







当你看到神话中的衔尾蛇时,很自然地会想:“这不会持久的。”这是一个强有力的象征——吞噬自己的尾巴——但在实践中却很难实现。对于人工智能(AI)来说,情况可能也是如此,根据一项新研究,AI在经过几轮训练后,可能会面临“模型崩溃”的风险,这种训练是基于它自己生成的数据。
在《自然》杂志上发表的一篇论文中,由牛津大学的伊利亚·舒马洛夫(Ilia Shumailov)领导的英国和加拿大研究人员展示了当今的机器学习模型在本质上容易受到他们称之为“模型崩溃”的综合症的影响。正如他们在论文引言中所写的:
我们发现,不加选择地从其他模型产生的数据中学习会导致“模型崩溃”——这是一个退化过程,随着时间的推移,模型忘记了真实的底层数据分布……
这是怎么发生的,为什么会这样?这个过程实际上很容易理解。
AI模型本质上是模式匹配系统:它们在训练数据中学习模式,然后将提示与这些模式匹配,填补最有可能的下一个点。无论你问的是“有什么好的肉桂糖曲奇食谱?”还是“按就职时年龄顺序列出美国总统”,模型基本上只是在返回那个单词序列最有可能的延续。(对于图像生成器来说有所不同,但在很多方面是类似的。)
但问题是,模型倾向于最常见的输出。它不会给你一个有争议的肉桂糖曲奇食谱,而是最常见的、普通的食谱。如果你让图像生成器画一只狗,它不会给你一个它在训练数据中只见过两张图片的稀有品种;你可能会得到一只金毛寻回犬或拉布拉多犬。
现在,将这两件事结合起来,考虑到网络上充斥着AI生成的内容,新的AI模型可能会吸收并训练这些内容。这意味着他们会看到很多金毛犬!
一旦他们训练了大量金毛犬(或平庸的博客垃圾、假脸、生成的歌曲),这就成了他们的新基准。他们会认为90%的狗真的是金毛犬,因此当被要求生成一只狗时,他们会进一步提高金毛犬的比例——直到他们基本上完全忘记了狗是什么。
《自然》杂志的一篇伴随评论文章中的这幅精彩插图直观地展示了这个过程:
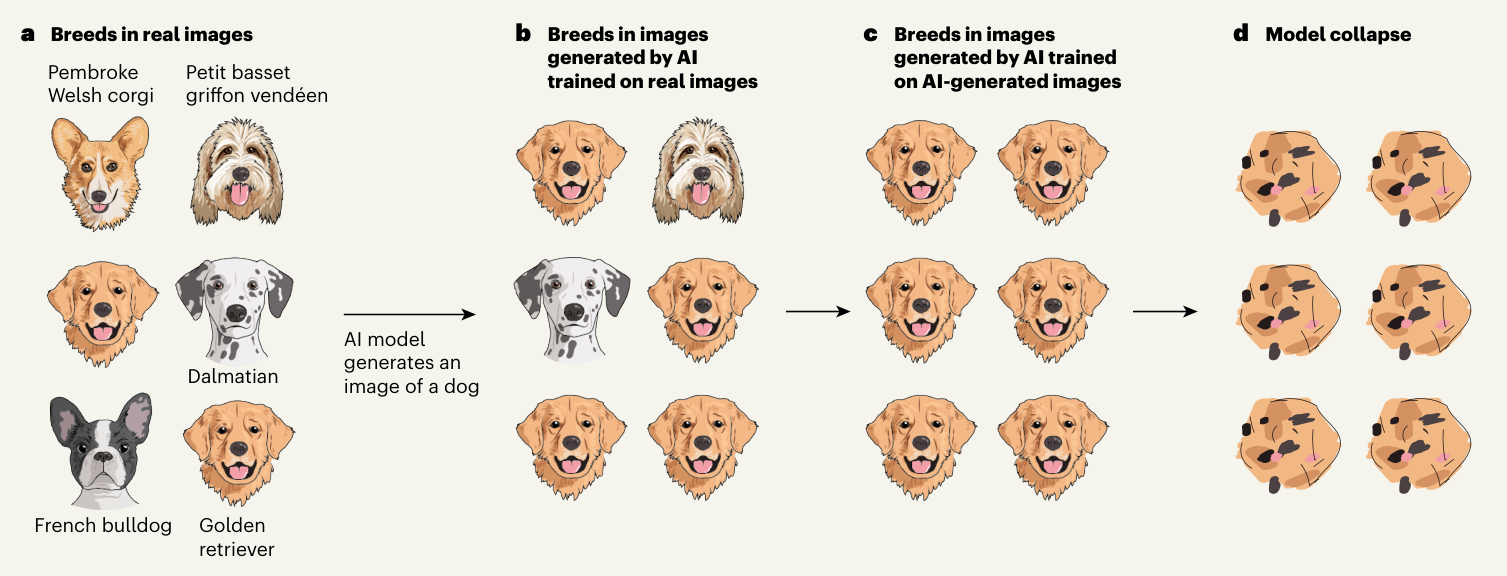
类似的事情也发生在语言模型和其他本质上倾向于在其训练集中为答案选择最常见数据的模型上——这通常确实是正确的做法。直到它遇到了现在公共网络上的大量垃圾信息。
基本上,如果模型继续相互吞噬数据,可能甚至不知道这一点,它们会逐渐变得奇怪和愚蠢,直到崩溃。研究人员提供了许多例子和缓解方法,但他们甚至称模型崩溃“不可避免”,至少在理论上是这样。
虽然它可能不会像他们进行的实验所显示的那样发展,但这种可能性应该让任何在AI领域的人都感到害怕。训练数据的多样性和深度越来越被认为是影响模型质量的最重要因素。如果你用完了数据,但生成更多数据有风险导致模型崩溃,这是否根本上限制了今天的AI?如果它确实开始发生,我们怎么知道?我们能做些什么来推迟或缓解这个问题?
最后一个问题的答案至少是肯定的,尽管这并不能减轻我们的担忧。
数据来源和多样性的定性和定量基准将有所帮助,但我们离标准化这些还很远。AI生成数据的水印将帮助其他AI避免它,但到目前为止还没有人找到一种合适的方式在图像上标记(好吧……我找到了)。
事实上,公司可能没有动力分享这类信息,而是囤积所有超有价值的原始和人类生成的数据,保留舒马洛夫等人所说的他们的“先行者优势”。
[模型崩溃]必须被认真对待,如果我们想要维持从大规模网络抓取的数据中训练的好处。事实上,在互联网上爬取的数据中存在大量由大型语言模型(LLM)生成的内容的情况下,关于真实人类与系统互动的数据收集的价值将越来越有价值。
……[我]可能越来越难以在大规模采用技术之前从互联网上爬取的数据或直接获取人类大规模生成的数据来训练新版本的LLM。
把它加入到AI模型可能面临的灾难性挑战的堆中——以及反对今天的方法产生明天的超级智能的理由。
















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









