







Abstract
在智能汽车的视觉导航系统中,车道至关重要。当然,车道是一种具有高级语义的交通标志,而它具有特定的局部模式,需要详细的低级特征才能准确定位。使用不同层次的特征对于准确检测车道非常重要,但目前还没有得到充分的研究。在这项工作中,我们提出了跨层细化网络(CLRNet),旨在充分利用高层和低层特征进行车道检测。具体来说,它首先利用高级语义特征检测车道,然后根据低级特征进行细化。这样,我们就能利用更多的上下文信息来检测车道,同时利用局部详细的车道特征来提高定位精度。我们采用 ROIGather 收集全局上下文,进一步增强了车道的特征表示。除了新颖的网络设计,我们还引入了线性 IoU 损失,将车道线作为一个整体进行回归,以提高定位精度。实验证明,所提出的方法大大优于最先进的车道检测方法。代码见:https://github.com/Turoad/CLRNet。
1. Introduction
车道线检测是计算机视觉中一项重要而又具有挑战性的任务,它需要网络来预测图像中的车道线。检测车道可使许多应用受益,例如自动驾驶和高级驾驶员辅助系统(ADAS),该系统可帮助智能车辆更好地定位自身并更安全地驾驶。
得益于CNN的有效特征表示,许多方法[17,19,33]已经获得了有前途的性能。然而,对于检测准确的车道仍然存在一些挑战。Lane具有高级语义,而它拥有特定的局部模式,需要详细的低级特征来准确定位。如何在CNN中有效地利用不同的特征层次是一个亟待解决的问题。正如我们在图1(a)可以看到的,地标和车道线具有不同的语义,但是它们共享相似的特征(例如,长长白色)。如果没有高层语义和全局上下文,很难区分它们。另一方面,由于车道狭长,局部特征简单,因此局部性也是必不可少的。我们在图1(B)中显示了高级特征的检测结果,虽然检测到了车道,但其位置并不精确。因此,低级和高级信息对于准确的车道检测是互补的。以前的工作要么对车道的局部几何形状进行建模,并将其集成到全局结果中[20],要么利用全局特征构建一个完全连通的图层,以预测车道[19]。这些检测器已经证明了局部或全局特征对于车道检测的重要性,但是它们没有利用这两种特征,从而产生不准确的检测性能。
车道检测中的另一个常见问题是没有车道存在的视觉证据。如图在图1(c)中,车道被汽车占用,而在图1(d)所示的实施例中,由于极端的照明条件,车道难以识别。在文献中,SCNN [17]和RESA [33]提出了一种消息传递机制来收集全局上下文,但这些方法执行逐像素预测,而没有将车道作为一个整体单元。因此,它们的性能落后于许多最先进的检测器。
在本文中,我们提出了一个新的框架,跨层细化网络(CLRNet),它充分利用低级别和高级别的车道检测特征。具体来说,我们首先在高级语义特征执行检测来粗略定位车道。然后,我们在精细细节特征的基础上执行细化,以获得更精确的位置。逐步细化车道的位置和特征提取导致高精度的检测结果。为了解决车道的非视觉证据的问题,我们引入ROIGather捕获更多的全局上下文信息,通过建立ROI车道特征和整个特征图之间的关系。此外,我们定义了车道线的IoU,并提出了线IoU(LIoU)损失,以将车道作为一个整体单元进行回归,并与标准损失(即平滑-l1损失)相比显著地提高了性能。
我们在三个车道检测基准上证明了我们的方法的有效性,即CULane[17]Tusimple[26]LLAMAS[2].实验结果表明,我们的方法在所有数据集上都达到了最先进的性能。其主要贡献可归纳如下:
我们证明了低级和高级的特征是对于车道检测是互补的,我们提出了一种新的网络架构(CLRNet),以充分利用车道检测低级和高级的特征。
我们提出ROICather,通过收集全局上下文以进一步增强车道特征的表示,这也可以插入到其他网络。
我们提出了为车道检测量身定制的线IoU(LIoU)损失,回归车道作为整个单元,并大大提高性能。
为了更好地比较不同检测器的定位精度,我们还采用了新的mF1度量。我们证明了所提出的方法在三个车道检测基准上大大优于其他最先进的方法。
2. Related Work
根据车道的表示,目前基于CNN的车道检测可分为三类:基于分割的方法、基于锚点的方法和基于参数的方法。
2.1. Segmentation-based methods
现代算法通常采用逐像素预测公式,即,将车道检测视为语义分割任务。SCNN [17]提出了一种消息传递机制来解决没有视觉证据的问题,该机制捕获了车道的强空间关系。SCNN显著提高了车道线检测的性能,但算法的实时性较差。RESA [33]提出了一种实时特征聚合模块,使网络能够收集全局特征并提高性能。在CurveLane-NAS [28]中,他们使用神经结构搜索(NAS)来寻找更好的网络,以捕获准确的信息,从而有利于弯道车道的检测。然而,NAS在计算上非常昂贵,并且花费了大量的GPU小时。由于这些基于分割的方法对整个图像执行逐像素预测,并且没有将车道作为一个整体单元来考虑,因此效率低且耗时。
2.2. Anchor-based methods
车道检测中的基于锚点的方法可以分为两类,例如,基于线锚的方法和基于行锚的方法。基于线锚点的方法采用预定义的线锚点作为参考来回归精确的车道。Line-CNN [8]是在车道检测中使用线锚的开创性工作。LaneATT [24]提出了一种新的基于锚点的注意机制,该机制聚合全局信息。它实现了最先进的结果,并显示了高功效和效率。SGNet [22]介绍了一种新型的消失点引导锚点生成器,并添加了多个结构引导以提高性能。对于基于行锚点的方法,它预测图像上每个预定义行的可能单元格。UFLD [19]首次提出了一种基于行锚点的车道线检测方法,并采用轻量级主干实现了较高的推理速度。虽然它简单快速,但它的整体性能并不好。CondLaneNet [12]引入了基于条件卷积和基于行锚的公式化的条件车道检测策略,即,它首先定位车道线的起点,然后执行基于行锚点的车道检测。然而,在一些复杂的场景中,起点很难识别,这导致性能相对较差。
2.3. Parameter-based methods
与点回归不同,基于参数的方法是用参数对车道曲线进行建模,然后对这些参数进行回归来检测车道。PolyLaneNet [25]采用多项式回归问题,实现了高效率。LSTR [13]将道路结构与摄像机姿态考虑在内,以对车道形状进行建模,然后将Transformer引入车道检测任务以获得全局特征。基于参数的方法具有更少的要回归的参数,但是它们对预测的参数敏感,例如,对高阶系数的误差预测可能导致车道的形状改变。虽然这些方法具有快速的推理速度,但它们仍然难以实现更高的性能。
3. Approach
3.1. The Lane Representation
Lane Prior.
车道又细又长,具有很强的形状先验,因此,预定义的车道先验可以帮助网络更好地定位车道。在常见的物体检测中,物体是用矩形框来表示的。然而,矩形框并不适合表示长线。根据文献 [8] 和 [24],我们使用等间距的二维点来表示车道。具体来说,车道表示为一个点序列,即
P
=
(
x
1
,
y
1
)
,
…
,
(
x
N
,
y
N
)
P = {(x_1, y_1), \dots, (x_N, y_N)}
P=(x1,y1),…,(xN,yN)。点的
y
y
y坐标在图像垂直方向上平均采样,即
y
i
=
H
N
−
1
∗
i
y_i=\frac{H}{N-1}*i
yi=N−1H∗i,其中
H
H
H为图像高度。因此,
x
x
x坐标与各自的
y
i
∈
Y
y_i ∈ Y
yi∈Y相关联。在本文中,我们称这种表示法为车道先验。每个车道先验值都将由网络预测,并由四个部分组成: (1) 前景和背景概率。(2) 车道先验长度。(3) 车道线的起点和车道先验的
x
x
x轴之间的角度(称为
x
、
y
和
θ
x、y 和 θ
x、y和θ)。(4) N 个偏移量,即预测值与地面实况之间的水平距离。
3.2. Cross Layer Refinemen
Motivation.
在神经网络中,深层高级特征强烈对应具有更多语义信息的整个对象,而浅层低级特征具有更多的局部上下文信息。允许车道目标获得高级特征可以帮助利用更多有用的上下文信息,例如,以区分车道线或地标。与此同时,精细细节功能有助于以高定位精度检测车道。在目标检测[9]中,它构建特征金字塔以利用ConvNet特征层次结构的金字塔形状,并将对象的不同尺度分配给不同的金字塔级别。然而,很难直接将车道分配给仅一个级别,因为高级和低级特征对于车道都是关键的。受Cascade RCNN [3]的启发,我们可以将车道对象分配到所有级别,并顺序地检测车道。特别地,我们可以检测具有高级特征的车道以粗略地定位车道。基于检测到的车道,我们可以用更详细的特征来细化它们。
Refinement structure.
我们的目标是利用ConvNet的金字塔特征层次结构,它具有从低到高的语义,并始终构建具有高级语义的特征金字塔。我们以ResNet[6]为骨干,使用
{
L
0
,
L
1
,
L
2
}
\{L_0,L_1,L_2\}
{L0,L1,L2}来表示FPN生成的特征级别。如图2所示,我们的跨层细化从最高级别
L
0
L_0
L0开始,逐渐接近
L
2
L_2
L2。我们用
{
R
0
,
R
1
,
R
2
}
\{R_0,R_1,R_2\}
{R0,R1,R2}来表示相应的细化。然后我们就可以构建一系列的细化
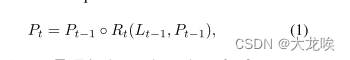
其中
t
=
l
,
⋅
⋅
⋅
,
T
t = l,· · ·,T
t=l,⋅⋅⋅,T,
T
T
T是细化的总数。我们的方法从具有高语义的最高级别层执行检测。
P
t
P_t
Pt是车道先验的参数(起始点坐标
x
、
y
x、y
x、y和角度
θ
θ
θ),其受[23]的启发可学习。对于第一层
L
0
L_0
L0,
P
0
P_0
P0均匀地分布在图像平面上。细化
R
t
R_t
Rt将
P
t
P_t
Pt作为输入以得到ROI车道特征,然后执行两个FC层以得到细化参数
P
t
P_t
Pt。逐步细化车道先验和特征提取对于成功的跨层细化是重要的。请注意,我们的方法不限于FPN结构,仅使用ResNet [6]或采用PAFPN [14]也是合适的。
3.3. ROIGather
Motivation.
在我们为每个特征图分配车道先验之后,我们可以使用ROIALIGN [5]获得车道先验的特征。然而,这些特征的上下文信息仍然是不够的。在某些情况下,车道实例可能会因极端的照明条件而被占用或模糊。因此,不存在车道存在的局部视觉迹象。为了确定一个像素是否属于车道,我们需要查看附近的特征。最近的一些研究[27,32]也表明,如果充分利用长范围相关性,则可以提高性能。因此,我们可以收集更多有用的上下文信息,以更好地学习车道特征。为此,我们沿着车道先验添加卷积。通过这种方式,车道先验中的每个像素可以聚集附近像素的信息,并且可以根据该信息来增强被遮挡部分。在此基础上,建立了车道先验特征与整个特征图之间的关系。因此,它可以利用更多的上下文信息来学习更好的特征表示 。
ROIGather structure.
ROIGather模块轻量且易于实现。它以特征图和车道先验为输入,每个车道先验有
N
N
N个点。对于每个车道先验,我们遵循ROIallign [5]以获得车道先验的ROI特征(
X
p
∈
R
C
×
N
p
\mathcal{X} _p ∈\mathbb{R} ^{C×N_p}
Xp∈RC×Np)。与边界框的ROIAlign不同,我们从车道先验均匀采样
N
p
N_p
Np个点,并使用双线性插值来计算这些位置处的输入特征的精确值。对于
L
1
、
L
2
L_1、L_2
L1、L2的ROI特征,我们将先前层的ROI特征连接起来以增强特征表示。对提取的 ROI 特征进行卷积,以收集每个车道像素的附近特征。为了节约内存,我们使用全连接进一步提取车道先验特征(
X
p
∈
R
C
×
1
\mathcal{X} _p ∈\mathbb{R} ^{C×1}
Xp∈RC×1)。特征图的大小调整为
X
f
∈
R
C
×
H
×
W
\mathcal{X} _f ∈\mathbb{R} ^{C×H×W}
Xf∈RC×H×W,并展平为
X
f
∈
R
C
×
H
W
\mathcal{X} _f ∈\mathbb{R} ^{C×HW}
Xf∈RC×HW。详细设置在4.2节.
为了聚集车道先验特征的全局上下文,我们首先计算ROI车道先验特征(
X
p
\mathcal{X} _p
Xp)和全局特征图(
X
f
\mathcal{X} _f
Xf)之间的注意力矩阵
W
W
W,其被写为:
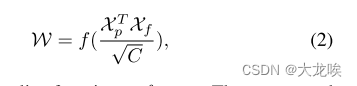
其中
f
f
f是归一化函数Softmax。聚合功能写成:
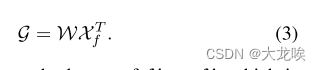
输出
G
G
G反映了
X
f
\mathcal{X} _f
Xf对
X
p
\mathcal{X} _p
Xp的奖励,
X
p
\mathcal{X} _p
Xp是从
X
f
\mathcal{X} _f
Xf的所有位置中选择的。最后,我们将输出添加到原始输入
X
p
\mathcal{X} _p
Xp。
3.4. Line IoU loss
Motivation.
如上所述,车道先验由需要与ground truth回归的离散点组成。常用的距离损失,如Smooth-L1,可以用来回归这些点。然而,这种损失将点作为独立变量,这是一个过于简化的假设[31],导致回归不那么准确。与距离损失不同的是,交并比(IOU)可以将车道先验作为一个整体进行回归,并为评估指标[21,31,34]量身定做。在我们的工作中,我们推导了一个简单而有效的算法来计算线路IOU(Liou)损耗。
Formula.
我们从line segment IoU的定义开始引入Line IoU损失,既两条线段之间的相互作用与并集的比率。对于如图3所示的预测车道中的每个点,我们首先将它(
x
i
p
x_i^p
xip)以半径
e
e
e延伸成线段。然后,IoU可以在延伸线段和其 ground truth之间计算,其写为:
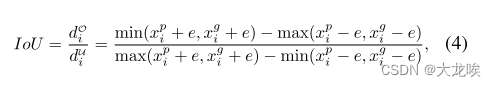
其中
x
i
p
−
e
x_i^p-e
xip−e,
x
i
p
x_i^p
xip+e是
x
i
p
x_i^p
xip的扩展点,
x
i
g
−
e
x_i^g-e
xig−e,
x
i
g
−
e
x_i^g-e
xig−e是相应的ground truth点。请注意,
d
i
o
d_i^o
dio可以为负,这使得在线段不重叠的情况下进行优化是可行的。
那么,LIoU可以被认为是无限线点的组合。为了简化表达式并使其易于计算,我们将其转换为离散形式,
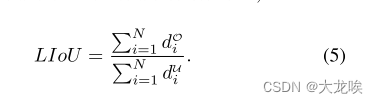
那么,LIoU 损失的定义是
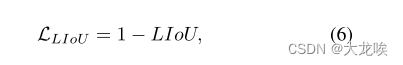
其中−1 ≤ LIoU ≤ 1,当两条线完全重叠时,则LIoU = 1,当两条线相距较远时,LIoU收敛到-1。
我们的线路IoU损失具有两个优势:(1)它简单可微,易于实现并行计算。(2)它将车道作为一个整体进行预测,这有助于提高整体性能。
3.5. Training and Infercence Details
Positive samples selection.
在训练期间,每个ground truth车道被动态地分配一个或多个预测车道作为正样本,这受到[4]的启发。特别地,我们首先基于分配成本对预测的车道进行排序,其被定义为:
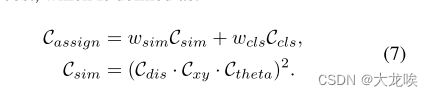
这里
C
c
l
s
C_{cls}
Ccls是预测和标签之间的focal cost[10]。
C
s
i
m
C_{sim}
Csim是预测车道和ground truth之间的相似性成本。它由三部分组成,
C
d
i
s
C_{dis}
Cdis表示所有有效车道点的平均像素距离,
C
x
y
C_{xy}
Cxy表示起点坐标的距离,
C
t
h
e
t
a
C_{theta}
Ctheta表示
θ
θ
θ角的差,它们都被归一化为
[
0
,
1
]
[0,1]
[0,1]。
w
c
l
s
w_{cls}
wcls和
w
s
i
m
w_{sim}
wsim是每个定义的分量的权重系数。每个ground truth车道都会根据
C
a
s
s
i
g
n
C_{assign}
Cassign分配到预测车道的动态数量
(
t
o
p
−
k
)
(top-k)
(top−k)。
Training Loss.
训练损失包括分类损失和回归损失。仅对指定的样本执行回归损失。总损失函数定义为:
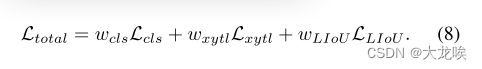
L
c
l
s
L_{cls}
Lcls是预测和标签之间的focal loss,
L
x
y
t
l
L_{xytl}
Lxytl是起始点坐标、
θ
θ
θ角和车道长度回归的smooth-l1 loss,LLioU是预测车道和ground truth之间的线IoU损失。可选地,我们可以在[19]之后添加辅助分割损失。它只在训练期使用,没有推理成本。
Inference.
我们设置一个分类得分阈值来过滤背景车道(低分车道先验),并按照 [24] 的方法使用 nms 去除高重叠车道。如果使用一对一赋值,即设置
t
o
p
−
k
=
1
top-k = 1
top−k=1,我们的方法也可以不使用 nms。
4. Experiment
4.1. Datasets
我们在两个广泛使用的车道检测基准数据集上进行了实验: CULane [17] 和 Tusimple [26] 以及最近发布的一个基准(LLAMAS [2])。
CULane [17] 是一个用于车道检测的大规模挑战性数据集。它包含九个具有挑战性的类别,如拥挤、夜间、交叉等。CULane 数据集包括训练集、验证集和测试集共 100,000 张图像。所有图像的像素均为 1640 × 590。
LLAMAS [2] 也是一个大规模的车道检测数据集,包含超过 10 万张图像。LLAMAS 中的车道标记是通过高精度地图自动标注的。由于测试集的标签不公开,我们将检测结果上传到 LLAMAS 基准的网站上进行测试。
Tusimple [26] 车道检测基准是车道检测中使用最广泛的数据集之一。它只包含高速公路场景,其中 3268 幅图像用于训练,358 幅用于验证,2782 幅用于测试。所有图像的像素均为 1280 × 720。
4.2. Implementation details
我们采用 ResNet [6] 和 DLA [30] 作为预训练骨干。所有输入图像的大小均调整为 320 × 800。在数据增强方面,与文献[12, 20]类似,我们使用了随机仿射变换(平移、旋转和缩放)和随机水平翻转。在优化过程中,我们使用 AdamW [16] 优化器,初始学习率为 1e-3,余弦衰减学习率策略 [15],幂设为 0.9。我们为 CULane、Tusimple 和 LLAMAS 分别训练了 15 epochs、70 epochs 和 20 epochs。我们的网络基于 Pytorch 实现,使用 1GPU 运行所有实验。我们设定车道先验点数 N = 72,采样数
N
p
N_p
Np = 36。ROIGather 中调整后的 H、W 分别为 10、25,通道 C = 64。LIoU 中的扩展半径
e
e
e 为 15。分配成本系数设为
w
c
l
s
w_{cls}
wcls = 1 和
w
s
i
m
w_{sim}
wsim= 3。
4.3. Evaluation Metric
我们采用 F1 测量作为 CULane [17] 和 LLAMAS [2] 的评估指标。我们计算了预测结果与ground truth之间的交叉重叠率(IoU)。IoU 大于阈值(0.5)的预测车道被视为真阳性车道(TP)。F1 定义为
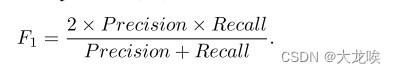
遵循COCO [11]检测度量,我们还报告了一个新的度量mF1,以更好地比较算法的定位性能。它被定义为
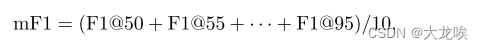
其中
F
1
@
50
、
F
1
@
55
、
−
−
−
、
F
1
@
95
F1@50、F1@55、- - - 、F1@95
F1@50、F1@55、−−−、F1@95分别为 IoU 临界值为 0.5、0.55、- - - 、0.95 时的 F1 指标。这打破了传统的做法,即奖励定位结果更好的检测器。
其中 Tusimple [26] 数据集的评估公式为
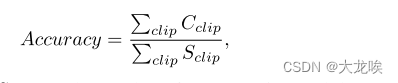
其中,
C
c
l
i
p
C_{clip}
Cclip、
S
c
l
i
p
S_{clip}
Sclip分别为图像的正确点数和ground truth点数。如果超过 85% 的预测车道点与地面实况点的距离在 20 像素以内,则该预测车道为正确预测车道。Tusimple 数据集还报告了假阳性率(FP)和假阴性率(FN),其中
F
P
=
F
p
r
e
d
N
p
r
e
d
,
F
N
=
M
p
r
e
d
N
g
t
F P=\frac{F_{p r e d}}{N_{p r e d}}, F N=\frac{M_{p r e d}}{N_{g t}}
FP=NpredFpred,FN=NgtMpred。
4.4. Comparison with the state-of-the-art results
Performance on CULane.
我们展示了我们的方法在 CULane 车道检测基准数据集上的结果,并与其他流行的车道检测方法进行了比较。如表 1 所示,我们提出的方法在 CULane 上的 F1@50 指标为 80.47,达到了最新水平。我们方法的 ResNet18 版本达到了 79.58 的 F1@50,甚至高于 CondLaneNet(ResNet101),同时比 CondLaneNet(ResNet18)高出 1.4 分。其中,我们的 mF1 比 CondLaneNet (ResNet18) 高出 3.4%,这表明我们的方法能更好地回归车道,并具有较高的定位精度。与基于线锚的方法 LaneATT 相比,我们的 ResNet18 版本的 mF1 和 F1@50 分别超过了 7.88% 和 4.45%。同时,使用 TensorRT 的 CLRNet 在一个英伟达 1080Ti GPU 上可以达到 206 FPS,这对于实时车道检测来说是非常高效的。
图 6 显示了 CULane 数据集的定性结果。基于分割的方法(如 RESA)不能将车道作为一个整体来预测,这就无法保持车道的平滑性。CondLaneNet 只预测车道的一个起点,容易遗漏一些车道实例。我们的方法可以在这些具有挑战性的场景中预测连续、平滑的车道,这表明我们的方法绝对可以收集全局上下文,并具有很强的准确检测车道的能力。
Performance on LLAMAS.
在 LLAMAS 数据集上的结果如表 2 所示。在测试集上,我们的方法分别比 PolyLaneNet [25] 和 LaneATT [24] 高出 7.7 F1@50 和 2.4 F1@50,进步显著。虽然 LaneAF [1] 在有效数据集上达到了 96.90 F1@50,但其推理速度较慢(接近 20FPS),因此难以部署。此外,我们的方法比 LaneAF 高出近 2 点 mF1,这表明我们的方法定位更准确。
Performance on Tusimple.
表 3 显示了与最先进方法的性能比较。不同方法在该数据集上的性能差异非常小,这表明该数据集的结果似乎已经饱和(高值)。我们的方法在 F1 分数上达到了新的最先进水平,并以 0.6% 的 F1 分数超过了之前的最先进水平。这一重大改进体现了我们方法的有效性。
4.5. Ablation study
为了验证所提方法不同组成部分的有效性,我们在 CULane 数据集上进行了多次实验,以显示其性能。
Overall Ablation Study.
为了分析每种建议方法的重要性,我们在表 4 中报告了整体消融研究。我们在 ResNet18 基线上逐步增加了 LIoU loss、Cross Layer Refinement 和 ROIGather。LIoU loss 将 mF1 从 51.90 提高到 52.80。这一结果验证了定位精度的大幅提高。此外,细化后的 mF1 进一步提高到 54.74。mF1、F1@50、F1@70 和 F1@90 的结果都得到了持续改善,这验证了利用高级和低级语义特征来检测车道是有用的,并能获得持续改善。ROIGather 将 mF1 进一步提高了 0.5%,这验证了丰富的全局上下文可以增强车道特征的表示。
Analysis for ROIGather.
为了进一步展示 ROIGather 如何在网络中发挥作用,我们在图 5 中将注意力图(公式 2)可视化。它显示了车道先验的 ROI 特征(橙色线)与整个特征图之间的注意力权重。颜色越亮,权重值越大。值得注意的是,所提出的 ROIGather 可以(i)有效收集具有丰富语义信息的全局上下文,(ii)即使在遮挡情况下也能捕捉到前景车道的特征。更多量化结果见附录。
Ablation study on Cross Layer Refinement
跨层细化的烧蚀研究见表 5。我们首先使用只有一层的探测器进行细化。从结果(设置
R
0
、
R
1
、
R
2
R_0、R_1、R_2
R0、R1、R2)可以看出,这三种细化的结果相似。
R
2
R_2
R2的 F1@90 相对较高,而 F1@50 则相对较低,这说明低层特征有助于准确回归车道。但是,由于丢失了较高的语义信息,可能会造成误检。我们选择结果较好的
R
0
R_0
R0,并逐步增加细化。如
R
0
→
R
0
R_0 → R_0
R0→R0 所示,结果略有改善。而其他融合特征的方法,如添加所有特征,仍然无法带来改善。从
R
0
R_0
R0到
R
2
R_2
R2的细化结果比其他方法要好得多,这验证了我们的跨层细化能更好地利用高层和低层特征。
Ablation Study on Line-IoU Loss.
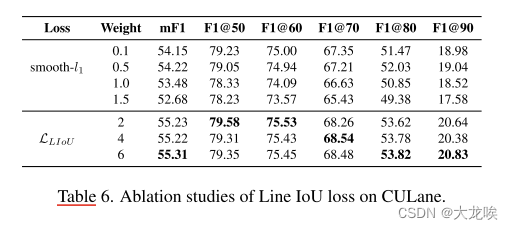
表 6 列出了对 IoU 线损耗的消融研究。我们首先改变损失权重,选择 smooth-l1 的最佳回归权重。我们发现,当回归权重为 1.5 时,smooth-l1 的回归损失远大于分类损失。结果表明,将权重降低到 0.5 会相对好一些。相比之下,LIoU loss 更为稳定,性能提高了近 1 点 mF1。更具体地说,改进主要来自于高重叠度量,如 F1@80 和 F1@90。这些实验结果验证了我们的线路 IoU 损失可以获得更好的性能,并使模型更好地收敛。我们发现所提出的线路 IoU 损失也能改善 LaneATT [24] 的性能,详情见附录。
5. Conclusion
本文介绍了用于车道检测的跨层细化网络(CLRNet)。CLRNet 可利用高层特征预测车道,同时利用局部细节特征提高定位精度。为了解决没有视觉证据证明车道存在的问题,我们提出了 ROIGather,通过与所有像素建立关系来增强车道特征的表示。为了将车道作为一个整体进行回归,我们提出了为车道检测量身定制的线性 IoU 损失,与标准损失(即 smooth-l1 损失)相比,它大大提高了性能。我们的方法在三个车道检测基准数据集(即 CULane、LLamas 和 Tusimple)上进行了评估。实验表明,我们提出的方法优于目前最先进的车道检测方法。
图和表
图
图 1. 车道检测的困难情况说明。(a) 低层特征的检测结果。由于丢失了全局上下文,它将地标误认为车道。(b) 高级特征的检测结果。它预测的车道定位不准确。© 车道几乎被汽车占据的情况。 (d) 车道因极端光照条件而模糊的情况。
图 2. 提出的 CLRNet 概述。(a) 网络根据 FPN [9] 结构生成特征图。随后,每个车道先验特征将从高级特征细化为低级特征。(b) 每个头部将利用更多上下文信息来获取车道先验特征。© 车道先验的分类和回归。建议的线性 IoU 损失有助于进一步提高回归性能。 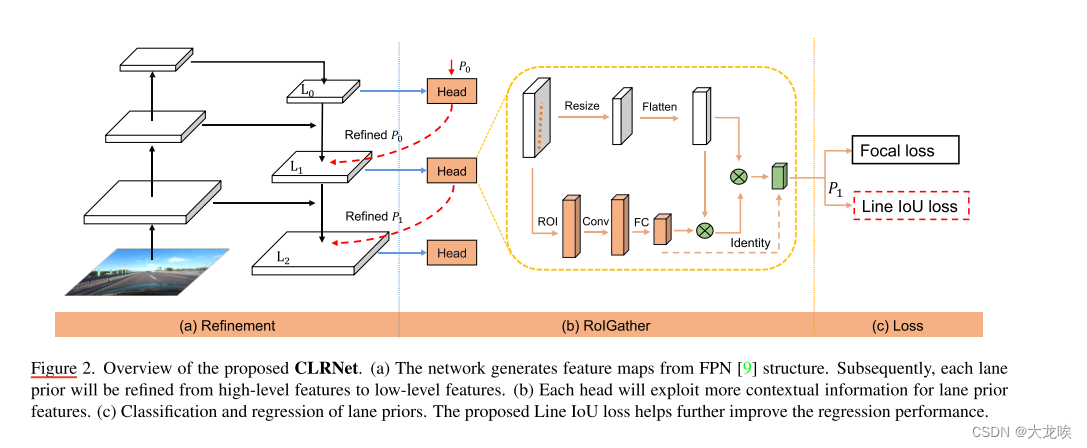
图 3. 线路 IoU 图示。通过对采样
x
i
x_i
xi位置的延长线段的 IoU 进行积分,可以计算出线路 IoU(交并比)。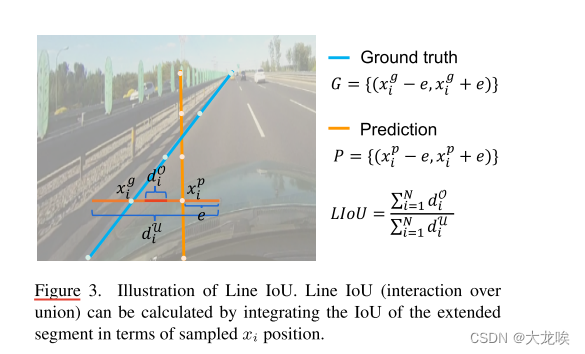
图 4. 最先进方法在 CULane 和 Tusimple 基准上的延迟与 F1 分数对比。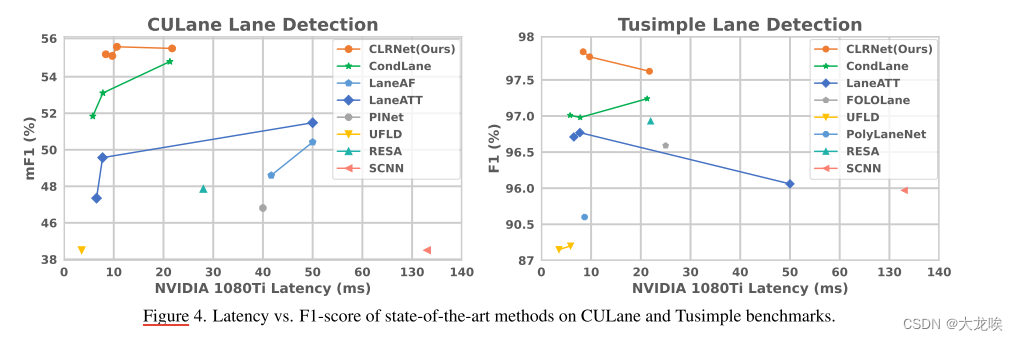
图 5. ROIGather 中的注意力权重图示。它显示了车道先验的 ROI 特征与整个特征图之间的注意力(公式 2)。橙色线是对应的车道先验。红色区域代表注意力权重得分较高。
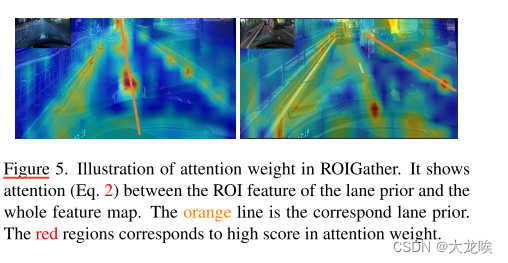
图 6. UFLD、RESA、LaneATT、CondLane 和我们的方法在 CULane 测试集上的可视化结果。

表
表 1. CULane 的最新结果。为了进行更公平的比较,我们在同一台机器上使用一个英伟达 1080Ti GPU 重新测量了源代码可用检测器的 FPS,*表示 TensorRT 上的 FPS。此外,我们还对这些检测器进行了评估,以报告 mF1、F1@50 和 F1@75。对于 "交叉 "类别,仅显示误报。这些类别的报告指标基于 F1@50。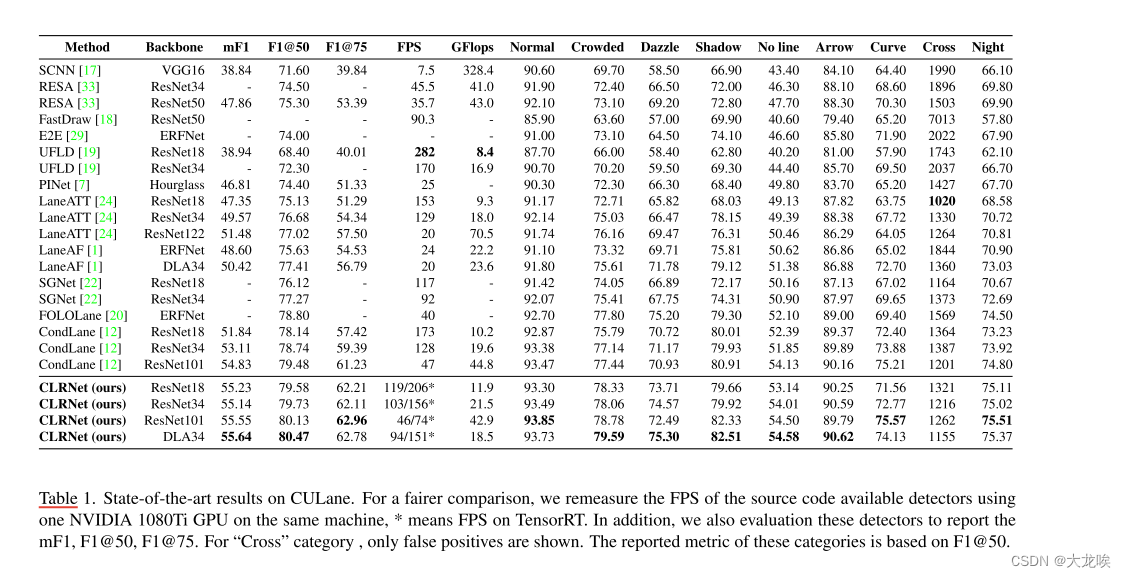
表 2. LLAMAS 的最新结果。此外,我们还使用源代码和训练有素的模型重新对这些方法进行了评估,以获得 mF1、F1@50 和 F1@75。 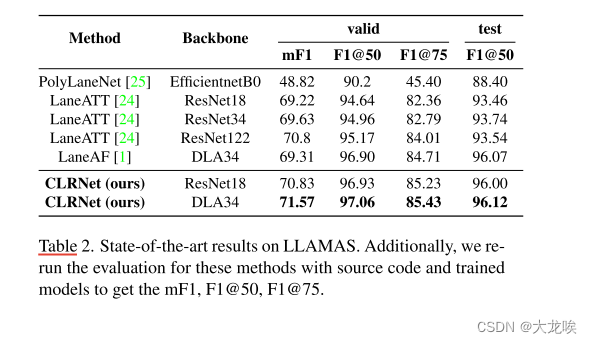
表 3. TuSimple 的最新结果。此外,还使用官方源代码计算了 F1。
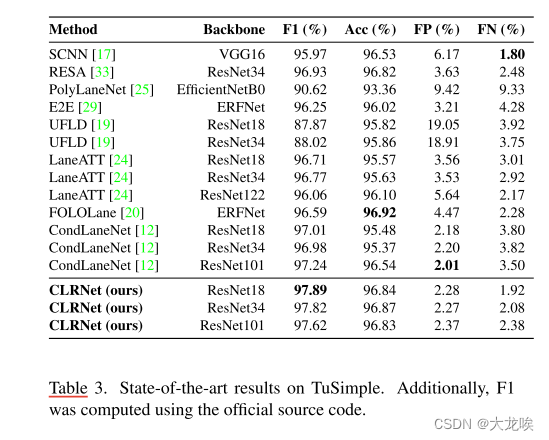
表 4. 我们的方法中各组件的效果。结果以 CULane 报告。
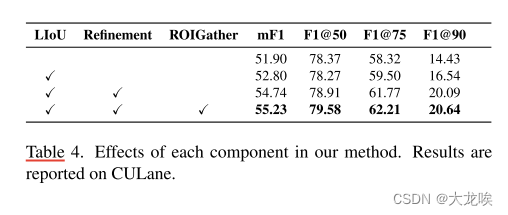
表 5. 不同细化方法的消融研究。
R
i
R_i
Ri是 3.2 节中讨论的细化方法。ADD 表示添加所有特征,细化迭代=3,以便进行更公平的比较。
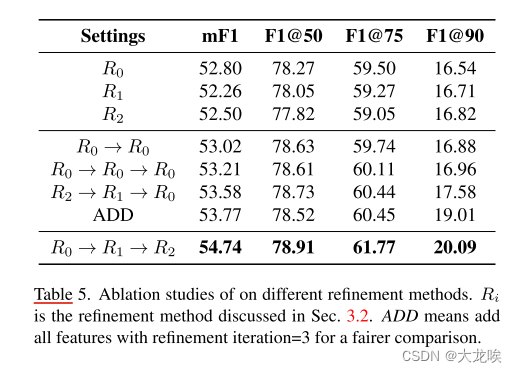
表 6. CULane 上 IoU 线损耗的消融研究。















 1156
1156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









