







本文提出了一种称为数据集蒸馏的方法:保持模型不变,尝试从一个大型训练数据集提取知识到一个小的数据集。其思想是合成少量的数据(每个类别一个数据),这些数据不需要来自正确的数据分布,但是当作为模型的训练数据时,训练得到的模型将近似于在原始数据上训练的模型。 |
论文地址:https://arxiv.org/pdf/1811.10959.pdf
代码地址:https://github.com/SsnL/dataset-distillation
算法细节
标准的训练通常是在小批量上做随机梯度下降,每一步t从训练数据中取一个
m
i
n
i
b
a
t
c
h
x
t
=
{
x
t
,
j
}
j
=
1
n
minibatch x_{t}= \{x_{t,j}\}^{n}_{j=1}
minibatchxt={xt,j}j=1n来进行更新,通常需要几千部甚至百万步:
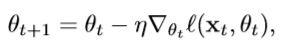
这篇文章的重点是学习到一个合成数据
x
~
=
{
x
~
i
}
i
=
1
M
\tilde{x}=\{\tilde{x}_{i}\}^{M}_{i=1}
x~={x~i}i=1M,和学习率
η
~
\tilde{\eta}
η~。因此一个梯度下降步骤为
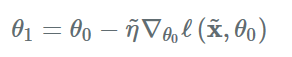
给定一个初始参数
θ
0
\theta_{0}
θ0,最小化以下目标函数来获得合成数据集
x
~
\tilde{x}
x~和学习率
θ
~
\tilde{\theta}
θ~。因为作者想要通过少量的梯度下降便得到一个比较好的模型,因此学习率既不能太大,也不能太小,因而需要学习获得。
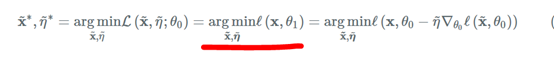
上面画红线的部分中,损失函数中的
θ
1
\theta_{1}
θ1是先通过合成数据集
x
~
\tilde{x}
x~进行一步梯度下降得到的。因为我们的目的是想要使用合成数据
x
~
\tilde{x}
x~训练出的模型和使用原始数据训练出的模型效果一样好(即损失尽可能小),所以用损失函数对
x
~
\tilde{x}
x~和
η
~
\tilde{\eta}
η~进行求导,使用标准的梯度下降来对
x
~
\tilde{x}
x~和
η
~
\tilde{\eta}
η~进行优化更新。从而获得更好的
x
~
\tilde{x}
x~和
η
~
\tilde{\eta}
η~以及模型的参数。对于数据的其它部分,例如标签,只把它固定而不进行学习。
在上面中是假设模型初始的参数是固定的,不能很好的泛化到其它的模型初始值(我的理解是使用合成数据
x
~
\tilde{x}
x~训练出来的模型的初始化参数需要和得到合成数据
x
~
\tilde{x}
x~的初始化参数是一样的,因此这样得到的合成数据并不能很很好地泛化到其它初始化参数)。而且得到的合成数据看起来像噪声,这是因为合成数据不仅编码了原始数据,还编码了固定的初始化参数
θ
0
\theta_{0}
θ0。为了解决这个问题,文章提出随机初始化参数,其中网络参数
θ
0
\theta_{0}
θ0是从分布
p
(
θ
0
)
p(\theta_{0})
p(θ0)中随机采样,实验表明在随机初始化模型参数条件下得到的合成数据集在任意的模型初始参数下效果也是不错的,但是没有固定参数的效果好。另外。合成数据通常看起来有一定的信息,因为合成数据编码了每个类别的判别特征。

在上面的图片中,第一行用的是固定初始化模型参数。第二行用的是随机初始化模型参数。固定初始化模型参数的更好,但是泛化能力不好,合成的图片也很模糊。随机初始化模型参数的效果还不错,有更好的泛化能力,合成的图片也包含更多的特征。
除了固定初始化模型参数和随机初始化模型参数外,文章还提出了使用其他任务中预训练好的模型参数来模型的参数,所以总共有以下4种方式构建初始化参数,其中最后一种方式的效果是最好的。

下图为dataset distillation的基本算法

第6行:用合成数据集
x
~
\tilde{x}
x~对模型参数进行更新。
第7行:求原始数据原始数据在此模型参数下的损失。
第9行:使用标准的梯度下降对
x
~
\tilde{x}
x~和
η
~
\tilde{\eta}
η~进行更新。
改进方法:
- 连续使用多个梯度下降,将算法1中的第6行改为下列形式,然后第9行修改为反向传播到所有步
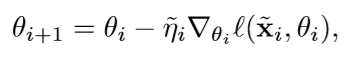
- 训练多次epoch,在算法1中的第1行到第9行为一个epoch。
下面的代码是该算法最核心的部分,算法1中的第6、7行在forward函数,第9行在backward函数
import logging
import time
import numpy as np
import torch
import torch.nn.functional as F
import torch.optim as optim
from basics import task_loss, final_objective_loss, evaluate_steps
from utils.distributed import broadcast_coalesced, all_reduce_coalesced
from utils.io import save_results
def permute_list(list):
indices = np.random.permutation(len(list))
return [list[i] for i in indices]
class Trainer(object):
def __init__(self, state, models):
self.state = state
self.models = models
self.num_data_steps = state.distill_steps # 一个epoch需要的步数 default=10
self.T = state.distill_steps * state.distill_epochs # 总共需要的步数
self.num_per_step = state.num_classes * state.distilled_images_per_class_per_step # 每一步图片的数量 = 标签种类数量 * 每一步一个标签所需的图片数量
assert state.distill_lr >= 0, 'distill_lr must >= 0'
self.init_data_optim()
def init_data_optim(self):
self.params = []
state = self.state
optim_lr = state.lr
# 设置生成一个epoch图片的标签(一个epoch包含num_data_steps个step)
self.labels = []
distill_label = torch.arange(state.num_classes, dtype=torch.long, device=state.device) \
.repeat(state.distilled_images_per_class_per_step, 1) # tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
distill_label = distill_label.t().reshape(-1) # [0, 0, ..., 1, 1, ...]
for _ in range(self.num_data_steps):
self.labels.append(distill_label)
self.all_labels = torch.cat(self.labels)
# 设置生成一个epoch的图片
self.data = []
for _ in range(self.num_data_steps):
distill_data = torch.randn(self.num_per_step, state.nc, state.input_size, state.input_size,
device=state.device, requires_grad=True)
self.data.append(distill_data)
self.params.append(distill_data)
# 设置生成图片的学习率
# undo the softplus + threshold
raw_init_distill_lr = torch.tensor(state.distill_lr, device=state.device)
# 生成T个step的初始学习率
raw_init_distill_lr = raw_init_distill_lr.repeat(self.T, 1)
self.raw_distill_lrs = raw_init_distill_lr.expm1_().log_().requires_grad_()
self.params.append(self.raw_distill_lrs)
assert len(self.params) > 0, "must have at least 1 parameter"
# now all the params are in self.params, sync if using distributed
if state.distributed: # 如果是分布式训练
broadcast_coalesced(self.params)
logging.info("parameters broadcast done!")
# 优化器设置
self.optimizer = optim.Adam(self.params, lr=state.lr, betas=(0.5, 0.999))
# 调整学习率设置
self.scheduler = optim.lr_scheduler.StepLR(self.optimizer, step_size=state.decay_epochs,
gamma=state.decay_factor)
for p in self.params:
p.grad = torch.zeros_like(p) # 产生一个维度和p一样大小的全0数组
# 得到一个step的合成数据
def get_steps(self):
# 得到一个generator,每次得到每一个epoch的一个step的数据
data_label_iterable = (x for _ in range(self.state.distill_epochs) for x in zip(self.data, self.labels))
# print(self.state.distill_epochs,len(self.data),len(self.labels)) # 3,10,10
lrs = F.softplus(self.raw_distill_lrs).unbind()
steps = []
# 依次取一个epoch的一个step
for (data, label), lr in zip(data_label_iterable, lrs):
steps.append((data, label, lr))
# print(steps[0][0].shape) # torch.Size([10, 1, 28, 28])
return steps
def forward(self, model, rdata, rlabel, steps):
state = self.state
# forward
model.train()
w = model.get_param()
params = [w]
gws = []
# Compute updated parameter with GD
for step_i, (data, label, lr) in enumerate(steps):
with torch.enable_grad():
# 测试模型在w参数下在蒸馏数据下的效果
output = model.forward_with_param(data, w)
loss = task_loss(state, output, label)
gw, = torch.autograd.grad(loss, w, lr.squeeze(), create_graph=True) # 求loss关于w的导数
with torch.no_grad():
# new_x = w - gw 获得更新后的参数
new_w = w.sub(gw).requires_grad_()
params.append(new_w)
gws.append(gw)
w = new_w
# Evaluate the objective function on real training data
model.eval()
output = model.forward_with_param(rdata, params[-1])
ll = final_objective_loss(state, output, rlabel)
return ll, (ll, params, gws) # 损失值数组 每次更新后的参数数组 每次更新的梯度数组
def backward(self, model, rdata, rlabel, steps, saved_for_backward):
l, params, gws = saved_for_backward # 损失值数组 每次更新后的参数数组 每次更新的梯度数组
state = self.state
datas = []
gdatas = []
lrs = []
glrs = []
dw, = torch.autograd.grad(l, (params[-1],))
# backward
model.train()
# Notation:
# math: \grad is \nabla
# symbol: d* means the gradient of final L w.r.t. *
# dw is \d L / \dw
# dgw is \d L / \d (\grad_w_t L_t )
# We fold lr as part of the input to the step-wise loss
#
# gw_t = \grad_w_t L_t (1)
# w_{t+1} = w_t - gw_t (2)
#
# Invariants at beginning of each iteration:
# ws are BEFORE applying gradient descent in this step
# Gradients dw is w.r.t. the updated ws AFTER this step
# dw = \d L / d w_{t+1}
for (data, label, lr), w, gw in reversed(list(zip(steps, params, gws))):
# hvp_in are the tensors we need gradients w.r.t. final L:
# lr (if learning)
# data
# ws (PRE-GD) (needed for next step)
#
# source of gradients can be from:
# gw, the gradient in this step, whose gradients come from:
# the POST-GD updated ws
hvp_in = [w]
hvp_in.append(data)
hvp_in.append(lr)
dgw = dw.neg() # gw is already weighted by lr, so simple negation .neg()表示取相反数
hvp_grad = torch.autograd.grad(
outputs=(gw,),
inputs=hvp_in,
grad_outputs=(dgw,)
)
# Update for next iteration, i.e., previous step
with torch.no_grad():
# Save the computed gdata and glrs
datas.append(data)
gdatas.append(hvp_grad[1])
lrs.append(lr)
glrs.append(hvp_grad[2])
# Update for next iteration, i.e., previous step
# Update dw
# dw becomes the gradients w.r.t. the updated w for previous step
dw.add_(hvp_grad[0])
return datas, gdatas, lrs, glrs
def accumulate_grad(self, grad_infos):
bwd_out = []
bwd_grad = []
for datas, gdatas, lrs, glrs in grad_infos:
bwd_out += list(lrs)
bwd_grad += list(glrs)
for d, g in zip(datas, gdatas):
d.grad.add_(g)
if len(bwd_out) > 0:
torch.autograd.backward(bwd_out, bwd_grad)
# 保存生成的图片和学习率
def save_results(self, steps=None, visualize=True, subfolder=''):
with torch.no_grad():
steps = steps or self.get_steps()
save_results(self.state, steps, visualize=visualize, subfolder=subfolder)
def __call__(self):
return self.train()
def prefetch_train_loader_iter(self):
state = self.state
device = state.device
# 生成一个train_loader迭代器
train_iter = iter(state.train_loader)
# 对每一个epoch (default: 400)
for epoch in range(state.epochs):
niter = len(train_iter)
print(niter)
prefetch_it = max(0, niter - 2)
for it, val in enumerate(train_iter):
# Prefetch (start workers) at the end of epoch BEFORE yielding
# 如果蒸馏数据集即将训练完一次,则再训练一次
if it == prefetch_it and epoch < state.epochs - 1:
train_iter = iter(state.train_loader)
yield epoch, it, val
def train(self):
state = self.state
device = state.device
train_loader = state.train_loader
sample_n_nets = state.local_sample_n_nets
grad_divisor = state.sample_n_nets # i.e., global sample_n_nets
ckpt_int = state.checkpoint_interval # 检查点间隔
data_t0 = time.time()
# 需要蒸馏的数据集的每一个epoch
for epoch, it, (rdata, rlabel) in self.prefetch_train_loader_iter(): # 需要蒸馏的数据集
# print(rdata.shape, rlabel.shape) #(torch.Size([1024, 1, 28, 28]), torch.Size([1024]))
data_t = time.time() - data_t0
# it=0表示蒸馏数据集已经训练一遍了
if it == 0:
# 调整学习率
self.scheduler.step()
# 如果蒸馏数据集训练一遍并且该epoch为检查点
if it == 0 and ((ckpt_int >= 0 and epoch % ckpt_int == 0) or epoch == 0):
with torch.no_grad():
steps = self.get_steps() # 获得3个epoch的生成图片信息
# 保存生成的图片和学习率
self.save_results(steps=steps, subfolder='checkpoints/epoch{:04d}'.format(epoch))
# 评估模型用蒸馏数据集训练前和训练后的效果
evaluate_steps(state, steps, 'Begin of epoch {}'.format(epoch))
do_log_this_iter = it == 0 or (state.log_interval >= 0 and it % state.log_interval == 0)
self.optimizer.zero_grad()
# 获得需要蒸馏的数据集
rdata, rlabel = rdata.to(device, non_blocking=True), rlabel.to(device, non_blocking=True)
if sample_n_nets == state.local_n_nets:
tmodels = self.models
else:
idxs = np.random.choice(state.local_n_nets, sample_n_nets, replace=False)
tmodels = [self.models[i] for i in idxs]
t0 = time.time()
losses = []
steps = self.get_steps()
# activate everything needed to run on this process
grad_infos = []
for model in tmodels:
if state.train_nets_type == 'unknown_init':
model.reset(state)
l, saved = self.forward(model, rdata, rlabel, steps)
losses.append(l.detach())
# 获得生成图片和学习率的更新梯度
grad_infos.append(self.backward(model, rdata, rlabel, steps, saved))
del l, saved
# 更新生成图片和学习率
self.accumulate_grad(grad_infos)
# all reduce if needed
# average grad
all_reduce_tensors = [p.grad for p in self.params]
# 如果记录这个iteration
if do_log_this_iter:
losses = torch.stack(losses, 0).sum()
all_reduce_tensors.append(losses)
# 如果是分布式
if state.distributed:
all_reduce_coalesced(all_reduce_tensors, grad_divisor)
else:
for t in all_reduce_tensors:
t.div_(grad_divisor)
# opt step
self.optimizer.step()
t = time.time() - t0
if do_log_this_iter:
loss = losses.item()
logging.info((
'Epoch: {:4d} [{:7d}/{:7d} ({:2.0f}%)]\tLoss: {:.4f}\t'
'Data Time: {:.2f}s\tTrain Time: {:.2f}s'
).format(
epoch, it * train_loader.batch_size, len(train_loader.dataset),
100. * it / len(train_loader), loss, data_t, t,
))
if loss != loss: # nan
raise RuntimeError('loss became NaN')
del steps, grad_infos, losses, all_reduce_tensors
data_t0 = time.time()
with torch.no_grad():
steps = self.get_steps()
self.save_results(steps)
return steps
def distill(state, models):
return Trainer(state, models).train()















 5390
5390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









