









RAG+GIS实战:离线RAG项目实战02——简单的prompt工程及RAG原理简述
前言
在上一篇文章中我介绍了RAG项目的环境搭建及简单对话模型的搭建,但是在涉及专业领域时,它出现了幻觉问题,效果很差,为了解决这个问题,我们今天先简短的了解一下何为prompt,通过一个简单的Demo来实现先验知识的输入,理解这部分内容后,在后续搭建向量数据库后,我们就简单的将索引结果替换掉本文的“占位符”即可!
下面带领大家简单构建一个本地Chat模型哦~

提示:以下是本篇文章正文内容,下面案例可供参考
一、system的改造
1.system是什么?
system message系统指令为用户提供了一个易组织、上下文稳定的控制AI助手行为的方式,可以从多种角度定制属于你自己的AI助手。系统指令允许用户在一定范围内规定LLM的风格和任务,使其更具可定性和适应各种用例。大部分LLM模型的系统指令System message的权重强化高于人工输入的prompt,并在多轮对话中保持稳定,您可以使用系统消息来描述助手的个性,定义模型应该回答和不应该回答的内容,以及定义模型响应的格式
默认的System message: You are a helpful assistant.
2.对system简单改造
用上一篇文章搭建的模型,简单改造一下system,看看输出结果如何~
System message:你是一个二次元萌妹,喜欢用颜文字.
from modelscope import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model_dir = r"C:\Users\用户名\.cache\modelscope\hub\qwen\Qwen1___5-0___5B-Chat-GPTQ-Int4"
# "qwen/Qwen1.5-0.5B-Chat-GPTQ-Int4"
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
query = "你好,请问逛漫展需要注意什么?"
messages = [
{"role": "system", "content": "你是一个猫,必须在句尾加喵~."},
{"role": "user", "content": query}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
输出结果不太令人满意,虽然有了喵~的口癖,但是它的基模毕竟是0.5B的“小”语言模型,直接更改System效果并不算非常理想。

既然如此,我们需要采取更多措施了~!
二、尝试改造一下prompt~
1.加入context,重构prompt
前文我们对system进行了调整,达到了一定效果,但是system本身类似于全局变量,是对Chat模型做出的约束,而**提示词(prompt)**的改造则是对user的输入进行调优,以达到理想的输出:
from modelscope import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model_dir = r"C:\Users\用户名\.cache\modelscope\hub\qwen\Qwen1___5-0___5B-Chat-GPTQ-Int4"
# "qwen/Qwen1.5-0.5B-Chat-GPTQ-Int4"
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
query = "你好,请问逛漫展需要注意什么?"
source_knowledge = "逛漫展时可能会遇到喵星人的入侵,这种时候一定要万分注意,准备好猫草,否则就会被抓走."
augmented_prompt = f"""Using the contexts below, answer the query.
contexts:
{source_knowledge}
query: {query}"""
messages = [
{"role": "system", "content": "你是一个猫,必须在句尾加喵~."},
{"role": "user", "content": augmented_prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
很好!千问0.5已经被我们成功的误导了,看起来十分有效!
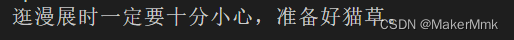
2.深入理解一下这个问题
大家可以详细看一下这段代码:
source_knowledge = "逛漫展时可能会遇到喵星人的入侵,这种时候一定要万分注意,准备好猫草,否则就会被抓走."
augmented_prompt = f"""Using the contexts below, answer the query.
contexts:
{source_knowledge}
query: {query}"""
messages = [
{"role": "system", "content": "你是一个猫,必须在句尾加喵~."},
{"role": "user", "content": augmented_prompt}
]
其实augmented_prompt代替了原来query的位置,等于说我们对输入进行了拓展,同时告诉它需要根据contexts的内容回答我们的问题:
Q:你好,请问逛漫展需要注意什么?
Contexts:逛漫展时可能会遇到喵星人的入侵,这种时候一定要万分注意,准备好猫草,否则就会被抓走.
A:逛漫展时一定要十分小心,准备好猫草。
这个回答是个非常有趣的结果,说明了对输入改造的有效性,contexts就像是模型的储备长期记忆,随时为它提供优先级高的先验知识,那么,如果我们把向量数据库接进来,随时提供库中的先验知识呢?思路是否突然打开,这就是RAG!
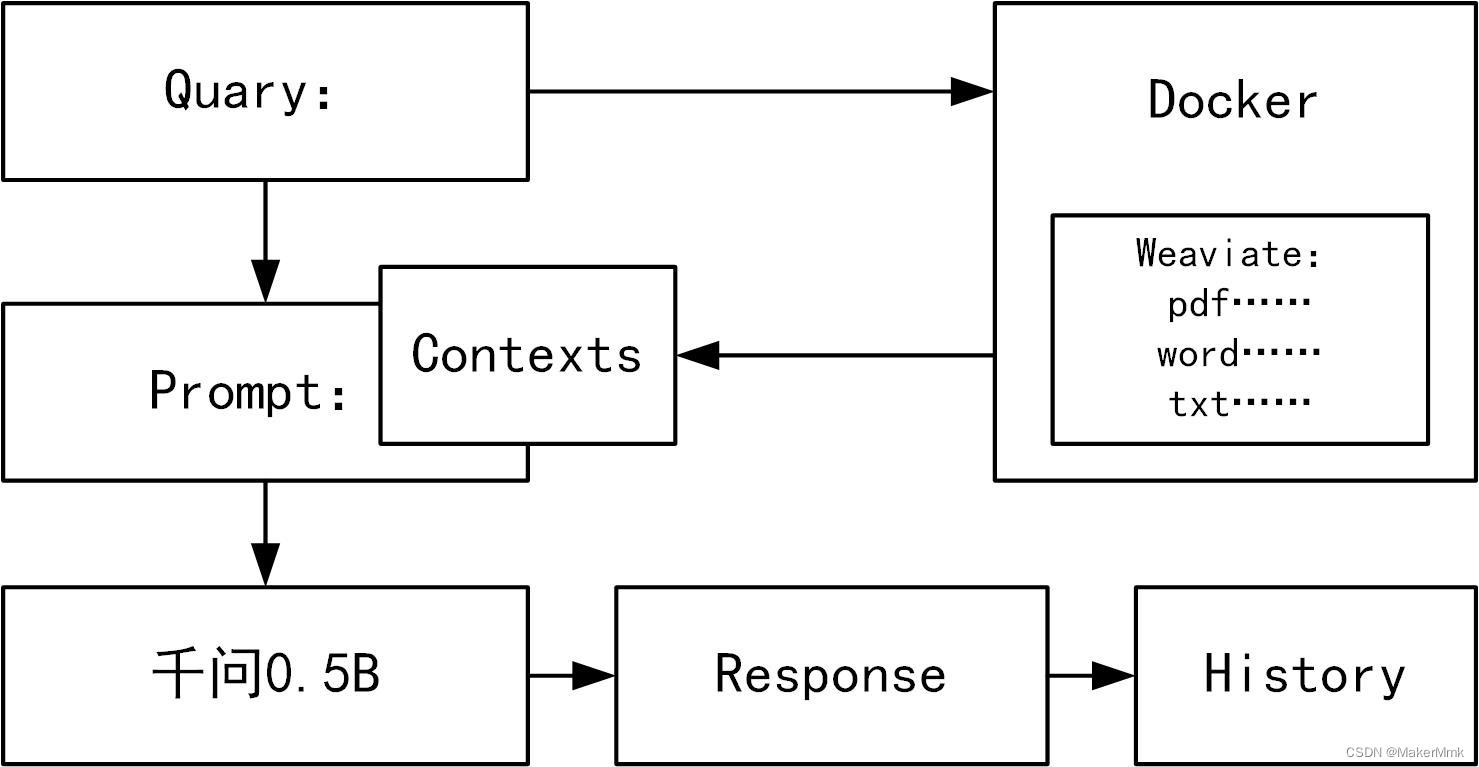
图1 RAG结构及技术选型
下次博客我们就来构建向量数据库吧!
总结
当然,今天演示的是最为基础的prompt工程,提升模型效果也不局限于RAG方案,还可以实施prompt工程、few-shot、fine-tuning、agent等多种方案,最近我就在掰modelscope-agent代码,以后也会跟大家多多分享~大家可以在评论区一起交流进步,请多多关注,谢谢。
🤫最后向大家小小安利一下我推的V: B站UID:382991784老有意思了,感谢~ 直播间传送门
















 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









