






 本文详细介绍了如何使用R语言和GIS工具(如ArcGIS、ENVI)进行数据准备和地理探测分析。内容涵盖数据转换、属性连接、数值表达,以及使用地理探测器进行分异、因子探测、交互作用探测、风险区探测和生态探测的步骤和方法。此外,还讨论了处理数据溢出和空值错误的策略。
本文详细介绍了如何使用R语言和GIS工具(如ArcGIS、ENVI)进行数据准备和地理探测分析。内容涵盖数据转换、属性连接、数值表达,以及使用地理探测器进行分异、因子探测、交互作用探测、风险区探测和生态探测的步骤和方法。此外,还讨论了处理数据溢出和空值错误的策略。
目录
相关教程–软件及数据准备
ArcGIS教程之——地理探测器
地理探测器原理、下载与使用
地理探测器(GeoDetector)原理及其实现
R语言数据分析
教程
官方教程–https://link.zhihu.com/?target=https%3A//cran.r-project.org/web/packages/geodetector/vignettes/geodetector.html%23factor-detector
1、R包、数据准备、GD综合代码
install.packages("GD") #安装包
setwd("D:\\ArcgisDATA\\DATA")#设置工作路径
library(GD) #加载包
test = read.table("分省各数据2017.csv",header=T, sep=",") #读入数据
head(test) #查看数据
#分类
#equal(等距), natural(自然间断点分类-Jenks), quantile(分位数), geometric(几何间隔), sd(标准差), manual(手动间隔),
discmethod <-c("equal","natural","quantile","geometric") #选择离散化方法
discitv <-c(3:10)#定义间断点个数为4~10个
#optidisc(y~x, data,间断点方法, 间断点个数)
#方法二--在最后同时按下Shift键与回车键实现----同,运行时间太长,不出来-
my_gd1 <- gdm(YA2017 ~ x1+x2+x3+x4+x5+x6+x7+x8+x9,
continuous_variable = c("x1","x2","x3","x4","x5","x6","x7","x8","x9"),
data = test,
discmethod = discmethod,
discitv = discitv)
plot(my_gd1)
my_gd1 <- gdm(YA2017 ~ Xpop2017+pre2017+tmax2017+x1+x2+x3+x4+x5+x6+x7+x8+x9,
continuous_variable = c("Xpop2017", "pre2017", "tmax2017","x1","x2","x3","x4","x5","x6","x7","x8","x9"),
data = test,
discmethod = discmethod,
discitv = discitv)
plot(my_gd1)
my_gd <- gdm(YA2017 ~ Xpop2017 + pre2017 + tmax2017,
continuous_variable = c("Xpop2017", "pre2017", "tmax2017"),
data = test,
discmethod = discmethod,
discitv = discitv)
plot(my_gd)
save(my_gd1, file="RDATA/my_gd1.RData")
#方法一---运行时间太长了---删除sd模式
opt.Temp_Pop <- optidisc(YA2017 ~ Xpop2017+pre2017+tmax2017+aod2017_3+x1+x2+x3+x4+x5+x6+x7+x8+x9, data = test,discmethod,discitv)
opt.Temp_Pop #输出经过optidisc()函数计算后的最优方法与最优分类
odc.Tempchange <- disc(ndvi_40$Tempchange, 10, method = "quantile") #根据上述结果指定数据,分类数量以及分类方法
odc.Popdensity <- disc(ndvi_40$Popdensity, 8, method = "quantile")
plot(opt.Temp_Pop) #对最优方法与最优分类进行可视化
#一次输出所有结果
test.gdm <- gdm(incidence ~ type + region + level, data = test)
test.gdm #查看结果
plot(test.gdm) #绘图
2、分异及因子探测—q值 gd
分异及因子探测主要用于探测Y的空间分异性;以及探测某因子X多大程度上解释了属性Y的空间分异,用q值度量
test.fd <- gd(RuleID ~ RuleID_1 + RuleID_2 + RuleID_3, data = test)
test.fd #查看结果,qv即为地理探测器的q统计量,用来度量自变量对因变量的解释度,sig为显著性水平
plot(test.fd) #绘图
plot(test.fd, sig = FALSE) #sig为FALSE表示不显著的q值也进行展示
3、交互作用探测—评估因子gdinteract
交互作用探测主要用于识别不同风险因子X之间的交互作用,即评估因子X1和X2共同作用时是否会增加或减弱对因变量 Y 的解释力,或这些因子对Y的影响是相互独立的
test.gdinter <- gdinteract(RuleID ~ RuleID_1 + RuleID_2 + RuleID_3l, data = test)
test.gdinter #查看结果
plot(test.gdinter) #绘图
4、风险区探测–显著性–gdrisk()
风险区探测主要用于判断两个子区域间的属性均值是否有显著的差别。其中以sig=0.05为标准,小于0.05为显著,即Y,大于0.05为不显著,即N。
test.gdrisk <- gdrisk(RuleID ~ RuleID_1 + RuleID_2 + RuleID_3l, data = test)
test.gdrisk #查看结果,
plot(test.gdrisk) #绘图
5、生态探测—交叉影响–gdeco()
生态探测主要用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,利用GD包中的gdeco() 函数。
test.gdeco <- gdeco(RuleID ~ RuleID_1 + RuleID_2 + RuleID_3l, data = test)
test.gdeco #查看结果
plot(test.gdeco) #绘图
数据准备
人口数据下载https://www.worldpop.org/project/categories?id=3
人口密度下载https://www.worldpop.org/project/categories?id=18
其他人口数据https://blog.csdn.net/shanyanyi7173/article/details/124855123
注意:使用Arcgis首先创建.gdb(本文中在后期shp转gdp的)
一、以表格显示分区统计
使用工具—以表格显示分区统计
1、教程及错误
错误始祖:路径错误
输出那里不要改动,就用他给的原始路径
错误1:000864
Arcgis栅格转矢量时遇到错误:“000864: The input is not within the defined domain”----将栅格字段转为整形(Arcgis工具)
错误2:shp链接表字段乱码
1、未解决:在shp文件的同级目录,建立同名的.cpg文件,在文件中填写正确的编码方式,如果是GBK,就写936;如果是UTF-8,就写UTF-8。这样能够指定arcmap以什么编码方式打开shp文件,而不是用默认的编码方式打开。(或者oem)


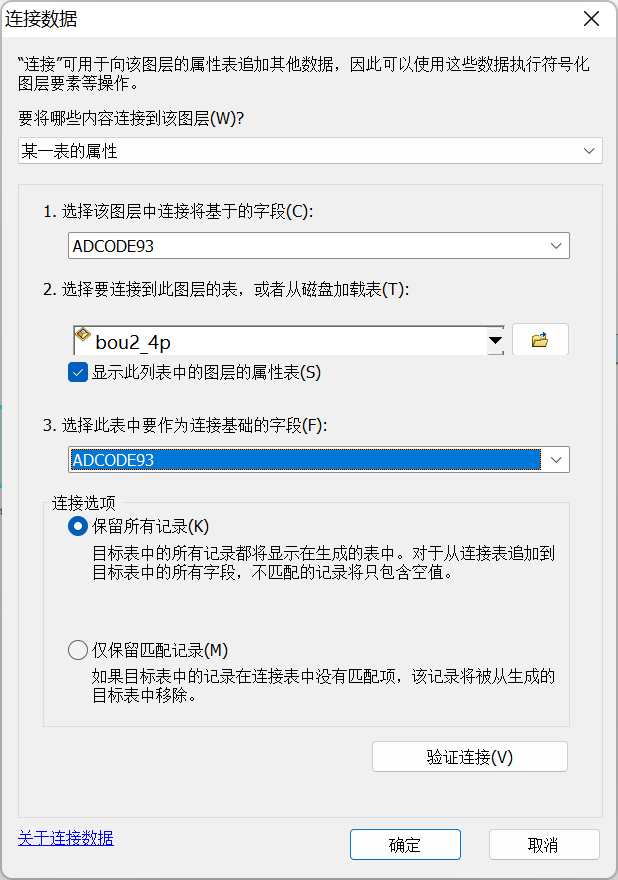
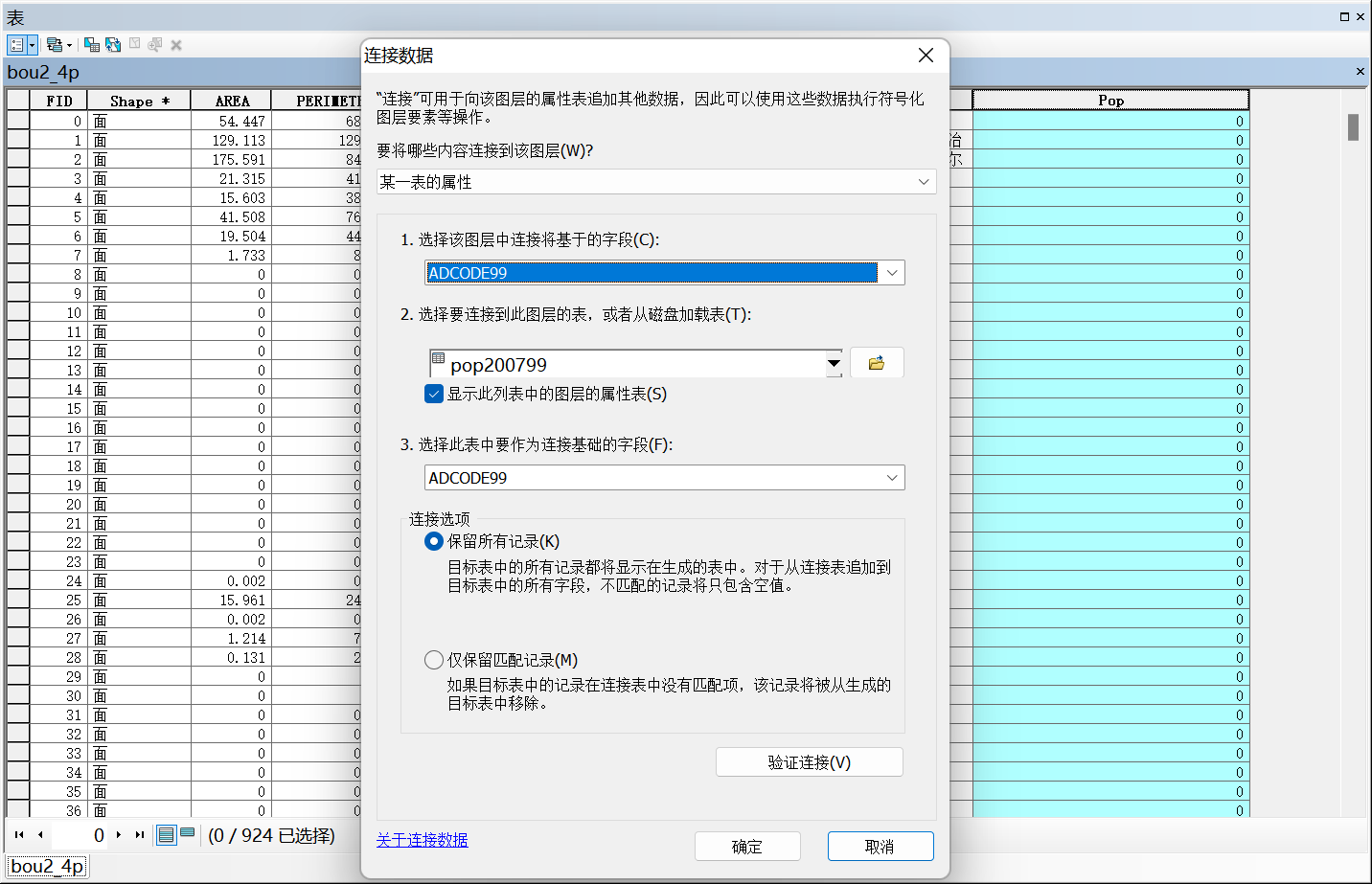
2、以ADCODE99字段代替NAME,输出表后关联shp字段—使用表转excel编辑字段
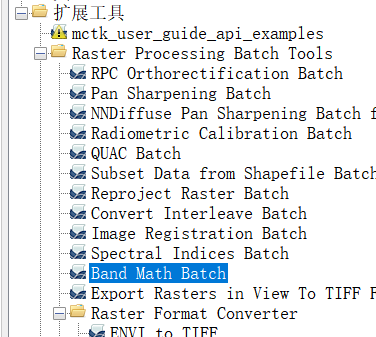
2、直接用ENVI,安装分区统计工具:
使用教程https://www.cnblogs.com/enviidl/p/16333230.html
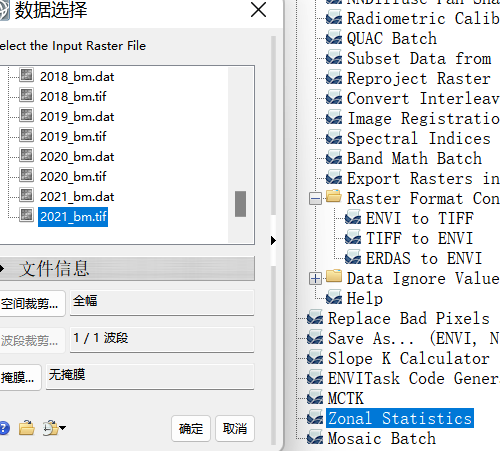
1、修改0值为NaN ----工具band math
float(b1)*b1/b1
2、hdr转tiff
3、分区统计-选择影像、shp、字段
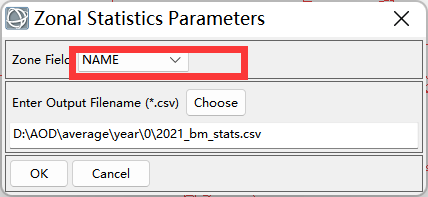
二、连接属性
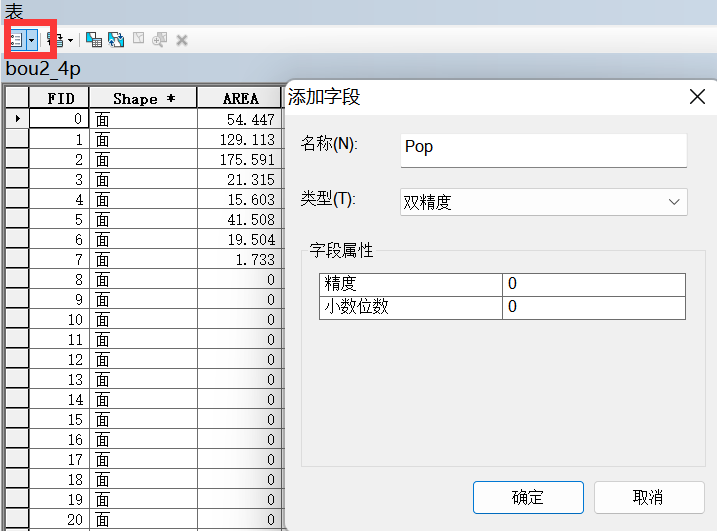
1、打开属性表–添加字段–人口
2、选中字段–连接对应字段
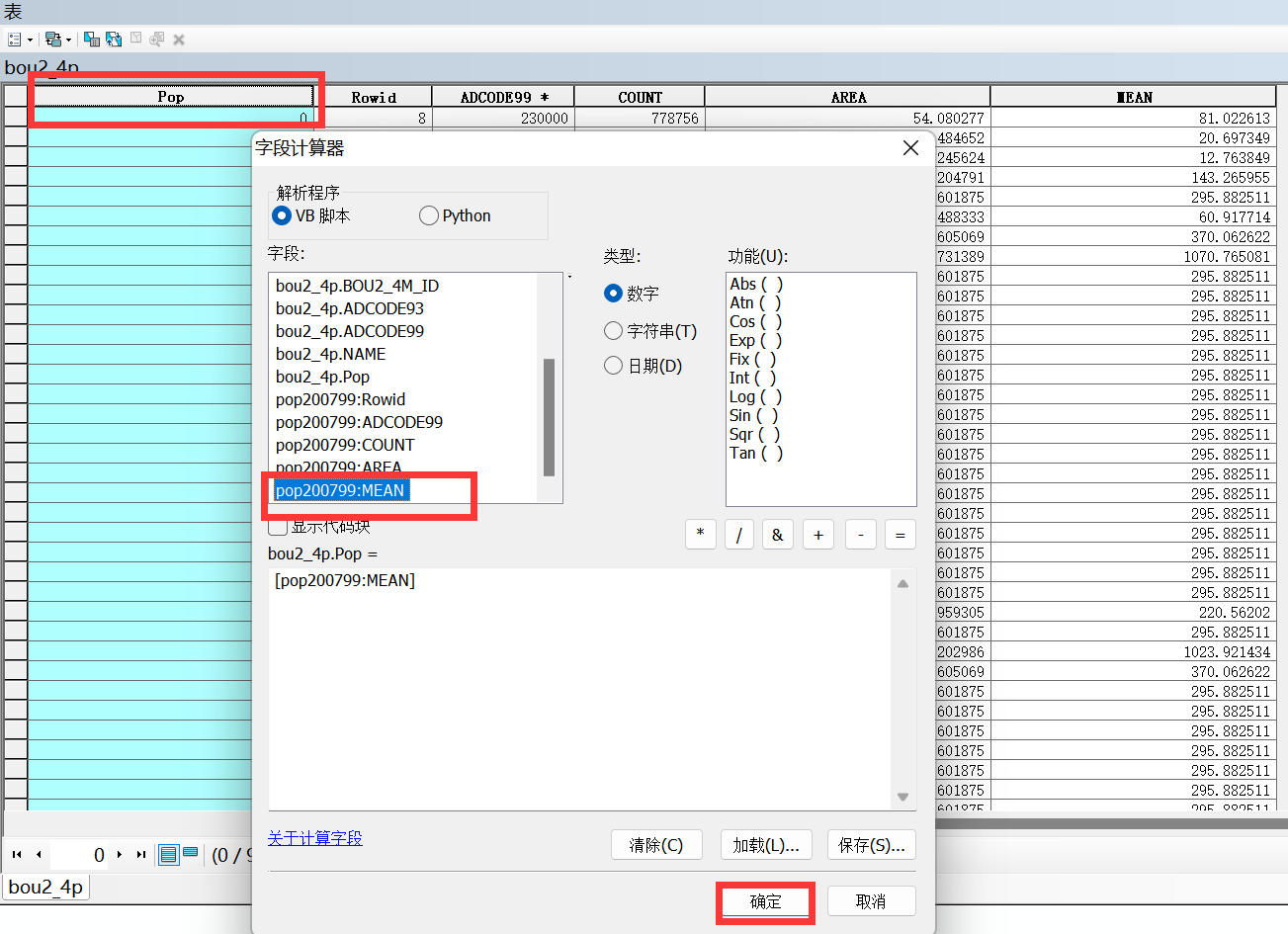
3、选中字段右击—字段计算器
4、移除连接(左上按钮–连接–移除连接)
三、转为数值表达
1、shp转gdp
1、文件–新建–地理数据库
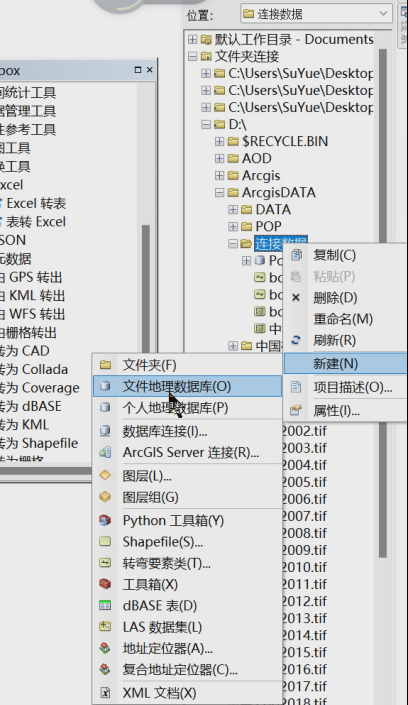
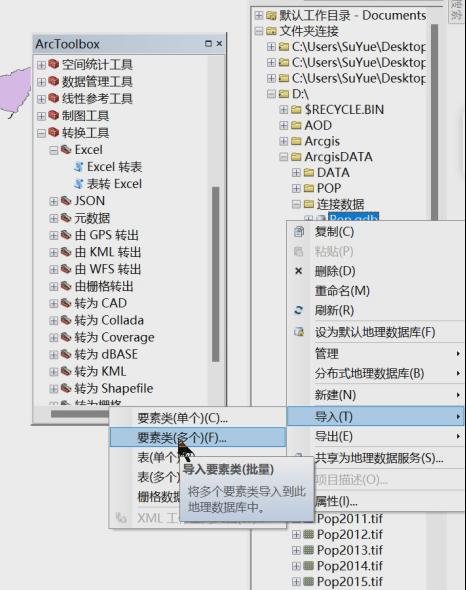
2、gdb–导入–多个要素类–添加相应shp即可
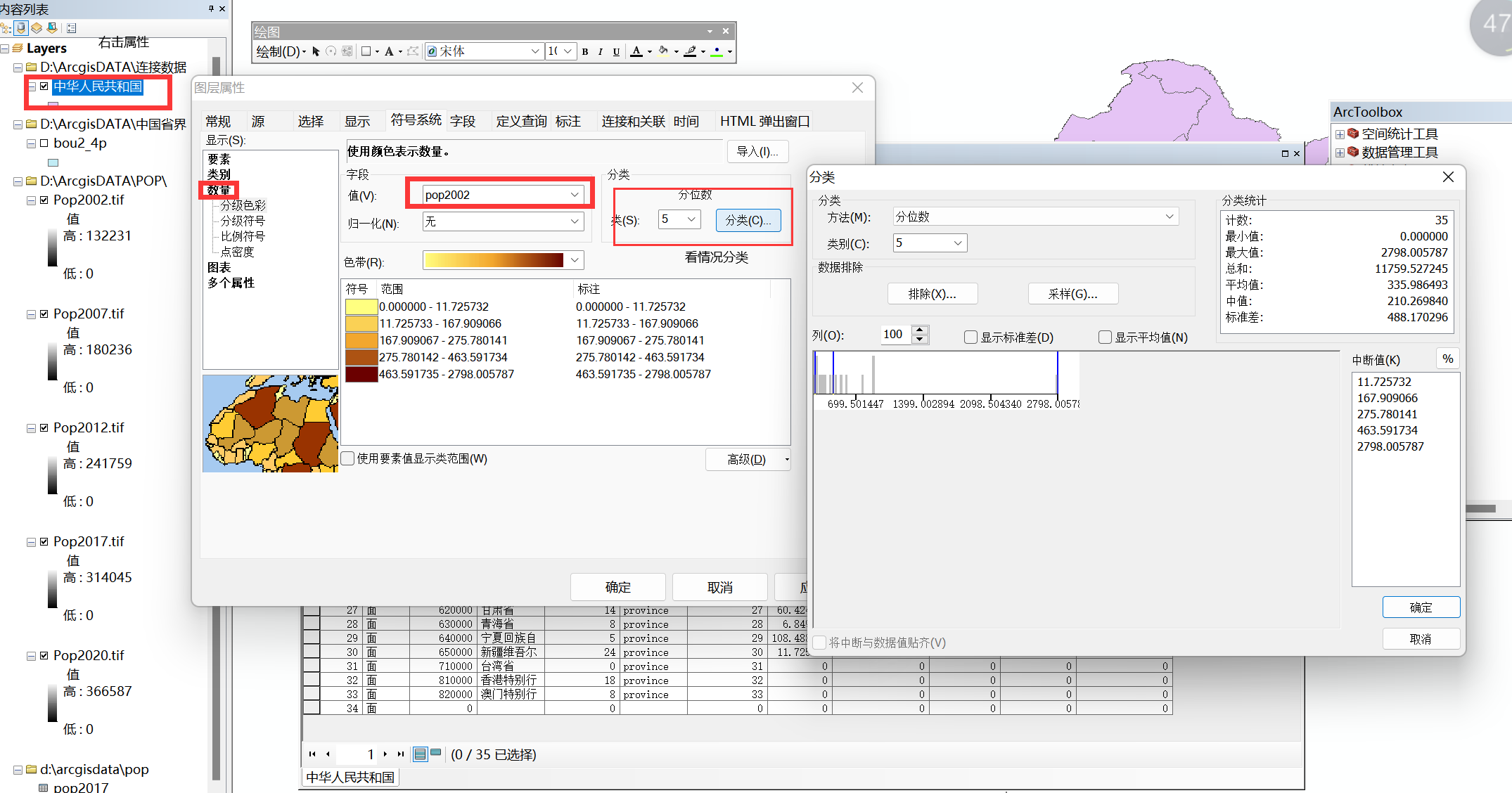
2、属性-添加类别
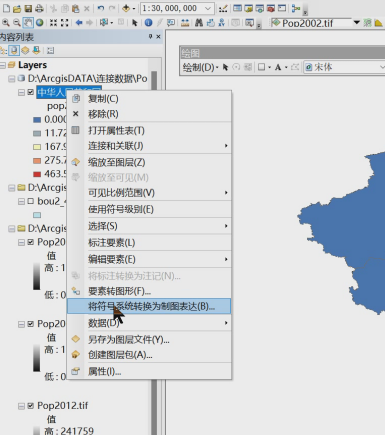
3、转为制图表达
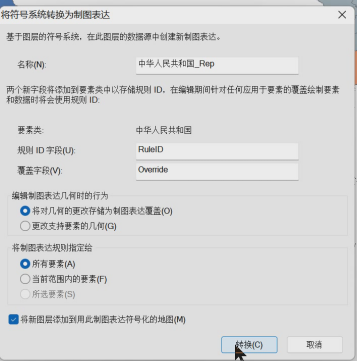
方法二
一、重分类
1、更改分辨率
2、重分类
3、栅格转点(创建目标区域渔网)
3.1选择-按位置选择(创建目标区域渔网)
3.2 右键-数据-导出数据(文件和个人要素类)
4、多值提取至点
5、打开属性表—全选–复制全选至excel
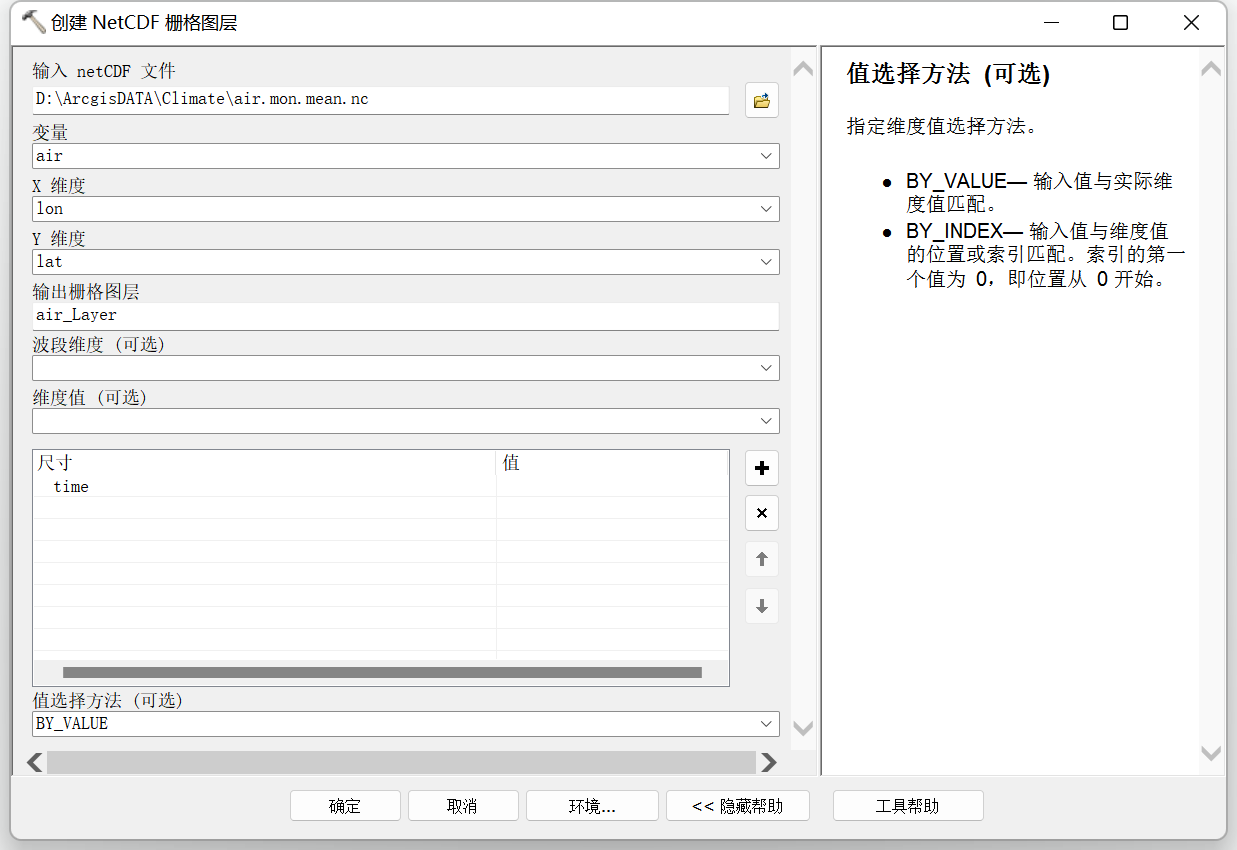
nc文件转栅格
三维工具----创建 NetCDF栅格图层
错误
1、地理探测器错误 溢出6
(1)数据量太大
解决:使用R包/ 数据重采样降低数据量分辨率
(2)粘贴错误选择了所有包括空行数据
解决:在word中选中所有表头----shift+ctrl+↓—在地理探测器中单击一个表表格-粘贴
2、地理探测器运行时错误11,除数为0
表格中有空值
解决:1.word中替换-定位到空值
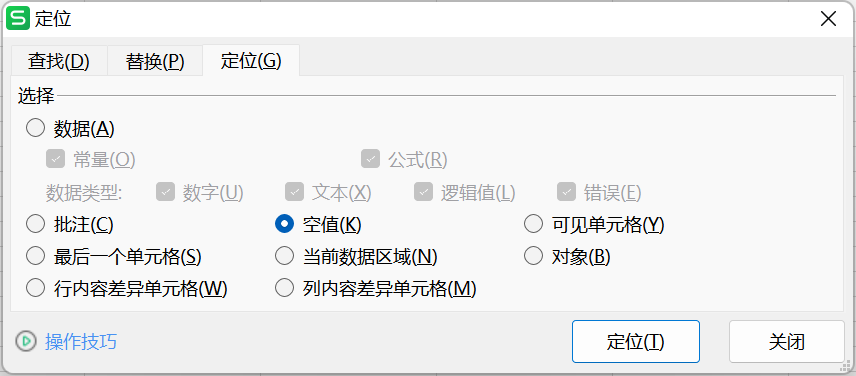
2.按住“Ctrl+Enter”键–输入1(自己的分类)—再次按住“Ctrl+Enter”键
地理探测器软件
1、介绍
地理探测器的基本思想是:假设研究区分为若干子区域, 如果子区域的方差之和小于区域总方差, 则存在空间分异性;如果两变量的空间分布趋于一致, 则两者存在统计关联性。地理探测器q统计量, 可用以度量空间分异性、探测解释因子、分析变量之间交互关系, 已经在自然和社会科学多领域应用。
地理探测器包括4个探测器:包括交互作用探测;生态探测;分异及因子探测;风险区探测。
1.因素X对于因素Y是独立起作用还是具有广义的交互作用?
2.是否存在空间异质性?什么因素造成了这种分层异质性?
3.因素X之间的相对重要性如何?
4.变量Y是否存在显著的区际差别?
1. 分异及因子探测–Factor_detector
探测Y的空间分异性;以及探测某因子X多大程度上解释了属性Y的空间分异,并用用q值度量,q值越大表示自变量X对属性Y的解释力越强, 反之则越弱。
最小为0,最大为1,越大说明该自变量对因变量的空间分异解释程度越大。
2. 交互作用探测–Interaction_detector
识别不同风险因子Xs之间的交互作用, 即评估因子X1和X2共同作用时是否会增加或减弱对因变量Y的解释力, 或这些因子对Y的影响是相互独立的。评估每两个自变量共同作用时,是否会增加或减弱对因变量的解释能力。
这里一共会有5个结果,从左到右分别为非线性减弱、单因子非线性减弱、双因子增强、独立、非线性增强。
3. 风险区探测–Risk_detector
用于判断两个子区域间的属性均值是否有显著的差别, 用t统计量来检验。
4. 生态探测–Ecological_detector
用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异, 以F统计量来衡量。
比较每两个自变量对因变量的空间分布的影响是否有显著的差异。
2、使用
**注意!:1.使用Excel打开表格 **
注意!:2.只复制粘贴需要计算的因子
3.粘贴–删除—run data–run
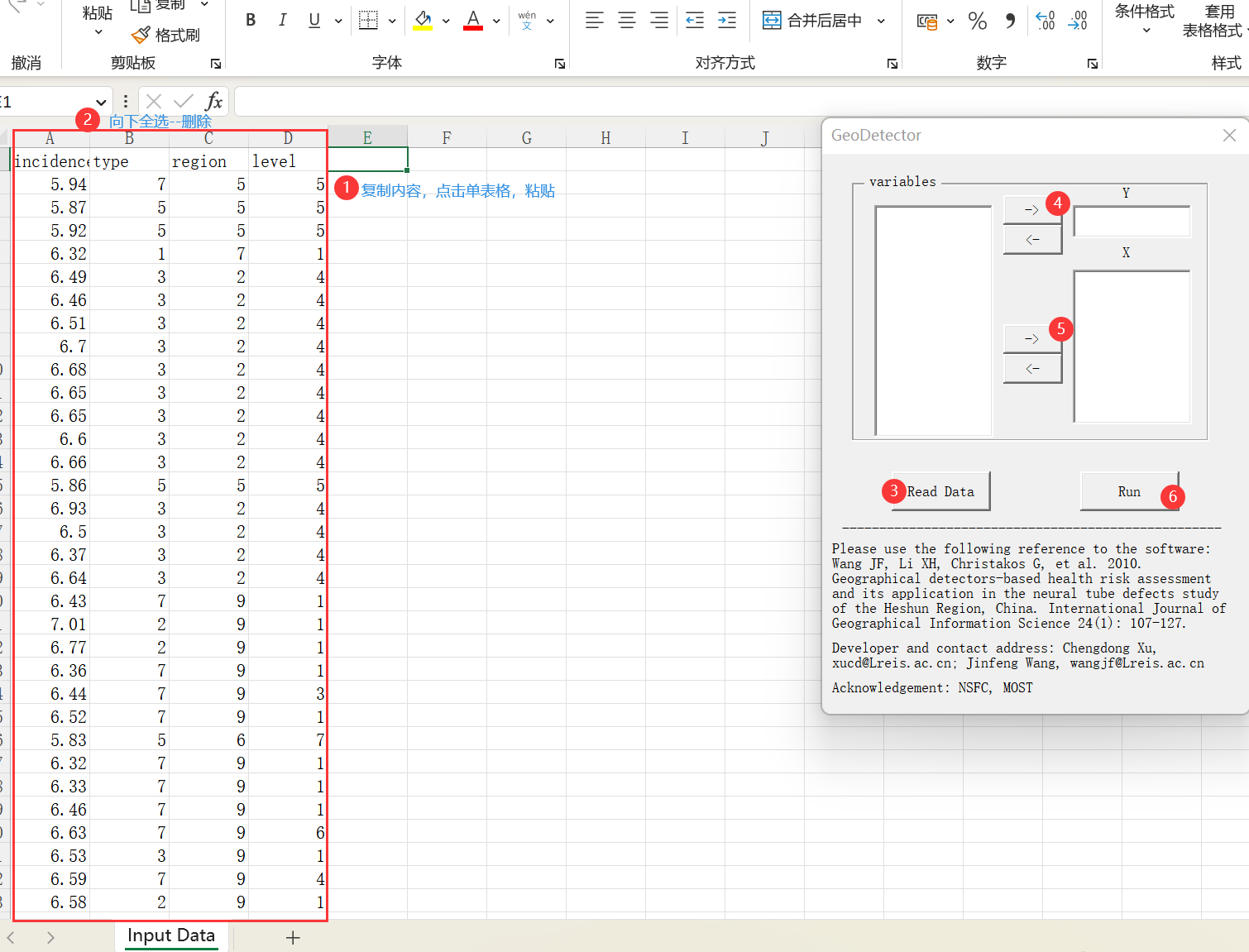
步骤实操(按点)
1、将栅格转点
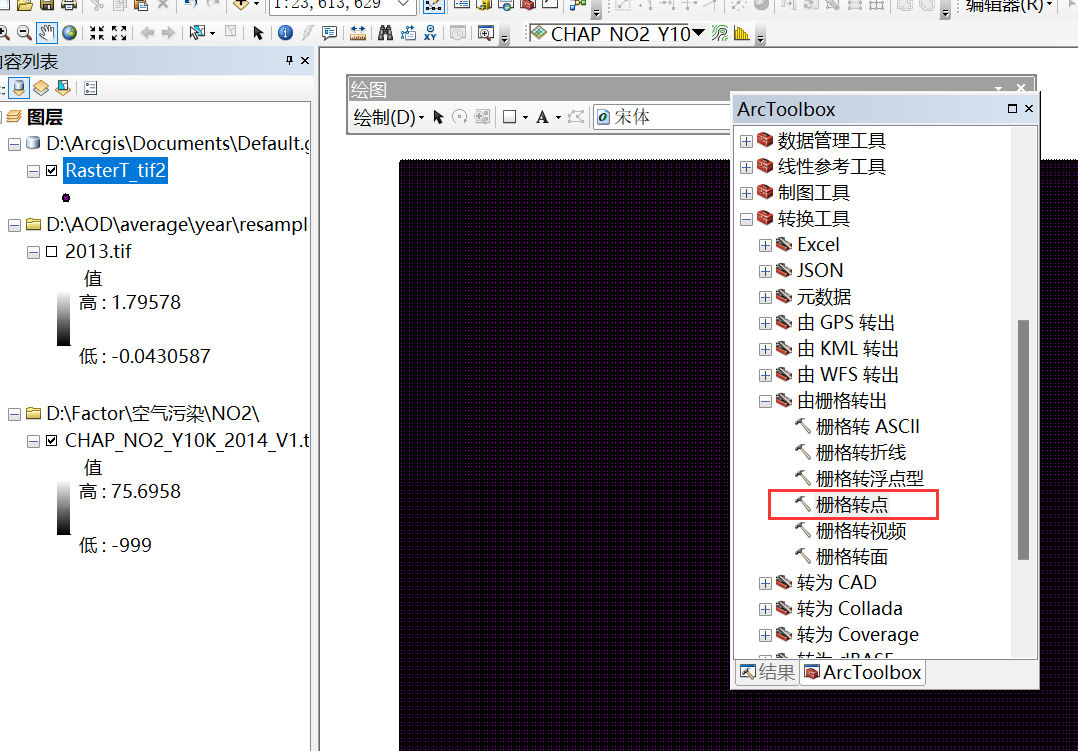
2、裁剪出需要的区域
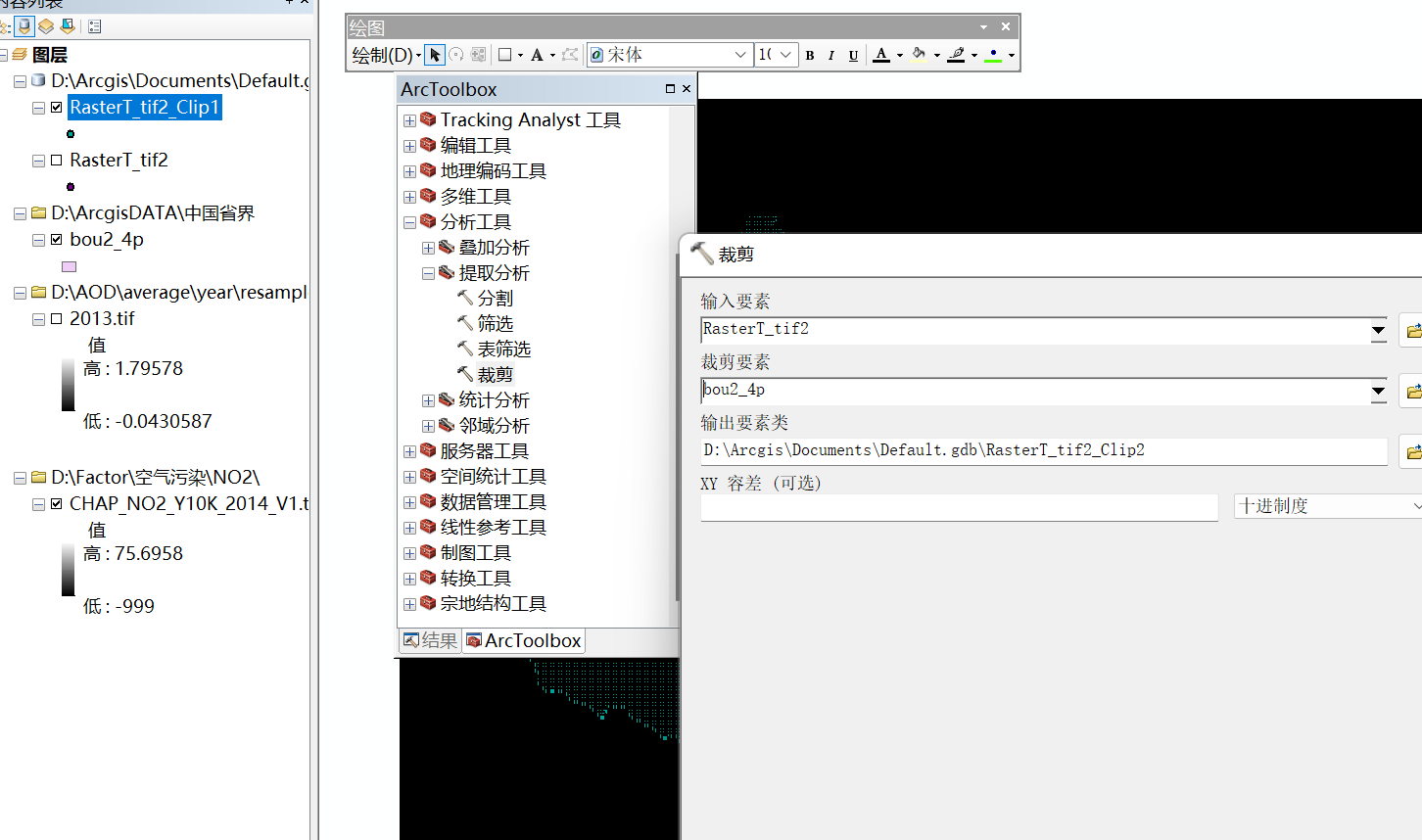
3、多值提取至点
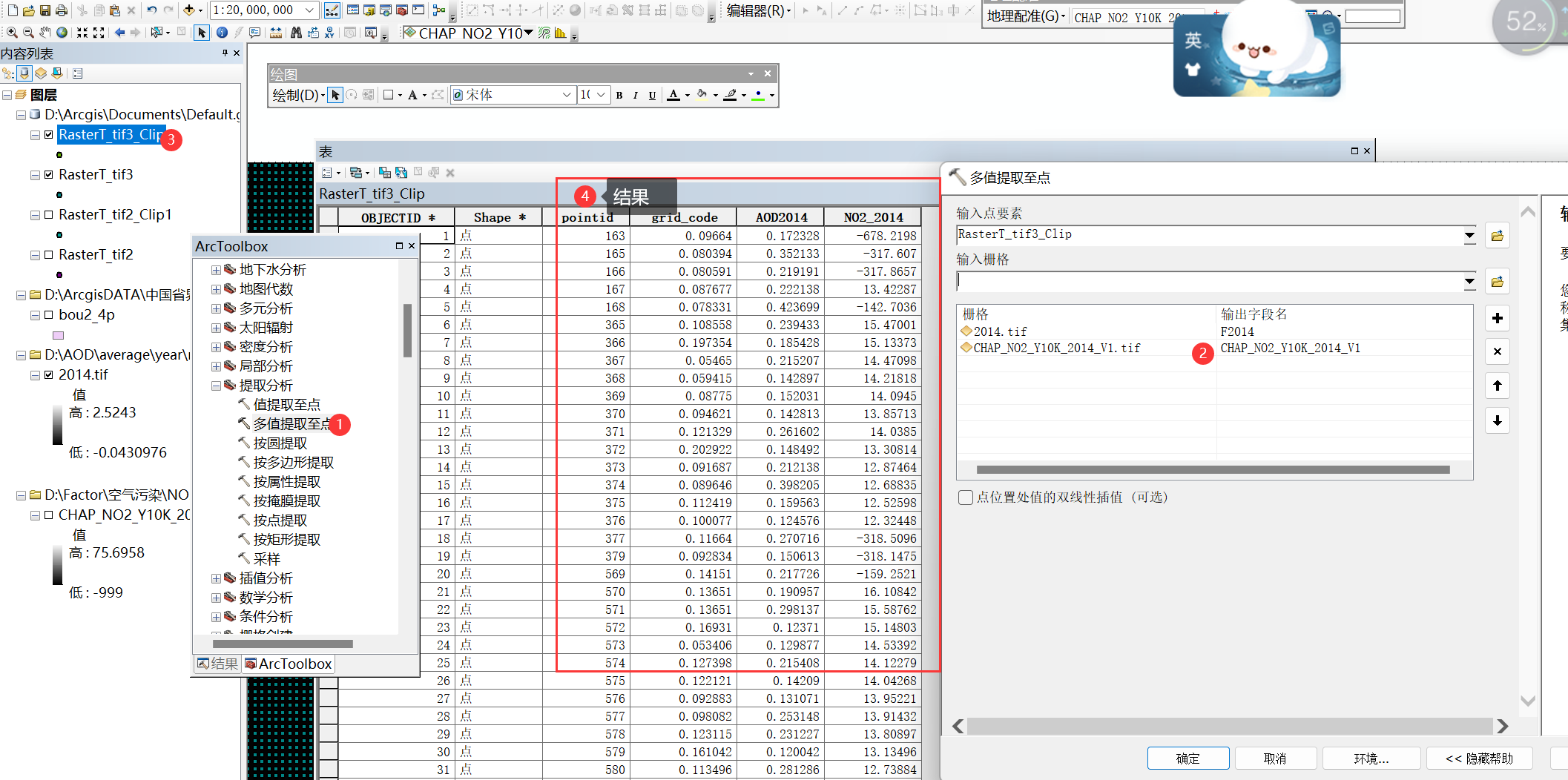
4、表转表格
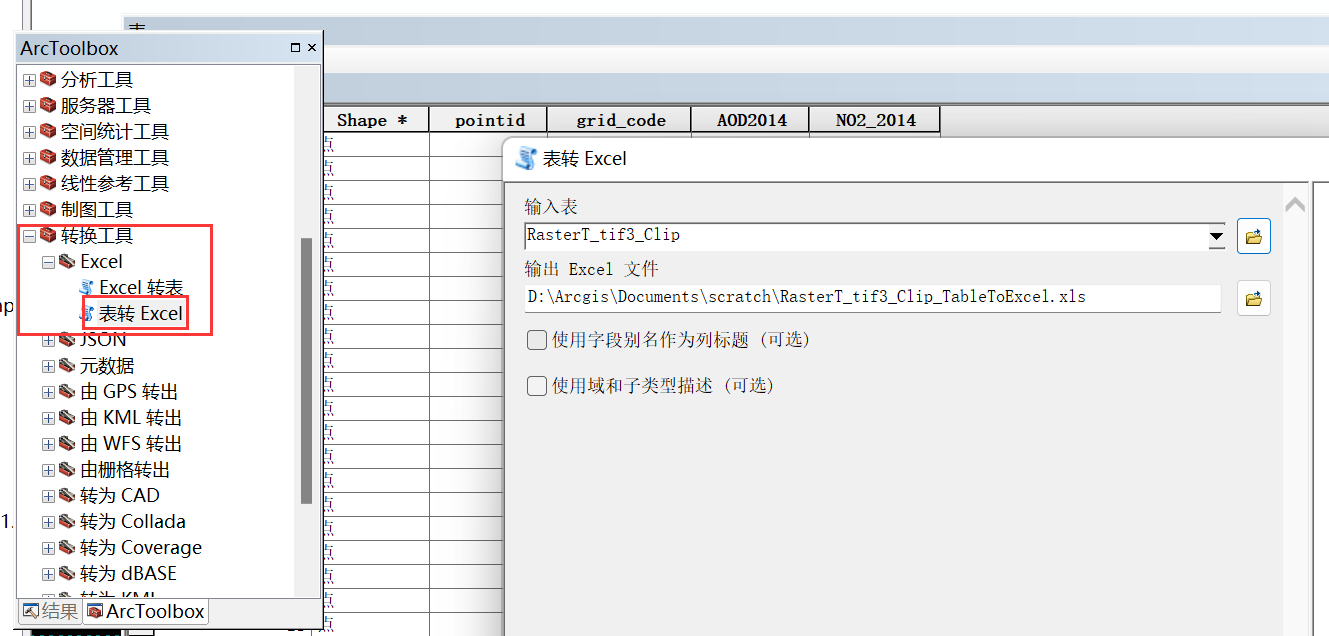
5、去除无效值并转为CSV格式
这里使用MATLAB
clc
clear
[data,~,raw]= xlsread('D:\ArcgisDATA\DATA2\2014N.xls');
% [AA,~,A]= xlsread('C:\Users\SuYue\Desktop\碳排放\2005.xlsx','Inter');
ia=1
for i=1:size(data,1)
if data(i,5)>0
A(ia,:)=data(i,:);
ia=ia+1;
end
end
xlswrite(strcat('D:\ArcgisDATA\DATA2\2014N1.csv'),A)
6、探测计算
setwd("D:\\ArcgisDATA\\DATA2")#设置工作路径
library(GD) #加载包
library("writexl")
library(readxl)
library(eoffice)
library(stringr)
test = read_excel("2014N2.xls") #读入数据
#head(test) #查看数据
#equal(等距), natural(自然间断点分类-Jenks), quantile(分位数), geometric(几何间隔), sd(标准差), manual(手动间隔),
discmethod <-c("equal","natural","quantile","geometric")
discitv <-c(4:10)#定义间断点个数为4~8个
continuous_variable <- colnames(test)[-c(1,2,4)]
data <- test[-c(1,2)]
#data <- test[-c(337:371),c(12,15,20,21,23,25,26,27)]
testgdm <- gdm(AOD2014 ~. ,
continuous_variable = continuous_variable,
data = as.data.frame(data),
discmethod = discmethod,
discitv = discitv)
Fig <- plot(testgdm)
library(eoffice)
topptx(Fig,"fig2011.ppt")
out=capture.output(testgdm)
write.table(out, file = "2011.txt", append = F,
quote = F, sep = " ", eol = "\n",
na = "NA", dec = ".", row.names = F,
col.names = F, qmethod = c(),
fileEncoding = "utf-8")


















 6426
6426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









