







大批量复杂三角网格模型的有限元分析自动化实现
本文给出一种可以使用复杂三角网格模型从模型重画修复,四面体网格划分到有限元分析的全流程自动化实现过程,涉及多个软件工具和编程语言,对于需要重复运行成百上千类似的有限元模型的情况下非常实用,本人亲测在一周之内完成了270组有限元分析,如果采用纯人力,是接近两个月的工作量。
需要用到的工具
Geomagic Wrap
三角网格的自动重画和修复工具,以下简称GW,拥有自己的命令脚本,三角网格重画和修复是保证后续四面体质量的重要一步,如果三角网格不完整或质量太差,hypermesh可能无法处理。
hypermesh
优秀的四面体网格和处理工具以下简称HM,之所以不使用HM重画和修复主要是因为针对一些非流行的网格和重叠网格的模型,HM不能够很好的进行处理,因此需要对模型使用GW进行前处理,另外HM可以直接导出abqus所能识别的inp输入文件,非常利于后续的处理。HM支持tcl脚本进行自动化
abaqus
经典有限元软件,有强大的有限元分析能力和完善的命令行,可以方便的实现自动化批处理。
其他
能够读写文件的任意编程语言,本文使用c++,三角网格模型若干,本文以stl文件格式为例。
整体方法
1.首先准备好需要进行批量有限元分析的stl文件
2.编写Geomagic Wrap脚本用以重画和修复三角网格模型
进入目录:C:\Users\Public\Documents\Geomagic\Geomagic Wrap 2021\macros(如果不在这里可以使用everything全局搜索一下)
新建名为“脚本 1.py”的文件,这里没有安装python也没有关系,安装GW时会自动安装一个内置的python版本并配套了相应的宏定义库,详细的文档可以在进入软件时的弹出窗口上连接进入,即下图右侧“脚本文档”。
这里简单演示使用脚本对三角网格进行重画修复的过程,这里可以使用记事本之类的任意文本编辑软件打开进行编辑
#-*- coding: utf-8 -*-
geo.open(0, 1, u'D:\\demo\\1231.stl')
geo.remesh(0.0004, 0, 1, 45, 0.002077, 1, 0, 0, 0.000147, 1)
geo.mesh_doctor("Auto-Repair")
geo.saveas(u'D:\\demo\\after_1231.stl', 4, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, -1, 0, 1, 0)
geo.open用于打开文件,前两个参数用于创建文档和视图,可以保持不变
geo.mesh用于重画网格,参数表意义如下:
targetEdgeLength: 目标边长,单位为米,表示重构后的多边形网格的平均边长。
minEdgeLength: 最小边长,单位为米,表示重构后的多边形网格的最小边长。
maxEdgeLength: 最大边长,单位为米,表示重构后的多边形网格的最大边长。
maxAngle: 最大角度,单位为度,表示重构后的多边形网格的最大角度。
maxAspectRatio: 最大长宽比,表示重构后的多边形网格的最大长宽比。
preserveBoundary: 保持边界,表示是否保持原始多边形网格的边界不变。如果为1,则保持;如果为0,则不保持。
preserveSharpEdges: 保持锐角,表示是否保持原始多边形网格的锐角不变。如果为1,则保持;如果为0,则不保持。
preserveFeatureEdges: 保持特征边,表示是否保持原始多边形网格的特征边不变。如果为1,则保持;如果为0,则不保持。
featureAngle: 特征角度,单位为度,表示用于识别特征边的角度阈值。
smoothMesh: 平滑网格,表示是否对重构后的多边形网格进行平滑处理。如果为1,则平滑;如果为0,则不平滑。
geo.mesh_doctor对网格进行修复
这里使用的是自动修复,还可以有其他可选参数:
“Remove Duplicate Vertices”: 删除重复的顶点。
“Remove Degenerate Faces”: 删除退化的面。
“Remove Duplicate Faces”: 删除重复的面。
“Remove Non-Manifold Edges”: 删除非流形的边。
“Remove Non-Manifold Vertices”: 删除非流形的顶点。
“Remove Holes”: 删除孔洞。
“Fill Holes”: 填充孔洞。
“Smooth Mesh”: 平滑网格。
geo.saveas用于保存重画后的模型
fileName: 文件名,可以是绝对路径或相对路径,必须用单引号或双引号括起来。
fileType: 文件类型,表示导出文件的格式。4表示STL格式。
binary: 二进制,表示是否使用二进制格式导出文件。如果为1,则使用;如果为0,则不使用。
swapBytes: 交换字节,表示是否交换字节顺序。如果为1,则交换;如果为0,则不交换。
swapFaces: 交换面,表示是否交换面的方向。如果为1,则交换;如果为0,则不交换。
saveNormals: 保存法线,表示是否保存法线信息。如果为1,则保存;如果为0,则不保存。
saveColors: 保存颜色,表示是否保存颜色信息。如果为1,则保存;如果为0,则不保存。
saveTextures: 保存纹理,表示是否保存纹理信息。如果为1,则保存;如果为0,则不保存。
saveGroups: 保存组,表示是否按照组结构导出文件。如果为1,则按照组结构导出;如果为0,则不按照组结构导出。
saveHiddenObjects: 保存隐藏对象,表示是否导出隐藏的对象。如果为1,则导出;如果为0,则不导出。
saveSelectionOnly: 仅保存选择对象,表示是否只导出选择的对象。如果为1,则只导出选择的对象;如果为0,则导出所有对象。
saveAsSingleObject: 作为单个对象保存,表示是否将所有对象合并成一个对象导出。如果为1,则合并成一个对象导出;如果为0,则保持原来的对象结构导出。
docIndex: 文档索引,表示要导出的文档的索引,从0开始。如果为-1,则表示当前文档。
viewIndex: 视图索引,表示要导出的视图的索引,从0开始。如果为-1,则表示当前视图。
useViewTransform: 使用视图变换,表示是否使用视图变换矩阵导出文件。如果为1,则使用;如果为0,则不使用。
useObjectTransform: 使用对象变换,表示是否使用对象变换矩阵导出文件。如果为1,则使用;如果为0,则不使用。
我们可以不断重复这一段代码,实现批量化的处理,更多更方便的循环方式读者可以自行查阅脚本文档
#-*- coding: utf-8 -*-
geo.open(0, 1, u'D:\\demo\\1231.stl')
geo.remesh(0.0004, 0, 1, 45, 0.002077, 1, 0, 0, 0.000147, 1)
geo.mesh_doctor("Auto-Repair")
geo.saveas(u'D:\\demo\\after_1231.stl', 4, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, -1, 0, 1, 0)
geo.open(0, 1, u'D:\\demo\\1241.stl')
geo.remesh(0.0004, 0, 1, 45, 0.002077, 1, 0, 0, 0.000147, 1)
geo.mesh_doctor("Auto-Repair")
geo.saveas(u'D:\\demo\\after_1241.stl', 4, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, -1, 0, 1, 0)
geo.open(0, 1, u'D:\\demo\\1441.stl')
geo.remesh(0.0004, 0, 1, 45, 0.002077, 1, 0, 0, 0.000147, 1)
geo.mesh_doctor("Auto-Repair")
geo.saveas(u'D:\\demo\\after_1441.stl', 4, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, -1, 0, 1, 0)
geo.open(0, 1, u'D:\\demo\\1442.stl')
geo.remesh(0.0004, 0, 1, 45, 0.002077, 1, 0, 0, 0.000147, 1)
geo.mesh_doctor("Auto-Repair")
geo.saveas(u'D:\\demo\\after_1442.stl', 4, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, -1, 0, 1, 0)
geo.open(0, 1, u'D:\\demo\\1443.stl')
geo.remesh(0.0004, 0, 1, 45, 0.002077, 1, 0, 0, 0.000147, 1)
geo.mesh_doctor("Auto-Repair")
geo.saveas(u'D:\\demo\\after_1443.stl', 4, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, -1, 0, 1, 0)

编写完后在[工具]->运行,选择刚编写好的脚本即可
3.编写hypermesh脚本,实现批量化四面体网格划分
在某一个全英文目录下新建一个1.tcl文件,文件名无所谓,但是要是tcl后缀,同样使用记事本程序打开。tcl是一种通用脚本语言,有兴趣的同学可以去学习一下,但是本例中不涉及过多的脚本语言逻辑,尽可能以hypermesh命令为主,相关的hypermesh命令大家可以参考altair官方文档 (2017)1,本例给出参考脚本如下。
*createstringarray 18 "HyperMesh " " " "ALESMOOTHINGS_DISPLAY_SKIP " "EXTRANODES_DISPLAY_SKIP " \
"ACCELEROMETERS_DISPLAY_SKIP " "LOADCOLS_DISPLAY_SKIP " "RETRACTORS_DISPLAY_SKIP " \
"VECTORCOLS_DISPLAY_SKIP " "SYSTCOLS_DISPLAY_SKIP " "PRIMITIVES_DISPLAY_SKIP " \
"BLOCKS_DISPLAY_SKIP " "ELEMENTCLUSTERS_DISPLAY_SKIP " "CROSSSECTION_DISPLAY_SKIP " \
"CONSTRAINEDRIGIDBODY_DISPLAY_SKIP " "RIGIDWALLS_DISPLAY_SKIP " "SLIPRINGS_DISPLAY_SKIP " \
"CONTACTSURF_DISPLAY_SKIP " "IDRULES_SKIP"
*feinputwithdata2 "\#stl\\stl" "D:\\demo\\after_1231.stl" 0 0 0 0 0 1 18 1 0
*drawlistresetstyle
*createstringarray 2 "pars: upd_shell tet_clps='0.100000,0.300000,0.500000,1.000000,0.380000,0.100000'" \
"tet: 35 1.3 -1 0 0.8 0"
*createmark elements 2 "all"
*tetmesh elements 2 1 elements 0 -1 1 2
*createmark elements 1 "by config" tria3
*deletemark elements 1
*createmark systems 1
*clearmark systems 1
*retainmarkselections 0
*createstringarray 2 "EXPORTIDS_SKIP" "IDRULES_SKIP"
*feoutputwithdata "D:/Altair/HyperWorks2019/templates/feoutput/abaqus/standard.3d" "D:/abaqus_model/task_dir/1-2-3/after_7.inp" 0 0 1 1 2
*createmark elements 1 "all"
*deletemark elements 1
*createstringarray 用以创建一些后续可能会使用到的字符串命令。
*feinputwithdata2 用来导入文件,其参数表如下:
import_reader: 设置读取器。"#stl\stl"表示使用STL格式读取器。
filename: 文件名,表示要导入的文件的路径。"D:\demo\after_1231.stl.stl"表示要导入的STL文件的位置。
overwrite_flag: 网格是否应偏移或 覆盖任何现有实体 ID,0表示覆盖现有任何实体。
reserved1: 预留位,置为0。
cleanup_tolerance: 一个实数,指示在几何导入以清理期间要使用的清理容差 拓扑,为0表示不清理容差。
blanked_component: 指示是否为数据创建空白组,为0表示不创建。
offset_flag: 是否偏移,这里无偏移,如果置为1需要指出偏移值。
string_array: 置为1,表示使用字符串命令。
number_of_strings: 指示刚刚创建的字符串命令的值。
scale_factor: 比例因子,置为1表示不使用
name_comps_by_layer: 0表示名称中不含有图层(这里通常用于catia导出的文件)。
*drawlistresetstyle 命令重置当前文档中所有对象的显示样式,包括颜色、透明度、线宽等
*createstringarray 2 “pars: upd_shell tet_clps=‘0.100000,0.300000,0.500000,1.000000,0.380000,0.100000’” \
“tet: 35 1.3 -1 0 0.8 0”:这里创建了两个字符串命令,其中:
pars:使用pars命令更新壳单元的塌陷参数,用于控制壳单元在四面体网格划分过程中的塌陷程度。pars命令的参数有一个,是一个字符串,表示要更新的参数和值,用等号连接。tet_clps是一个六元组,表示六种不同类型的壳单元的塌陷系数,用逗号分隔。塌陷系数越大,表示壳单元越容易塌陷;塌陷系数越小,表示壳单元越不容易塌陷。
这里设置壳单元塌陷系数如下:三角形:0.1、四边形:0.3、三角形(带孔):0.5、四边形(带孔):1.0、三角形(带边界):0.38、四边形(带边界):0.1
tet:tet命令创建四面体网格,用于将三维实体或壳单元网格转换为四面体网格。tet命令的参数有六个,分别是:
tet_opts: 网格选项,为位输入参数,计算比较复杂,详细参见2。
growth: 网格增长率,表示四面体网格的边长在不同区域的变化率。1.3表示边长每增加一层,就增加30%。
minSize: 最小网格尺寸,表示四面体网格的最小边长,单位为米。如果为-1,则表示不限制最小尺寸。-1表示不限制最小尺寸。
maxSize: 最大网格尺寸,表示四面体网格的最大边长,单位为米。如果为-1,则表示不限制最大尺寸。0表示不限制最大尺寸。
quality: 网格质量,表示四面体网格的质量阈值,范围在0到1之间。0.8表示只接受质量大于等于0.8的四面体网格。
optimize: 网格优化,表示是否对四面体网格进行优化处理。如果为1,则优化;如果为0,则不优化。0表示不优化。
*createmark elements 2 “all”:选取所有元素作为元素集合2
*tetmesh :*tetmesh命令对选中的三维实体或壳单元网格对象进行四面体网格划分,参数列表如下:
type1: 对象类型,表示要划分的对象的类型。elements表示要划分的对象是单元。
id1: 对象标识,表示要划分的对象的标识。2表示要划分的对象是第二个单元集。
model1: 模式选择。1表示固定无边界层
type2: 对象类型,表示要划分的对象的类型。elements表示要划分的对象是单元。
id2: 对象标识,对于脚本而言这里通常设置为0。
model2:此处置为-1表示忽略
string_array: 这里应该始终设置为1,表示字符串命令输入。
number_of_strings: 2表示使用上面创建的二个字符串来作为划分命令参数。
*createmark elements 1 “by config” tria3:这里同上是创建元素合集,但是不同的是使用了“by config”来筛选,tria3表示三角节点网格,这里要说明的是,在划分完四面体网格之后,hypermesh里实际上是存在三维的四面体网格和二维的三角网格的,这里我们已经不再需要二维是三角形网格,因此,需要把三角网格筛选出来删除掉,只保留四面体网格。
*deletemark将筛选出来的删掉
*retainmarkselections设置为0,不保留标记的实体,避免混淆。
*feoutputwithdata 输出文件
export_template输出文件模板,通常与hypermesh安装位置和要输出的文件类型有关,具体位置可以参考官方文档,本例给出的是输出abaqus文件的模板位置
filename输出文件名和路径
reserved1保留参数1,置为0
reserved2保留参数2,置为0
export_type输出类型,设置为1表示输出所有实体
string_array置为1,使用上面定义的字符串
number_of_strings字符串大小
最后是将输出后的所有元素全部删除,进入下一次循环,与GW脚本类似,可以通过简单重复执行实现批量,也可以使用tcl脚本语言实现循环,tcl语言请参考相关教程。
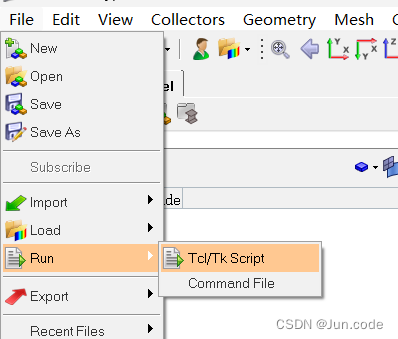
打开hypermesh,[file]->[Run]->[Tcl/Tk Script],选择刚刚写好的tcl文件,即可开始执行。
3.c++读入inp文件,并根据inp文件格式配置有限元分析
首先需要说明的是,HM导出的inp文件事实上是单纯的四面体网格数据文件,而我们需要将其读入后,加上相应的有限元分析材料属性、约束和载荷等条件转写为完整的abqus输入文件,可以用于直接的分析计算。
HM导出的inp文件只包含头部注释,节点(NODE)和元素索引(ELEMENT)信息
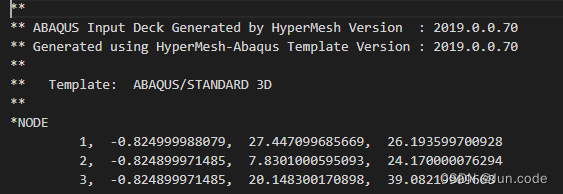

注意,索引有可能会倒序,因此在读取的时候需要检查,以下给出读取的参考c++代码
bool import_inp(vector<inpNode>& nodedata, vector<eleC3D4>& eledata, string file_route, InpKind ik) {
fstream fs;
string file_line;
bool inputNode = false, inputEle = false;
fs.open(file_route);
if (!fs.is_open())
{
return false;
}
while (getline(fs, file_line))
{
if (file_line[0] == '*') {
if (file_line[1] == '*')continue;
else if (file_line[1] == 'N') { inputNode = true; inputEle = false; }
else if (file_line[1] == 'E') { inputNode = false; inputEle = true; }
continue;
}
if (inputNode) {
nodedata.push_back(inpNode(file_line));
}
else if (inputEle) {
eledata.push_back(eleC3D4(file_line));
}
}
if (eledata[1].eleID < eledata[0].eleID) {
reverse(eledata.begin(), eledata.end());
}
fs.close();
}
而后inp文件的配置则需要根据实际的有限元要求来进行,可以参考相关数据了解inp文件结构,比如石老师的经典《ABAQUS有限元分析实例详解》,读者可以通过博客3先简单了解一下,并不会太困难。
由c++输出的第一个inp文件可以先用abaqus打开检查一下是否可用,而后再进行批量转换:

4.使用bat批处理及abaqus命令行实现批量自动计算
在计算机任意位置新建txt文件,这里给出参考指令
cd D:\demo
call abq2021 job=after_1231.inp cpus=2 int ask=off
注意,使用这些命令前一定要保证电脑安装abaqus时勾选了command组件,否则无法执行
首先进入需要执行批处理的文件夹,然后使用call命令,在这里我使用2021版的abaqus,所以命令为abq2021,后续界job=【配置好的inp文件名】,然后设置运算时使用的cpu核数,这里建议只使用不超过总核数三分之二的核数,且最好为2的n次方个核数,以保证计算机的正常维持,最后ask=off是关闭所有询问,这时候在某一个模型执行失败后会直接进入下一个的计算,而不会终止,也不会询问是否覆盖等问题。
这里也可以采用上述类似的方式直接复制改文件名实现批量,或者使用bat的相关高级用法实现循环
cd D:\demo
call abq2021 job=after_1231.inp cpus=2 int ask=off
call abq2021 job=after_1241.inp cpus=2 int ask=off
call abq2021 job=after_1441.inp cpus=2 int ask=off
call abq2021 job=after_1442.inp cpus=2 int ask=off
call abq2021 job=after_1443.inp cpus=2 int ask=off
编辑完后将文件名后缀改为.bat文件,双击后即可开始执行。

















 1683
1683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









