






Abstract.
在这项工作中,我们解决了现有条件扩散模型的两个局限性:迭代去噪过程导致的推理速度慢,以及模型微调对配对数据的依赖。为了解决这些问题,我们引入了一种通用方法,通过对抗学习目标将单步扩散模型适应新任务和新领域。具体来说,我们将 vanilla 潜在扩散模型的各种模块整合到一个具有较小可训练权重的端到端生成器网络中,从而增强了其保持输入图像结构的能力,同时减少了过拟合。我们证明,在非配对环境下,我们的模型 CycleGAN-Turbo 在各种场景转换任务中的表现优于现有的基于 GAN 和基于扩散的方法,如昼夜转换和添加/移除雾、雪、雨等天气效果。我们将方法扩展到了配对设置,在配对设置中,我们的模型 pix2pix-Turbo 与最近用于 Sketch2Photo 和 Edge2Image 的 ControlNet 等作品不相上下,但采用的是单步推理。这项工作表明,单步扩散模型可以作为一系列 GAN 学习目标的强大支柱。我们的代码和模型见 https://github.com/GaParmar/img2img-turbo。
Introduction
条件扩散模型[5, 38, 48, 73]使用户能够根据空间条件和文本提示生成图像,使各种需要用户精确控制场景布局、用户草图和人体姿势的图像合成应用成为可能。尽管这些模型取得了巨大成功,但也面临着两大挑战。首先,扩散模型的迭代特性使得推理速度缓慢,限制了实时应用,如交互式 Sketch2Photo。其次,模型训练通常需要策划大规模的配对数据集,这对许多应用来说成本高昂,而对其他应用来说则不可行[77]。
在这项工作中,我们介绍了一种适用于配对和非配对环境的一步图像到图像转换方法。我们的方法可以获得与现有条件扩散模型相媲美的视觉效果,同时将推理步骤减少到 1 步。更重要的是,我们的方法可以在没有图像配对的情况下进行训练。我们的主要想法是通过对抗学习目标,将预先训练好的文本条件一步扩散模型(如 SD-Turbo [54])有效地适应新的领域和任务。
遗憾的是,在我们的实验中,直接将标准扩散适配器(如 ControlNet [73])应用于一步法设置的效果并不理想。与传统的扩散模型不同,我们观察到噪声图会直接影响单步模型的输出结构。因此,通过额外的适配器分支馈入噪声图和输入调节会给网络带来相互冲突的信息。特别是在未配对的情况下,这种策略会导致原始网络在训练结束时被忽略。此外,在图像到图像的转换过程中,由于 SD-Turbo 模型的多级流水线(Encoder-UNet-Decoder)重建不完善,输入图像中的许多视觉细节会丢失。当输入图像是真实图像时,这种细节丢失尤为明显和关键,例如在从白天到黑夜的转换过程中。
为了应对这些挑战,我们提出了一种新的生成器架构,在保留输入图像结构的同时利用 SD-Turbo 权重。首先,我们将调节信息直接输入 UNet 的噪声编码器分支。这样,网络就能直接适应新的控制,避免噪声图与输入控制之间的冲突。其次,我们将编码器、UNet 和解码器这三个独立模块整合为一个端到端可训练架构。为此,我们采用 LoRA [17] 技术,使原始网络适应新的控制和领域,从而减少过拟合和微调时间。最后,为了保留输入的高频细节,我们通过 zero-conv [73],在编码器和解码器之间加入跳过连接。我们的架构用途广泛,可作为 CycleGAN 和 pix2pix 等条件 GAN 学习目标的即插即用模型[19, 77]。据我们所知,我们的工作是首次利用文本到图像模型实现一步图像翻译。
我们主要关注较难的非配对翻译任务,例如从白天到黑夜的转换,以及在图像中添加/去除天气效果。我们的研究表明,在分布匹配和输入结构保持方面,我们的模型 CycleGAN-Turbo 明显优于现有的基于 GANs 的方法和基于扩散的方法,同时效率也高于基于扩散的方法。我们还对我们方法的每种设计选择进行了广泛的消融研究。
为了展示我们架构的多功能性,我们还进行了配对设置的实验,如Edge2Image 或Sketch2Photo。我们名为 pix2pix-Turbo 的模型在视觉上取得了与最新条件扩散模型相当的结果,同时将推理步骤减少到 1 步。我们可以通过在预训练模型中使用的噪声图和我们模型的编码器输出之间进行插值来生成多样化的输出。总之,我们的工作表明,一步预训练的文本到图像模型可以作为许多下游图像合成任务的强大而通用的支柱。
Related Work
Image-to-Image translation. 生成模型的最新进展使许多图像到图像的翻译应用成为可能。配对图像翻译方法[19, 41, 51, 65, 75, 79]将图像从源域映射到目标域,使用重建[20,74]和对抗损失[13]相结合的方法。最近,出现了各种条件扩散模型,将文本和空间条件整合到图像翻译任务中[2, 5, 28, 38, 48, 64, 73]。这些方法通常基于预先训练好的文本到图像模型。例如,GLIGEN [28]、T2I-Adapter [38] 和 ControlNet [73]等作品利用门控变换层或零卷积层(gated transformer layers or zero-convolution layers)等适配器引入了有效的微调技术。但是,模型训练仍然需要大量的训练对。相比之下,我们的方法无需图像对就能利用大规模扩散模型,推理速度明显更快。
在许多无法获得配对输入和输出图像的情况下,人们提出了多种技术,包括循环一致性 [24, 70, 77]、共享中间潜空间 [18, 27, 29]、内容保存损失 [56, 60] 和对比学习 [14, 40]。最近的研究[52, 59, 67]也探索了无配对翻译任务的扩散模型。不过,这些基于 GAN 或扩散的方法通常需要在新领域从头开始训练。相反,我们引入了第一种利用预训练扩散模型的非配对学习方法,并展示了比现有方法更好的结果。
Text-to-Image models. 大规模文本条件模型[3,11,21,39,46,49]通过在互联网规模的数据集上进行训练[6, 55],显著提高了图像质量和多样性。一些研究[15, 35, 37, 42, 62]提出了使用预先训练好的文本到图像模型编辑真实图像的零镜头(zero-shot)方法。例如,SDEdit[35] 通过在输入图像中添加噪声来编辑真实图像,随后根据文本提示使用预先训练好的模型进行去噪。在图像编辑过程中,"提示到提示 "工作会进一步处理或保留交叉注意层和自我注意层中的特征[8, 9, 12, 15, 42, 44, 62]。其他研究则在图像编辑之前针对输入图像微调网络或文本嵌入[23, 37],或采用更精确的反转方法[57,63]。尽管这些方法取得了令人印象深刻的成果,但在有许多物体的复杂场景中经常会遇到困难。我们的工作可以看作是利用新领域/任务中的配对或非配对数据来增强这些方法。
One-step generative models. 为了加快扩散模型推断,最近的研究集中于利用快速 ODE 求解器减少采样步骤的数量[22, 32],或将慢速的多步骤教师模型提炼为快速的少步骤学生模型[36, 50]。直接从噪声回归到图像往往会产生模糊的结果 [33, 76]。为此,各种蒸馏方法使用一致性模型训练 [34, 58]、对抗学习 [54, 69]、变分蒸馏 [66, 71]、整流 [30, 31],以及它们的组合 [54]。还有一些方法直接使用 GAN 进行文本到图像的合成 [21,53]。与这些专注于一步式文本到图像合成的方法不同,我们首次提出了同时使用文本和条件图像的一步式条件模型。我们的方法优于直接使用原始 ControlNet 和一步法提炼模型的基线方法。
Method
我们从能够生成逼真图像的一步预训练文本到图像模型开始。然而,我们的目标是将输入的真实图像从源域转换到目标域,例如将白天驾驶的图像转换到夜晚。在第 3.1 节中,我们将探讨为模型添加结构的不同调节方法以及相应的挑战。接下来,在第 3.2 节中,我们研究了困扰潜空间模型的常见细节丢失问题(如文字、手、路标)[47],并提出了解决方法。然后,我们将在第 3.3 节讨论我们的非配对图像翻译方法,并进一步扩展到配对设置和随机生成(第 3.4 节)。
Adding Conditioning Input
要将文本到图像模型转换为图像翻译模型,我们首先需要找到一种有效的方法,将输入图像纳入模型中。
Conflicts between noise and conditional input. 将条件输入纳入扩散模型的一个常见策略是引入额外的适配器分支[38, 73],如图 3 所示。具体来说,我们使用稳定扩散编码器的权重[73]或使用随机初始化权重的轻量级网络[38]初始化第二个编码器,标记为条件编码器。控制编码器接收输入图像,并通过残差连接向预先训练好的稳定扩散模型输出多分辨率的特征图。这种方法在控制扩散模型方面效果显著。然而,如图 3 所示,使用两个编码器(U-Net 编码器和条件编码器)来处理噪声图和输入图像,这对单步模型提出了挑战。与多步扩散模型不同,单步模型中的噪声图直接控制生成图像的布局和姿态,往往与输入图像的结构相矛盾。因此,解码器会收到两组残差特征,每组特征都代表不同的结构,这使得训练过程更具挑战性。
Direct conditioning input. 图 3 还表明,预训练模型生成的图像结构受噪声图 z 的影响很大。基于这一认识,我们建议将调节输入直接输入网络。图 7 和表 4 还显示,直接调节比使用额外的编码器效果更好。为了让骨干模型适应新的调节,我们在 U-Net 的不同层中添加了几个 LoRA 权重[17](见图 2)。
Preserving Input Details
在多物体和复杂场景中,无法使用潜在扩散模型(LDM [47])的一个主要挑战是缺乏细节保护。
Why details are lost. 潜在扩散模型(LDM)的图像编码器将输入图像的空间压缩了 8 倍,同时将通道数从 3 个增加到 4 个。 这种设计加快了扩散模型的训练和推理。但是,对于需要保留输入图像精细细节的图像转换任务来说,这种设计可能并不理想。我们在图 4 中对这一问题进行了说明,图 4 中我们获取了一张输入的日间驾驶图像(左图),并使用未使用跳跃连接的架构将其转换为相应的夜间驾驶图像(中图)。请注意,文字、路标和远处的汽车等细粒度细节没有得到保留。相比之下,采用包含跳跃连接的架构(右图)后,翻译后的图像能更好地保留这些复杂的细节。
Connecting first stage encoder and decoder. 为了捕捉输入图像的细粒度视觉细节,我们在编码器和解码器网络之间添加了跳跃连接(见图 2)。具体来说,我们在编码器中的每个下采样块后提取四个中间激活,通过 1×1 零卷积层(zero-convolution layer)进行处理[73],然后将其输入解码器中相应的上采样块。这种方法可确保在整个图像转换过程中保留复杂的细节。
Unpaired Training
我们在所有实验中都使用了具有一步推理功能的 Stable Diffusion Turbo(v2.1)作为基础网络。在此,我们展示了我们的生成器可用于无配对转换的改进 CycleGAN 方案 [77]。具体来说,我们的目标是在给定一个非配对数据集,将图像从源域
转换到某个期望的目标域
。
我们的方法包括两个转换函数和
: 两种翻译都使用第 3.1 节和第 3.2 节中描述的相同网络
,但与任务相对应的标题
和
不同。例如,在白天 → 夜晚翻译任务中,
是白天开车,
是夜晚开车。如图 2 所示,我们冻结了大部分层,只训练第一个卷积层和添加的 LoRA 适配器。
Cycle consistency with perceptual loss. 循环一致性损耗 强制规定,对于每个源图像
,两个转换函数都应使其回到自身。我们将
称为 L1 差分和 LPIPS [74]的组合。权重请参见附录 D。
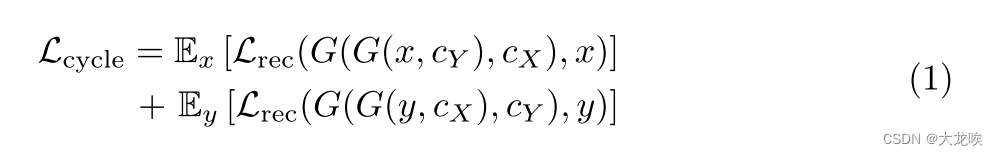
Adversarial loss. 我们在两个域中都使用了对抗损失[13],以鼓励转换输出与相应的目标域相匹配。我们使用了两个对抗判别器 和
,目的是从转换后的图像中对相应域的真实图像进行分类。这两个判别器都以 CLIP 模型为骨干,遵循视觉辅助 GAN [26] 的建议。对抗损失可定义为
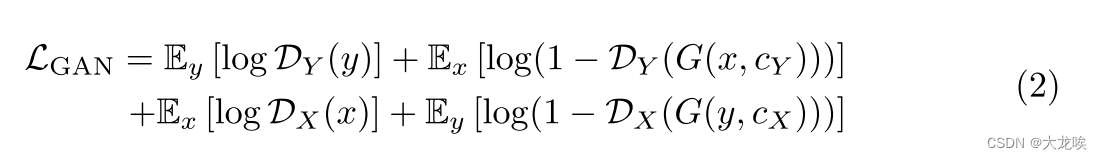
Full objective. 完整的训练目标包括三种不同的损失:周期一致性损失 、对抗性损失
和一致性(identity)正则化损失
。损失由
和
加权,具体如下:

Extensions
虽然我们的主要重点是非配对学习,但我们也演示了学习其他类型 GAN 目标的两种扩展方法,例如从配对数据中学习和生成随机输出。
Paired training. 我们将转换网络调整为配对设置,例如将边缘或草图转换为图像。我们将成对版本的方法称为 pix2pix-Turbo。在配对设置中,我们的目标是学习单个翻译函数
其中,
是源域(如输入草图),
是目标域(如输出图像),
是输入标题。对于配对训练目标,我们使用(1)重构损失作为感知损失和像素空间重构损失的组合;(2)GAN 损失,类似于公式 2 中的损失,但只针对目标域;(3)CLIP 文本-图像配准损失
[45]。详情请参见附录 D。
Generating diverse outputs 生成随机输出在许多图像翻译任务中都很重要,例如草图到图像的生成。然而,让一步式模型生成多样化输出具有挑战性,因为它需要利用额外的输入噪声,而这些噪声往往会被忽略 [18,78]。我们建议通过将特征和模型权重插值到预训练模型中来生成多样化的输出,因为预训练模型已经生成了多样化的输出。具体来说,在给定插值系数的情况下,我们会做出以下三个改变。首先,我们将高斯噪声和编码器输出结合起来。我们的生成器
现在需要三个输入:输入图像
、噪声映射
和系数
。更新函数
首先将噪声
和编码器输出结合起来:
。 然后,我们将合并后的信号输入 U-Net。
其次,我们还根据(其中
和
分别表示原始权重和新添加的权重)对 LoRA 适配器权重和跳跃连接的输出进行缩放。
最后,我们根据系数对重建损失进行缩放。

值得注意的是,对应于预训练模型的默认随机行为,在这种情况下,重构损失不强制执行。
对应于第 3.3 和 3.4 节所述的确定性转换。我们通过改变插值系数对图像转换模型进行微调。图 9 显示,这种微调使我们的模型能够在推理过程中通过采样不同的噪声产生不同的输出。
Experiments
我们在多个图像翻译任务中进行了广泛的实验,主要分为三大类。首先,我们将我们的方法与之前几种基于 GAN 和扩散模型的图像翻译方法进行了比较,结果表明我们的方法在定量和定性方面都更胜一筹。其次,我们在第 4.2 节中逐一分析了我们的非配对方法 CycleGAN-Turbo 的每个组件的有效性。最后,我们将在第 4.3 节中展示我们的方法是如何在配对设置下工作并产生不同的输出结果的。请在我们的 GitHub 页面https://github.com/GaParmar/img2img-turbo上查找代码、模型和互动演示。
Training details. 我们在驾驶数据集上的非配对模型的可训练参数总量为 330 MB,包括 LoRA 权重、零conv 层(zero-conv layer)和 U-Net 的第一个 conv 层。超参数和架构详情请参阅附录 D。
Datasets. 我们在两个常用数据集(Horse ↔ Zebra and Yosemite Summer ↔ Winter)和两个更高分辨率的驾驶数据集(来自 BDD100k [72] 和 DENSE [4]的白天 ↔ 夜晚和晴朗 ↔ 雾天)上进行了非配对翻译实验。对于前两个数据集,我们沿用 CycleGAN [77] 的方法,在训练时加载 286×286 图像并使用 256×256 随机裁剪。在推理过程中,我们直接在256 × 256 应用转换。对于驾驶数据集,我们在训练和推理过程中将所有图像的大小调整为 512 × 512。评估时,我们使用相应的验证集。
Evaluation Protocol. 有效的图像翻译方法必须满足两个关键标准: (1) 匹配目标域的数据分布;(2) 在翻译输出中保留输入图像的结构。我们使用 FID [16],按照 clean-FID 的实现方法 [43],对分布匹配进行评估。我们使用 DINO-StructDist [61]来评估是否符合第二项标准,它可以测量两幅图像在特征空间中的结构相似性。我们报告了所有 DINO 结构得分乘以 100 的结果。FID 分数越低,表明与参考目标分布的匹配度越高,真实度越高;DINO-Struct-Dist 分数越低,表明翻译后的图像能更准确地保留输入结构。FID 分值低而 DINO-Struct-Dist 高,表明一种方法无法保持输入结构。如果 DINO-Struct-Dist 分数较低,但 FID 分数较高,则表明一种方法几乎没有改变输入图像。将这两个分数结合起来考虑至关重要。此外,我们还比较了表 1 和表 2 中所有方法在 Nvidia RTX A6000 GPU 上的推理运行时间,并进行了人类感知研究。
Comparison to Unpaired Methods
我们将 CycleGAN-Turbo 与之前基于 GAN 的非配对图像翻译方法、零镜头(zero-shot)图像编辑方法以及使用其公开代码进行图像编辑训练的扩散模型进行了比较。定性地,图 5 和图 6 显示,无论是基于 GAN 还是基于扩散的现有方法,都很难在输出逼真度和结构保持之间取得适当的平衡。
Comparison to GAN-based methods. 我们将我们的方法与两个未配对的 GAN 模型--CycleGAN [77] 和 CUT [40] 进行了比较。我们在所有数据集上使用默认超参数对这些基线模型进行 100,000 步训练,并选择最佳检查点。表 1 和表 2 显示了八项非配对翻译任务的定量比较。CycleGAN 和 CUT 表现出有效的性能,在较简单的、以对象为中心的数据集上,如马 → 斑马(图 13),实现了较低的 FID 和 DINO-Structure 分数。在 FID 和 DINO-structure 距离指标方面,我们的方法略胜一筹。但是,对于更复杂的场景,如夜晚 → 白天,CycleGAN 和 CUT 的 FID 分数明显高于我们的方法,而且经常会出现不理想的假象(图 15)。
Comparison to diffusion-based editing methods. 接下来,我们在表 1 和表 2 中将我们的方法与几种基于扩散的方法进行比较。首先,我们考虑了最近的零镜头图像翻译方法,包括 SDEdit [35]、Plug-and-Play [62]、pix2pix-zero [42]、CycleDiffusion [67] 和 DDIB [59],这些方法使用预先训练好的文本到图像扩散模型,并通过不同的文本提示翻译图像。需要注意的是,最初的 DDIB 实现需要从头开始训练两个独立的特定领域扩散模型。为了提高其性能并进行公平的比较,我们用预先训练好的文本到图像模型取代了特定领域模型。我们还将其与 Instruct-pix2pix [5]进行了比较,后者是一个为基于文本的图像编辑而训练的条件扩散模型。
如表 1 和图 14 所示,在以对象为中心的数据集(如马→斑马)上,这些方法可以生成逼真的斑马,但却难以精确匹配对象的姿势,这一点可以从持续较大的 DINO 结构分数看出。在驾驶数据集上,这些编辑方法的表现明显较差,原因有三:(1) 模型难以生成包含多个物体的复杂场景;(2) 这些方法(Instruct-pix2pix 除外)需要先将图像反转为噪声图,从而引入了潜在的伪影;(3) 经过预训练的模型无法合成与驾驶数据集捕获的图像类似的街景图像。表 2 和图 16 显示,在所有四项驾驶翻译任务中,这些方法输出的图像质量较差,表现为 FID 分数较高,而且不符合输入图像结构,表现为 DINOStructure 距离值较高。
Human Preference Study 接下来,我们在 Amazon Mechanical Turk (AMT) 上进行了一项人类偏好研究,以评估不同方法生成的图像质量。我们使用了相关数据集的完整验证集,每次对比都由三名用户独立评估。我们将两个模型的输出并排展示,并要求用户在无限的时间内选择哪个模型更准确地遵循目标提示。例如,我们为 "从白天到黑夜 "的翻译任务收集了 1,500 张比较结果和 500 张验证图片。给用户的提示是 "哪张图片看起来更像夜间拍摄的真实驾驶场景图片?“
表 3 将我们的方法与基于 GAN 的最佳方法 CycleGAN [77] 和基于扩散的最佳方法 Instruct-Pix2Pix [5] 进行了比较。在所有数据集上,我们的方法都优于这两种基线方法,但 "晴到雾天 "翻译任务除外。在这种情况下,用户更喜欢 InstructPix2Pix 的结果,因为它输出的雾图像更具艺术性。然而,InstructPix2Pix 未能保留输入结构,这一点从其较高的 DINO-Struct 得分(7.6)和我们的得分(1.4)可以看出。此外,如表 2 所示,它的结果与目标雾数据集有很大偏差,FID 分数(170.8)比我们的(137.0)高。
Ablation Study
在此,我们通过表 4 和图 7 中的大量消融研究来展示我们算法设计的有效性。
Using pre-trained weights. 首先,我们评估了使用预训练网络的影响。在表 4 配置 A 中,我们在 "Horse ↔ Zebra "数据集上训练了一个未配对的模型,但使用的是随机初始化的权重,而不是预先训练的权重。如图 7 Config A 所示,如果不利用预先训练好的文本到图像模型的先验,输出图像就会显得不自然。
Different ways of adding conditioning inputs. 接下来,我们比较了向模型添加结构输入的三种方法。配置 B 使用 ControlNet 编码器[73],配置 C 使用 T2I 适配器[38],最后,配置 D 直接将输入图像馈送至基础网络,而不添加任何分支。配置 B 可获得与配置 D 类似的 FID。但是,它的 DINOStructure 距离也明显较高,这表明 ControlNet 编码器很难与输入的结构相匹配。从图 7 中也可以看出这一点;配置 B(第三行)不断改变场景结构并幻化出新的物体,例如在驾驶场景中幻化出部分建筑物,在马到斑马的转换中幻化出不自然的斑马图案。配置 C 使用轻量级 T2I-Adapter 来学习结构,其 FID 和 DINO-Struct 分数较低,输出的图像有一些伪影,结构保存较差。
Skip Connections and trainable encoder and decoder. 最后,我们可以通过表 4 和图 7 中 Config D 与我们的最终方法 CycleGAN-Turbo 的比较来了解跳跃连接的效果。在所有任务中,增加跳跃连接并联合训练编码器和解码器可以显著改善结构保持,尽管代价是 FID 略有增加。
Additional results. 有关其他数据集的其他消融研究、使用不同数量的训练图像进行模型训练的效果以及编码器-解码器微调的作用,请参见附录 A 和 C。
Extensions
Paired translation. 我们在一个由 30 万张艺术图片组成的社区收集数据集 [1] 上训练 Edge2Photo 和 Sketch2Photo 模型。我们提取了 Canny 边缘 [7] 和 HED 轮廓 [68]。由于我们的方法和基线使用的是不同的数据集,因此我们展示的是可视化比较,而不是进行 FID 评估。有关训练数据和预处理的更多细节见附录 D。
在图 8 中,我们将我们的配对方法 pix2pix-Turbo 与现有的一步法和多步法翻译方法进行了比较,其中包括两种使用潜在一致性模型 [34] 的一步法基线和使用 ControlNet 适配器的稳定扩散 - Turbo [54]。虽然这些方法可以在一步内产生结果,但它们的图像质量会下降。接下来,我们将其与使用 100 步稳定扩散的普通 ControlNet 进行比较。在 100 步 ControlNet 基准线上,我们还使用了无分类器引导和长描述性否定提示。如图 8 所示,与单步基线相比,这种方法能生成更令人满意的输出结果。我们的方法只需一次前向传递,无需负面提示或免分类器引导,即可生成令人满意的输出结果。
Generating diverse outputs. 最后,在图 9 中,我们展示了我们的方法可用于生成第 3.4 节所述的各种输出结果。在输入草图和用户提示相同的情况下,我们可以对不同的噪声地图进行采样,并生成多样化的多模态输出,例如不同风格的猫、背景的变化以及不同外壳图案的乌龟。
Discussion and Limitations
我们的工作表明,一步式预训练模型可以作为一个强大而通用的骨干模型,用于许多下游图像合成任务。通过各种 GANs 目标,可以将这些模型调整到新的任务和领域,而无需进行多步扩散训练。我们的模型训练只需要少量额外的可训练参数。
Limitations. 虽然我们的模型只需一个步骤就能产生直观的结果,但它也有局限性。首先,我们无法指定引导的强度,因为我们的骨干模型 SD-Turbo 并不使用无分类器引导。引导蒸馏[36]可能是实现引导控制的一个有前途的解决方案。其次,我们的方法不支持负提示,而负提示是减少伪影的一种便捷方法。第三,使用周期一致性损失和大容量生成器进行模型训练需要消耗大量内存。探索更高分辨率图像合成的单边方法[40]是有意义的下一步。
Acknowledgments. 我们感谢 Anurag Ghosh、Nupur Kumari、Sheng-YuWang、李沐阳、Sean Liu、Or Patashnik、George Cazenavette、Phillip Isola 和 Alyosha Efros 对我们的手稿进行了富有成效的讨论并提供了宝贵的反馈意见。这项工作得到了以色列通用汽车研究院、国家自然科学基金 IIS-2239076、Packard Fellowship 和 Adobe Research 的部分支持。
图
图 1:我们提出了一种通用方法,通过对抗学习将单步扩散模型(如 SD-Turbo [54])调整到新的任务和领域。这使我们能够充分利用预训练扩散模型的内部知识,同时实现高效推理(例如,512x512 图像只需 0.3 秒)。我们的单步图像到图像转换模型被称为 CycleGAN-Turbo 和 pix2pix-Turbo,可以在各种任务中分别合成非配对(上图)和配对设置(下图)的真实输出。

图 2:我们的生成器架构。我们将原始潜像扩散模型中的三个独立模块紧密集成到一个具有较小可训练权重的端到端网络中。这种架构允许我们将输入图像 x 转换为输出图像 y,同时保留输入场景结构。我们在每个模块中使用 LoRA 适配器[17],在输入和输出之间引入跳过连接和 Zero-Convs [73],并重新训练 U-Net 的第一层。蓝色方框表示可训练层。半透明层被冻结。同一生成器可用于不同的 GAN 目标。
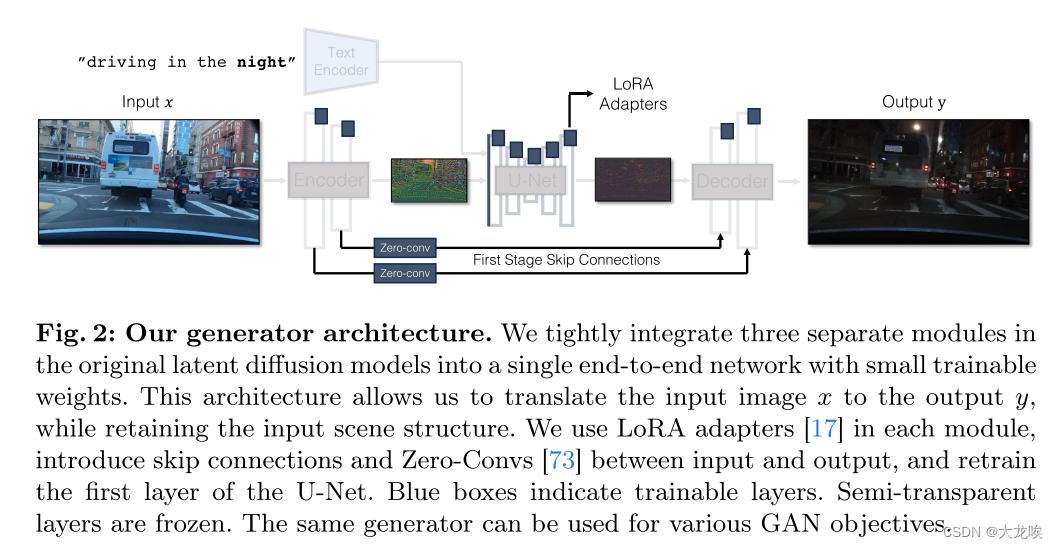
图 3:(左)一步模型学习将输入噪声映射到输出图像。请注意,SD2.1-Turbo 的特征从噪声映射形成了一个连贯的布局(a)。(右图)不幸的是,添加条件编码器分支[38,73]会导致冲突,因为来自新分支的特征(b)与原始特征(a)的布局不同。这种冲突会恶化 SD-Turbo 解码器中的下游特征(c),影响输出质量。使用 PCA 对特征图进行可视化处理。
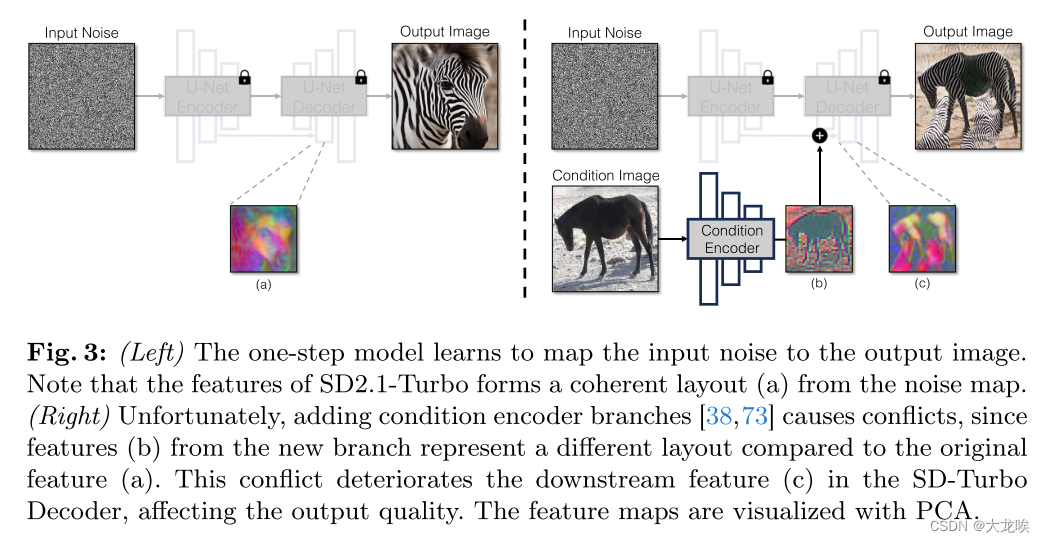
图 4:跳跃连接有助于保留细节。我们将使用和不使用跳跃连接训练的昼夜模型的输出可视化。可以清楚地看到,加入跳跃连接后,输入的日间图像细节得以保留。夜间图像的放大裁剪经过 1.5 的伽玛调整,以便于可视化。
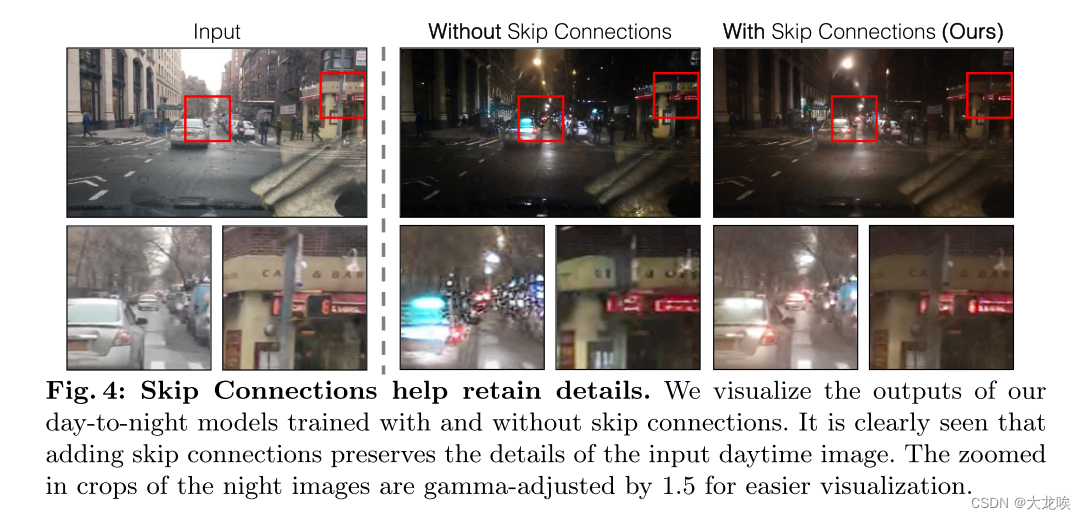
图 5:在 256 × 256 数据集上与基线的比较。我们将非配对方法与 CUT [40] 和 Instruct-pix2pix [5]进行了比较,它们分别是基于 GAN 的最佳方法和扩散方法。CUT 输出的图像通常包含严重的图像伪影。而 Instruct-pix2pix 则无法保留输入图像的结构。

图 6:在驾驶数据集(512 × 512)上与基线的比较。我们将我们的非配对翻译方法与 CycleGAN [77] 和 Instruct-pix2pix [5]进行了比较,它们是该数据集上性能最好的基于 GAN 的方法和扩散方法。CycleGAN 没有使用现有的文本到图像模型,因此会在输出结果中产生人工痕迹,例如在从白天到黑夜的翻译中出现天空区域。相比之下,Instruct-pix2pix 使用了一个大型文本到图像模型,但没有使用未配对的数据集。因此,Instructpix2pix 的输出结果看起来很不自然,与我们数据集中的图像大相径庭。

图 7:消融单个组件。与表 4 所述的其他设计方案相比,我们的最终方案实现了最佳的内容保存和逼真度。
图 8:配对边缘到图像任务(512 × 512)的比较。与现有的单步方法相比,我们的方法(运行时间:0.29 秒)达到了更高的真实度,与 100 步 ControlNet(运行时间:18.85 秒)相比也具有竞争力。

图 9:产生不同的输出。通过改变输入噪声图,我们的方法可以从相同的输入调节中产生不同的输出。此外,还可以通过改变文本调节来控制输出风格。

图 10:消融单个组件。在 Horse ↔ Zebra 数据集上的其他消融结果。下行所示为我们的最终方法,取得了最佳的翻译效果。

图 11:消融单个组件。昼夜转换的其他消融结果。最底下一行显示的是我们的方法,它生成的翻译效果最令人信服,细节保留得最好。请放大查看差异。

图 12:消融单个组件。黑夜→白天平移的其他消融结果。最下面一行显示的是我们的方法,它生成的平移效果最令人信服,细节保留得最好。请放大查看差异。

图 13:与基于 GAN 的基线比较。与 CycleGAN 和 CUT 在 Horse ↔ Zebra 翻译任务上的额外比较。

图 14:与基于扩散的基线比较。在 "马" ↔"斑马 "翻译任务中与基于扩散的基线进行的其他比较。

图 15:与基于 GAN 的基线比较。与 CycleGAN 和 CUT 在 Day → Night 翻译任务上的额外比较。

图 16:与基于扩散的基线比较。在 "昼→夜 "翻译任务中与几种基于扩散的基线进行的额外比较。

图 17:相同输入图像和不同噪声图的不同输出结果。我们观察到,噪声图并没有改变图像结构,这表明噪声在很大程度上被忽略了。

图 18:在不添加跳转连接的情况下对编码器和解码器进行微调。在这里,我们对 VAE 的编码器和解码器进行了微调,但没有添加跳转连接(中间一列)。在没有跳转连接的情况下,该方法很难保留重要的细节,例如上行图像中街道标志上的文字 "ON RED"、商店标志上的文字以及下行图像中的行人过街标志。相比之下,我们的方法通过跳转连接更好地保留了这些细节。

表
表 1:在标准 CycleGAN 数据集(256 × 256)上进行的评估。在标准 CycleGAN 数据集上与之前基于 GAN 和基于 Diffusion 的方法进行比较,使用 FID 衡量图像质量和分布对齐情况,使用 DINO-Struct. 我们的方法在所有任务中实现了最低的 DINO-Struct. 循环扩散法(Cycle-Diffusion)的 FID 稍好,但代价是整体翻译较差.
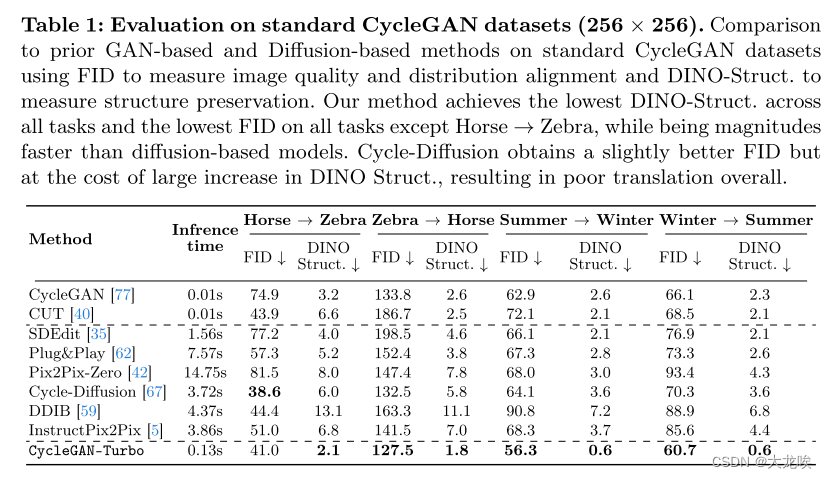
表 2:在 512 × 512 驾驶数据集上的比较。在所有驾驶数据集上,我们的方法都优于所有基于 GAN 和基于扩散的基线方法。InstructPix2pix 在 "日"→"夜 "数据集上的 DINO-Struct 略低,但 FID 却高得多,因此与目标分布不匹配。Plug&Play 在夜间→白天时也有类似的结果。
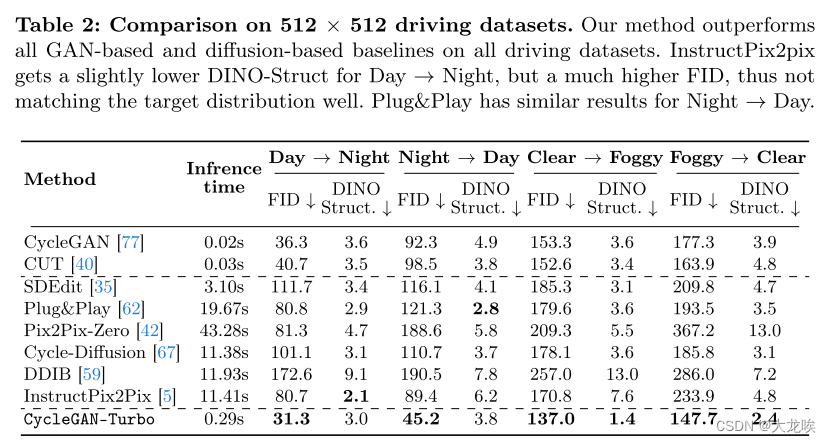
表 3:人类偏好评估。我们进行了一项研究,要求用户挑选看起来更像目标领域的图片。我们让 3 位不同的用户对验证中的每张图片进行评分。在所有数据集中,我们的方法都更受欢迎,但 "晴转雾天 "数据集除外。
表 4:从 "马 "到 "斑马 "的消融。括号中的数值反映了与我们的最终方法相比的相对变化。 首先,Conf.A 使用随机初始化的权重训练非配对翻译模型,导致 FID 大幅增加。接下来,Conf. B、C 和 D 尝试了不同的输入类型,结果表明直接输入的性能最好。最后,我们的方法在 Conf. 最后,我们的方法将跳过连接添加到Conf. D,在结构保持性方面有了改善。其他任务的消融情况见附录 A。
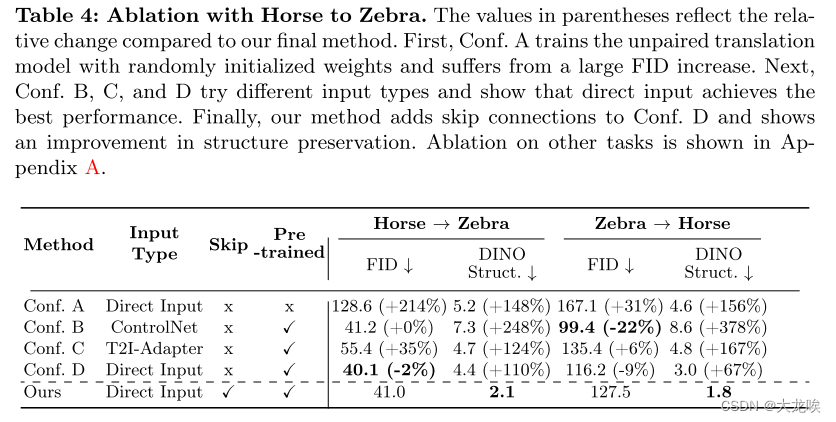
表 5:昼夜消融。括号中的数值反映了与我们的最终方法相比的相对变化。首先,Conf.A 使用随机初始化权重训练非配对翻译模型,导致 FID 大幅增加。接下来,Conf. B、C 和 D 尝试了不同的输入类型,结果表明直接输入实现了最佳性能。最后,我们的方法在 Conf.D 中添加了跳转连接,结果表明在分布匹配和结构保持方面都有所改进。
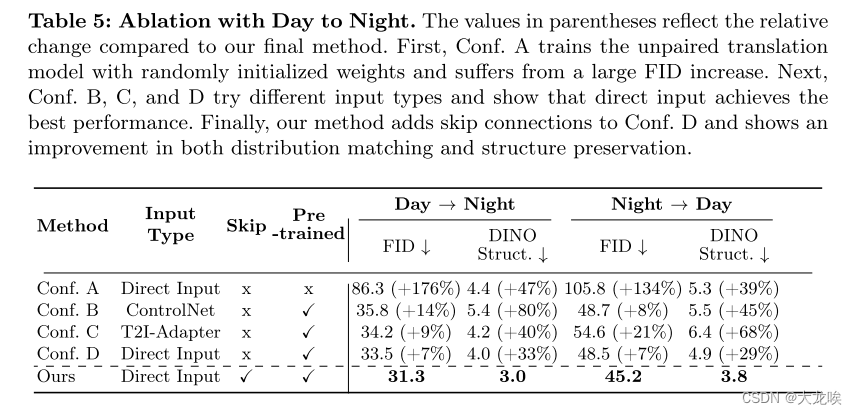
表 6:使用不同数量的输入图像进行训练。

Appendix
接下来,我们从 A 部分开始,提供更多数据集上的消融研究结果。B 部分将对所有基于 GAN 的基线和基于 Diffusion 的基线进行更多比较。C 部分展示了对条件编码器冲突、不同数据集大小的影响以及编码器-解码器微调作用的额外分析。最后,我们将在 D 部分提供超参数和训练细节。
A Additional Ablation Study
主论文中的表 3 显示了对 "马到斑马 "翻译的消融研究结果。我们在图 10 中展示了该数据集的更多定性消减结果。接下来,我们在图 11、图 12 和表 5 中对 "从白天到黑夜 "的翻译进行了同样的定性消减。与正文类似,我们比较了四种变体:(1) 配置 A 使用随机初始化权重而非预先训练的权重;(2) 配置 B 使用 ControlNet 编码器 [73];(3) 配置 C 使用 T2I-Adapter [38];(4) 配置 D 直接将输入图像馈送至基础网络而不跳转连接。
在分布匹配(FID)和结构保持(DINO 结构距离)方面,我们的完整方法优于所有其他变体。
B Additional Baseline Comparisons
主论文中的图 5 和图 6 显示了我们的方法与表现最好的 GAN 基线和表现最好的基于扩散的基线的比较。在此,我们还在图 13 和图 15 中展示了与所有 GAN 基线的定性比较,并在图 14 和图 16 中展示了与所有基于扩散的基线的定性比较。在保留输入图像结构的同时,我们的方法始终能产生更逼真的输出结果。
C Additional Analysis
Conflict with Condition Encoder. 主论文中的图 3 展示了通过独立编码器添加条件图像时的冲突特征。在这里,我们展示了使用条件编码器(如主论文图 3 所示)会导致原始网络被忽略。在图 17 中,我们展示了不同噪声图但条件图像相同的输出结果。不同的噪声图产生了感知上相似的输出图像,这表明原始的 SD-Turbo 编码器特征已被忽略。
Varying the Dataset Size. 接下来,我们将评估我们的方法在不同规模的数据集上的有效性。我们使用日夜转换数据集,其中包括 36,728 张日间图像和 27,971 张夜间图像。为了了解数据集大小对性能的影响,我们在逐渐缩小的原始数据集子集上训练了三个额外的模型: 1,000 张图像、100 张图像,最后是 10 张图像。表 6 显示,减少训练图像的数量会导致 FID 略有增加,但在所有不同的设置下,结构保持基本不变。这表明我们的模型可以在小型数据集上进行训练。
Role of Skip Connections. 此外,我们还评估了跳转连接的作用,即在不添加跳转连接的情况下对 VAE 编码器和解码器进行微调的基线。图 18 显示,该基线无法保留文字和路标等精细细节。
D Training Details
Unpaired translation. 在所有非配对翻译评估中,我们使用了以下四个数据集。对于日间和夜间数据集,我们使用测试时相应验证中的 500 张图像。雾天图像的验证集包括来自 DENSE 数据集的 50 幅图像。
Horse ↔ Zebra: 按照 CycleGAN [77],我们使用 Imagenet [10] 中野马类的 939 幅图像和斑马类的 1177 幅图像。
Yosemite Winter ↔ Summer: 我们使用 CycleGAN [77] 中从 Flickr 收集的 854 张冬季Yosemite 照片和 1273 张夏季Yosemite 照片。
Day↔ Night: 我们使用 BDD100k 数据集 [72] 中的白天和夜晚子集来完成这项任务。
Clear↔ Foggy: 我们使用 BDD100k 中的日间晴朗图像(12,454 张)和 DENSE 数据集[4]中 "浓雾 "子集中的 572 张浓雾图像。
在所有非配对翻译实验中,我们使用了学习率为 1e-6、批量大小为 8、和
的Adam求解器 [25]。
Paired translation. 配对翻译的训练目标包括主论文第 3.4 节中提到的三种损失:重建损失 (L2 和 LPIPS)、GAN 损失
和 CLIP 文本图像对齐损失
。完整的学习目标如下所示。我们使用
,
。
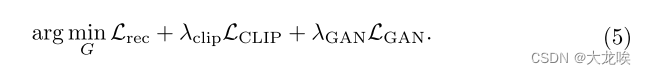
我们对 pix2pix-Turbo 配对方法进行了两项任务的训练: Edge2Image 和 Sketch2Image。这两个任务使用的是同一个社区收集的艺术图像数据集 [1],并遵循 ControlNet [73] 的预处理方法。
Edge2Image 我们使用 Canny 边缘检测器 [7],在训练时使用随机阈值。我们使用 Adam 优化器进行训练,学习率为 1e-5,批大小为 40,共训练 7500 步。
Sketch2Image 我们首先使用 HED 检测器生成合成草图,然后应用随机阈值、非最大抑制和随机形态变换等数据增强技术。我们的 Sketch2Image 使用 Edge2Image 模型进行初始化,并使用相同的学习率、批量大小和优化器进行 5000 步微调。
其他
(2023,SDXL-Turbo,少步生成,对抗损失,分数蒸馏损失)对抗扩散蒸馏_score distillation sampling-CSDN博客
















 3840
3840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









