







公式
Q-learning
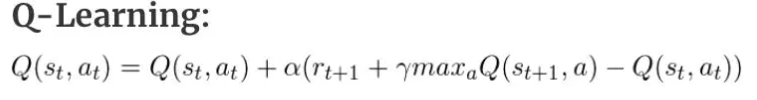
SARSA
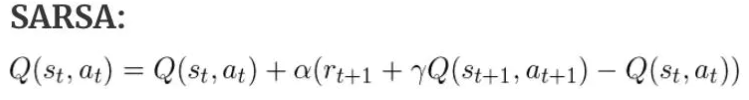
区别
其实我认为俩者的区别就是在于更新的时候有没有考虑到e-greed贪恋算法中的随机这个因素,sarsa考虑到了,Q-learning没有考虑。为什么这么说呢?
假设我们有三个状态S1 S2 S3
我们在使用SARSA的时候会用到S1 A1 R 和S2 A2(sarsa的构成),这个时候我们发现,我们的机器其实已经走到了S3这个位置,是在执行完A2这个动作之后,我们更新的是S1的Q表格
而Q-learning的区别在于,我们在更新Q表格的时候实际上我们还在S2这个位置,我们的A2这个值呢,是猜的。
为什么说是猜的,我们使用的是max,也就是Q值最大的那个动作,我们在SARSA实际上走的时候不也使用的是Q值最大的那个动作嘛?
实际上不然,我们有一定的概率随机走,也就是我们的e-greed贪心算法,在SARSA中,走完之后我们知道实际上走的A2动作是什么,也就知道,我们是在随机探索呢,还是按着既定策略在走。而Q-learning则以为,我们一直按着既定策略在走,他不知道我们实际上有探索这个过程,所以这就是区别。
SARSA:实践是检验真理的唯一途径
Q-learning:我不要你以为,我要我以为,我以为你是这么走的,那你就是这么走的
这样的话,SARSA就会考虑到危险的可能性,于是呢,他就会离着危险的地方远远的。而Q-learning他就压根不知道有危险这个东西存在,于是呢,他会朝着最捷径的路去走(如下图)

其实这样就能更好的理解on-policy和off-policy的区别,on-policy都是按着我们实际的策略在走,off-policy就不一定了。在这里由于理解可能过于片面就不详细赘述了。















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









