






 本文详细解析了Kaldi框架中声纹识别的全流程,包括数据准备、特征提取、UBM模型训练、i-vector提取、PLDA建模及打分等关键步骤。
本文详细解析了Kaldi框架中声纹识别的全流程,包括数据准备、特征提取、UBM模型训练、i-vector提取、PLDA建模及打分等关键步骤。
前言
因为科研项目需要用到声纹识别,有小伙伴说先跑通kaldi中的aishell v1,就能对声纹识别有一个大致的了解,本小白在Linux和C++基础薄弱的情况下,边看其中的run.sh以及其引用的脚本,再加上其他小伙伴的总结和相关理论知识,用两个月时间理清了整个流程(战线有点长,但其实还有很多细节不明白,都怪C++看不懂,一定恶补!!!),在这里记录一下自己的学习过程,欢迎各位走过路过的大神批评指正。
1 下载和解压数据
1.1 代码&详解
15 data=/export/a05/xna/data #创建存放数据的目录,在这一步我直接用data=data代替了一层层的目录,也不知道原作者为什么要把数据藏的这么深。
16 data_url=www.openslr.org/resources/33 #这是aishell 数据包的地址,下载比较慢,我记得是有镜像文件,我是直接在windows下用镜像地址下载后拷贝到data目录下的,共有两个文件:data_aishell.tgz和resource_aishell.tgz 分别是语音数据和字典,在声纹识别中用不到后者。
18 . ./cmd.sh #多线程并行
19 . ./path.sh #配置环境变量,方便可执行文件的调用
20
21 set -e # exit on error #若有错误则退出
22
1.2 生成文件
**【注】**解压缩的脚本文件有点问题,所以一直出现找不到文件的情况,在稍作修改之后解压缩成功了,其中wav中一共是400个人,分为dev (开发集,用于优化模型)40人 train训练集340人,test测试集20人,每个人说话的语音条数不一样,大致都为300多条。
2 数据准备
2.1 代码
26 # Data Preparation
27 local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript
2.2 详解
数据准备脚本的细节我直接省略了,大致过程就是在data/local下创建dev test train三个文件夹,然后把语音所需要的各个数据都存放在这三个文件夹中作为中间数据,然后创建data/test data/train 两个文件夹,把data/local下的数据复制到这两个文件夹中。
2.3 生成文件
其实我们只需要知道,最终这个语句做的事情就是在data/test和data/train中生成了以下文件:spk2utt text utt2spk wav.scp
spk2utt和utt2spk 是两个表格,可以用vi打开,格式如下:
spk2utt <说话人编号> <语音编号>
utt2spk <语音编号> <说话人标号>
text <语音编号> <对应文字>
wav.scp<语音编号> <对应地址>
3 特征提取
3.1 代码
29 # Now make MFCC features.
30 # mfccdir should be some place with a largish disk where you
31 # want to store MFCC features.
32 mfccdir=mfcc
33 for x in train test; do
34 steps/make_mfcc.sh --cmd "$train_cmd" --nj 10 data/$x exp/make_mfcc/$x $mfccdir
35 sid/compute_vad_decision.sh --nj 10 --cmd "$train_cmd" data/$x exp/make_mfcc/$x $ mfccdir
36 utils/fix_data_dir.sh data/$x
3.2 详解
特征提取有两步:
第一步是steps/make_mfcc.sh提取mfcc特征,生成log文件放入exp/make_mfcc 的test和train中,特征向量放入v1/mfcc中,有ark文件和scp文件,其中ark文件是真实的向量,scp文件是向量的地址。用命令copy-feats --binary=false ark:raw_mfcc_test_1.ark ark,t:raw_mfcc_test_1.ark.txt 生成txt文件,然后可用vi查看。
【注】
1、在make_mfcc.sh脚本中对特征提取进行了一些配置,配置文件为conf/mfcc.conf
–sample-frequency=16000 #采样频率为16khz
–num-mel-bins=40 #取40个mel滤波器组,一般默认为23个
–num-ceps=20 #取前20个倒谱系数作为MFCC特征,比一般的12个系数多
2、 在选项参数中,–nj=10,即将数据分成10组并行计算,因此生成了10个:raw_mfcc_test_x.ark/scp
x=1,2…10,train数据同理,最后,需要将他们合并到同一个表格中。
第二步是vad,即去掉语音中的静音部分,这里的vad和一般的能量阈值法不同,是直接将MFCC的第一维来作为能量,然后带入阈值的计算公式,还有一个滑窗的过程,取检测帧前后的若干帧,每一帧都判断一下是否大于阈值,若这些帧大于阈值的数量超过60%,就认为该帧有语音输出,即在vad中输出为1,否则为0.
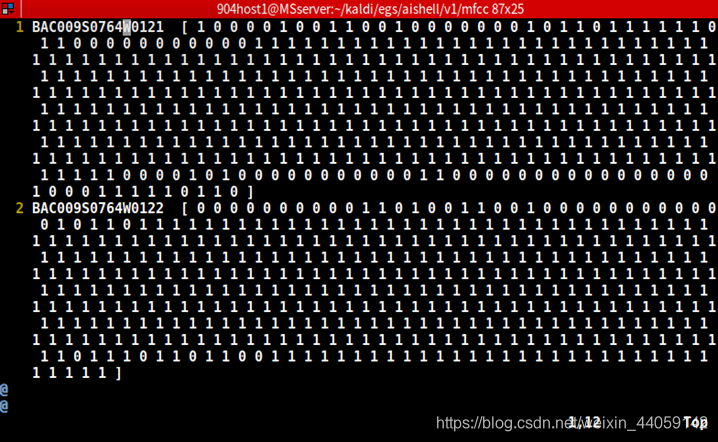
生成的vad存放在mfcc中,用copy-vector 打开查看,上图是vad的输出形式。
3.3 生成文件
(1)中间文件
exp/make_mfcc/exp/make_mfcc/test /make_mfcc_test_x.log
exp/make_mfcc/exp/make_mfcc/test/ vad_test.x.log
mfcc/raw_mfcc_test.x.scp
mfcc/raw_mfcc_test.x.ark #由0,1拼接而成的向量,每一列代表一帧
mfcc/vad_test.x.scp
mfcc/vad_test.x.ark
(train数据同理)
(2)最终生成文件:
data/train,test/feats.scp < 语音编号> <特征对应的地址>
utt2num_frames <语音编号> <对应的帧数>
frame_shift 帧移,10ms
vad.scp <语音编号> <对应的vad地址>
feats.scp <语音编号> <对应的mfcc地址>
utt2dur <语音编号> <语音时长>
4 UBM模型训练
4.1 代码
39 # train diag ubm
40 sid/train_diag_ubm.sh --nj 10 --cmd "$train_cmd" --num-threads 16 \
41 data/train 1024 exp/diag_ubm_1024
42
43 #train full ubm
44 sid/train_full_ubm.sh --nj 10 --cmd "$train_cmd" data/train \
45 exp/diag_ubm_1024 exp/full_ubm_1024
4.2 详解
UBM模型训练分为两步,第一步是训练对角协方差矩阵,第二步是训练协方差全矩阵,具体原因请看UBM的推导论文:Speaker Verification Using Adapted Gaussian Mixture Models
在训练过程中还对特征作了进一步处理:
add-deltas #对原来的MFCC进行了一阶差分和二阶差分,因而后面所见到的模型都以60维mfcc为基础。
apply-cmvn-sliding # 进行倒谱均值方差归一化,该归一化通常是为了获得基于说话人或者基于说话语句的零均值,单位方差归一化特征倒谱,用于改善噪声。
select-voiced-frames #依据vad和feast选择出有语音输出的帧进行模型训练。
4.3 生成文件
第一步产生文件:exp/diag_ubm_1024/final.dubm,转换成文本:gmm-global-copy –binary=false final.dubm final_dubm.txt
第二步产生文件: exp/diag_ubm_1024/final.ubm,转换成文本:fgmm-global-copy –binary=false final.ubm final_ubm.txt
final.dubm文件内容:
GCONSTS 这个值为一个1024维向量,是便于计算用的常量
WEIGHT 权重
INV_VARS 方差矩阵的逆矩阵
MEANS_INVVARS : 均值向量的转置*方差矩阵的逆矩阵
final.ubm文件内容和上一个相同,其中INV_VARS为1024个60×60的下三角矩阵
5 训练ivector
5.1 代码
#train ivector
48 sid/train_ivector_extractor.sh --cmd "$train_cmd --mem 10G" \
49 --num-iters 5 exp/full_ubm_1024/final.ubm data/train \
50 exp/extractor_1024
5.2 详解
训练ivector实际是训练T矩阵的过程,其整体流程如下:
(1) 由final.ubm得到final.dubm
(2) 用final.ubm初始化ivector,即T矩阵
(3) final.dubm选择前20个高斯分量,并输出后验概率
(4) 迭代更新5次,得到最终的T矩阵
5.3 生成文件
exp/extractor_1024/final.ie
转成文本;格式:ivector-extractor-copy –binary=false final.ie final_ie.txt
文件内容:
w_vec #ubm高斯分量的权重
M_2014 #T矩阵,1024·60400维矩阵
SigmaInv #ubm的协方差矩阵 1024个6060的下三角矩阵
【注 】其实我并不知道这里面的ubm是如何使用的,感觉两个UBM都用到了,生成的参数中的SigmaInv不知道是哪里来的,如果有人知道的话烦请解释一下。
6 提取ivector
6.1 代码
52 #extract ivector
53 sid/extract_ivectors.sh --cmd "$train_cmd" --nj 10 \
54 exp/extractor_1024 data/train exp/ivector_train_1024
6.2 详解
这一步才是真正的提取i-vector,将训练好的T矩阵带入计算公式,从而获得每句话的ivector。
介绍extract_ivectors.sh中的几个可执行文件。
gmm-gselect 本实验中一共采用了1024个高斯,在计算充分统计量时需要用到类条件概率,但实际上有前若干个类条件概率较大的高斯就能描述该帧的概率分布情况,这里取了前30个。
fgmm-global-gselect-to-post #选定了30个高斯之后输出每一帧的后验概率
ivector-extract #提取每句话的ivector, 生成ivector.JOB.scp JOB根据自己的电脑配置来设置。
ivector-normalize-length #对每一句话的ivector进行正则化处理
ivector-mean #在ivector的理论中,假设每句话代表一个说话人,所以最后要对同一说话人的不同语音进行i-vector平均化,从而得到每个人的ivector.最后再进行一次对每个人的ivetor的正则化处理
6.3 生成文件
exp/ivector_train_1024/ivector.scp #每句话的ivector
exp/ivector_train_1024/num_utts.ark #
exp/ivector_train_1024/spk_ivector.ark/ scp# 每个人的ivector
7 训练PLDA
7.1 代码
#train plda
57 $train_cmd exp/ivector_train_1024/log/plda.log \
58 ivector-compute-plda ark:data/train/spk2utt \
59 'ark:ivector-normalize-length scp:exp/ivector_train_1024/ivector.scp ark:- |' \
60 exp/ivector_train_1024/plda
7.2 详解
Ivector是全局差异因子,同时包含了说话人之间的差异和信道差异,于是我们用PLDA来做一个优化处理,剥离掉其中的信道差异。使用PLDA来作一个映射,将每一帧的PLDA是一个生成式模型,用EM算法来估计参数,我们定义第 i 个人的第 j 语音为 其模型的生成式可表示为:
其中,μ 表示全体训练数据的均值;
F 可以看做是身份空间,包含了可以用来表示各种说话人的信息;
hi 就可以看做是具体的一个说话人的身份(或者是说话人在身份空间中的位置);
G 可以看做是误差空间,包含了可以用来表示同一说话人不同语音变化的信息;
wij 表示的是在G空间中的位置;
ϵij 是最后的残留噪声项,用来表示尚未解释的东西。
该项为零均高斯分布,方差为Σ。
这个过程就是训练F、Σ并计算μ。
7.3 生成文件
exp/ivector_train_1024/plda
将文件转换成文本格式:ivector-copy-plda –-binary=false plda plda.txt
文件内容:
(1) 所有语音i-vector的均值 400维向量
(2) 说话人差异矩阵F 400*400维矩阵
(3) 协方差对角阵Σ 400维向量形式
8 划分测试集并提取特征
8.1 代码
#split the test to enroll and eval
63 mkdir -p data/test/enroll data/test/eval
64 cp data/test/{spk2utt,feats.scp,vad.scp} data/test/enroll
65 cp data/test/{spk2utt,feats.scp,vad.scp} data/test/eval
66 local/split_data_enroll_eval.py data/test/utt2spk data/test/enroll/utt2spk d ata/test/eval/utt2spk
67 trials=data/test/aishell_speaker_ver.lst
68 local/produce_trials.py data/test/eval/utt2spk $trials
69 utils/fix_data_dir.sh data/test/enroll
70 utils/fix_data_dir.sh data/test/eval
71
72 #extract enroll ivector
73 sid/extract_ivectors.sh --cmd "$train_cmd" --nj 10 \
74 exp/extractor_1024 data/test/enroll exp/ivector_enroll_1024
75 #extract eval ivector
76 sid/extract_ivectors.sh --cmd "$train_cmd" --nj 10 \
77 exp/extractor_1024 data/test/eval exp/ivector_eval_102
8.2 详解
将测试集test中的语音分成enroll(注册集)和eval(评估集),其中注册集是20个人中每个人随机抽3句话,这个可以在底层的c++中修改注册集的语音条数,其余的放入评估集。这里有一个trails变量,最终用于生成文件aishell_speaker_ver.lst,用vi打开查看,在上一步的没人随机抽取三句话作为注册语音的过程中,对每个人的语音文件进行了打乱,因此在生成的文件中顺序是随机的。每一句话都重新和每个说话人进行匹配,匹配正确则为target,否则为notarget,以此来文件中模拟所有可能的识别结果。文件内容如图所示:
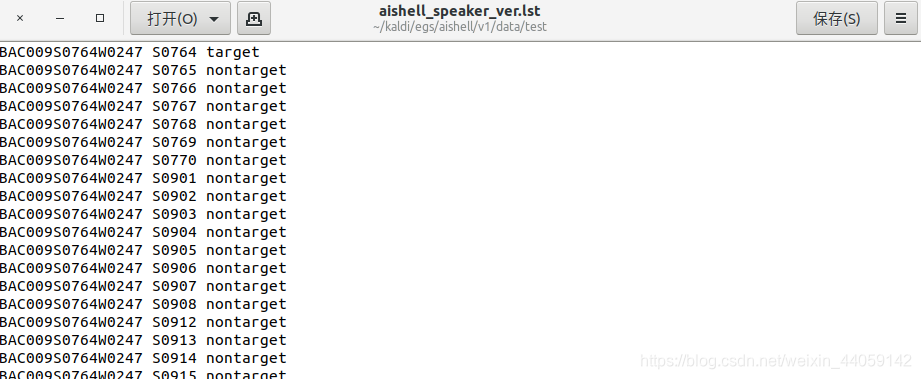
这个文件用于后续的PLDA打分,最后,分别提取enroll和eval的句子ivector和说话人ivector.
9 PLDA打分
9.1 代码
79 #compute plda score
80 $train_cmd exp/ivector_eval_1024/log/plda_score.log \
81 ivector-plda-scoring --num-utts=ark:exp/ivector_enroll_1024/num_utts.ark \
82 exp/ivector_train_1024/plda \
83 ark:exp/ivector_enroll_1024/spk_ivector.ark \
84 "ark:ivector-normalize-length scp:exp/ivector_eval_1024/ivector.scp ark:- |" \
85 "cat '$trials' | awk '{print \\\$2, \\\$1}' |" exp/trials_out
9.2 详解
这个过程的可执行文件为ivector-plda-scoring,我们看它的参数,选项部分是语音的数量,参数输入部分,第一个是plda模型,第二个是注册集中每个人的ivector,第三个是经过归一化处理的评估集中每条语音的ivector,第四个参数则是分数存储的文件。
具体的打分过程是:程序首先读取输入的注册集和测试集文件,然后按行读取trials的内容,比如说上述trials文件的第一行,以<注册集说话人id> <测试语音id> 的方式读取,(egs:S0764,BAC009S0764207)然后分别去两个输入文件中寻找对应的i-vector,计算PLDA得分,将<注册集说话人id> <测试语音id><得分> 写入到trials_out中
将二者带入PLDA的公式中,则可计算出得分。最后输出到trials_out中,格式为<语音><说话人><匹配得分>。
10 计算等错误率EER
10.1 代码
87 #compute eer
88 awk ‘{print $3}’ exp/trials_out | paste - $trials | awk ‘{print $1, $4}’ | compute-eer -
10.2 详解
将trials_out的第三列数据(即得分)复制到aishell_speaker_ver.lst中的首列,再提取出其中的第一个和第四个数据,即<分数> <判定结果>,将targe和nontarget的分数分开,并分别按从小到大的顺序排列,target数据从左到右遍历,nontarget从右到左遍历,比较两组数据对应的分数大小,刚开始时nontarget的分数比target大,因为这里是把正确的识别成了错误的,然后两边数据的分数慢慢趋近,最后在nontarget的分数比target小的位置确定阈值。由于target的数据要远小于nontarget,因此在对比数据时nontarget的数据是按一定的间隔选择数据用于比较,通过下面这段代码来选择数据:
nontarget_n = nontarget_size * target_position * 1.0 / target_size,
nontarget_position = nontarget_size - 1 - nontarget_n;
到此,aishell的声纹识别就完成了,我在后期把注册数据改成了10条,得到的eer和threshold如下: 
11 后记
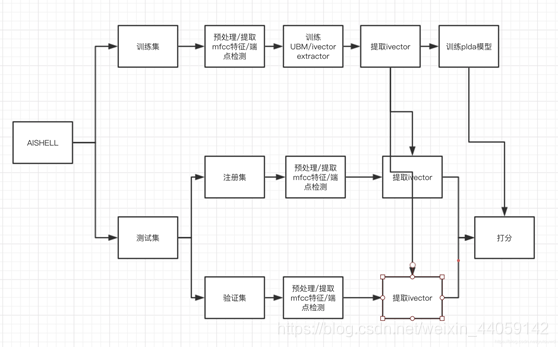
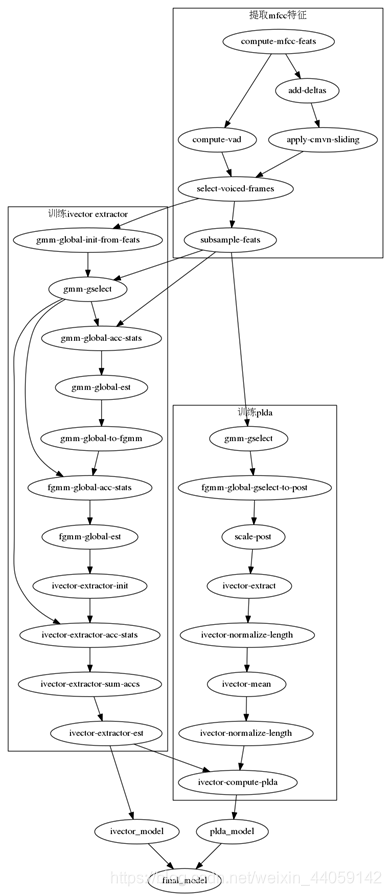
以上就是kaldi中aishell/v1/run.sh的整个流程,关于原理上的东西没有涉及太多,等有时间了再单独拿出来写一写。最后附上两张大神画的流程图,个人觉得比较有参考价值。

















 4959
4959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









