






Dataset Distillation
论文:arxiv.org/pdf/1811.10959.pdf
代码:https://github.com/SsnL/dataset-distillation
- 保持模型固定,将大训练集中的知识提炼成小训练集
- 小数据集不需要与原始大数据集相同分布
- 在给定固定网络初始化的情况下,只需几个梯度下降步骤即可实现接近原始性能
3.1 Optimizing Distilled Data
- 标准训练通常应用minibatch随机梯度下降或其变体。
- 在每个step
t
t
t,对一个minibatch训练数据
x
t
=
[
x
t
,
j
]
j
−
1
n
x_t=[x_{t,j}]_{j-1}^n
xt=[xt,j]j−1n进行采样,以将当前参数更新为:
θ t + 1 = θ t − η ▽ θ t ℓ ( x t , θ t ) \theta_{t+1}=\theta_t-\eta\triangledown_{\theta_t}\ell(x_t,\theta_t) θt+1=θt−η▽θtℓ(xt,θt)其中, η \eta η表示学习率。 - 这样的训练过程通常需要数万甚至数百万个更新步骤才能收敛。
- 本文目标是学习一小部分合成蒸馏训练数据
x
~
=
[
x
~
i
]
i
=
1
M
\widetilde{x}=[\widetilde{x}_i]_{i=1}^M
x
=[x
i]i=1M,
M
≪
N
M{\ll}N
M≪N以及相应的学习率
η
~
\widetilde{\eta}
η
,以至单个梯度下降step如:
θ 1 = θ 0 − η ~ ▽ θ 0 ℓ ( x ~ , θ 0 ) \theta_{1}=\theta_0-\widetilde{\eta}\triangledown_{\theta_0}\ell(\widetilde{x},\theta_0) θ1=θ0−η ▽θ0ℓ(x ,θ0) - 使用学习到的合成数据 x ~ \widetilde{x} x 可以极大地提高真实测试集的性能。
- 给定初始化参数
θ
0
\theta_0
θ0,通过最小化目标
L
\mathcal{L}
L以获得合成数据
x
~
\widetilde{x}
x
和学习率
η
~
\widetilde{\eta}
η
:
x ~ ∗ , η ~ ∗ = arg min x ~ , η ~ L ( x ~ , η ~ ; θ 0 ) − arg min x ~ , η ~ ℓ ( x , θ 1 ) − arg min x ~ , η ~ ℓ ( x , θ 0 − η ~ ▽ θ 0 ℓ ( x ~ , θ 0 ) ) \widetilde{x}^*,\widetilde{\eta}^*=\arg \mathop{\min}\limits_{\widetilde{x},\widetilde{\eta}}\mathcal{L}(\widetilde{x},\widetilde{\eta};\theta_0)-\arg \mathop{\min}\limits_{\widetilde{x},\widetilde{\eta}}\ell(x,\theta_1)-\arg \mathop{\min}\limits_{\widetilde{x},\widetilde{\eta}}\ell(x,\theta_0-\widetilde{\eta}\triangledown_{\theta_0}\ell(\widetilde{x},\theta_0)) x ∗,η ∗=argx ,η minL(x ,η ;θ0)−argx ,η minℓ(x,θ1)−argx ,η minℓ(x,θ0−η ▽θ0ℓ(x ,θ0))其中,
θ 1 \theta_1 θ1为蒸馏数据 x ~ \widetilde{x} x 和学习率 η ~ \widetilde{\eta} η 的函数,然后在所有训练数据 x x x上评估新的权重。
损失 L ( x ~ , η ~ ; θ 0 ) \mathcal{L}(\widetilde{x},\widetilde{\eta};\theta_0) L(x ,η ;θ0)对 x ~ \widetilde{x} x 和 η ~ \widetilde{\eta} η 是可微的,因此可以使用基于梯度的标准方法进行优化。 - 在许多分类任务中,数据 x x x可能包含离散部分,例如数据标签对中的类标签。
- 对于这种情况,固定离散部分而不是学习它们。
3.2 随机初始化蒸馏
-
固定初始化的局限性:给定初始化优化的蒸馏数据不能很好地推广到其他初始化。
-
蒸馏数据通常看起来像随机噪声,因为它对训练集 x x x和固定网络初始化 θ 0 \theta_0 θ0的信息进行编码。
-
为了解决这个问题,本文转而计算少量蒸馏数据,这些数据可以适用来自特定分布的随机初始化网络。优化问题表述如下:
x ~ ∗ , η ~ ∗ = arg min x ~ , η ~ E θ 0 ∼ p ( θ 0 ) L ( x ~ , η ~ ; θ 0 ) \widetilde{x}^*,\widetilde{\eta}^*=\arg \mathop{\min}\limits_{\widetilde{x},\widetilde{\eta}}\mathbb{E}_{\theta_0\thicksim{p(\theta_0)}}{\mathcal{L}(\widetilde{x},\widetilde{\eta};\theta_0)} x ∗,η ∗=argx ,η minEθ0∼p(θ0)L(x ,η ;θ0)其中,网络初始化 θ 0 \theta_0 θ0是从分布 p ( θ 0 ) p(\theta_0) p(θ0)中随机采样的。
在优化过程中,蒸馏数据被优化为适用于随机初始化网络。 -
在实践中,我们观察到最终蒸馏数据能够很好地推广到未知初始化。
-
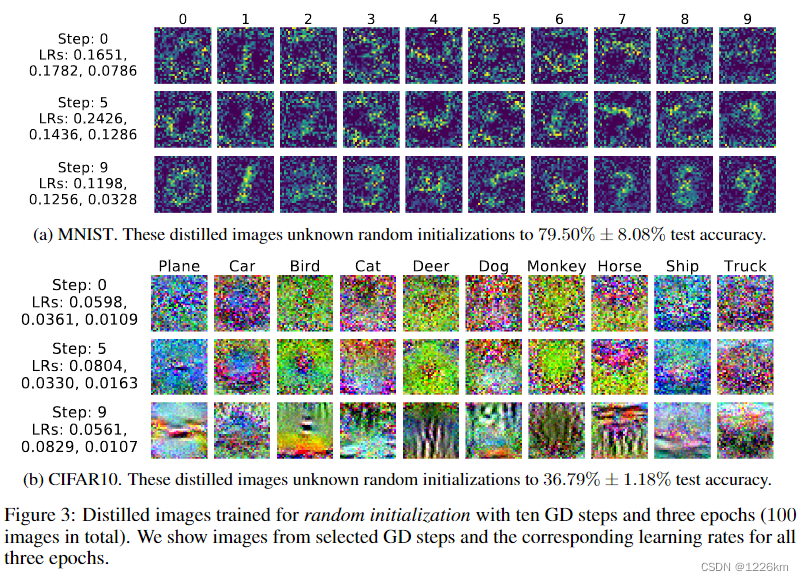
此外,蒸馏图像通常看起来信息丰富,编码了每个类别的判别特征(例如图3)

-
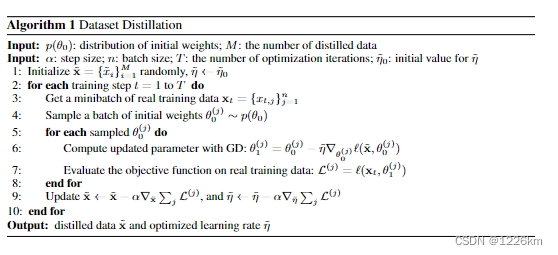
算法1说明了我们的主要方法。
实验结果

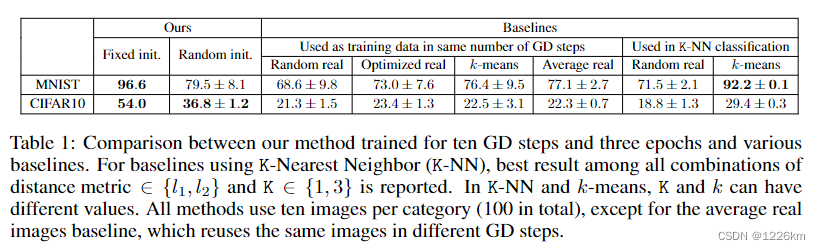
- 局限性:没有跨模型进行验证















 5389
5389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









