







什么是DBSCAN
最近在搞比赛,深入理解了一下DBSCAN算法,下面说说我的心得
DBSCAN(Density-Based Spatial Clustering of Application with Noise,具有噪声的基于密度的空间聚类应用)是一种基于高密度连接区域的密度聚类算法。该算法将具有足够高密度的区域划分为簇,并可以在带有“噪声”的空间数据库中发现任意形状的聚类,它定义簇为密度相连的点的最大集合。相比于较常见的kmeans聚类,DBSCAN不需要初始选取的点的个数,具有一次扫描数据便完成聚类的优点。
原理
任意点p的局部点密度由两个参数定义,即Eps(邻域的最大半径)及MinPts(在Eps邻域中的最少点数)。相关一些概念的定义如下:
定义1(Eps邻域)
给定一个对象p,p的Eps邻域NEps(p)定义为以p为核心,以Eps为半径的d维超球体区域,即:
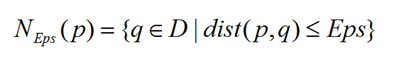
其中,D为d维实空间上的数据集, dist (p,q)表示D中的2个对象p和q之间的距离。
定义2(核心点与边界点)
对于对象p∈D,给定一个整数MinPts,如果p的Eps邻域内的对象数满足|NEps§|≥MinPts ,则称p为(Eps,MinPts ) 条件下的核心点;不是核心点但落在某个核心点的Eps邻域内的对象称为边界点。
这两个定义是最重要的定义
算法流程:
(1)找出所有核心点
(2)访问核心点领域内的所有核心点
(3)当所有已访问的核心点的领域都不能访问其他未访问的核心时,生成 一个簇
代码实现
def dbscan(df,mins,r):
lat=df['latitude'].tolist()
lon=df['longitude'].tolist()
time=df['timestamp'].tolist()
'''
查找所有的核心点
'''
he={}
for i in range(len(lat)):
he[time[i]]=[time[i]]
for i in range(len(lat)):
for j in range(1,len(lat)):
if geodesic((lat[i],lon[i]),(lat[j],lon[j])).m < r:
he[time[i]].append(time[j])
hexin=[]
for i in he:
if len(he[i])>mins:
hexin.append(i)
D=set(time)
'''
随机选取核心点进行迭代
'''
c=[]
k=0
while len(hexin)!=0:
D_old=D
q=[]
o=hexin[random.randint(0,len(hexin))] #随机选取一个核心点
q.append(o)
D=D-set([o]) #表示已访问过这个核心点
while len(q)!=0:
x=q.pop(0)
if x in he:
detal=set(he[x])&D
for i in detal:
if i not in q:
q.append(i)
D=D-detal
c.append(D_old-D)
for i in c[k]:
if i in hexin:
hexin.remove(i)
k+=1
return c
可视化工具
这个网址可以看DBSCAN的可视化过程,加深理解
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/














 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









