







前言
最近开始看mvs系列论文,记录一些心得体会,废话不多说,直接进入主题
一、整体概述
作者提出了一种端到端的网络进行深度图估计,网络的输入是一张参考图像(文中的reference img)和一系列的源图像(source imgs),这篇文章的目的是为了得到参考图像的深度图,网络整体结构如下:
 这里将按照网络的整体流程来逐步讨论。
这里将按照网络的整体流程来逐步讨论。
二、特征提取
首先呢,对输入的所有图像进行2d卷积来提取特征:
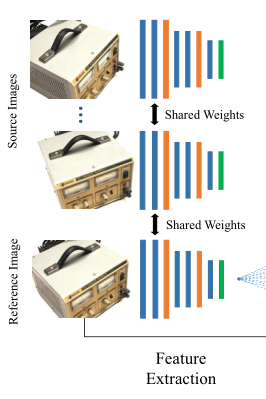
经过特征提取网络,图像会被编码成32通道的特征图,由于内存性能的原因,在这一部分对图像进行了下采样,最终得到32通道,大小为原图1/4的特征图。
pytorch代码
class FeatureNet(nn.Module):
def __init__(self):
super(FeatureNet, self).__init__()
self.inplanes = 32
self.conv0 = ConvBnReLU(3, 8, 3, 1, 1)
self.conv1 = ConvBnReLU(8, 8, 3, 1, 1)
self.conv2 = ConvBnReLU(8, 16, 5, 2, 2)
self.conv3 = ConvBnReLU(16, 16, 3, 1, 1)
self.conv4 = ConvBnReLU(16, 16, 3, 1, 1)
self.conv5 = ConvBnReLU(16, 32, 5, 2, 2)
self.conv6 = ConvBnReLU(32, 32, 3, 1, 1)
self.feature = nn.Conv2d(32, 32, 3, 1, 1)
def forward(self, x):
x = self.conv1(self.conv0(x))
x = self.conv4(self.conv3(self.conv2(x)))
x = self.feature(self.conv6(self.conv5(x)))
return x
三 、可微分的单应变换
我们知道,单应矩阵描述了不同图像点对之间的约束关系,先来一波公式的推导:

可以发现,在这里单应矩阵中唯一的变量是“d”,也就是平面点法式方程中的深度d。
公式很容易推导,作者在这一步想表达的的意思不是很复杂,但是作为一个初学者来说(指我),我更加好奇为什么在这里要用到可微分的单应变换来构建cost volumn (后文会提到的3d代价体),在我不理解的时候,甚至想为啥不直接让他再进入到一个2d网络去学习这种关系得了(哈哈哈别喷我),查阅了一下资料,这里用到单应变换的原因是基于一种几何的方法–平面扫描法。
三维重建之平面扫描算法(Plane-sweeping)
参考 :https://blog.csdn.net/xuangenihao/article/details/81392684
可以理解成,利用网络去学习平面扫描法背后的几何关系。
pytorch代码
def homo_warping(src_fea, src_proj, ref_proj, depth_values):
# src_fea: [B, C, H, W]
# src_proj: [B, 4, 4]
# ref_proj: [B, 4, 4]
# depth_values: [B, Ndepth]
# out: [B, C, Ndepth, H, W]
batch, channels = src_fea.shape[0], src_fea.shape[1]
num_depth = depth_values.shape[1]
height, width = src_fea.shape[2], src_fea.shape[3]
with torch.no_grad():
proj = torch.matmul(src_proj, torch.inverse(ref_proj))
rot = proj[:, :3, :3] # [B,3,3]
trans = proj[:, :3, 3:4] # [B,3,1]
y, x = torch.meshgrid([torch.arange(0, height, dtype=torch.float32, device=src_fea.device),
torch.arange(0, width, dtype=torch.float32, device=src_fea.device)])
"""
生成网格x , y 为 height * width 互为转置
"""
y, x = y.contiguous(), x.contiguous()#trans view前数据在内存里不连续 让他连续
y, x = y.view(height * width), x.view(height * width)#把x,y展开
xyz = torch.stack((x, y, torch.ones_like(x))) # [3, H*W] //秒! 相当于组成一个齐次坐标矩阵 详见 learn
xyz = torch.unsqueeze(xyz, 0).repeat(batch, 1, 1) # [B, 3, H*W]// 复制一个patch 这样的数据
rot_xyz = torch.matmul(rot, xyz) # [B, 3, H*W]
rot_depth_xyz = rot_xyz.unsqueeze(2).repeat(1, 1, num_depth, 1) * depth_values.view(batch, 1, num_depth,
1) # [B, 3, Ndepth, H*W]
proj_xyz = rot_depth_xyz + trans.view(batch, 3, 1, 1) # [B, 3, Ndepth, H*W]
proj_xy = proj_xyz[:, :2, :, :] / proj_xyz[:, 2:3, :, :] # [B, 2, Ndepth, H*W]
proj_x_normalized = proj_xy[:, 0, :, :] / ((width - 1) / 2) - 1
proj_y_normalized = proj_xy[:, 1, :, :] / ((height - 1) / 2) - 1
proj_xy = torch.stack((proj_x_normalized, proj_y_normalized), dim=3) # [B, Ndepth, H*W, 2]
grid = proj_xy
warped_src_fea = F.grid_sample(src_fea, grid.view(batch, num_depth * height, width, 2), mode='bilinear',
padding_mode='zeros')
warped_src_fea = warped_src_fea.view(batch, channels, num_depth, height, width)
return warped_src_fea
这个代码我简单注释了一下,其中维度变换对于我来说来时很头疼的,建议把这里自己看懂后自己复现一下,hhhhhh!
四、3d代价体的构造
刚才学习了一下已知位姿的单应变换构造方法,接下来作者构造了一个3d代价体,它的目的是为了学习到参考图像的像素点在不同深度下的概率。
经过特征提取网络后,每幅图像都得到了一个32通道的特征图。mvs的目的是进行稠密重建,而相机内外参数以及参考图像上像素点大致的深度范围是已知的(在稀疏重建中获得)。作者把已知的深度范围(假设是0-100)划分为n份(假设为10),那么连续的深度就被离散化了,变成10份(0,10,20,…,100),刚才我们提到过,单应变换中,只有唯一的未知量d(公式在上面写着,就是我手写的那一部分),那么,在刚才划分的10个平面上就对应有10个单应矩阵,然后将参考图像和源图像的特征图都分别变换到这10个平面上来(这个10个平面本身就和参考图像平行,所以参考图像就不用计算了,直接放上去就行),我画个图理解一下这个过程:

经过单应变换后,图像可能都扭曲了(虽然我画的是方的),此时需要对图像进行插值,把它变成一个方的,并且长宽的原图大小相同(不是经过了一次下采样嘛)。
接下来,对r,s1,s2进行一个求取方差的操作,构建出3d cost volume,具体怎么做,我还是画个图:

公式如下:
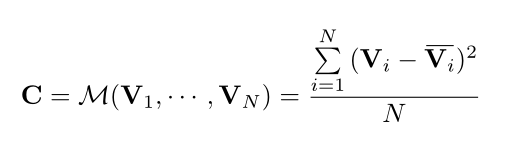
文章说这样可以使得这个网络适应任意视角的输入,假如说上图中不止有(s1,s2)还有s3,s4,s5,s6…(s11夺冠了),也按照上面的公式算,最后还是能变成一个立方体。至于为什么不用均值呀什么的其他统计量之类的,作者说这是做实验做出来的,方差效果最好!
今天先到这,写累了 …待续…















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









