






论文链接:论文
论文简介
这是一篇ICCV2021的文章,主要针对Long-Tail Visual Relationship Recognition(LTVRR)问题做出解决,这个框架旨在提升Long-Tail视觉关系识别。与常规的Long-Tail问题不同,在LTVRR中,object、subject、relationship都有着大量的例子,论文针对的是很少出现的关系(也就是罕见的(object,relationship,subject)三元组),例如:

论文主要贡献有三点:
①、将Long-tail分类任务中的几种最先进的方法应用到设置之中
②、提出一种新的增强方法RelMix,并将其应用于视觉任务中,使得在学习时能更加关注到尾部类
③、将视觉长尾问题作为一个hubness问题,并引入一个Visio-linguistic的hubness损失
论文笔记
①、论文框架

将从同一幅图像中提取的s-r-o三联体通过视觉嵌入网络,通过结合主题、对象和关系的特征对结果嵌入进行增强。然后使用ViLub Loss和RelMix增强对训练进行正则化。
②、其中,关于<s,r,o>的嵌入xs,xr,xo分别定义如下: 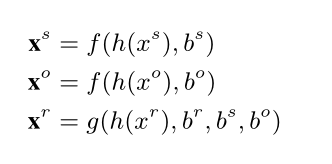
其实还是一个利用多线索的公式,直接将空间线索也集合到对应关系的embedding中。h(θ)是VGG16的前五层, f (θ) 和 g(θ)是提取visual embedding的神经网络。
③、论文的loss值主要由两部分组成,Per-example Loss和VilHub Per-minibatch Loss
Per-example Loss 就是传统的 triplet loss, triplet loss鼓励配对模式的匹配嵌入比不匹配模式更接近m。

其中,N是正的ROI区域数目。
VilHub Per-minibatch Loss说的是跨语言的准确性通常会因为hubness的现象而显著降低,是说当一些频繁出现的词难以区分的接近许多其他出现较少的词。在长尾问题中,这些频繁出现的词会以牺牲不常见的类别为代价被过度优化。为了缓解这种现象,论文通过端对端的学习纠正语言和视觉表示。这个损失的实质是对当前batch的头类和尾类进行公平预测。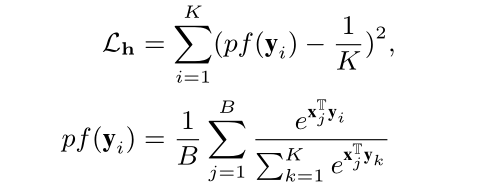
④、 RelMix Augmentation
假设输入图像x中存在主体s,客体o,主客体之间存在关系r,记这些提取过的特征为xs,xo,xr,记真实标签为ys,yo,yr,这一模块通过系统地结合使用这些特征来训练增强数据。
RelMix augmentation的目标是通过有意义的的方式结合提取的视觉特征来丰富视觉关系标签的训练覆盖。这一部分在训练时,选择三组三元组作为训练数据,其中两组来自中高频域,一组来自因此低频域,最终采样的x,y定义如下:
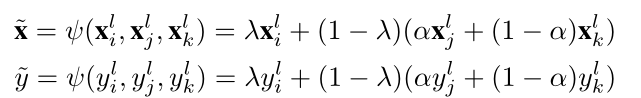
其中xi,xj来自于中高频率,xk来自于低频率,α服从概率为0.5的伯努利分布,λ服从[0,1]的均匀分布,这允许了方法更关注尾部类。
⑤、Result
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









