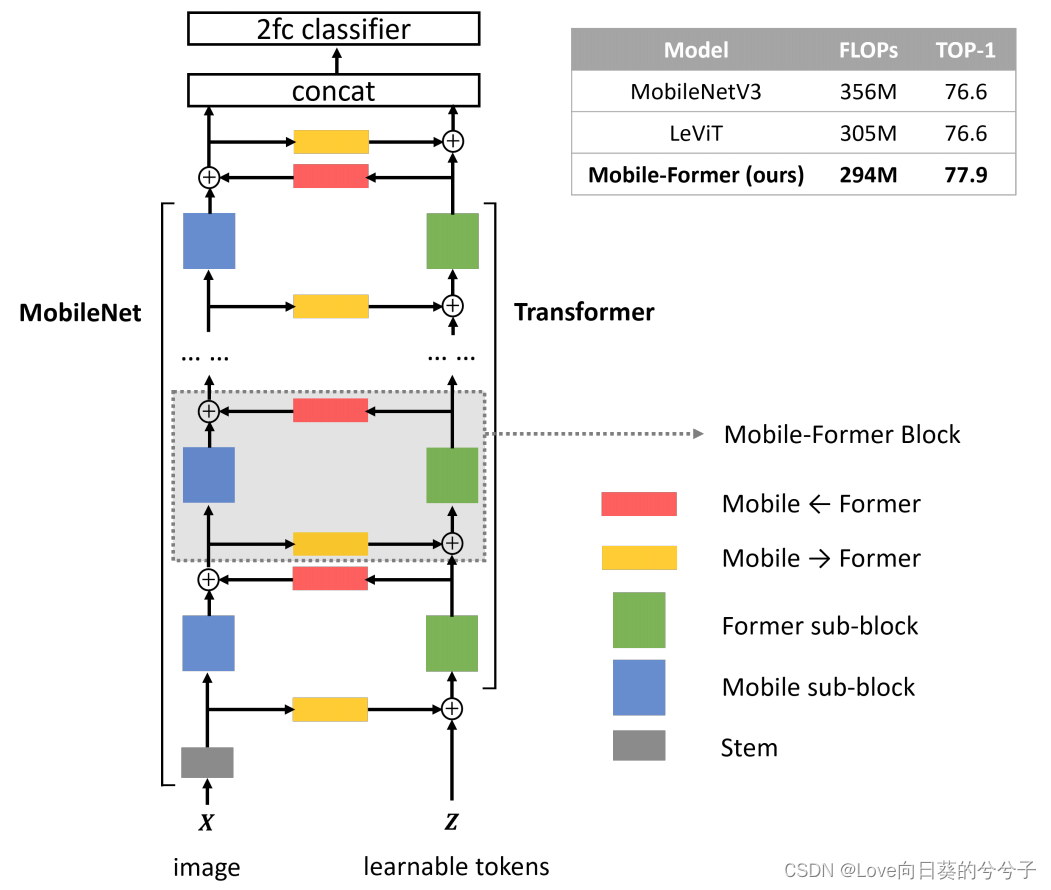
3.1 Mobile-Former结构概述
如上图所示, Mobile-Former网络由左边MobileNet和右边Transformer并行组成。具体地:
- 左边的MobileNet的输入是一张图像,它由mobile(或倒置bottleneck)块堆叠而成,其利用有效的深度和点卷积来提取局部特征。
- 右边的Transformer以一些可学习的token作为输入,并堆叠multi-head attention与前馈网络(FFN)。这些token用于编码图像的全局特征。
- MobileNet和Transformer之间通过一个双向桥进行交流,该桥由所提出的轻量级交叉注意建模而成
值得注意的是,右边的Transformer与以往的视觉Transformer的输入不同,以往的视觉Transformer的输入是利用图像patch来形成token,而Mobile-Former中的Transformer只接受少量随机初始化的可学习token(少于6)作为输入。
MobileNet和Transformer结构我们已经见怪不怪了,我们这里重点看看轻量级交叉注意,即,Mobile-Former双向桥。下面详细讲解一下。
3.2 轻量级交叉注意(Mobile-Former双向桥)
我们已经知道Mobile和Former是通过一个双向桥梁进行交流,来建模局部和全局特征双向融合。具体地,这两个方向分别表示为 M o b i l e → F o r m e r Mobile→Former Mobile→Former和 M o b i l e ← F o r m e r Mobile←Former Mobile←Former。
为了实现这个目的,作者提出了一个轻量级的交叉注意模型,其中注意,投影( W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV)从Mobile边删除以节省计算,但在Former端保留了。作者在channel数较低的MobileNet的bottleneck处计算交叉注意。具体来说,从局部特征映射 X X X到全局tokens Z Z Z的轻量级交叉注意可以表示为:
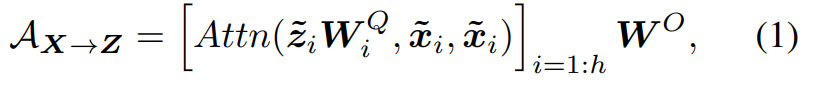
其中局部特征 X X X和全局tokens Z Z Z被分成 h h h个头,即, X = [ x ~ 1 , ⋯ , x ~ h ] , Z = [ z ~ 1 , ⋯ , z ~ h ] X = [\tilde{x}_1, \cdots, \tilde{x}_h], Z = [\tilde{z}_1, \cdots, \tilde{z}_h] X
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2811
2811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









