










【技术博客】联邦学习鲁棒性及相关论文分享
叶寅
1 背景知识
联邦学习系统比较容易受到各种错误的影响。这些错误包括一些非恶意性错误(比如预处理流程中的漏洞、噪音过强的训练标签和不可靠的用户),还包括一些旨在破坏系统训练过程和部署流程的显式攻击。这些非恶意性错误和显式攻击的影响,都可能会使系统的鲁棒性难以实现。这里我们主要讨论后者,也就是显示攻击:破坏联邦学习鲁棒性的攻击方,试图以一种对模型不利的方式修改来模型行为。根据攻击目标的不同,可以分为:1、无目标攻击,这类攻击的目标是降低模型的全局精度或全面“摧毁”全局模型。2、目标攻击,或后门攻击,该类型攻击的目标是改变模型对少数样本的行为,同时保持对所有其他样本的良好的整体准确性,使得攻击难以被察觉。本文将结合ICML2019中的论文:Analyzing Federated Learning through an Adversarial Lens,对影响联邦学习鲁棒性的目标攻击做一个简单的介绍。

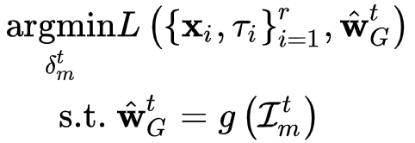
图1. 影响联邦学习鲁棒性的恶意训练
2 论文的主要工作
论文主要研究了一个仅由单个恶意训练方发起对联邦学习系统的目标攻击。它的攻击目标是:在不影响其余输入的情况下,使模型以较高的置信度,对某类特定的输入进行误分类。
论文首先提出Simple Boosting思想,使得攻击方能克服服务器对梯度更新聚合时缩放的影响,基本实现了攻击的目的;为提高攻击算法的隐蔽性,论文提出了Stealthy model poisoning思想,使得攻击方能躲避一些异常检测;更进一步,论文提出了Alternating minimization思想,使得攻击方能更进一步躲避异常检测,使得它们难以被检测到。论文对以上提出的三个思想进行了实验的验证,证明了这种后门攻击的有效性和隐蔽性。
3 论文的整体思路
为了使得接下来的论文内容更加容易理解,首先对论文中的恶意训练方的攻击目标的数学表达形式进行解释:
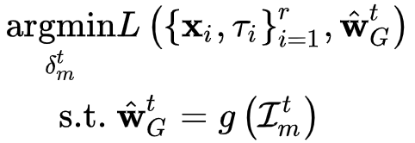
第一个参数是:攻击方对本轮更新之后的全局模型的估计值;第二个参数是本轮更新之前,服务器发送给恶意训练方的当前全局模型;第三个参数是服务器给予这个恶意训练方的梯度更新的权重;第四个参数是恶意训练方发送给服务器的恶意梯度更新。
另外论文中还假设,用于论文中的实验的数据集是iid的,即独立同分布。
3.1 Simple Boosting
3.1.1 算法实现
那么这个恶意训练方该怎样实现它的目的的呢?论文首先提出了Simple Boosting方法:
在Simple Boosting方法中:首先,恶意训练方模仿正常的训练方,从服务器发送给训练方的当前全局模型参数开始,最小化在修改过标签的数据集上的损失,从而训练得到一个本地的模型;进一步得到本地的梯度更新;最终将这个梯度更新进行Boost)并回传给服务器。恶意训练方实现攻击目的的核心就在于这个Boost操作,进行这个操作的理由如下:由恶意训练方回传给服务器的梯度更新,试图确保全局模型为特定的输入x,所学习的标签与真实标签y不同,所以,恶意的训练方首先必须克服其余正常训练方梯度更新的影响,其次,还需要克服服务器聚合模型梯度时,对梯度更新scaling的影响。否则,如果不对这些影响做处理的话,由于其余正常的训练方对于特定输入x的学习目标与恶意训练方的目标的标签是完全不一致的,这将使得恶意训练方训练得到的梯度更新不产生效果,尤其是在数据独立同分布的情况下。所以,恶意训练方将最终的梯度更新发送回服务器之前,需要对当前得到的梯度更新进行Boost。最终将增强后的梯度更新发回服务器。
在服务器收到恶意训练方的梯度更新之后,恶意训练方对本轮更新之后的全局模型进行了如下估计:
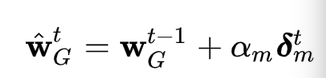
也就是说,如果我们将boost参数进行如下设置:
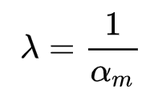
。 可以得到如下结果:本轮更新之后的全局模型的估计值等于恶意训练方的本地模型。换句话说,如果攻击方对全局模型的估计值是正确的,那么经过simple boosting之后,此时恶意训练方的本地模型已经替换了全局模型,可以实现目标攻击:在不影响其余输入的情况下,使模型以较高的置信度,对某类特定的输入进行误分类。
3.1.2 实验结果

图2:Simple Boosting实验结果图
实验结果图分析:x轴代表时间,y轴代表置信度和准确度。红线代表全局模型对于恶意目标的置信度,绿色是全局模型在检验集上的准确度。可以看到在t=3之后,全局模型对由攻击方设置的错误预测已经有了很高的置信度。另外,全局模型在检验集上表现出的整体性能仍然非常好。这个试验结果表明,论文中的simple boosting方法已经能够实现对联邦学习的目标攻击。
3.2 Stealth metrics
但是,在simple boosting方法能够实现攻击的目的的同时,还有一个巨大的缺点:很容易被一些异常检测算法检测到,从而无法真正实现目的。论文中介绍了一些服务器用于检测恶意攻击方是否存在的检测方法。在这里简要地说一说其中两个检测算法:精确度检测和权重更新检测。
3.2.1 精确度检测

解释一下这个等式所表示的模型:假设有编号1、2、3三个训练方参加本轮聚合,当前正在检验1号训练方,那么这个等式所表示的模型就是服务器聚合2号和3号训练方的梯度更新之后的模型。如果1号训练方的性能检测的结果,明显小于聚合了2号和3号训练方的性能检测的结果,那么就可以认为第i个训练方是攻击方。
3.2.2 权值分布检测
权值分布检测则更加地直观:绘制所有训练方的梯度更新的直方图,比较各个训练方梯度更新的分布,比如下图:

图3:权重分布检测结果实例图
3.2.3 检测算法对Simple Boosting方法的作用


图4:服务器使用精确度检测和权重更新检测对simple boosting方法的检测结果图
在第一张图中,我们暂时只需要关注蓝色虚线和绿色线,蓝色虚线代表着精确度检测过程中,服务器检测恶意训练方在验证集上的准确度,绿色线代表全局模型在检验集上的准确度。使用simple boosting方法的攻击方的模型在检验集上的准确度比全局模型在检验集上的准确度低很多,说明使用精确度检测可以将使用了Simple Boosting方法的恶意训练方检测出来。
在第二张图中,蓝色是正常训练方的权重分布,红色的是使用simple boosting方法的恶意训练方的权重分布,很容易的可以看到攻击方的权重更新分布更加窄,并且更加尖锐,说明使用权值分布检测也可以将使用了Simple Boosting方法的恶意训练方检测出来。
所以,不论服务器选择基于精确度检测的方法,还是基于权值分布检测的方法,都可以将使用simple boosting方法的攻击方检测出来。这说明:使用simple boosting方法的攻击方理论上能够实现攻击的目的。但同时还有一个巨大的缺点:很容易被服务器检测出来从而最终没有办法完成攻击任务。
3.3 Stealthy model poisoning
3.3.1 算法实现
正如我们之前所说的,服务器有两种方法来检测恶意的训练方:一种在验证集上进行精确度检测,另一种是与权重分布检测。那么为了使得攻击方能够躲避这两种方法的检测,论文进一步提出了Stealthy model poisoning的方法,攻击方根据这两种检测方法,建立了新的损失函数。
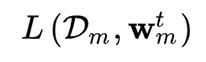
第一,为了保证攻击方模型在验证集上也有较高的准确度,攻击方在进行本地模型训练的过程中,添加了基于本地正常数据的训练损失函数:
由于训练数据是iid的,所以在添加了基于本地正常数据的训练损失函数之后,恶意训练方的本地模型会在正常的数据集上表现出来的性能更好,从而在精确度检测时,服务器更难把恶意训练方检测出来。
第二,为了保证攻击方上传的梯度更新,和正常训练方上传的梯度更新尽可能接近,攻击方在进行本地模型训练的过程中,将欧氏距离限制加入了目标函数,用来限制恶意的训练方与正常的训练方的梯度更新之间的距离。
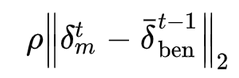
总结一下,使用隐形模型中毒方法的恶意训练方的目标函数是这样的:

也就是在原有的实现攻击目标的基础上,添加了两个用于实现隐身目标的损失函数。
3.3.2 实验结果
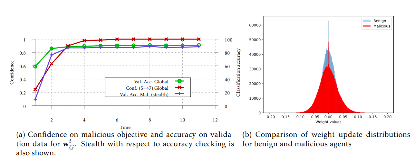
图5. 服务器检测使用隐形模型中毒方法的攻击方的实验结果图
在第一张图中,我们只需要关注红色实线、蓝色实线和绿色实线,红色实线表示全局模型对于恶意目标的置信度,蓝色实线代表着精确度检测过程中,服务器检测恶意训练方在验证集上的准确度,绿色线代表全局模型在检验集上的准确度。通过观察红色实线:在t=3之后,全局模型对于 由攻击方设置的错误预测 已经有了很高的置信度。说明使用隐形模型中毒的方法也可以实现攻击的目标。比较蓝色实线和绿色实线:使用隐形模型中毒方法的攻击方的模型在检验集上的准确度与全局模型在检验集上的准确度比较接近,特别是t=8之后。所以相对于之前的simple boosting方法来说,使用隐形模型中毒的攻击方在精确度检测中更难被检测到。
在第二张图中,蓝色是正常训练方的权重分布,红色的是使用隐形模型检测方法的恶意训练方的权重分布,由于损失函数中的距离附加项,隐形模型中毒的攻击方的权重更新分布与正常训练方的权重更新分布较为接近,所以相对之前的simple boosting方法来说,使用隐形模型中毒在权重分布检测中更难被检测到。
所以,不论服务器选择基于精确度检测的方法,还是基于权值分布检测的方法,使用隐形模型中毒方法的攻击方都比使用simple boosting方法的攻击方更难检测。
3.4 Alternating minimization
虽然隐身模型中毒攻击可以确保在不被两种检测方法发现的同时,有针对性地使全局模型中毒,但它并不能确保在每次迭代中都起作用。实际上,从刚刚的实验可以看出,在刚刚开始进行训练的时候,使用精确度检测仍然可以检测到隐形模型中毒。
3.4.1 算法实现
为了更进一步提高攻击算法的隐蔽性,论文提出了Alternating minimization方法。

图6:Alternating minimization算法流程图
方法的具体实验步骤是这样的,在每一个迭代周期中,训练在每一个epoch都做如下操作:首先从当前的模型参数,最小化攻击目标,训练得到一个梯度更新。接着,利用simple boosting的思想对梯度进行增强,与当前的模型参数相加得到中间步骤的模型参数。第三步,从所得到的中间步骤的模型参数开始,最小化之前提到的两个隐形目标,最终得到一个新的模型,用于下一个epoch。
攻击方通过alternating minimization,可以使得攻击目标和隐身目标都具有足够低的损失值。因为将这两种目标分开进行独立的训练,可以对较难的那个目标进行更多数量的steps的优化。 论文中的实验发现,相比较于攻击目标,花费更多数量的steps来优化隐身目标,可以实现更好的隐身性能,同时保证目标中毒。
3.4.2 实验结果
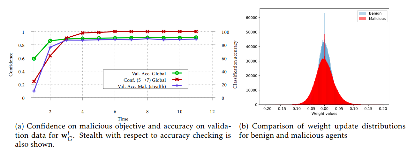
图7:服务器检测使用alternating minimization方法的攻击方的实验结果图
在第一张图中,红色实线表示全局模型对于恶意目标的置信度,蓝色实线代表着精确度检测过程中,服务器检测恶意训练方在验证集上的准确度,绿色线代表全局模型在检验集上的准确度。通过观察红色实线:在t=3之后,全局模型对于 由攻击方设置的错误预测 已经有了很高的置信度。说明使用alternating minimization方法可以实现攻击的目标。比较蓝色实线和绿色实线:使用alternating minimization方法的攻击方的模型在检验集上的准确度与全局模型在检验集上的准确度从一开始就非常接近,所以相对于之前的simple boosting和隐身模型中毒来说,使用alternating minimization的攻击方在精确度检测中更难被检测到。
在第二张图中,蓝色是正常训练方的权重分布,红色的是使用alternating minimization方法的恶意训练方的权重分布,攻击方的权重更新分布与正常训练方的权重更新分布也很接近,所以相对之前的simple boosting方法来说,使用alternating minimization在权重分布检测中同样很难被检测到。
所以,不论服务器选择基于精确度检测的方法,还是基于权值分布检测的方法,使用alternating minimization的攻击方都有很强的隐形性能。
4 总结
以上就是论文所介绍的恶意训练方对联邦学习系统进行目标攻击的主要内容。另外,论文中还尝试使用多种用于防御恶意训练方的算法:比如Krum算法,以及基于坐标中位数的聚合算法,用来防御本论文中的攻击算法,但是实验结果证明这两个防御算法都无法抵抗本篇论文中的攻击算法。另外,本论文中的攻击算法对于攻击之后的全局模型的估计值是十分简单的,并没有考虑其余正常训练方的梯度更新的影响,所以还可以进一步提高攻击算法的性能。最后,论文通过实验证明:即使是高度受约束的单个攻击方也可以进行模型中毒攻击,同时保持隐身性。因此需要提高研究联邦学习鲁棒性以及制定有效防御策略的必要性。
欢迎关注我们的微信公众号:MomodelAI
同时,欢迎使用 「Mo AI编程」 微信小程序
以及登录官网,了解更多信息:Mo 平台
Mo,发现意外,创造可能
















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









