







 研究者提出了一种通过单步扩散模型和对抗学习策略,解决传统模型速度慢及依赖于配对数据的问题。CycleGAN-Turbo和pix2pix-Turbo在无配对和配对场景下展示了优越性能,特别是在图像转换任务中。该工作表明,单步模型可作为多任务GAN学习的有效基础。
研究者提出了一种通过单步扩散模型和对抗学习策略,解决传统模型速度慢及依赖于配对数据的问题。CycleGAN-Turbo和pix2pix-Turbo在无配对和配对场景下展示了优越性能,特别是在图像转换任务中。该工作表明,单步模型可作为多任务GAN学习的有效基础。
One-Step Image Translation with Text-to-Image Models
2024.3.18
CMU and Adobe, arXiv 2403.12036
Cat Sketching
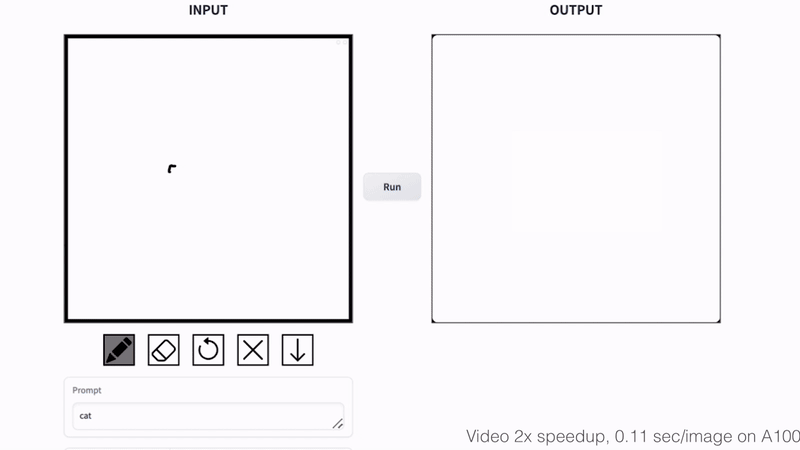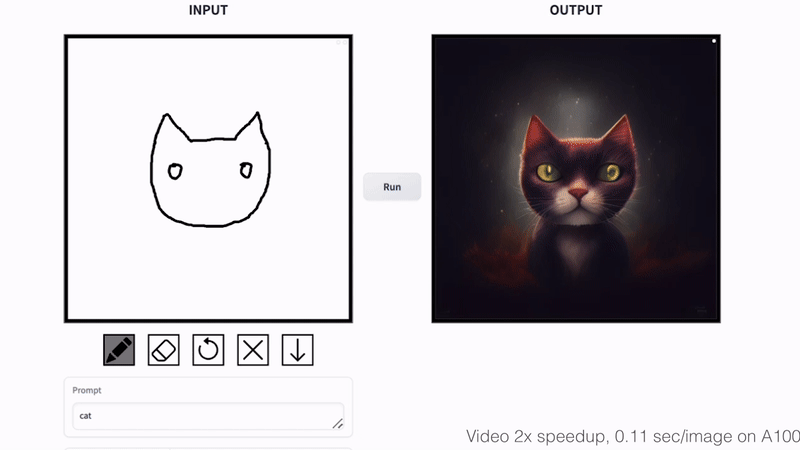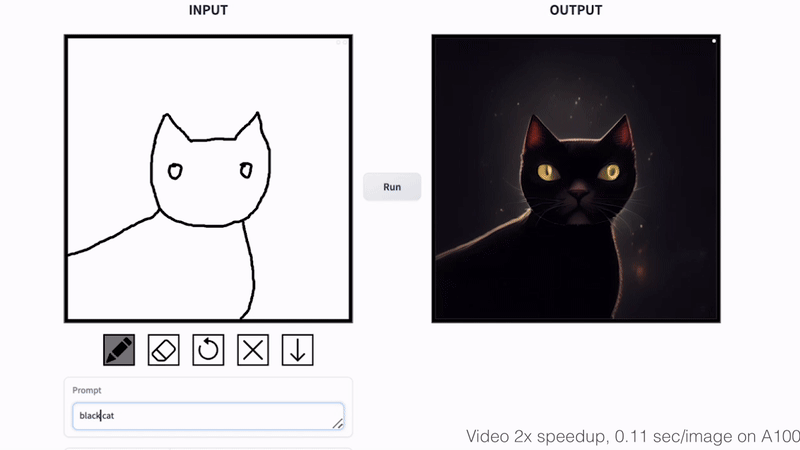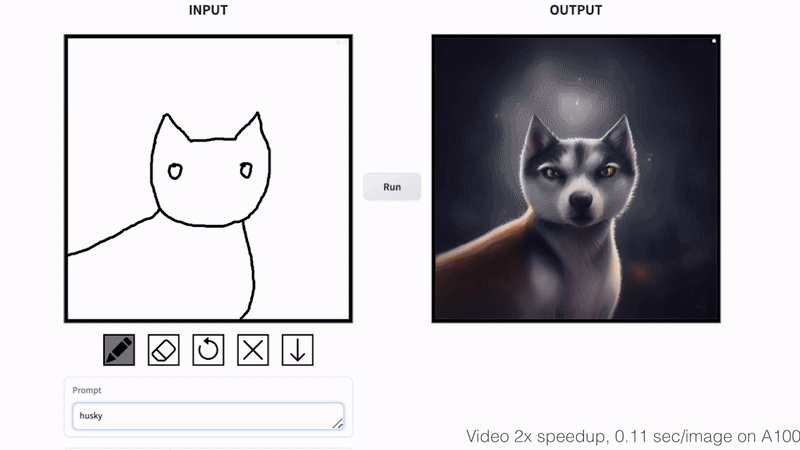
Fish Sketching
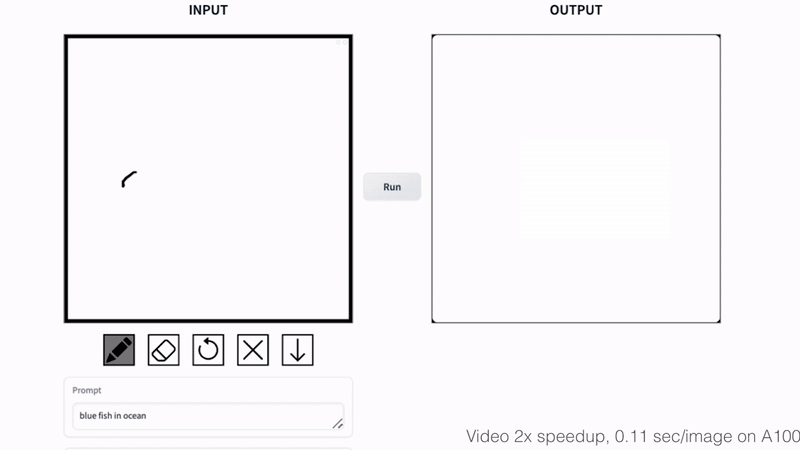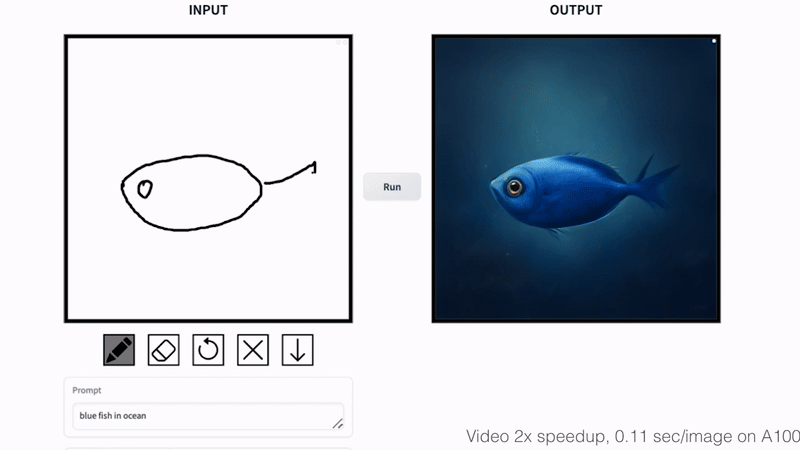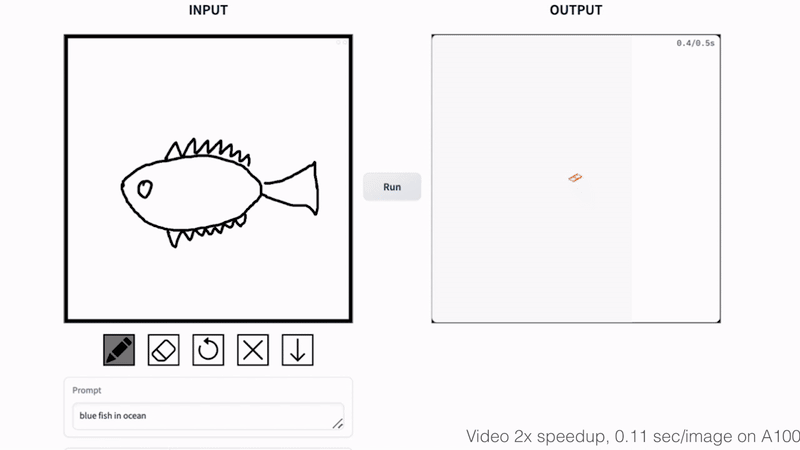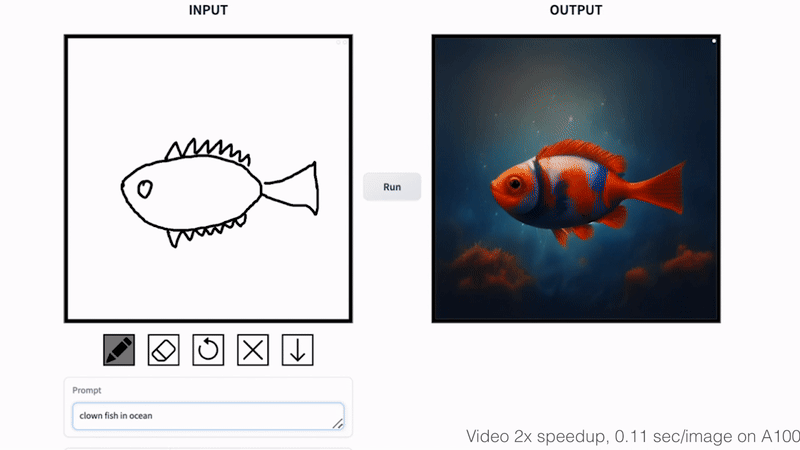

Abstract
In this work, we address two limitations of existing conditional diffusion models: their slow inference speed due to the iterative denoising process and their reliance on paired data for model fine-tuning. To tackle these issues, we introduce a general method for adapting a single-step diffusion model to new tasks and domains through adversarial learning objectives. Specifically, we consolidate various modules of the vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, enhancing its ability to preserve the input image structure while reducing overfitting. We demonstrate that, for unpaired settings, our model CycleGAN-Turbo outperforms existing GAN-based and diffusion-based methods for various scene translation tasks, such as day-to-night conversion and adding/removing weather effects like fog, snow, and rain. We extend our method to paired settings, where our model pix2pix-Turbo is on par with recent works like Control-Net for Sketch2Photo and Edge2Image, but with a single-step inference. This work suggests that single-step diffusion models can serve as strong backbones for a range of GAN learning objectives. Our code and models are available at https://github.com/GaParmar/img2img-turbo.
在这项工作中,我们解决了现有条件扩散模型的两个局限性:
- 迭代去噪过程导致的推理速度慢,
- 以及模型微调对配对数据的依赖。
为了解决这些问题,我们引入了一种通用方法,通过对抗学习目标将单步扩散模型适应新任务和新领域。
具体来说,我们将 vanilla 潜在扩散模型的各种模块整合到一个具有较小可训练权重的端到端生成器网络中,从而增强了其保持输入图像结构的能力,同时减少了过拟合。
我们证明,在非配对环境下,我们的模型 CycleGAN-Turbo 在各种场景转换任务中的表现优于现有的基于 GAN 和基于扩散的方法,如昼夜转换和添加/移除雾、雪、雨等天气效果。
我们将方法扩展到了配对设置,我们的模型 pix2pix-Turbo 与最近用于 Sketch2Photo 和 Edge2Image 的 Control-Net 等作品不相上下,但只需一步推理。
这项工作表明,单步扩散模型可以作为一系列 GAN 学习目标的强大支柱。
Method
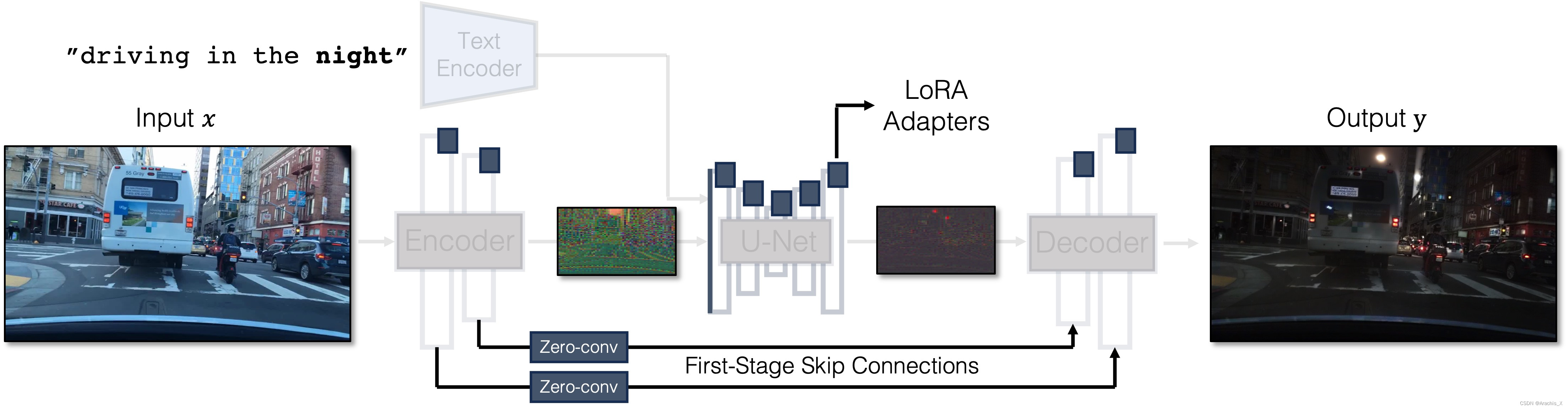
Our Generator Architecture: We tightly integrate three separate modules in the original latent diffusion models into a single end-to-end network with small trainable weights. This architecture allows us to translate the input image x to the output y, while retaining the input scene structure. We use LoRA adapters in each module, introduce skip connections and Zero-Convs between input and output, and retrain the first layer of the U-Net. Blue boxes indicate trainable layers. Semi-transparent layers are frozen. The same generator can be used for various GAN objectives.
我们的生成器架构: 我们将原始潜扩散模型中的三个独立模块紧密集成到一个具有较小可训练权重的端到端网络中。
这种架构允许我们将输入图像 x 转换为输出图像 y,同时保留输入场景结构。
-
我们在每个模块中使用 LoRA 适配器,在输入和输出之间引入跳过连接和 Zero-Convs,并重新训练 U-Net 的第一层。
-
蓝色方框表示可训练层。半透明层被冻结。
-
同一生成器可用于不同的 GAN 目标。
Results
Paired Translation with pix2pix-turbo
Edge to Image

Generating Diverse Outputs
By varying the input noise map, our method can generate diverse outputs from the same input conditioning. The output style can be controlled by changing the text prompt.
通过改变输入噪声图,我们的方法可以从相同的输入条件中产生不同的输出。
输出风格可通过改变文本提示来控制。

Unpaired Translation with CycleGAN-Turbo
Day to Night

Night to Day

Clear to Rainy

Rainy to Clear

使用
具体使用见项目地址

















 9417
9417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









