





博客主页: [青松]
目录
史上最全大模型(LLMs)面试题系列:帮你彻底搞定Transformer-干货!
💯 Position encoding为什么选择相加而不是拼接呢?
💯 Layer Normalization 有哪几个可训练参数?
💯 LLM为何使用 PreNorm 代替 PostNorm?
💯 LLM为何使用 RMSNorm 代替 LayerNorm?
💯 LLM使用 SwiGLU 相对于 ReLU 有什么好处?
史上最全大模型(LLMs)面试题系列:帮你彻底搞定Transformer-干货!
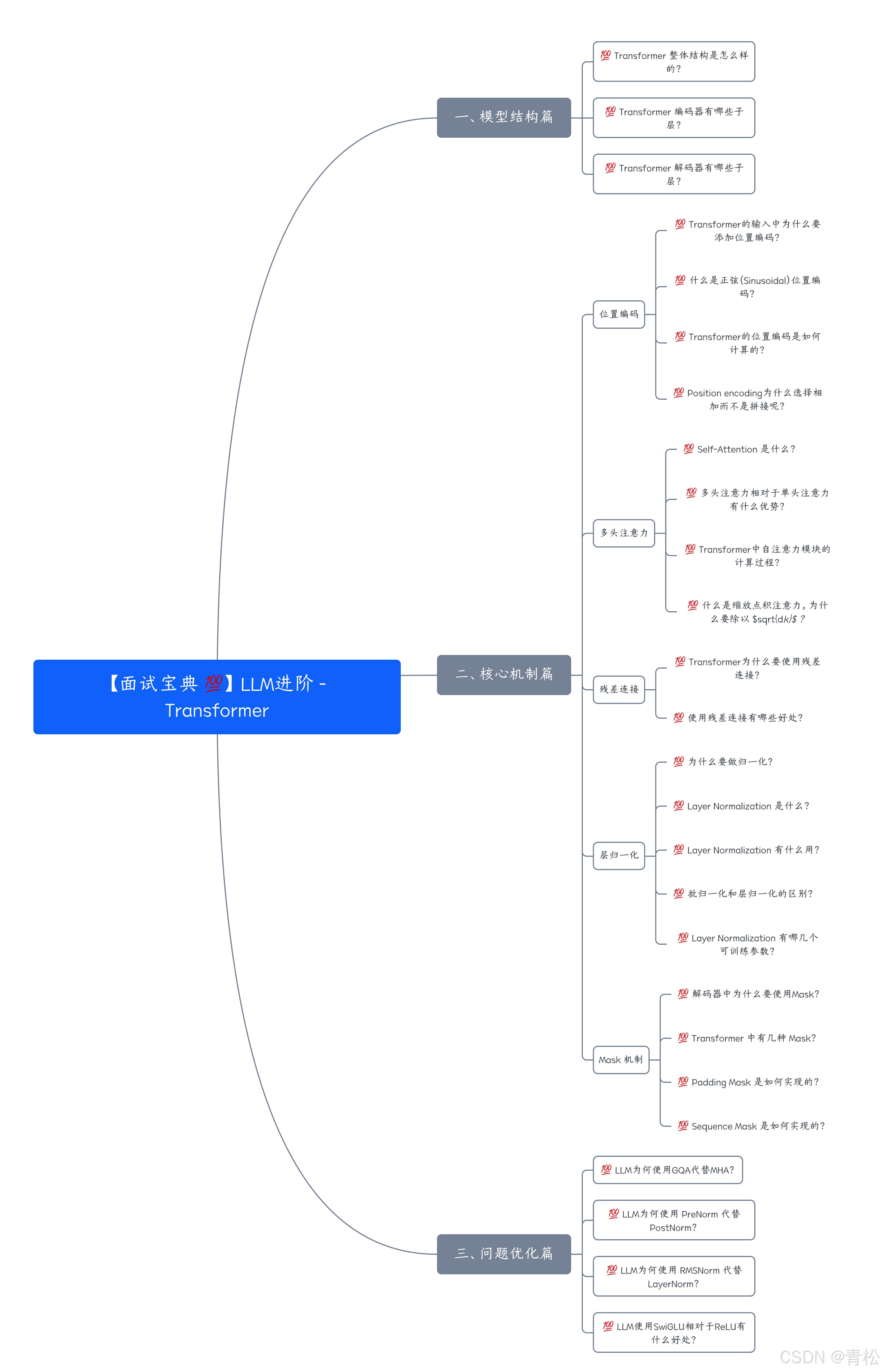
一、模型结构篇
💯 Transformer 整体结构是怎么样的?
基于 Transformer 结构的编码器和解码器结构如图所示,左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构。它们均由若干个基本的 Transformer 块(Block)组成(对应着图中的灰色框)。这里 N 表示进行了 N 次堆叠。每个 Transformer 块都接收一个向量序列作为输入,并输出一个等长的向量序列作为输出。
基于 Transformer 的编码器和解码器结构:
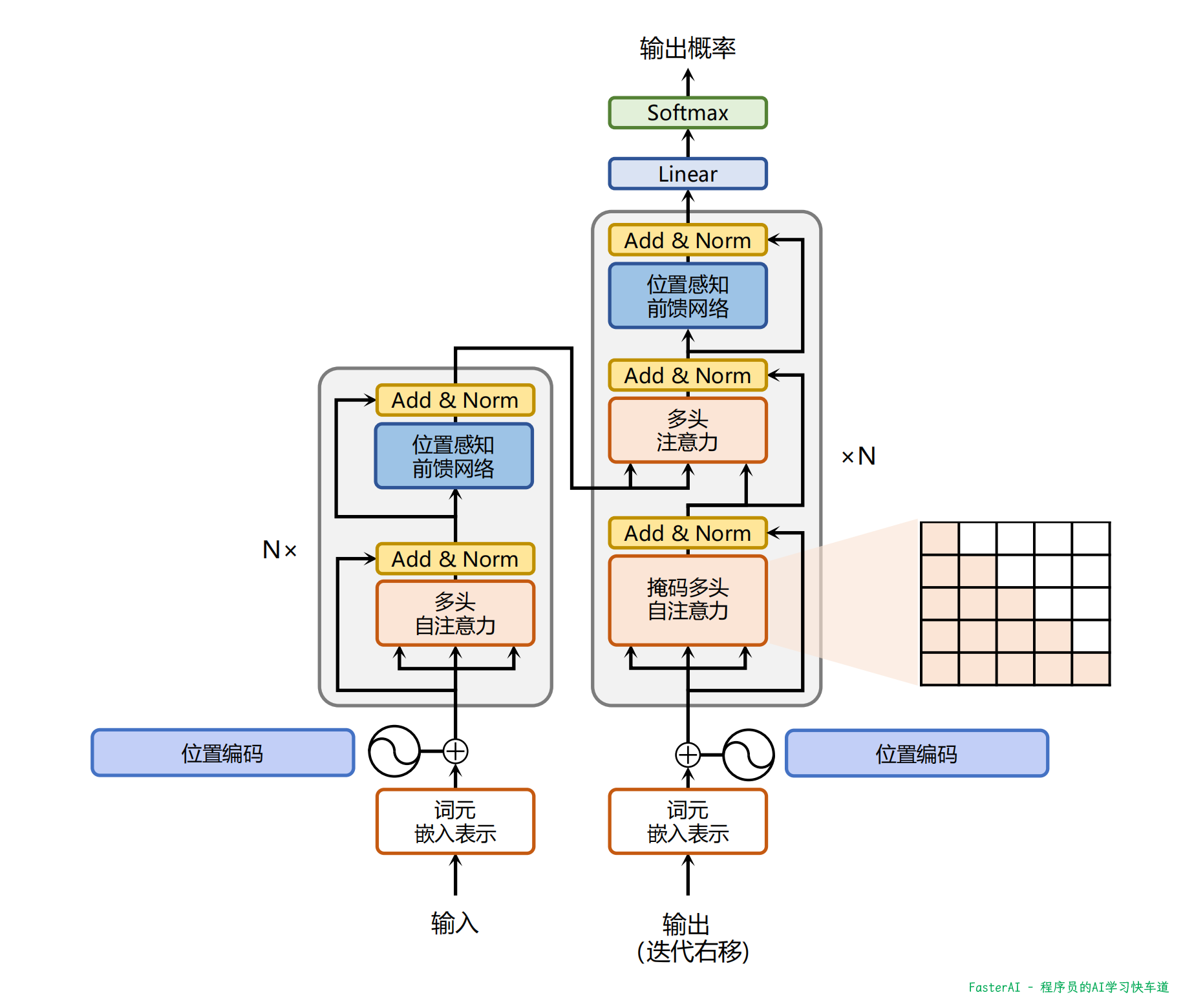
在从输入到输出的语义抽象过程中,主要涉及到如下几个模块:
-
注意力层:使用多头注意力(Multi-Head Attention)机制整合上下文语义,它使得序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本的长程依赖。
-
位置感知前馈层(Position-wise FFN):通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。
-
残差连接:对应图中的 Add 部分。它是一条分别作用在上述两个子层当中的直连通路,被用于连接它们的输入与输出。从而使得信息流动更加高效,有利于模型的优化。
-
层归一化:对应图中的 Norm 部分。作用于上述两个子层的输出表示序列中,对表示序列进行层归一化操作,同样起到稳定优化的作用。
💯 Transformer 编码器有哪些子层?
重要性:★
Transformer 编码器由 2 个子层组成:多头注意力层、前馈网络层。
Transformer 两个编码器串联结构如图所示:
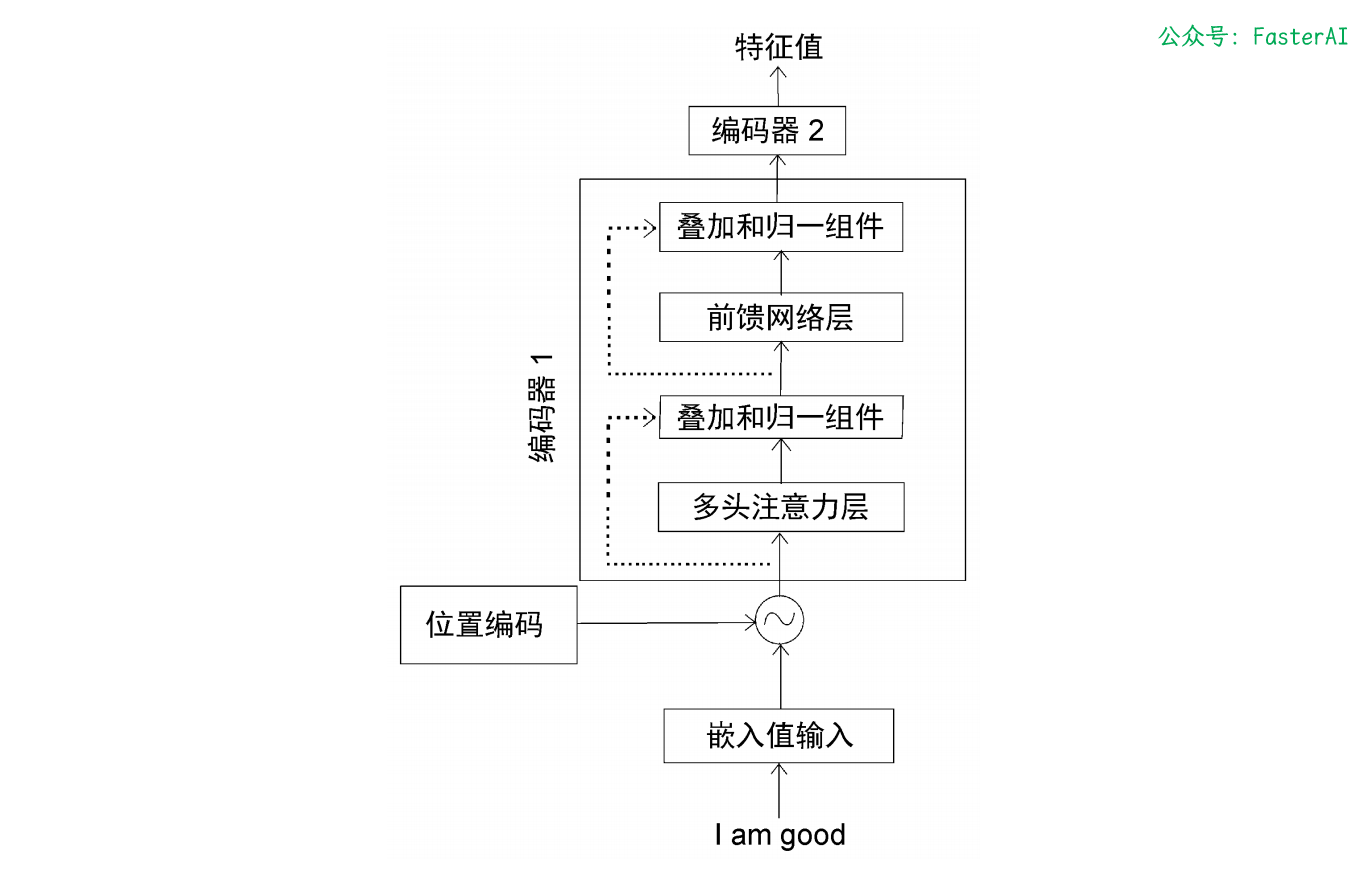
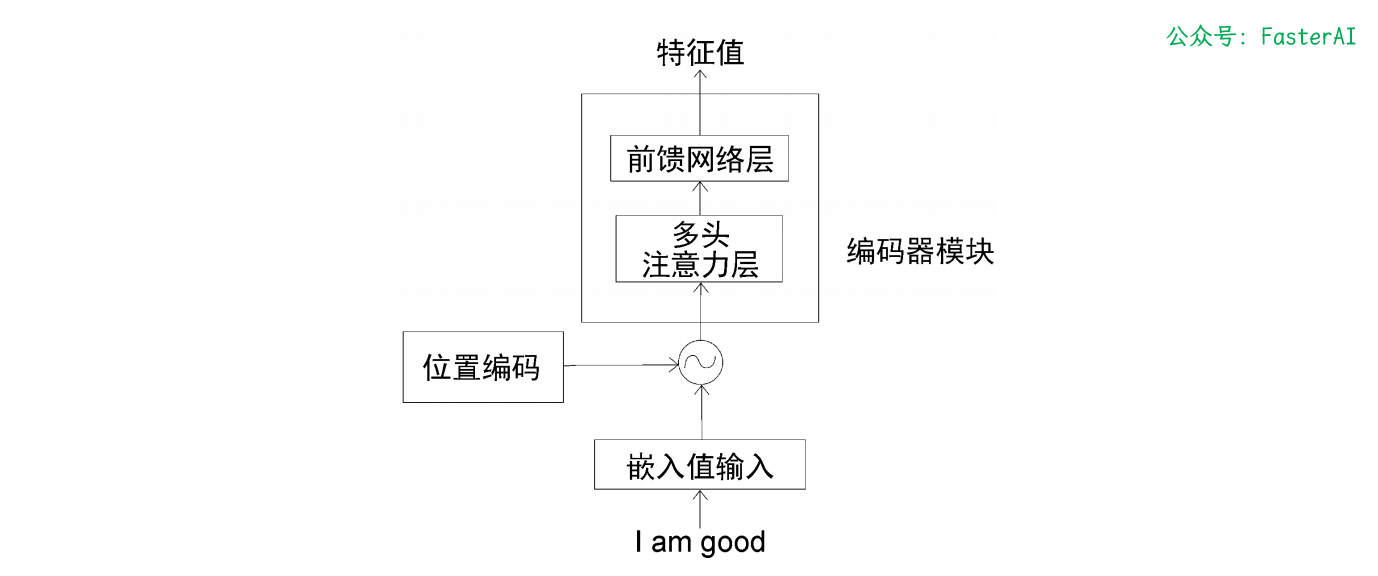
Transformer 编码器的编码有以下步骤:
-
将输入转换为嵌入矩阵(输入矩阵),并将位置编码加入其中,再将结果作为输入传入底层的编码器(编码器 1)。
-
编码器 1 接受输入并将其送入多头注意力层,该子层运算后输出注意力矩阵。
-
将注意力矩阵输入到下一个子层,即前馈网络层。前馈网络层将注意力矩阵作为输入,并计算出特征值作为输出。
-
接下来,把从编码器 1 中得到的输出作为输入,传入下一个编码器(编码器 2)。
-
编码器 2 进行同样的处理,再将给定输入句子的特征值作为输出。
这样可以将 N 个编码器一个接一个地叠加起来。从最后一个编码器(顶层的编码器)得到的输出将是给定输入句子的特征值。
💯 Transformer 解码器有哪些子层?
重要性:★
Transformer 解码器由 3 个子层组成:带掩码的多头注意力层、多头注意力层、前馈网络层。
Transformer 两个解码器串联结构如图所示:
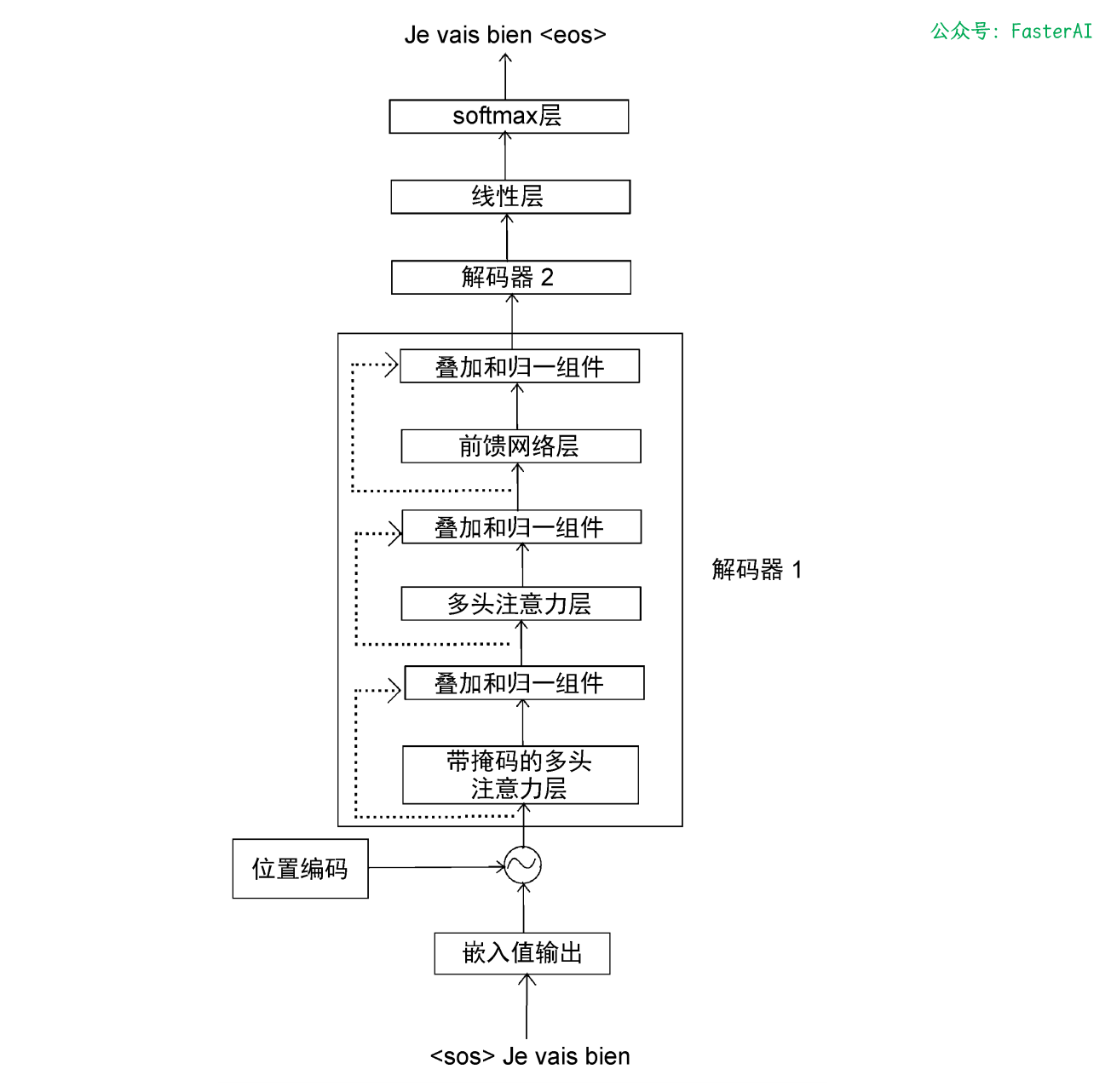
Transformer 解码器的解码有以下步骤: (1)首先,我们将解码器的输入转换为嵌入矩阵,然后将位置编码加入其中,并将其作为输入送入底层的解码器(解码器 1)。 (2)解码器收到输入,并将其发送给带掩码的多头注意力层,生成注意力矩阵 M。 (3)然后,将注意力矩阵 M 和编码器输出的特征值 R 作为多头注意力层(编码器−解码器注意力层)的输入,并再次输出新的注意力矩阵。 (4)把从多头注意力层得到的注意力矩阵作为输入,送入前馈网络层。前馈网络层将注意力矩阵作为输入,并将解码后的特征作为输出。 (5)最后,我们把从解码器 1 得到的输出作为输入,将其送入解码器 2。 (6)解码器 2 进行同样的处理,并输出目标句的特征。
二、核心机制篇
位置编码
💯 Transformer的输入中为什么要添加位置编码?
重要性:★★★
Transformer 将句子中的所有词并行地输入到神经网络中。并行输入有助于缩短训练时间,同时有利于学习长期依赖。不过,并行地将词送入 Transformer,却不保留词序。因此,需要添加一些表明词序(词的位置)的信息,以便网络能够理解句子的含义。这里引入了一种叫作位置编码的技术,以实现上述目标。顾名思义,位置编码是一种表示一个词在句子中的位置(词序)的编码。
编码器中的位置编码:
💯 什么是正弦(Sinusoidal)位置编码?
基于Sinusoidal的位置编码最初是由谷歌在论文Attention is All You Need中提出的方案,用于Transformer的位置编码。具体计算方式如下所示:
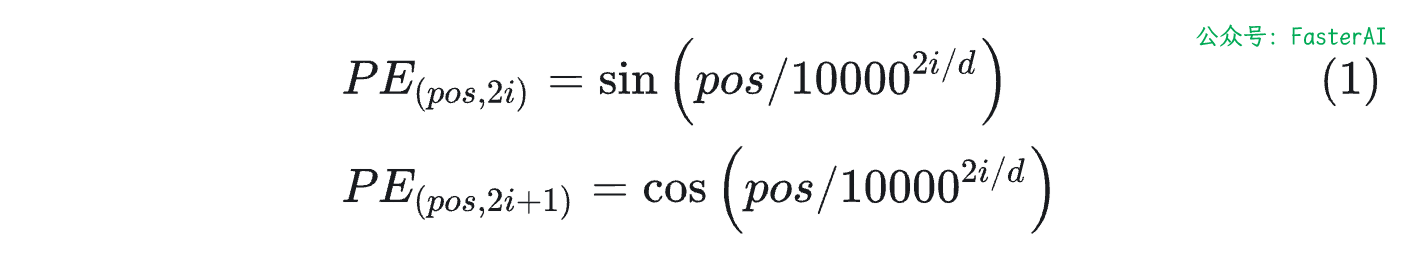
其中pos是位置,i表示维度。
-
具有相对位置表达能力:Sinusoidal可以学习到相对位置,对于固定位置距离的k,PE(i+k)可以表示成PE(i)的线性函数。
-
两个位置向量的内积只和相对位置 k 有关。
-
Sinusoidal编码具有对称性。,即,这表明Sinusoidal编码具有对称性。
- 随着k的增加,内积的结果会直接减少,即会存在远程衰减。
-
正弦编码是否真的具备外推性?实际的Attention计算中还需要与attention的权重W相乘,即 ,这时候内积的结果就不能反映相对距离
-
💯 Transformer的位置编码是如何计算的?
重要性:★★★
Transformer 位置编码矩阵究竟是如何计算的呢?如下所示,Transformer 论文“Attention Is All You Need”的作者使用了正弦函数来计算位置编码:
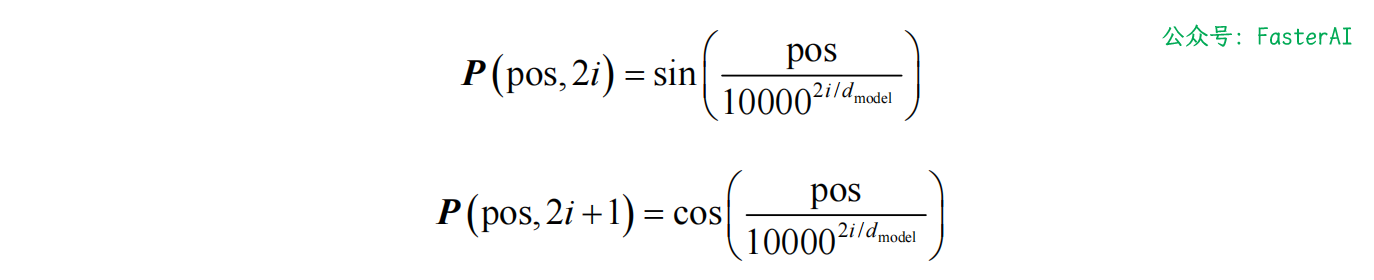
-
表示该词在句子中的位置
-
表示在输入矩阵中的位置
-
表示嵌入维度
计算实例:对于给定的句子 I am good 为例,嵌入维度为4,计算位置编码。
-
根据公式计算位置编码矩阵:
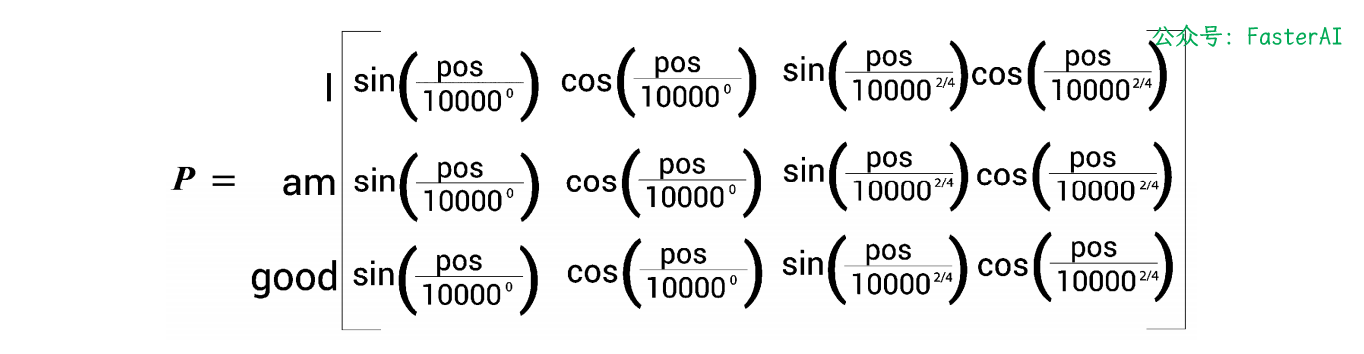
-
计算位置编码矩阵(简化版):
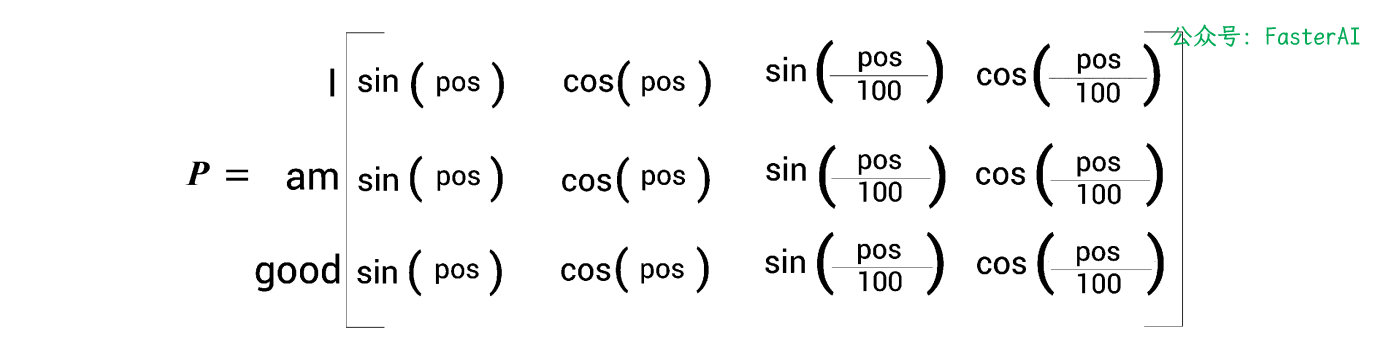
-
继续计算位置编码矩阵:
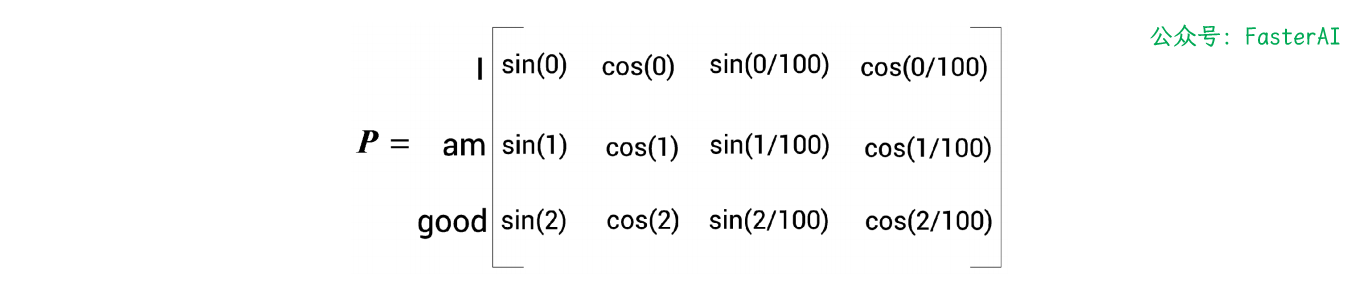
-
最终的位置编码矩阵 如图所示:

💯 正弦位置编码是否真的具备外推性?
似乎Sinusoidal只和相对位置有关。但是实际的Attention计算中还需要与attention的权重W相乘,即 ,这时候内积的结果就不能反映相对距离。
正弦编码中真实的q,k向量内积和相对距离之间,没有远程衰减性,如下图所示:
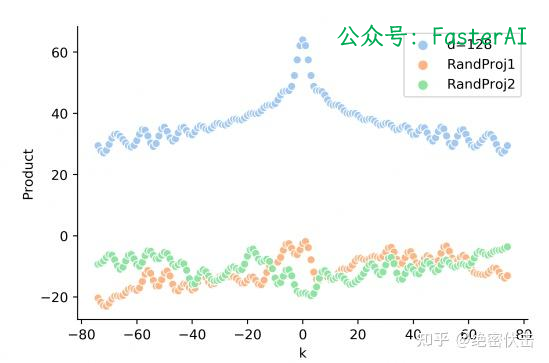
正弦编码本质上是一种绝对位置编码,其设计初衷是为每个位置提供一个唯一的编码。因此,它在处理超出训练序列长度的输入时,缺乏足够的灵活性和泛化能力。
为了克服正弦编码的外推性不足,研究者提出了多种改进方法,如旋转位置编码(RoPE)和ALiBi等。这些方法通过引入额外的机制来增强正弦编码的外推能力,但仍存在一定的局限性。
💯 Position encoding为什么选择相加而不是拼接呢?
重要性:★
首先明确:Transformer 会对原始输入做嵌入(embedding),从而映射到需要的维度,可采用一个变换矩阵做矩阵乘积的方式来实现,Transformer 中的 position embedding 也是加在这个嵌入后的向量中的。
了解这一点后,我们开始尝试使用 concat 的方式在原始输入中加入位置编码:
给每一个位置 concat 上一个代表位置信息的 one-hot 向量 (N代表共有N个位置)形成 ,它也可以表示为 这个形式。
接着对这个新形成的向量做线性变换,即上述提到的 Transformer 对原始输入做的嵌入操作。记变换矩阵 , d 就是需要嵌入到的维度(这里为了简便,直接假设原输入的维度与嵌入维度一致,都是 d ),它也可以表示为 ,其中 , 。现在进行变换:
由变换结果可知,在原输入上 concat 一个代表位置信息的向量在经过线性变换后等同于将原输入经线性变换后直接加上位置编码信息。
也就是说,可以用concat的形式来表示add,某种程度上两者是等价的,但是使用concat会使维度变大,增加计算量。
多头注意力
💯 Self-Attention 是什么?
一般而言,注意力机制中的Q、K、V的来源不同。与之相对,自注意力机制的Q、K、V均来源于同一个输入X。注意力机制(self-attention mechanism)是指在处理序列元素时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。它通过计算元素之间的相对重要性来自适应地捕捉元素之间的长程依赖关系。
自注意力的计算过程如下:
-
生成 Q、K、V 向量 ![[Pasted image 20250117143547.png]]
-
计算注意力权重 ![[Pasted image 20250117143623.png]]
-
加权和
![[Pasted image 20250117143639.png]]
![[Pasted image 20250117143833.png]]
💯 多头注意力相对于单头注意力有什么优势?
重要性:★★★
Transformer原文中使用了 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息。简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。
其核心思想在于,多头注意力相比单头注意力是更软的注意力机制,对每个词蕴含的不同语义维度给予不同的权重。
实例:以 All is well 这句话为例,假设我们需要计算 well 的自注意力值。以此为实例来理解多头注意力层的作用。
在计算相似度分数后,我们得到单词 well 的自注意力值:
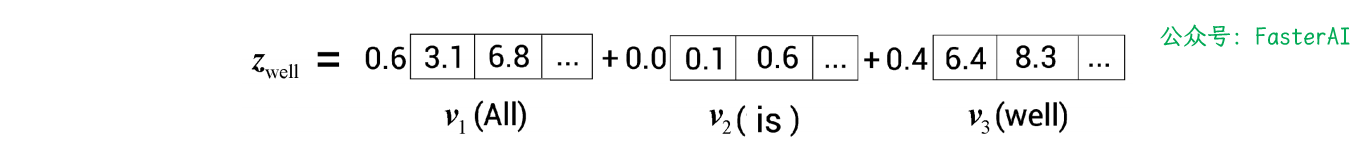
从图中可以看出,well 的自注意力值是分数加权的值向量之和,并且它实际上是由 All 主导的。也就是说,将 All 的值向量乘以 0.6,而 well 的值向量只乘以了0.4。**这意味着 zwell 将包含 60%的 All 的值量,而 well 的值向量只有 40%**。
因此,如果某个词实际上由其他词的值向量控制,只使用1个头的注意力,就会将关注词所有嵌入维度(不同语义维度)设置为统一的权重,这样反而会引入噪声。
为了确保结果准确,我们不能依赖单一的注意力矩阵,而应该计算多个注意力矩阵,对不同的嵌入维度设置不同的权重,并将其结果串联起来。使用多头注意力的逻辑是这样的:使用多个注意力矩阵,而非单一的注意力矩阵,可以提高注意力矩阵的准确性。。
多头注意力矩阵,公式如下所示:

💯 Transformer中自注意力模块的计算过程?
重要性:★★★
注意力矩阵 Z 由句子中所有单词的自注意力值组成,它的计算公式如下:
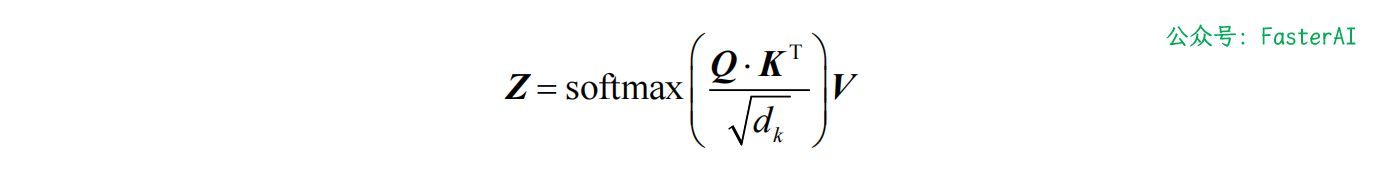
自注意力机制的计算步骤总结如下:

自注意力机制的计算流程图如图所示:
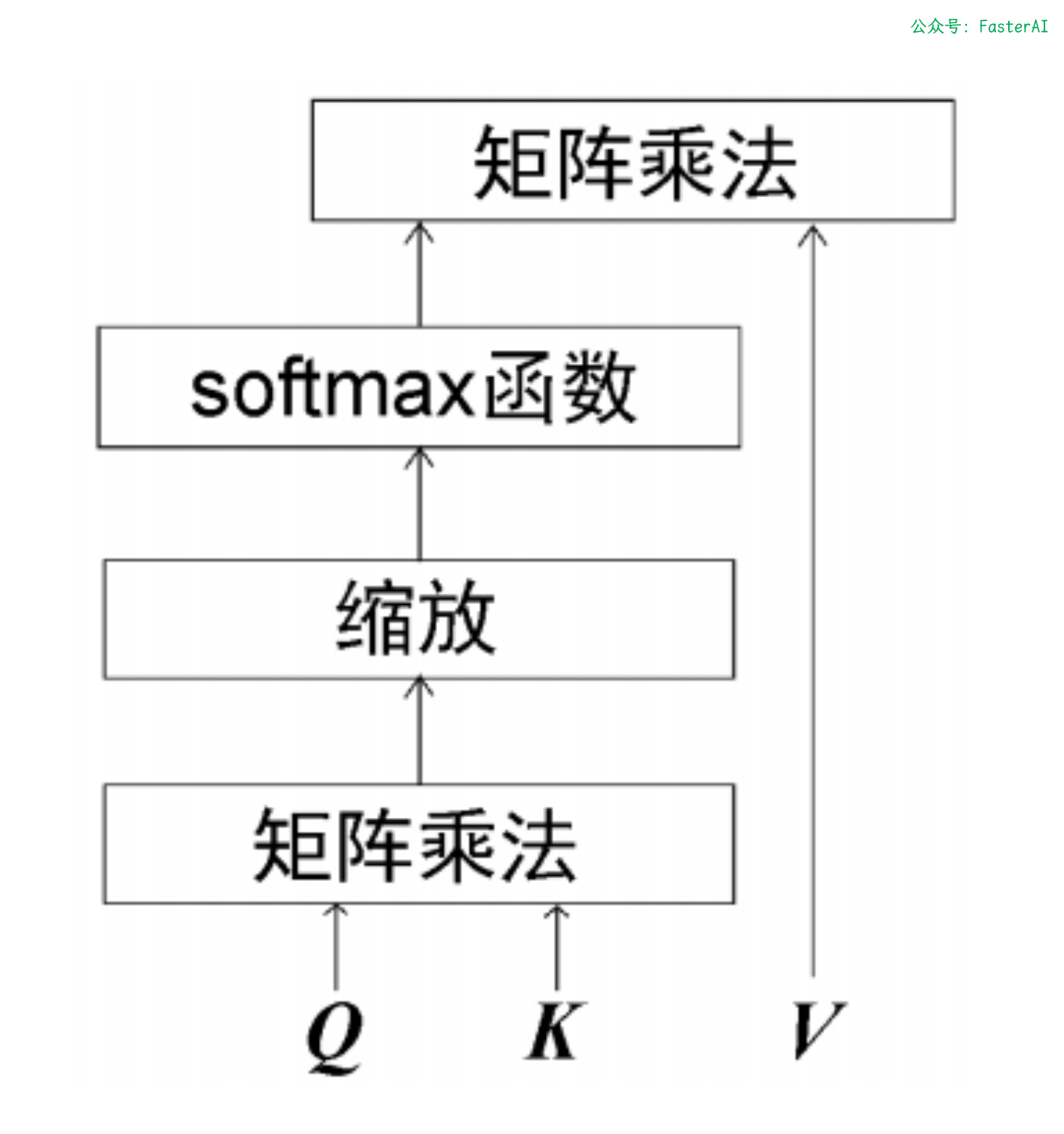
Transformer 自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用 对结果进行缩放。
💯 什么是缩放点积注意力,为什么要除以 ?
重要性:★★★
Transformer 自注意力机制也被称为缩放点积注意力机制,这是因为其计算过程是先求查询矩阵与键矩阵的点积,再用 对结果进行缩放。这样做的目的主要是获得稳定的梯度。
因为当输入信息的维度 d 比较高,会导致 softmax 函数接近饱和区,梯度会比较小。因此,缩放点积模型可以较好地解决这一问题。
残差连接
💯 Transformer为什么要使用残差连接?
由 Transformer 结构组成的网络结构通常都是非常庞大。编码器和解码器均由很多层基本的Transformer 块组成,每一层当中都包含复杂的非线性映射,这就导致模型的训练比较困难。
因此,在 Transformer 块中进一步引入了残差连接与层归一化技术以进一步提升训练的稳定性。
具体来说,残差连接主要是指使用一条直连通道直接将对应子层的输入连接到输出上去,从而避免由于网络过深在优化过程中潜在的梯度消失问题:
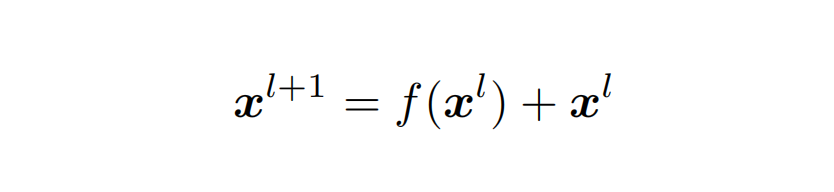
💯 使用残差连接有哪些好处?
残差连接(Residual Connection)在深度学习中具有多方面的好处,以下是其主要优点的详细说明:
-
缓解梯度消失问题:
深层神经网络中,由于连续的非线性层叠加,反向传播过程中梯度可能会逐渐减小甚至消失,导致网络难以训练。残差连接通过为梯度提供一条“捷径”,使得梯度可以直接从输出层流向输入层,从而有效缓解了梯度消失的问题。 -
提高训练效率和稳定性:
残差连接允许网络中的信息直接从输入传递到后续层,减少了中间层的复杂性,使得网络更容易收敛。这不仅提高了训练速度,还增强了模型的稳定性。 -
增强模型表达能力:
残差连接使得每一层可以学习到输入和输出之间的“残差”,即输入与输出之间的差异。这种设计使网络能够构建更复杂的函数,从而提高了模型的表达能力。 -
促进深层网络的训练:
通过引入残差连接,可以构建更深的网络结构,而不会遇到梯度消失或爆炸的问题。这使得深层网络在图像识别、语音识别等任务中表现更加出色。 -
信息传递效率的提升:
残差连接允许信息在网络中更有效地流动,避免了传统层与层之间完全依赖于层叠结构的信息传递方式可能导致的问题。这种设计提高了信息传递的效率,使网络能够更好地捕捉深层次特征。
层归一化
💯 为什么要做归一化?
在训练模型之前,对训练数据集进行标准化和归一化处理,可以加快模型的收敛速度,而且更重要的是在一定程度上缓解了深层网络中梯度弥散的问题,从而使训练深层网络模型更加容易。归一化处理是深度神经网络训练常用的技巧。
归一化的具体作用是归纳统一样本的统计分布性,归一化在[0,1]之间是统计的概率分布,归一化在[-1, 1]之间是统计的坐标分布。为了建模或计算方便,首先要保持度量单位的同一性,在深度学习中,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权重只能同时增加或减小,从而导致学习速度很慢。
为了避免出现这种情况并方便后面数据的处理,加快网络学习速度,可以对输入信号进行归一化,使所有样本的输入信号均值接近于0或与其均方差相比很小。
总结起来,主要有以下原因: (1)应用层面需要统一量纲,因为样本数据的评价标准不一样,需要对其量纲化,统一评价标准。 (2)在使用梯度下降的方法求解最优化问题时,归一化或标准化后可以加快梯度下降的求解速度,即提升模型的收敛速度。 (3)应用归一化可以避免神经元饱和,当神经元的激活在接近0或1时会饱和,在这些区域,梯度几乎为0。这样,在反向传播过程中,局部梯度就会接近0,此时应用归一化可以有效地减少梯度消失。 (4)避免输出数据中小的数值被吞食,也避免太大的数值引发数值问题。
💯 Layer Normalization 是什么?
Layer Normalization(层归一化)是一种在深度学习中用于稳定神经网络训练的技术。它由 Jimmy Ba 和 George Hinton 在 2016 年提出,旨在解决训练过程中由于激活函数饱和导致的梯度消失或爆炸问题,从而提高模型的训练速度和性能。
具体来说,Layer Normalization 对每一层的输入进行归一化处理,而不是像 Batch Normalization 那样对整个批次的数据进行归一化。它的核心思想是通过计算每个样本在特征维度上的均值和方差,并使用这些统计量对输入进行标准化处理。这样可以使得每一层的输入具有相似的分布特性,从而避免了训练过程中由于输入变化带来的不稳定性。
Layer Normalization 的计算公式如下:
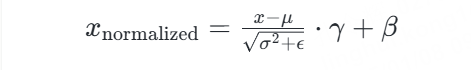
Pasted image 20250115193139
其中, 是输入数据,μ 是均值,σ 是方差,ϵ 是一个非常小的正数以防止除零,γ 和 β 是可学习的参数,分别用于缩放和平移。
💯 Layer Normalization 有什么用?
Layer Normalization 的主要优点包括:
-
适用于循环神经网络(RNN) :由于不需要依赖于批次大小,Layer Normalization 可以直接应用于 RNN 中,解决了 Batch Normalization 在序列长度不固定时的局限性。
-
提高训练稳定性:通过标准化输入,Layer Normalization 可以减少内部协变量偏移(internal covariate shift),使模型训练更加稳定。
-
加速训练过程:Layer Normalization 可以减少训练时间,因为它不需要像 Batch Normalization 那样依赖于小批量数据的统计信息。
Layer Normalization 是一种有效的神经网络正则化技术,广泛应用于深度学习模型中,特别是在自然语言处理(NLP)任务和 Transformer 模型中。
💯 批归一化和层归一化的区别?
批归一化(Batch Normalization,BN)和层归一化(Layer Normalization,LN)是深度学习中两种常见的归一化技术,它们在处理数据时有着显著的区别。
- 归一化的对象不同:
-
批归一化是对整个批次(batch)的数据进行归一化。具体来说,它计算每个批次中的样本均值和方差,然后对每个样本的特征进行标准化处理。这意味着,对于一个包含多个样本的批次,每个特征维度都会被独立地归一化,以确保数据的分布更加稳定和均一。
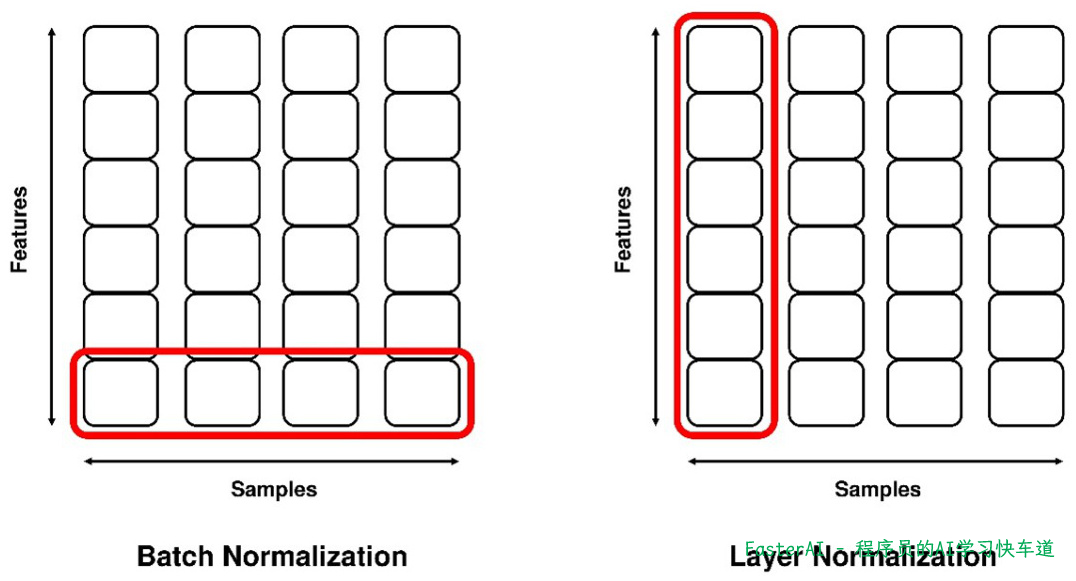
-
层归一化则是对单个样本的所有特征进行归一化。也就是说,对于一个样本,它的所有特征值会被一起标准化,而不是像批归一化那样分别对每个特征维度进行处理。因此,层归一化不会保留样本之间的差异,而是将所有特征视为一个整体进行处理。
-
- 适用场景的不同:
-
批归一化更适合于大规模数据集的训练,因为它依赖于批次中的样本数量来计算均值和方差。当样本数量较大时,批归一化能够有效地减少内部协变量偏移,加速模型的收敛速度,并提高模型的泛化能力。
-
层归一化则更适用于小批量训练或单样本推理场景。由于它不依赖于批次大小,层归一化可以更好地适应变长序列数据(如自然语言文本),并且在循环神经网络(RNN)等模型中表现优异。此外,层归一化有助于保持样本间的差异性,从而避免了批归一化可能带来的信息丢失问题。
-
- 计算方式的不同:
-
批归一化的计算是对于每个特征维度,计算该维度在当前批次中的均值和方差,然后对每个样本的该特征进行标准化处理。
-
层归一化的计算是对于每个样本的所有特征,计算其整体的均值和方差,然后进行标准化处理。
-
- 对模型性能的影响:
-
批归一化通过减少内部协变量偏移,有助于加速训练过程并提高模型的稳定性。然而,在小批量训练时,其效果可能会受到限制,因为小批量的数据可能无法准确反映整体分布。
-
层归一化则能够更好地适应不同长度的输入序列,并且在处理序列数据时表现出更高的稳定性。此外,层归一化不会破坏样本的位置信息,这在某些任务中可能是一个优势。
-
批归一化和层归一化各有优缺点,选择哪种方法取决于具体的应用场景和数据特性。批归一化适合大规模数据集和批量训练,而层归一化则更适合小批量训练和序列数据处理。
💯 Layer Normalization 有哪几个可训练参数?
为了进一步使得每一层的输入输出范围稳定在一个合理的范围内,层归一化技术被进一步引入每个 Transformer 块的当中:
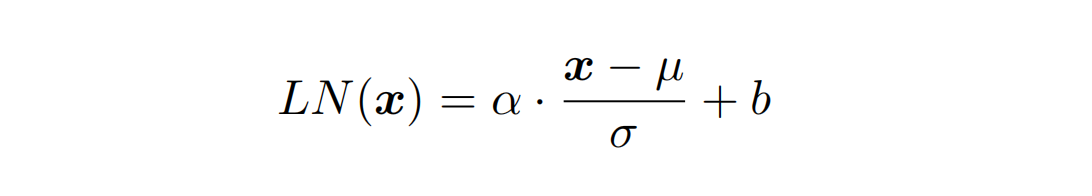
其中 µ 和 σ 分别表示均值和方差,用于将数据平移缩放到均值为 0,方差为 1 的标准分布,α 和 b是可学习的参数。层归一化技术可以有效地缓解优化过程中潜在的不稳定、收敛速度慢等问题。
使用 Pytorch 实现的层归一化参考代码如下:
class NormLayer(nn.Module):
def __init__(self, d_model, eps = 1e-6):
super().__init__()
self.size = d_model
## 层归一化包含两个可以学习的参数
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm
Mask 机制
💯 解码器中为什么要使用Mask?
在Transformer模型的解码器中使用mask的主要原因是为了确保模型在生成序列时遵循自回归(autoregressive)的特性,即在生成当前词时只能依赖于之前已经生成的词,而不能看到未来的信息。这种机制有助于保持序列生成的顺序性和逻辑性,从而提高模型的预测准确性和泛化能力。
解码器中的mask操作通过限制注意力机制的视野,使得模型在计算注意力分数时只能关注到当前时刻之前的信息。例如,在计算某个词的注意力分数时,mask会将未来词的位置对应的注意力分数设置为非常小的值(如负无穷),这样在经过softmax函数后,这些位置的权重几乎为零,从而实现对未来的屏蔽效果。
这种机制模拟了真实推理场景中的情况,即在生成下一个词时,模型无法看到后续词的信息。这不仅有助于防止模型在训练过程中出现不稳定的预测结果,还能确保生成的序列符合自然语言处理任务中的顺序性要求。
解码器中使用mask是为了确保Transformer模型在生成序列时能够遵循自回归特性,避免因看到未来信息而导致的不准确预测,并保持生成过程的顺序性和逻辑性。
💯 Transformer 中有几种 Mask?
Transformer模型中主要有两种类型的Mask,分别是Padding Mask和Sequence Mask。
-
Padding Mask:这种Mask用于处理输入序列长度不一致的问题。在自注意力机制中,较短的序列会被填充为相同的长度,而这些填充的位置会通过设置为无穷小(负无穷大)来忽略掉,从而不影响模型的计算结果。
-
Sequence Mask:这种Mask用于防止在解码器生成输出时,当前位置的信息被后续位置的信息影响。具体来说,它会在自注意力计算中遮盖掉当前位置之后的信息,确保生成的单词只依赖于之前已经生成的单词。
💯 Padding Mask 是如何实现的?
Padding Mask 是一种用于处理变长序列数据的掩码机制,主要用于在 Transformer 模型中区分输入序列中的真实数据和填充数据。
Padding Mask 是一个布尔矩阵,用于指示输入序列中哪些位置是填充的(即用 0 填充的位置),哪些位置是实际数据(即非填充的位置)。其主要目的是在自注意力机制中屏蔽掉填充部分,确保模型不会将这些无意义的填充数据纳入计算,从而提高模型的效率和准确性。
具体实现方式如下: - 在生成 Padding Mask 时,通常会根据输入序列的长度动态生成一个与输入序列形状相同的矩阵。例如,对于一个长度为 L 的序列,Padding Mask 的形状可以是 [B, L],其中 B 是批次大小。 - 具体实现上,可以通过比较输入序列中的每个位置是否为填充符号(如 PAD),然后将填充位置标记为 False,非填充位置标记为 True。
在 Transformer 的自注意力机制中,Padding Mask 被用来屏蔽掉填充部分的位置。具体来说,当计算注意力分数时,填充位置的注意力权重会被设置为一个非常大的负数(如负无穷),这样在经过 softmax 归一化后,这些位置的权重几乎为零,从而不会对模型的输出产生影响。
此外,在模型训练过程中,Padding Mask 还可以防止填充数据对模型学习产生干扰,确保模型只关注实际输入的有效部分。
💯 Sequence Mask 是如何实现的?
Sequence Mask 是一种用于在自注意力机制中防止模型“看到”未来信息的掩码技术。具体来说,它通过生成一个下三角矩阵来实现,该矩阵的上三角部分为0,而对角线及其以下部分为1。这个矩阵的作用是将自注意力计算中的权重设置为0,从而确保在时间步 t 的解码输出只能依赖于 t 时刻之前的输入,而不能依赖于 t 之后的信息。
在实际应用中,Sequence Mask 主要用于 Transformer 模型中的解码器部分。例如,在生成序列时,通过将当前位置之后的信息权重设置为负无穷大(或直接设置为0),可以有效地阻止模型访问这些信息。这种机制确保了模型在生成每个新词时,只能基于已生成的词进行预测,从而保证了生成序列的自回归性质。
Sequence Mask 的实现通常涉及以下步骤:
-
生成掩码矩阵:根据序列长度生成一个形状为
[batch_size, seq_len, seq_len]的下三角矩阵。 -
应用掩码:将该掩码矩阵与缩放点积注意力(scaled dot-product attention)的结果相乘,以屏蔽掉未来信息的影响。
三、问题优化篇
💯 LLM为何使用 GQA 代替 MHA?
重要性:★★
随着模型规模越来越大,训练和推理时需要的显存越来越多,为了降低大模型的计算量,需要使用缓存注意力机制代替Transformer原始的多头注意力机制,达到既节约时间,又节约显存的目的。
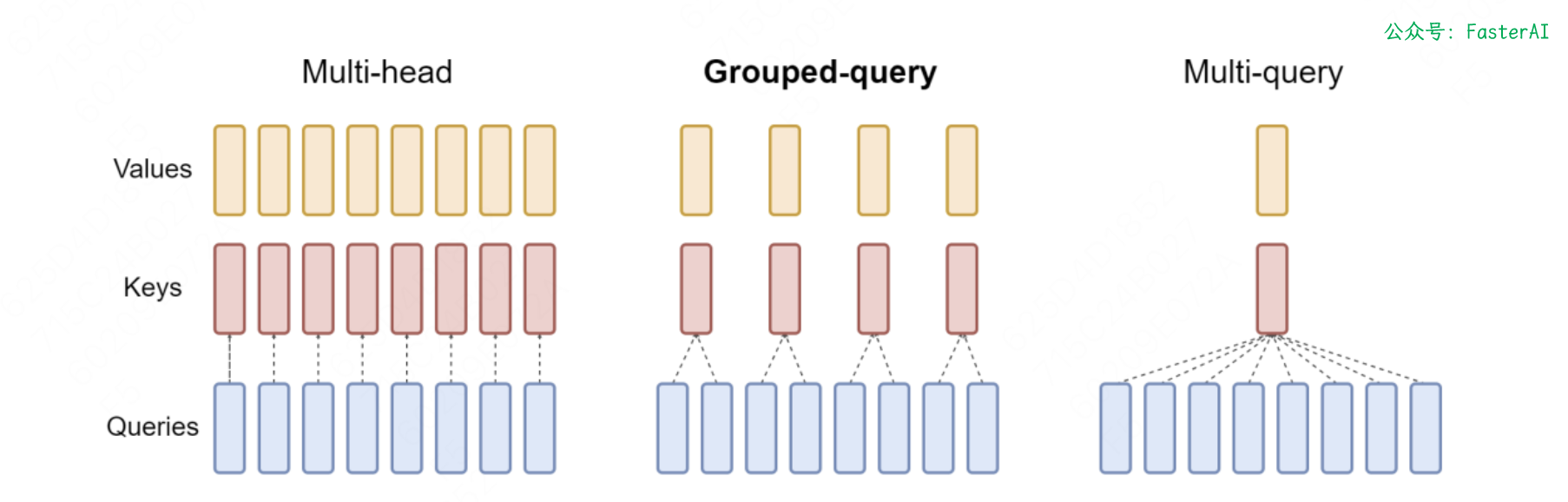
最极端的做法是MQA(多查询注意力),MQA能够大幅加速采用MHA的Transformer的推理,但是会有明显的性能损失,而GQA(分组查询注意力)通过设置合适的分组大小,可以和MQA的推理性能几乎相等,同时逼近MHA的模型性能。
MQA和GQA对推理的帮助主要是以下两点:
-
降低内存读取模型权重的时间开销:由于Key矩阵和Value矩阵数量变少了,因此权重参数量也减少了,需要读取到内存的数量量少了,因此减少了读取权重的等待时间
-
KV-Cache空间占用明显降低:KV-Cache会将之前推理过的Key、Value向量存储在内存中,而随着步长和batch_size的增长,KV-Cache空间占用越来越高,使得KV-Cache不能被高效的读写,而MHA和GQA方式使得KV-Cache需要存储的参数量降低了head_num倍,从而提高KV-Cache的读写效率;另一方面,可以有空间来增大batch_size,从而提高模型推理的吞吐量。
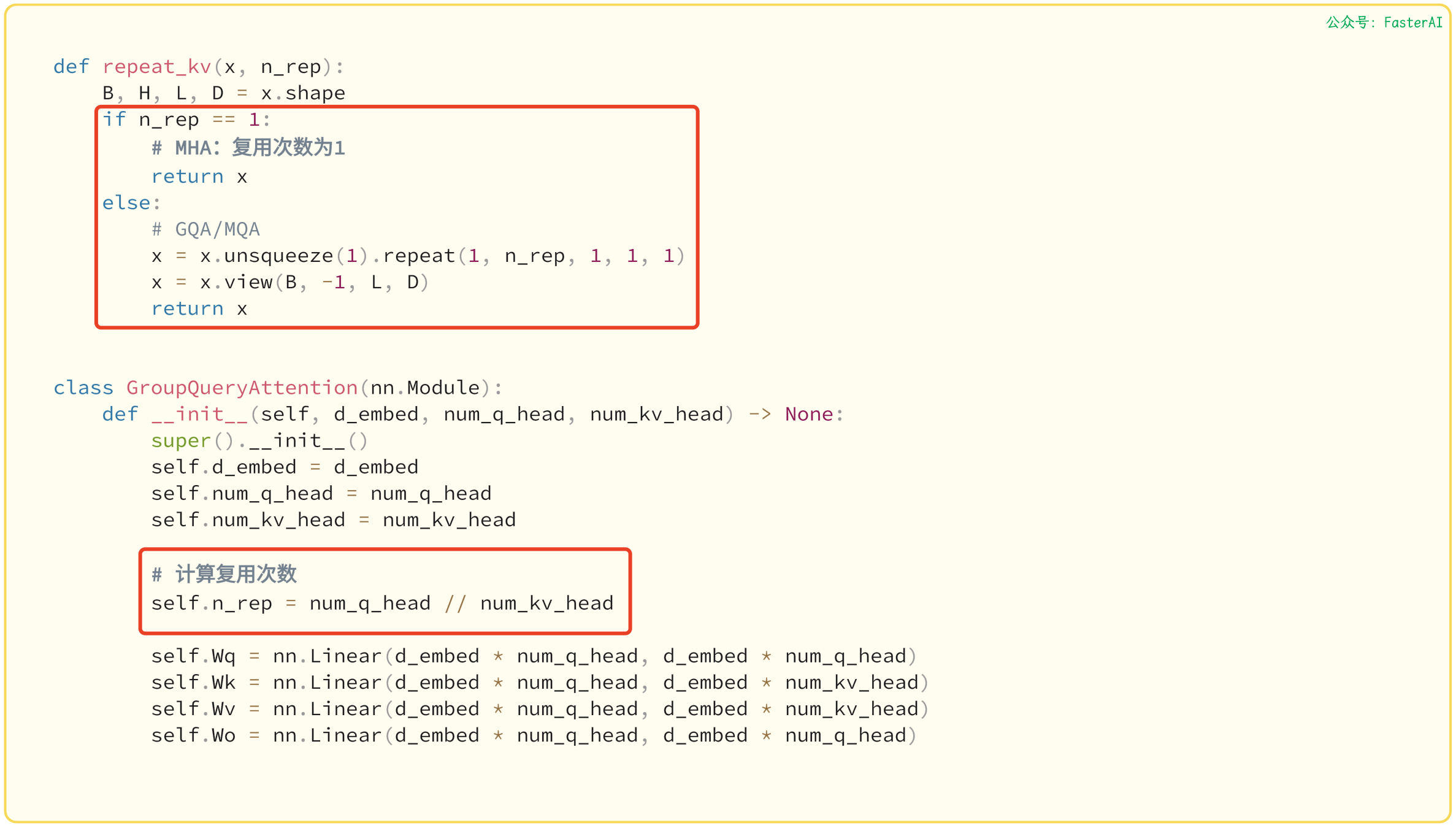
GQA的代码实现:

💯 LLM为何使用 PreNorm 代替 PostNorm?
重要性:★
PreNorm(前归一化)和PostNorm(后归一化)是Transformer模型中的两种不同归一化策略。它们的主要区别在于Layer Normalization(LN)的位置不同,这影响了模型的训练稳定和最终性能。
-
PreNorm:在自注意力机制或前馈网络(FFN)之前进行归一化。这种结构在训练时通常更容易和更稳定,但有观点认为它的深度学习效果不如PostNorm,因为它可能在增加模型宽度的同时减少了有效深度,导致模型的深度有“水分”。
-
PostNorm:在自注意力机制或前馈网络之后进行归一化。原始的Transformer模型使用的是PostNorm,它有助于稳定梯度,但可能需要更仔细的参数调整,如学习率预热(warm-up)策略。
PostNorm在训练上可能更具挑战性,但有研究表明,它在迁移学习等任务中可能有更好的表现。此外,PostNorm的模型在训练完成后,其效果往往优于PreNorm。
然而,PreNorm由于其更稳定的训练特性,随着大模型层数的加深对训练稳定性的要求更高,所以目前在许多大型模型中得到了广泛应用。
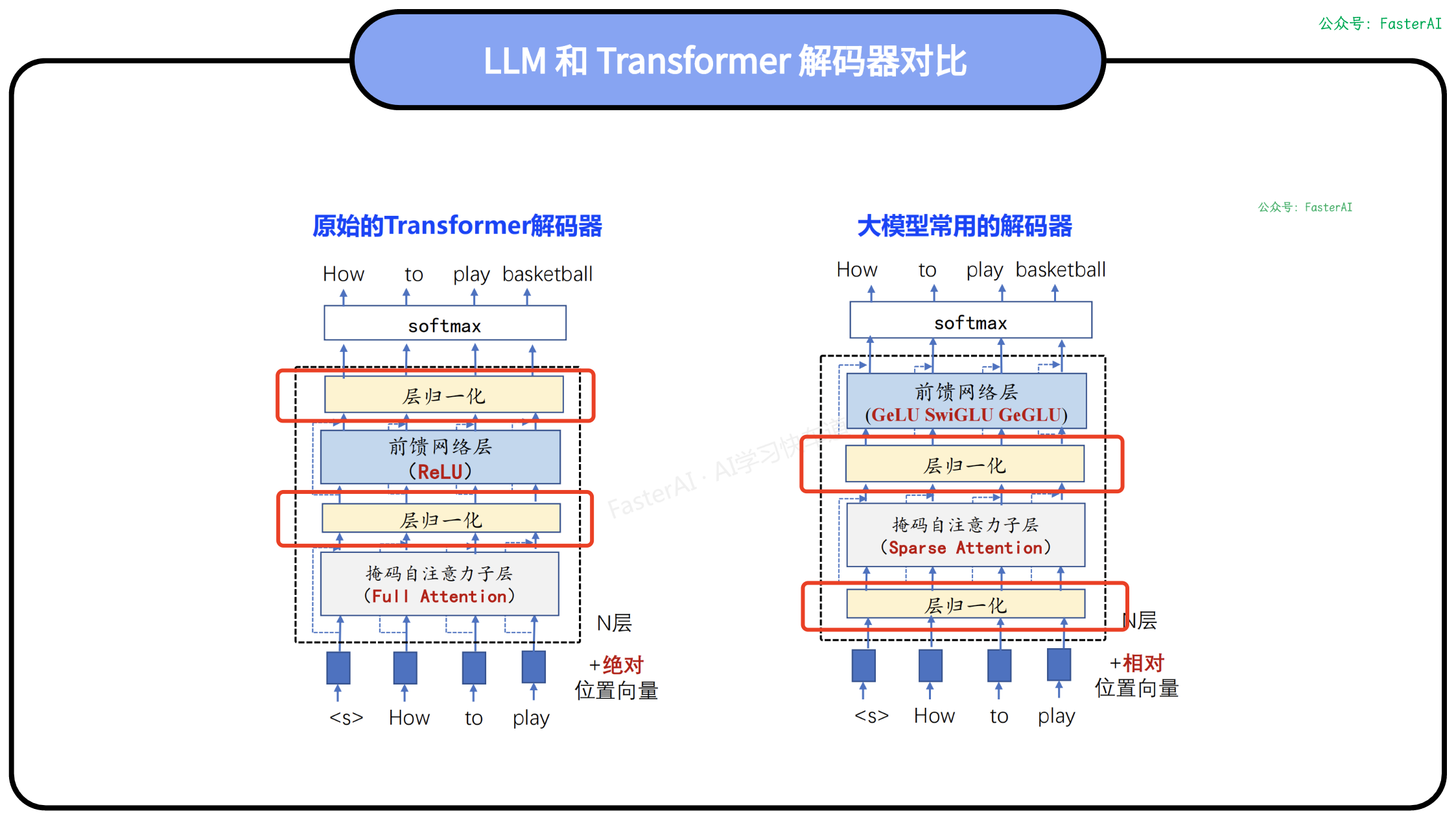
💯 LLM为何使用 RMSNorm 代替 LayerNorm?
重要性:★★★
大模型使用RMSNorm代替LayerNorm是为了降低计算量。
均方根归一化 (Root Mean Square Layer Normalization,RMS Norm)论文中提出,层归一化(Layer Normalization)之所以有效,关键在于其实现的缩放不变性(Scale Invariance),而非平移不变性(Translation Invariance)。
基于此,RMSNorm在设计时简化了传统层归一化的方法。它移除了层归一化中的平移操作(即去掉了均值的计算和减除步骤),只保留了缩放操作。
因此 RMSNorm 主要是在 LayerNorm 的基础上去掉了减均值这一项,其计算效率更高且没有降低性能。
RMS Norm针对输入向量 x,RMSNorm 函数计算公式如下:
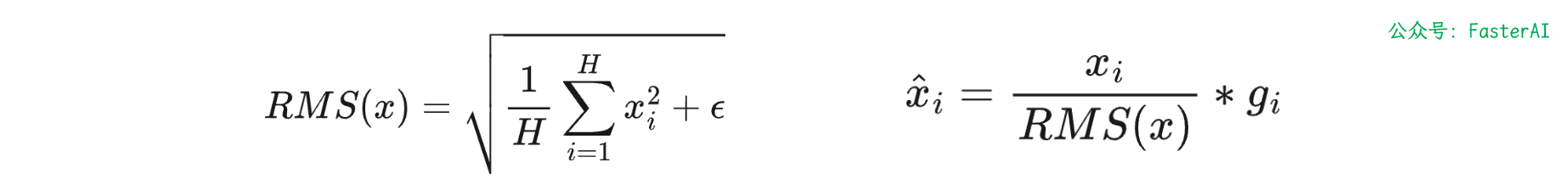
层归一化(LayerNorm)的计算公式:
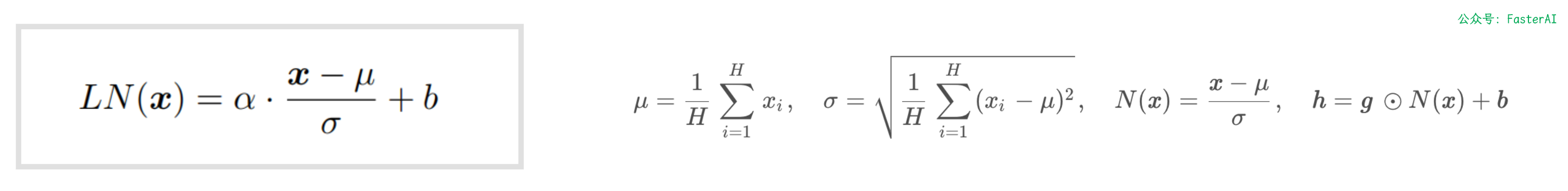
经过对比,可以清楚的看到,RMSNorm 主要是在 LayerNorm 的基础上去掉了减均值这一项,计算量明显降低。
RMSNorm 层归一化的代码实现:

💯 LLM使用 SwiGLU 相对于 ReLU 有什么好处?
重要性:★★★ 💯
使用的SwiGLU替换ReLU最重要的原因是SwiGLU可以更好的捕获序列的特征。
① 使用ReLU的FFN的计算公式:
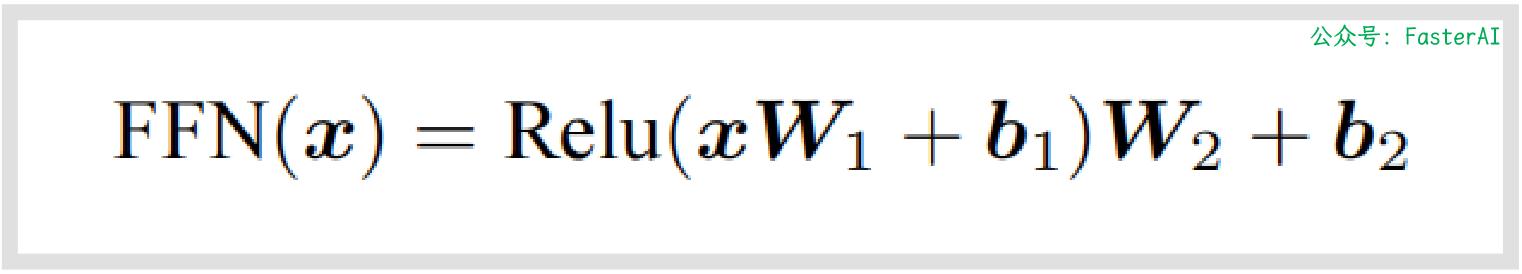
② 使用SwiGLU的FFN的计算公式:
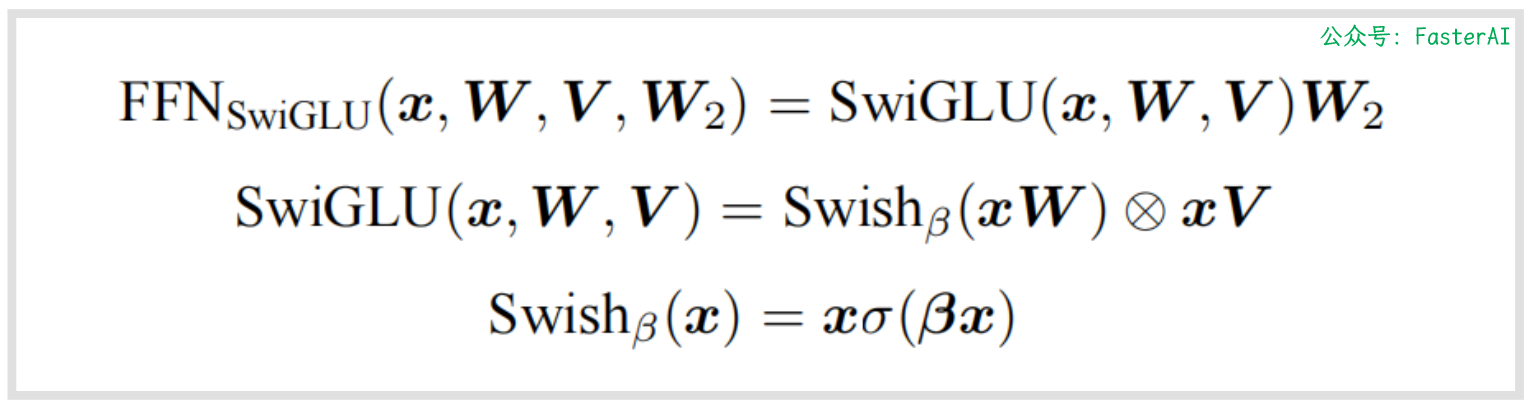
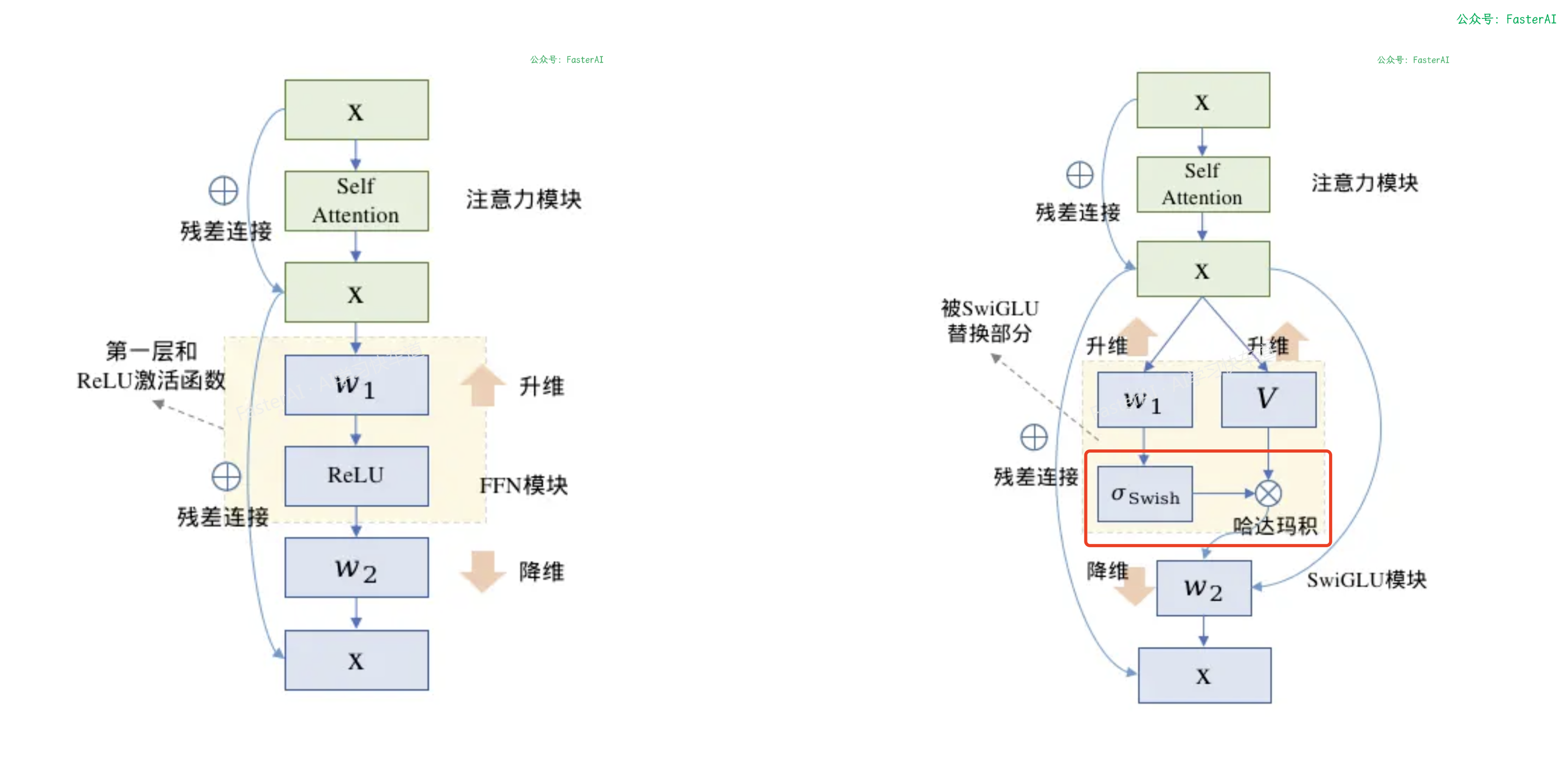
更直观的看下ReLU和SwiGLU的可视化对比:
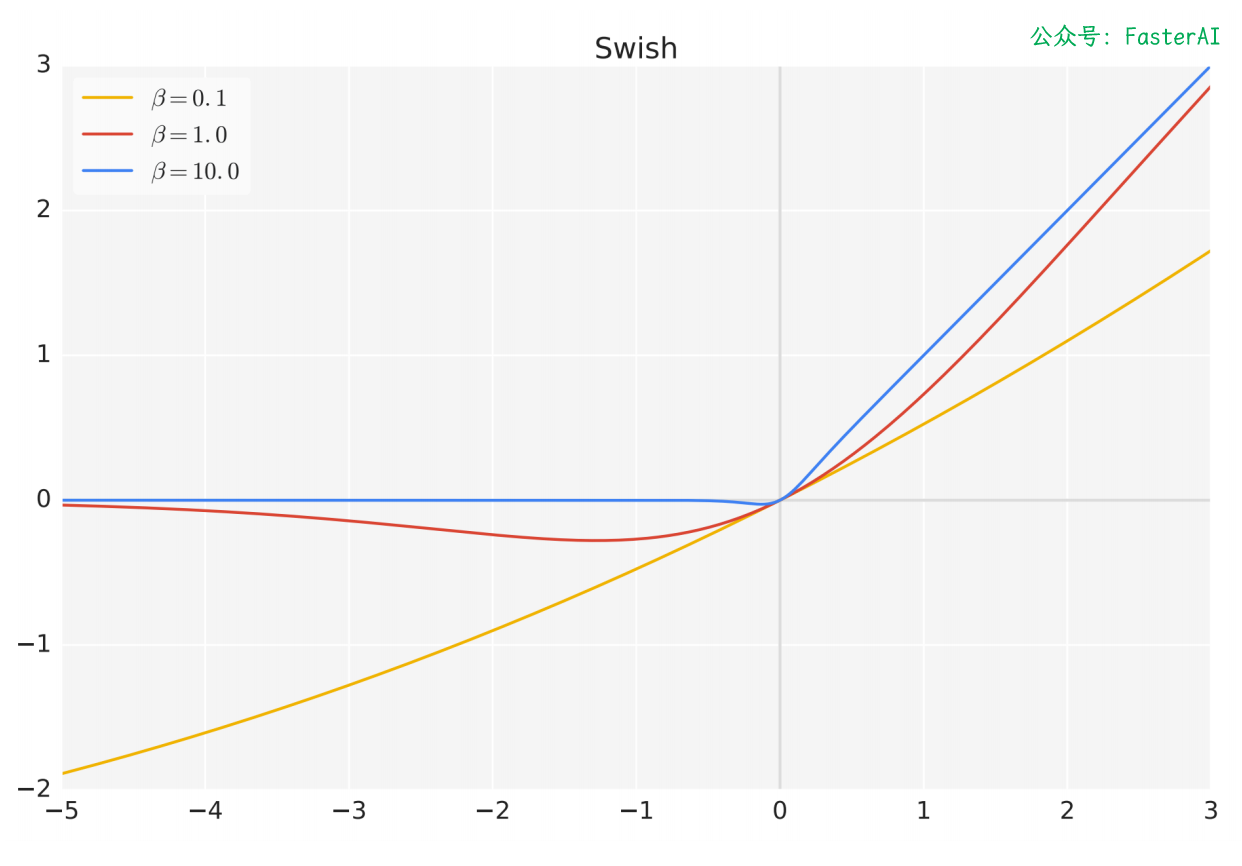
Swish 激活函数在参数 β 不同取值下的形状:
SwiGLU在计算中引入了门控机制,门控机制可以使用更软性的权重筛选有用的信息,并且梯度更平滑。这么做有以下几个主要好处:
-
动态门控机制:SwiGLU继承了GLU的门控特性,通过使用sigmoid函数作为门控器,可以对输入信号进行筛选和选择性放大。这种门控机制允许模型自适应地选择哪些信息是重要的,从而有助于提高模型对数据的表示能力。
-
增加非线性和复杂度:SwiGLU通过引入Swish激活函数,为神经网络增添了更多的非线性,使得模型能够捕捉和学习数据中更为复杂的特征和模式。
-
提高信息流动的效率:SwiGLU的门控机制使得模型能够更有效地管理和调整信息的流动,减少无关信息的干扰,提高了信息处理的效率。
-
避免“dying ReLU”问题:ReLU的一个主要问题是“dying ReLU”,即某些神经元在训练过程中可能永远不会被激活,导致这些神经元对网络的贡献为零。SwiGLU通过其动态门控机制,减少了这种问题的发生。
-
提高模型精度:在某些任务中,SwiGLU可以显著提高模型的精度,尤其是在自然语言处理任务中,如GLUE和SuperGLUE,SwiGLU的使用可以带来超过4%的精度提升。
【NLP百面百过】大模型算法高频面题(全面整理 ʘ‿ʘ)
全面总结了【大模型面试】的高频面题和答案解析,答案尽量保证通俗易懂且有一定深度。
适合大模型初学者和正在准备面试的小伙伴。
旨在帮助AI工程师快速完成面试准备,先人一步顺利拿到高薪 Offer 🎉🎉🎉
一、大模型(LLMs)基础面
💯 大模型(LLMs)架构篇
- 一、概念篇
-
💯 LLM架构对Transformer都有哪些优化?
-
- 二、组件篇
- 位置编码
-
💯 什么是正弦(Sinusoidal)位置编码?
-
💯 什么是旋转位置编码(RoPE)?
-
💯 RoPE相对正弦位置编码有哪些优势?
-
- 长度外推
-
💯 正弦编码是否真的具备外推性?
-
💯 RoPE如何进行外推?
-
💯 如何进行位置线性内插(Position Interpolation)?
-
💯 NTK-Aware Scaled RoPE 和位置线性内插的区别是什么?
-
💯 NTK-Aware Scaled RoPE 为何要对高频做外推,而对低频做内插?
-
- 注意力机制
-
💯 LLM为何使用GQA代替MHA?
-
💯 GQA如何平衡计算效率与模型性能?
-
💯 GQA与MQA(Multi-Query Attention)有何区别?各自适用场景是什么?
-
💯 GQA是否会影响模型对不同注意力模式的捕捉能力?如何缓解?
-
- PreNorm和PostNorm
-
💯 PreNorm和PostNorm有何不同?
-
💯 为什么PreNorm通常能提升训练稳定性?
-
💯 PostNorm在何种场景下可能优于PreNorm?
-
如何通过残差连接设计缓解PostNorm的优化问题?
-
- RMSNorm和LayerNorm
-
💯 为何使用 RMSNorm 代替 LayerNorm?
-
💯 RMSNorm与LayerNorm在数学公式上的核心区别是什么?
-
💯 RMSNorm可能带来哪些信息损失?如何补偿?
-
💯 RMSNorm是否适用于所有模态任务?
-
- 激活函数
-
💯 LLM使用SwiGLU相对于ReLU有什么好处?
-
💯 SwiGLU相比ReLU如何提升模型非线性表达能力?
-
💯 为什么SwiGLU在预训练任务中表现更佳?
-
💯 SwiGLU的参数量是否会显著增加?如何优化?
-
- 位置编码
💯 注意力机制(Attention)篇
- 一、概念篇
-
💯 什么是 Attention?
-
💯 为什么要引入 Attention 机制?
-
💯 如何计算 Attention?
-
- 二、变体篇
-
💯 Soft Attention 是什么?
-
💯 Hard Attention 是什么?
-
💯 Global Attention 是什么?
-
💯 Local Attention 是什么?
-
💯 Self-Attention 是什么?
-
💯 多查询注意力(Multi-Query Attention)是什么?
-
💯 分组查询注意力(Grouped Query Attention)是什么?
-
💯 分页注意力(Paged Attention)是什么?
-
💯 闪存注意力(Flash Attention)是什么?
-
💯 Transformer 理论篇
- 一、模型结构篇
-
💯 Transformer 整体结构是怎么样的?
-
💯 Transformer 编码器有哪些子层?
-
💯 Transformer 解码器有哪些子层?
-
- 二、核心机制篇
- 位置编码
-
💯 Transformer的输入中为什么要添加位置编码?
-
💯 什么是正弦(Sinusoidal)位置编码?
-
💯 Transformer的位置编码是如何计算的?
-
💯 Position encoding为什么选择相加而不是拼接呢?
-
- 多头注意力
-
💯 Self-Attention 是什么?
-
💯 多头注意力相对于单头注意力有什么优势?
-
💯 Transformer中自注意力模块的计算过程?
-
💯 什么是缩放点积注意力,为什么要除以 ?
-
- 残差连接
-
💯 Transformer为什么要使用残差连接?
-
💯 使用残差连接有哪些好处?
-
- 层归一化
-
💯 为什么要做归一化?
-
💯 Layer Normalization 是什么?
-
💯 Layer Normalization 有什么用?
-
💯 批归一化和层归一化的区别?
-
💯 Layer Normalization 有哪几个可训练参数?
-
- Mask 机制
-
💯 解码器中为什么要使用Mask?
-
💯 Transformer 中有几种 Mask?
-
💯 Padding Mask 是如何实现的?
-
💯 Sequence Mask 是如何实现的?
-
- 位置编码
- 三、问题优化篇
-
💯 LLM为何使用GQA代替MHA?
-
💯 LLM为何使用 PreNorm 代替 PostNorm?
-
💯 LLM为何使用 RMSNorm 代替 LayerNorm?
-
💯 LLM使用SwiGLU相对于ReLU有什么好处?
-
二、大模型微调面
💯 有监督微调(SFT)篇
- 一、概念篇
-
💯 从零训练一个大模型有哪几个核心步骤?
-
💯 为什么要对LLM做有监督微调(SFT)?
-
💯 如何将一个基础模型训练成一个行业模型?
-
- 二、数据篇
-
💯 如何准备SFT阶段的训练数据?
-
💯 alpaca 格式是这么样的?
-
💯 sharegpt 格式是什么样的?
-
💯 alpaca 格式和sharegpt 格式分别适合什么微调场景?
-
💯 如何自动生成指令构建SFT的训练数据?
-
💯 Self-instruct 数据生成步骤?
-
- 三、技巧篇
-
💯 什么是灾难性遗忘?
-
💯 LM做有监督微调(SFT)变傻了怎么办?
-
💯 如何避免灾难性遗忘?
-
- 四、对比篇
-
💯 有监督微调(SFT)和人工偏好对齐(RLHF)有何区别?
-
💯 有监督微调(SFT)适用于什么场景?
-
💯 人工偏好对齐(RLHF)适用于什么场景?
-
💯 高效微调篇
- 一、概念篇
-
💯 什么是微调?
-
💯 全量微调与参数高效微调的区别是什么?
-
💯 为什么需要对大模型进行高效微调?
-
💯 对大模型高效微调有哪些常用方法?
-
- 二、轻度微调
-
💯 什么是轻度微调?
-
💯 轻度微调有哪些常用方法?
-
💯 什么是BitFit微调?
-
💯 什么是分层微调?
-
💯 分层微调如何设置学习率?
-
- 三、适配器微调
-
💯 什么是适配器微调?
-
💯 适配器微调有哪些优势?
-
💯 讲一讲IA3微调?
-
- 四、提示学习(Prompting)
- 概念篇
-
💯 什么是提示学习(Prompting)?
-
💯 提示学习(Prompting) 代表方法有哪些?
-
- 前缀微调(Prefix-tuning)
-
💯 什么是前缀微调(Prefix-tining)?
-
💯 前缀微调(Prefix-tining)的优点是什么?
-
💯 前缀微调(Prefix-tining)的缺点是什么?
-
- 提示微调(Prompt-tuning)
-
💯 什么是提示微调(Prompt-tuning)?
-
💯 提示微调(Prompt-tuning)的核心思想?
-
💯 提示微调(Prompt-tuning)的 优点是什么?
-
💯 提示微调(Prompt-tuning)的 缺点是什么?
-
- P-tuning
-
💯 P-tuning 动机是什么?
-
💯 P-tuning v2 解决了什么问题?
-
💯 P-tuning v2 进行了哪些改进?
-
- 概念篇
- 五、指令微调
-
💯 为什么需要 指令微调(Instruct-tuning)?
-
💯 指令微调(Instruct-tuning)是什么?
-
💯 指令微调(Instruct-tuning)的优点是什么?
-
💯 指令微调(Instruct-tuning) 和 提示学习(Prompting)的区别是什么?
-
- 六、LoRa微调
-
💯 什么是LoRA微调?
-
💯 为什么在参数高效微调中使用低秩矩阵分解?
-
💯 详细说明LoRA的工作原理及其优势?
-
💯 LoRA微调时有哪些可配置的参数?
-
💯 在配置LoRA时,如何设置参数r和alpha?
-
💯 LoRA存在低秩瓶颈问题,ReLoRA和AdaLoRA分别通过哪些方法改进?
-
💯 动态秩分配(如AdaLoRA)如何根据层的重要性调整秩?正交性约束的作用是什么?
-
💯 AdapterFusion如何实现多任务学习?
-
💯 如何利用LoRAHub实现跨任务泛化?其组合阶段与适应阶段的具体流程是什么?
-
💯 提示学习篇
- 一、概念篇
-
💯 什么是提示学习(Prompting)?
-
💯 提示学习(Prompting) 代表方法有哪些?
-
- 二、方法篇
- 前缀微调(Prefix-tuning)
-
💯 什么是前缀微调(Prefix-tining)?
-
💯 前缀微调(Prefix-tining)的优点是什么?
-
💯 前缀微调(Prefix-tining)的缺点是什么?
-
- 提示微调(Prompt-tuning)
-
💯 什么是提示微调(Prompt-tuning)?
-
💯 提示微调(Prompt-tuning)的核心思想?
-
💯 提示微调(Prompt-tuning)的 优点是什么?
-
💯 提示微调(Prompt-tuning)的 缺点是什么?
-
- P-tuning
-
💯 P-tuning 动机是什么?
-
💯 P-tuning v2 解决了什么问题?
-
💯 P-tuning v2 进行了哪些改进?
-
- 前缀微调(Prefix-tuning)
- 三、对比篇
-
💯 提示微调(Prompt-tuning)与 Prefix-tuning 区别 是什么?
-
💯 提示微调(Prompt-tuning)与 fine-tuning 区别 是什么?
-
💯 人类对齐训练(RLHF)篇
- 一、概念篇
-
💯 从零训练一个大模型有哪几个核心步骤?
-
💯 从零训练大模型的三大阶段(Pretrain/SFT/RLHF)分别解决什么问题?
-
💯 什么是人类偏好对齐训练?
-
💯 为什么需要做人类偏好对齐训练?
-
💯 RLHF有哪几个核心流程?
-
💯 RLHF与SFT的本质区别是什么?为什么不能只用SFT?
-
💯 什么是人类偏好对齐中的"对齐税"(Alignment Tax)?如何缓解?
-
💯 RLHF的三大核心模块(奖励模型训练、策略优化、偏好数据收集)如何协同工作?
-
💯 为什么RLHF需要马尔可夫决策过程(MDP)建模?对话场景如何设计MDP五元组?
-
- 二、方法篇
- 强化学习和马尔可夫决策过程(MDP)
-
💯 马尔可夫决策过程的五元组是分别指什么?
-
💯 状态价值函数、优势价值函数、动作价值函数分别表示什么意思?
-
💯 在强化学习中,基于值函数的和基于策略的的优化方法有何区别?
-
💯 基于值函数的方法在处理连续动作空间问题时的优缺点分别是什么?
-
💯 基于策略的方法在处理连续动作空间问题时的优缺点分别是什么?
-
- PPO 算法
-
什么是近端策略优化(PPO)?
-
RLHF中的PPO主要分哪些步骤?
-
💯 PPO中的重要性采样(Importance Sampling)如何修正策略差异?
-
💯 Actor-Critic架构在RLHF中的双网络设计原理?
-
💯 KL散度在RLHF中的双重作用是什么?
-
PPO-Clip与PPO-Penalty的数学形式差异及适用场景?
-
- DPO 算法
-
💯 DPO如何通过隐式奖励建模规避强化学习阶段?
-
Bradley-Terry模型与DPO目标函数的关系推导
-
DPO vs PPO:训练效率与性能上限的对比分析
-
- 强化学习和马尔可夫决策过程(MDP)
- 三、实践篇
-
💯 RLHF训练数据的格式是什么样的?
-
💯 人类偏好数据收集的三大范式(人工标注/用户隐式反馈/AI生成对比)?
-
💯 如何选择人类偏好对齐训练还是SFT?
-
💯 如何选择人类偏好对齐训练算法?
-
💯 如何理解人类偏好对齐训练中的Reward指标?
-
💯 Reward Hack问题(奖励模型过拟合)的检测与缓解方案有哪些?
-
💯 Prompt 工程篇
- 一、概念篇
-
什么是Prompt工程?
-
为什么需要Prompt工程?
-
- 二、技巧篇
- Prompt设计要素
-
任务说明、上下文、问题和输出格式的作用是什么?
-
如何优化Prompt以提高模型性能?
-
如何规范编写Prompt?
-
- 上下文学习(In-Context Learning)
-
什么是上下文学习?
-
上下文学习三种形式(零样本、单样本、少样本)的区别?
-
如何选择有效的演示示例?
-
影响上下文学习性能的因素有哪些?
-
如何通过预训练数据分布和模型规模优化上下文学习效果?
-
为什么提示中示例的顺序和数量会影响模型性能?
-
- 思维链(Chain of Thought, CoT)
-
思维链(CoT)的核心思想是什么?
-
思维链(CoT)在解决哪些任务类型中效果显著?
-
思维链(CoT)有哪几种常见的模式?
-
按部就班(如 Zero-Shot CoT、Auto-CoT)、三思后行(如 ToT、GoT)、集思广益(如 Self-Consistency)三种 CoT 模式有何异同?
-
如何在不同任务中选择和应用CoT?
-
CoT如何提升模型在复杂推理任务中的表现?
-
为什么某些指令微调后的模型无需显式 CoT 提示?
-
- Prompt设计要素
- 三、对比篇
-
Prompt工程与传统微调的区别是什么?
-
三、大模型进阶面
💯 大模型压缩篇
- 一、动因篇
-
💯 为什么需要对大模型进行压缩和加速?
-
- 二、方法篇
- 低秩分解
-
💯 什么是低秩分解?
-
💯 什么是奇异值分解(SVD)?
-
- 权值共享
-
💯 什么是权值共享?
-
💯 权值共享为什么有效?
-
- 模型量化
-
💯 什么是模型量化?
-
💯 均匀量化和非均匀量化有什么区别?
-
💯 大模型训练后量化有什么优点?
-
💯 什么是混合精度分解?
-
- 知识蒸馏
-
💯 什么是蒸馏?
-
💯 什么是基于反馈的知识蒸馏?
-
💯 什么是基于特征的知识蒸馏?
-
💯 什么是蒸馏损失?
-
💯 什么是学生损失?
-
💯 模型蒸馏的损失函数是什么?
-
- 剪枝
-
💯 什么是剪枝?
-
💯 描述一下剪枝的基本步骤?
-
💯 结构化剪枝和非结构化剪枝有什么不同?
-
- 低秩分解
💯 分布式训练篇
- 一、动因篇
-
分布式训练主要解决大模型训练中的哪些问题?
-
- 二、数据并行
-
数据并行主要为了解决什么问题?
-
PS架构是如何进行梯度同步和更新的?
-
Ring-AllReduce是如何进行梯度同步和更新的?
-
PS架构和Ring-AllReduce架构有何不同?
-
- 三、模型并行和张量并行
-
模型并行主要为了解决什么问题?
-
什么是张量并行,如何使用集群计算超大矩阵?
-
基础的流水线并行存在什么问题?
-
讲一讲谷歌的GPipe算法?
-
讲一讲微软的PipeDream算法?
-
- 四、DeepSpeed ZeRO
-
如何计算大模型占用的显存?
-
ZeRO主要为了解决什么问题?
-
ZeRO1、ZeRO2、ZeRO3分别做了哪些优化?
-
用DeepSpeed进行训练时主要配置哪些参数?
-
💯 大模型魔改篇
- 一、概念篇
-
什么是模型编辑(Model Editing)?
-
模型编辑(Model Editing)核心目标是什么?
-
对比重新预训练和微调,模型编辑的优势和适用场景是什么?
-
如何用模型编辑修正大语言模型中的知识错误?
-
- 二、性质篇
-
模型编辑的五大性质(准确性、泛化性、可迁移性、局部性、高效性)分别是什么?
-
如何量化评估模型编辑的五大性质?
-
若模型编辑后泛化性较差,可能的原因是什么?如何优化?
-
模型编辑局部性如何避免“牵一发而动全身”的问题?
-
- 三、方法篇
- 外部拓展法
-
知识缓存法(如SERAC)的工作原理是什么?
-
知识缓存法中的门控单元和推理模块如何协作?
-
附加参数法(如T-Patcher)如何在不改变原始模型架构的情况下实现编辑?
-
知识缓存法和附加参数法的优缺点有何优缺点?
-
- 内部修改法
-
ROME方法如何通过因果跟踪实验定位知识存储位置?
-
阻断实验的作用是什么?
-
元学习法(如MEND)如何实现“学习如何编辑”?
-
元学习法的双层优化框架如何设计?
-
定位编辑法(如KN、ROME)如何通过修改全连接前馈层参数实现精准编辑?
-
- 外部拓展法
- 四、对比篇
-
SERAC、T-Patcher、ROME在准确性、泛化性、局部性上的表现有何差异?
-
为什么ROME的局部性表现优于T-Patcher?
-
四、NLP 任务实战面
💯 文本分类篇
- 一、概念篇
-
什么是文本分类?
-
- 二、方法篇
- 主题建模法
-
什么是主题建模任务?
-
主题建模有哪些常用方法?
-
TF-IDF 算法是做什么的?
-
TF-IDF 有什么优缺点?适合哪些文本分类任务?
-
- 传统分类法
-
讲一讲 FastText 的分类过程?
-
讲一讲 TextCNN 文本分类的过程?
-
如何基于基于预训练模型做文本分类?
-
- 检索匹配法
-
什么场景需要用检索的方式做文本分类?
-
如何用检索的方式做文本分类?
-
检索的方法 的 训练阶段 如何做?
-
检索的方法 的 预测阶段 如何做?
-
用检索的方式做文本分类有何优缺点?
-
- 大模型方法
-
如何用Prompt的方式做文本分类?
-
如何使用多提示学习提升文本分类效果?
-
使用LLM做文本分类任务为何需要做标签词映射(Verbalizer)?
-
- 主题建模法
- 三、进阶篇
-
文本分类任务中有哪些难点?
-
如何解决样本不均衡的问题?
-
如何冷启动文本分类项目?
-
如果类别会变化如何设计文本分类架构?
-
短文本如何进行分类?
-
长文本如何进行分类?
-
💯 命名实体识别(NER)篇
- 一、概念篇
-
什么是实体识别?
-
实体识别有哪些常用的解码方式?
-
NER的常用评价指标(精确率、召回率、F1)有何局限性?
-
预训练模型(如BERT,LLM)如何改变传统NER的范式?
-
- 二、方法篇
- 传统方法
-
如何用序列标注方法做NER任务?
-
什么是 CRF?
-
CRF为什么比Softmax更适合NER?
-
如何使用指针标注方式做NER任务?
-
如何使用多头标注方式做NER任务?
-
如何使用片段排列方式做NER任务?
-
- 大模型方法
-
如何将NER建模为生成任务(例如使用T5、GPT)?
-
大模型做NER任务的解码策略有何不同?
-
如何设计模板提升NER任务少样本效果?
-
- 对比篇
-
序列标注方法有何优缺点?
-
指针标注、多头标注和片段排列有何优缺点,分别适用于哪些场景?
-
大模型方法和传统方法做NER任务分别有什么优缺点?
-
- 传统方法
- 三、标注篇
-
实体识别的数据是如何进行标注的?
-
BIO、BIOES、IOB2标注方案的区别与优缺点?
-
- 四、问题篇
-
实体识别中有哪些难点?
-
什么是实体嵌套?
-
如何解决实体嵌套问题?
-
如何解决超长实体识别问题?
-
NER实体span过长怎么办?
-
如何解决 NER 标注数据噪声问题?
-
如何解决 NER 标注数据不均衡问题?
-
💯 关系抽取篇
- 一、概念篇
-
什么是关系抽取?
-
常见关系抽取流程的步骤是怎样的?
-
- 二、句子级关系抽取篇
-
什么是模板匹配方法?
-
模板匹配方法的优点是什么?
-
模板匹配方法存在哪些局限性或缺点呢?
-
什么是关系重叠问题?
-
什么是复杂关系问题?
-
什么是联合抽取?
-
介绍下基于共享参数的联合抽取方法?
-
介绍下基于联合解码的联合抽取方法?
-
关系抽取的端到端方法和流水线方法各有什么优缺点?
-
- 三、文档级关系抽取篇
-
文档级关系抽取与单句关系抽取有何区别?
-
在进行跨句子甚至跨段落的关系抽取时,会遇到哪些特有的挑战?
-
文档级关系抽取的方法有哪些?
-
文档级关系抽取常见数据集有哪些以及其评估方法?
-
💯 检索增强生成(RAG)篇
- 一、动因篇
-
为什么要做RAG系统?
-
RAG和大模型微调的区别?
-
RAG和大模型微调分别适用于什么场景?
-
讲一下RAG的总体流程?
-
- 二、流程篇
- Query 理解
-
用户理解阶段一般会做哪些处理?有何作用?
-
用户问题总是召回不准确,在用户理解阶段可以做哪些优化?
-
- Index 构建
-
问答对问答中,如何构建索引,提升对用户问题的泛化能力?
-
文档问答中,如何构建索引,提升对用户问题的泛化能力?
-
问题经常命中不到文本块,如何在索引阶段做优化?
-
- Retrieval 召回
-
多路检索如何实现?
-
如何合并多路检索的结果,对它们做排序?
-
BM25检索器总是召回无关的知识,最可能的原因是什么?
-
如何借助其他用户的使用情况,提升总体的检索性能?
-
- Reranker 精排
-
为何要对检索的结果做精排(重排)?
-
如何构建重排序模型的微调数据?
-
- Query 理解
五、NLP 基础面
💯 分词(Tokenizer)篇
-
💯 如何处理超出词表的单词(OVV)?
-
💯 BPE 分词器是如何训练的?
-
💯 WordPiece 分词器是如何训练的?
-
💯 Unigram 分词器是如何训练的?
💯 词嵌入(Word2Vec)篇
- 一、动因篇
-
💯 什么是词向量化技术?
-
💯 如何让向量具有语义信息?
-
- 二、基于统计的方法
-
💯 如何基于计数的方法表示文本?
-
💯 上下文中的窗口大小是什么意思?
-
💯 如何统计语料的共现矩阵?
-
💯 基于计数的表示方法存在哪些问题?
-
- 三、基于推理的方法
-
💯 Word2Vec的两种模型分别是什么?
-
💯 Word2Vec 中 CBOW 指什么?
-
💯 Word2Vec 中 Skip-gram 指什么?
-
💯 CBOW 和 Skip-gram 哪个模型的词嵌入更好?
-
- 四、问题优化篇
-
💯 Word2Vec训练中存在什么问题?
- 💯 Word2Vec如何优化从中间层到输出层的计算?
-
用负采样优化中间层到输出层的计算
-
负采样方法的关键思想
-
负采样的采样方法
-
-
💯 为什么说Word2vec的词向量是静态的?
-
💯 Word2vec的词向量存在哪些问题?
-
💯 卷积神经网络(CNN)篇
- 一、动因篇
-
💯 卷积,池化的意义
-
- 二、模型篇
-
💯 为什么卷积核设计尺寸都是奇数
-
💯 卷积操作的特点
-
💯 为什么需要 Padding ?
-
💯 卷积中不同零填充的影响?
-
💯 1 1 卷积的作用?
-
💯 卷积核是否越大越好?
-
💯 CNN 特点
-
💯 为何较大的batch size 能够提高 CNN 的泛化能力?
-
💯 如何减少卷积层参数量?
-
- 三、对比篇
-
💯 SAME 与 VALID 的区别
-
💯 CNN 优缺点
-
💯 你觉得 CNN 有什么不足?
-
💯 CNN 与 RNN 的优劣
-
💯 循环神经网络(RNN)篇
- 一、RNN 概念篇
-
💯 RNN的作用是什么?
-
- 二、RNN 模型篇
-
💯 RNN的输入输出分别是什么?
-
💯 RNN是如何进行参数学习(反向传播)的?
-
💯 Relu 能否作为RNN的激活函数
-
- 三、RNN 优化篇
-
💯 RNN不能很好学习长期依赖的原因是什么?
-
💯 RNN 中为何会出现梯度消失,梯度爆炸问题?
-
💯 为何 RNN 训练时 loss 波动很大
-
💯 计算资源有限的情况下有没有什么优化方法?
-
💯 推导一下 GRU
-
- 四、RNN 对比篇
-
💯 LSTM 相对 RNN 的主要改进有哪些?
-
💯 LSTM 与 GRU 之间的关系
-
💯 LSTM 与 GRU 区别
-
💯 长短期记忆网络(LSTM)篇
- 一、动因篇
-
💯 RNN 梯度消失的原因?
-
💯 LSTM 如何缓解 RNN 梯度消失的问题?
-
💯 LSTM不会发生梯度消失的原因
-
- 二、模型篇
-
💯 LSTM 相对 RNN 的主要改进有哪些?
-
💯 门机制的作用
-
💯 LSTM的网络结构是什么样的?
-
💯 LSTM中记忆单元的作用是什么?
-
💯 LSTM中的tanh和sigmoid分别用在什么地方?
-
💯 LSTM有几个门,分别起什么作用?
-
💯 LSTM 单元是如何进行前向计算的?
-
💯 LSTM的前向计算如何进行加速?
-
💯 LSTM 单元是如何进行反向传播的?
-
- 三、应用篇
-
💯 LSTM在实际应用中的提升技巧有哪些?
-
为何多层LSTM叠加可以提升模型效果?
-
双向LSTM为何更有效?
-
LSTM中如何添加Dropout层?
-
💯 BERT 模型篇
- 一、动因概念篇
-
Bert 是什么?
-
为什么说BERT是双向的编码语言模型?
-
BERT 是如何区分一词多义的?
-
BERT为什么如此有效?
-
BERT存在哪些优缺点?
-
- 二、BERT 架构篇
-
BERT 是如何进行预训练的?
-
BERT的输入包含哪几种嵌入?
-
什么是分段嵌入?
-
BERT的三个Embedding直接相加会对语义有影响吗?
-
讲一下BERT的WordPiece分词器的原理?
-
为什么BERT在第一句前会加一个【CLS】标志?
-
BERT-base 模型和 BERT-large 模型之间有什么区别?
-
使用BERT预训练模型为什么最多只能输入512个词?
-
BERT模型输入长度超过512如何解决?
-
- BERT 训练篇
- Masked LM 任务
-
BERT 为什么需要预训练任务 Masked LM ?
-
掩码语言模型是如何实现的?
-
为什么要采取Masked LM,而不直接应用Transformer Encoder?
-
Bert 预训练任务 Masked LM 存在问题?
-
什么是 80-10-10 规则,它解决了什么问题?
-
bert为什么并不总是用实际的 masked token替换被“masked”的词汇?
-
为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
-
- Next Sentence Prediction 任务
-
Bert 为什么需要预训练任务 Next Sentence Prediction ?
-
下句预测任务是如何实现的?
-
- Masked LM 任务
- BERT 微调篇
-
对 Bert 做 fine-turning 有什么优势?
-
Bert 如何针对不同类型的任务进行 fine-turning?
-
- 对比篇
-
BERT 嵌入与 Word2Vec 嵌入有何不同?
-
elmo、GPT和bert在单双向语言模型处理上的不同之处?
-
word2vec 为什么解决不了多义词问题?
-
为什么 elmo、GPT、Bert能够解决多义词问题?
-
💯 BERT 变体篇
- 一、BERT变体篇
-
句序预测任务与下句预测任务有什么不同?
-
ALBERT 使用的参数缩减技术是什么?
-
什么是跨层参数共享?
-
RoBERTa 与 BERT 有什么不同?
-
在 ELECTRA 中,什么是替换标记检测任务?
-
如何在 SpanBERT 中掩盖标记?
-
Transformer-XL怎么实现对长文本建模?
-
- 二、问题优化篇
-
针对BERT原生模型的缺点,后续的BERT系列模型是如何改进【生成任务】的?
-
针对BERT原生模型的缺点,后续的BERT系列模型是如何引入【知识】的?
-
针对BERT原生模型的缺点,后续的BERT系列模型是如何引入【多任务学习机制】的?
-
针对BERT原生模型的缺点,后续的BERT系列模型是如何改进【mask策略】的?
-
针对BERT原生模型的缺点,后续的BERT系列模型是如何进行【精细调参】的?
-
💯 BERT 实战篇
- 一、场景篇
-
BERT擅长处理哪些下游NLP任务?
-
BERT为什么不适用于自然语言生成任务(NLG)?
-
如何使用预训练的 BERT 模型?
-
在问答任务中,如何计算答案的起始索引?
-
在问答任务中,如何计算答案的结束索引?
-
如何将 BERT 应用于命名实体识别任务?
-
- 二、微调篇
-
什么是微调?
-
什么是继续预训练?
-
如何进行继续预训练?
-
- 三、问题篇
-
什么是 Bert 未登录词?
-
Bert 未登录词如何处理?
-
Bert 未登录词各种处理方法有哪些优缺点?
-
BERT在输入层如何引入额外特征?
-
六、深度学习面
💯 激活函数篇
- 一、动因篇
-
💯 为什么需要激活函数
-
💯 为什么激活函数需要非线性函数?
-
- 二、方法篇
- sigmoid
-
💯 什么是 sigmoid 函数?
-
💯 为什么选 sigmoid 函数 作为激活函数?
-
💯 sigmoid 函数有什么缺点?
-
- tanh
-
💯 什么是 tanh 函数?
-
💯 为什么选 tanh 函数作为激活函数?
-
💯 tanh 函数作为激活函数有什么缺点?
-
- relu
-
💯 什么是 relu 函数?
-
💯 为什么选 relu 函数作为激活函数?
-
💯 relu 函数有什么缺点?
-
💯 为什么tanh收敛速度比sigmoid快?
-
- sigmoid
💯 优化器篇
- 一、动因篇
-
💯 梯度下降法的思想是什么?
-
- 二、方法篇
-
💯 SGD是如何实现的?
-
💯 SGD有什么缺点?
-
💯 Momentum 是什么?
-
💯 Adagrad 是什么?
-
💯 RMSProp是什么?
-
💯 Adam 是什么?
-
- 三、对比篇
-
💯 批量梯度下降(BGD)、随机梯度下降(SGD)与小批量随机梯度下降(Mini-Batch GD)的区别?
-
💯 正则化篇
- 一、动因篇
-
💯 为什么要正则化?
-
💯 权重衰减的目的?
-
- 二、 正则化篇
-
💯 什么是 L1 正则化?
-
💯 什么是 L2 正则化?
-
💯 L1 与 L2 的异同
-
💯 为什么 L1 正则化 可以产生稀疏值,而 L2 不会?
-
💯 为何只对权重进行正则惩罚,而不针对偏置?
-
💯 为何 L1 和 L2 正则化可以防止过拟合?
-
- 三、Dropout 篇
-
💯 什么是Dropout?
-
💯 为什么Dropout可以解决过拟合问题?
-
💯 Dropout 在训练和测试阶段的区别是什么?
-
💯 Dropout 的变体有哪些?
-
💯 如何选择合适的 Dropout 率?
-
💯 Dropout 和其他正则化方法(如 L1、L2 正则化)有何不同?
-
💯 归一化篇
- 一、动因篇
-
💯 为什么要做归一化?
-
💯 为什么归一化能提高求最优解速度?
-
- 二、方法篇
-
💯 主流的归一化有哪些方法?
- Batch Normalization
-
💯 Batch Normalization 是什么?
-
💯 Batch Normalization 的有点有哪些?
-
💯 BatchNorm 存在什么问题?
-
- Layer Normalization
-
💯 Layer Normalization 是什么?
-
💯 Layer Normalization 有什么用?
-
-
- 三、对比篇
-
💯 批归一化和组归一化的比较?
-
💯 批归一化和权重归一化的比较?
-
💯 批归一化和层归一化的比较?
-
💯 参数初始化篇
- 一、概念篇
-
💯 什么是内部协变量偏移?
-
💯 神经网络参数初始化的目的?
-
💯 为什么不能将所有神经网络参数初始化为0?
-
- 二、方法篇
-
💯 什么是Xavier初始化?
-
💯 什么是He初始化?
-
💯 过拟合篇
-
💯 过拟合与欠拟合的区别是什么?
-
💯 解决欠拟合的方法有哪些?
-
💯 防止过拟合的方法主要有哪些?
-
💯 什么是Dropout?
-
💯 为什么Dropout可以解决过拟合问题?
💯 集成学习篇
- 一、概念篇
-
集成学习的核心思想是什么?
-
集成学习与传统单一模型相比有哪些本质区别?
-
从偏差-方差分解的角度,解释集成学习为什么能提升模型性能?
-
集成学习有效性需要满足哪些前提条件?
-
- 二、Boosting 篇
-
解释一下 Boosting 的迭代优化过程
-
Boosting 的基本思想是什么?
-
Boosting 如何通过残差拟合实现误差修正?
-
GBDT 是什么?
-
XGBoost 是什么?
-
GBDT与 XGBoost 的核心差异是什么?
-
为什么XGBoost要引入二阶泰勒展开?对模型性能有何影响?
-
- 三、Bagging 篇
-
什么是 Bagging?
-
Bagging 的基本思想是什么?
-
Bagging的并行训练机制如何提升模型稳定性?
-
随机森林 是什么?
-
随机森林与孤立森林的本质区别是什么?
-
对比Bagging与Dropout在神经网络中的异同?
-
- 四、Stacking 篇
-
什么是 Stacking ?
-
Stacking 的基本思路是什么?
-
Stacking中为什么要用K折预测生成元特征?
-
如何避免Stacking中信息泄露问题?
-
- 五、对比篇
-
对比Boosting/Bagging/Stacking三大范式的核心差异(目标、训练方式、基学习器关系)?
-
集成学习中基学习器的"稳定性"如何影响算法选择?
-
Boosting、Bagging 与 偏差、方差的关系?
-
为什么Bagging常用高方差模型?
-
💯 评估指标篇
- 一、概念篇
-
💯 混淆矩阵有何作用?
-
💯 分类任务中有哪几个常规的指标?
-
- 二、F1-Score 篇
-
💯 什么是 F1-Score?
-
💯 对于多分类问题来说, F1 的计算有哪些计算方式?
-
💯 什么是 Macro F1?
-
💯 什么是 Micro F1?
-
💯 什么是 Weight F1?
-
- 三、对比篇
-
💯 Macro 和 Micro 有什么区别?
-
💯 什么是马修斯相关系数(MCC)?
-
- 四、曲线篇
-
💯 ROC 曲线主要有什么作用?
-
💯 什么是 AUC(Area under Curve)?
-
💯 P-R 曲线有何作用?
-


















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









