







【RAG 项目实战 02】Chainlit 持久化对话历史
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
01 创建账号
1、登录 Literal AI
2、创建一个项目
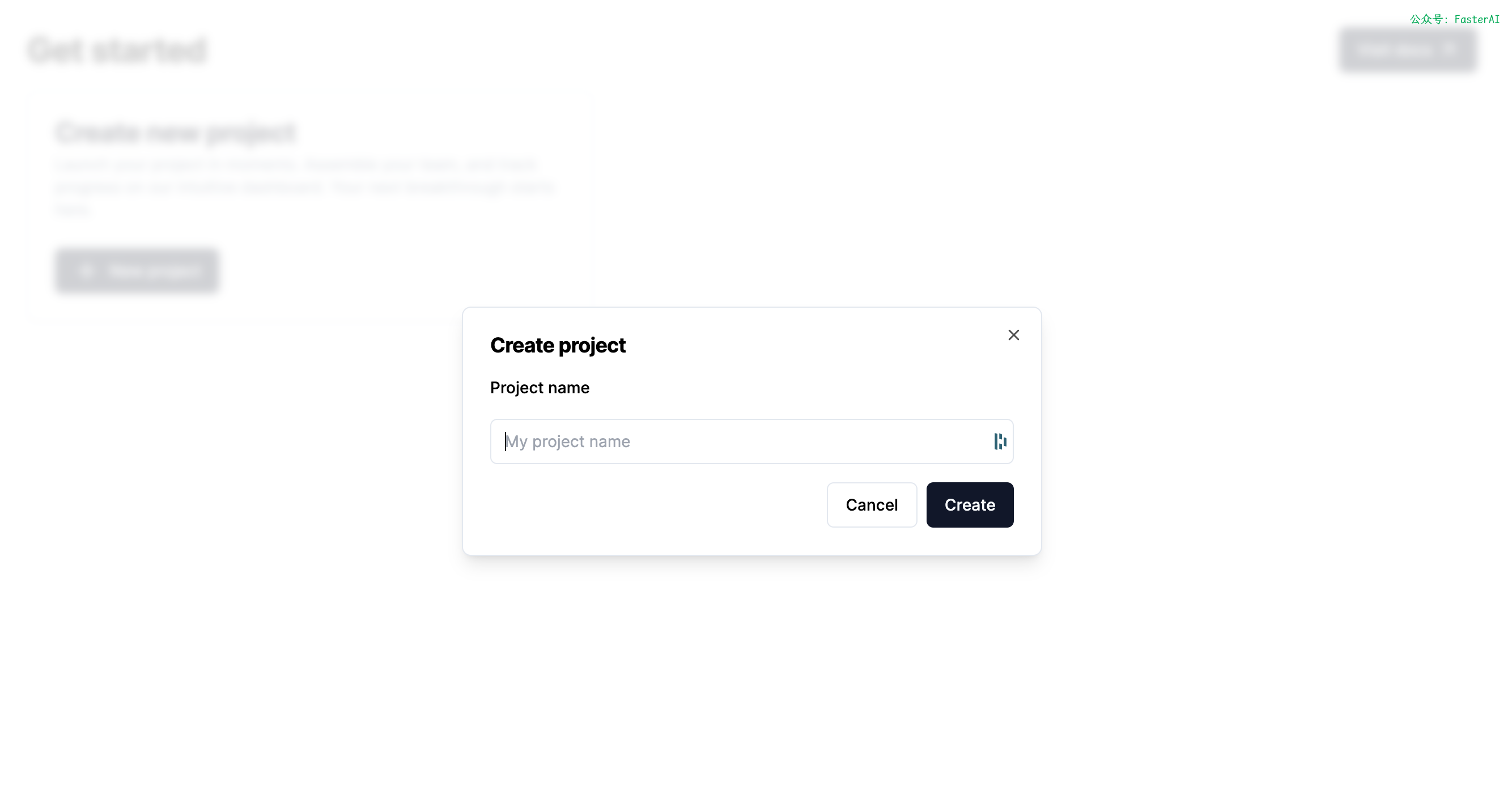
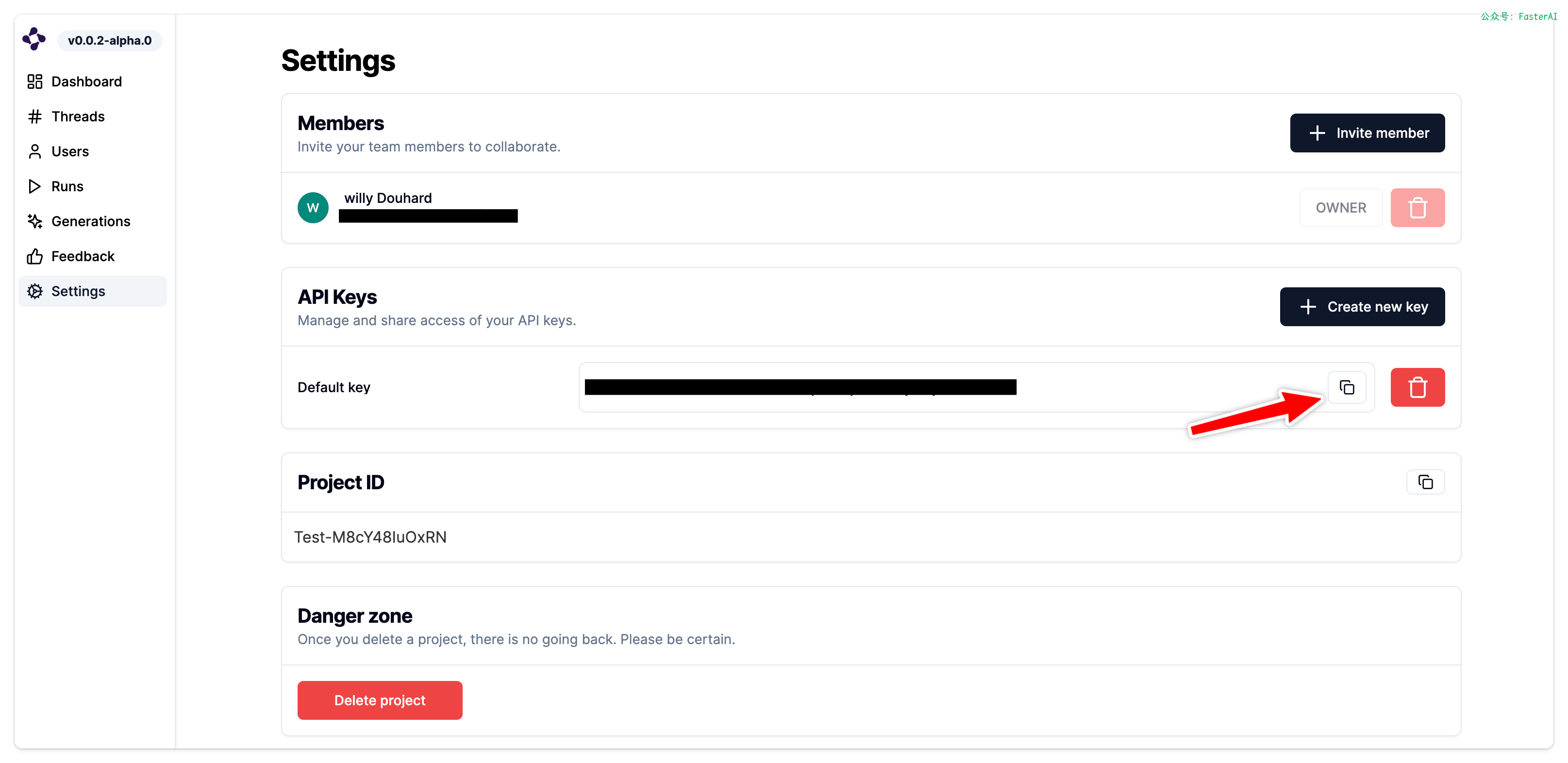
3、在设置页面复制API Key
02 创建密码
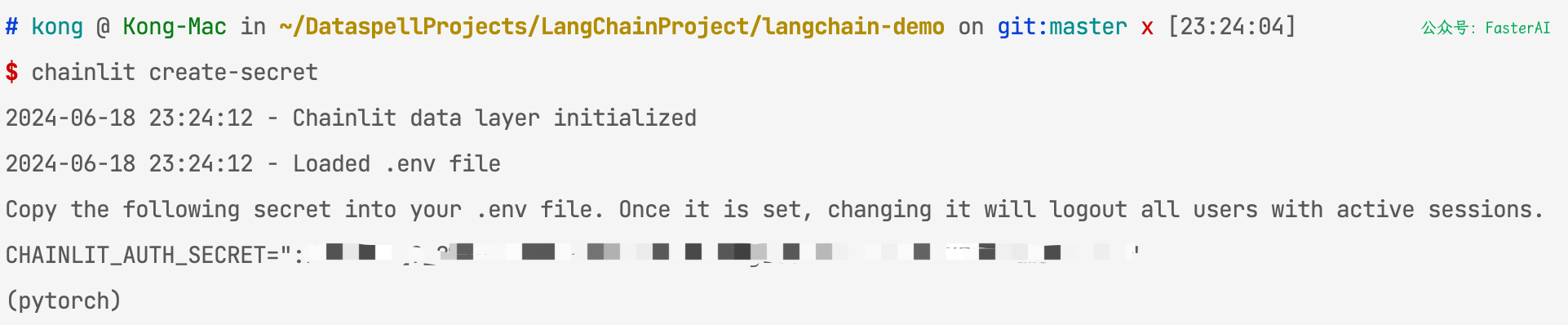
1、 使用 chainlit create-secret 命令创建密钥,并复制到 .env 中
2、添加密码验证
from typing import Optional
import chainlit as cl
@cl.password_auth_callback
def auth_callback(username: str, password: str):
# Fetch the user matching username from your database
# and compare the hashed password with the value stored in the database
if (username, password) == ("admin", "admin"):
return cl.User(
identifier="admin", metadata={"role": "admin", "provider": "credentials"}
)
else:
return None
【动手学 RAG】系列文章:


















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









