







原文《大数据治理平台技术方案及案例解析》PPT格式,主要从大数据平台架构图、大数据平台业务能力、数据处理、数据规划、大数据计算框架、大数据分析引擎、应用案例分析等进行建设。
一、大数据平台架构图
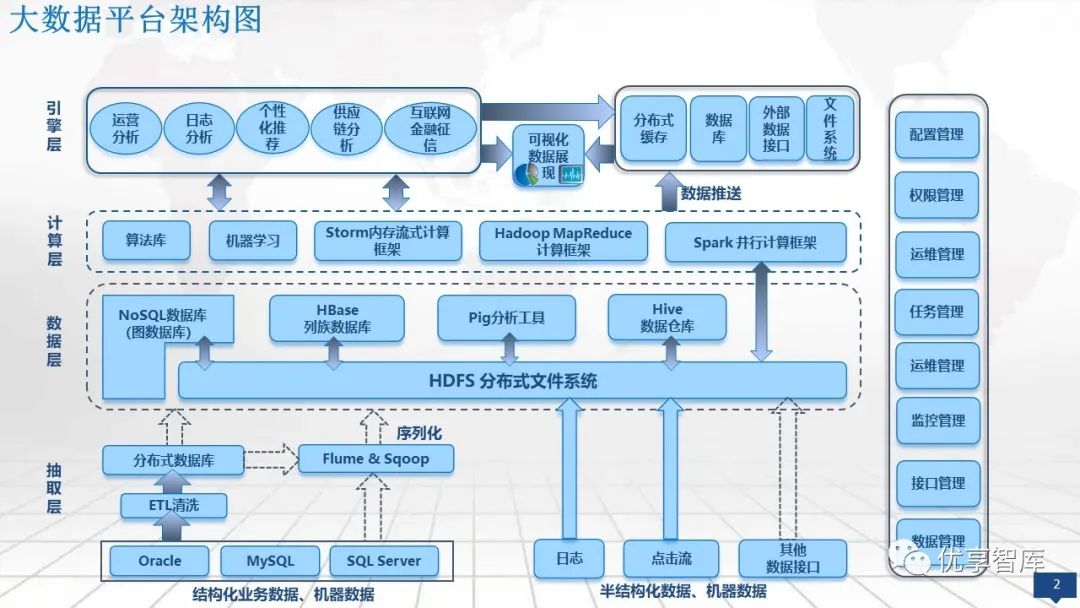
二、大数据业务能力
-
大数据开发及运行环境
-
大数据日志分析系统
-
零售行业商业运营指标分析(BI)
-
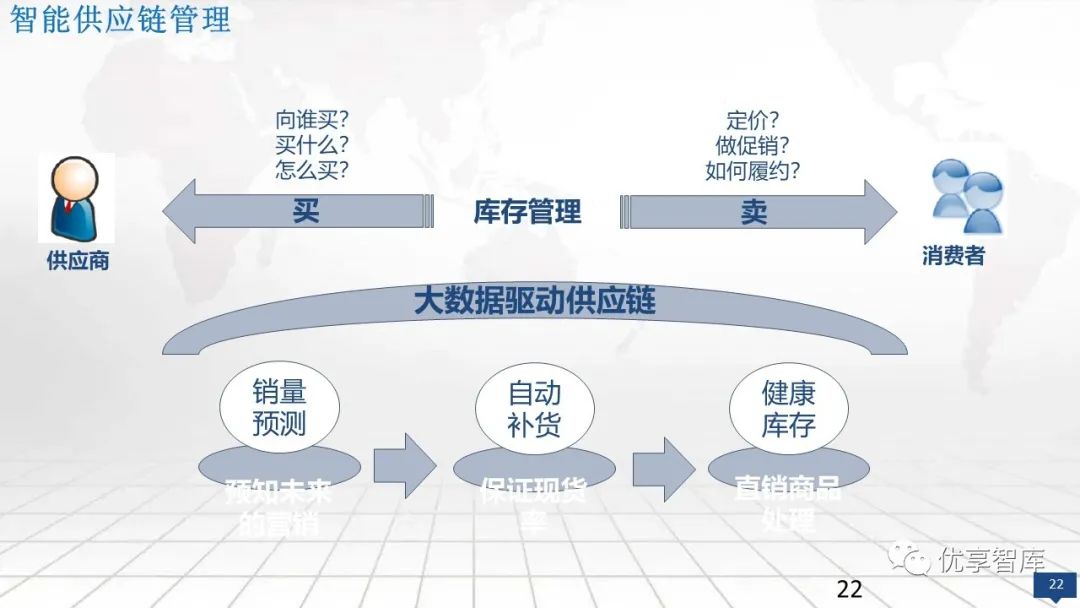
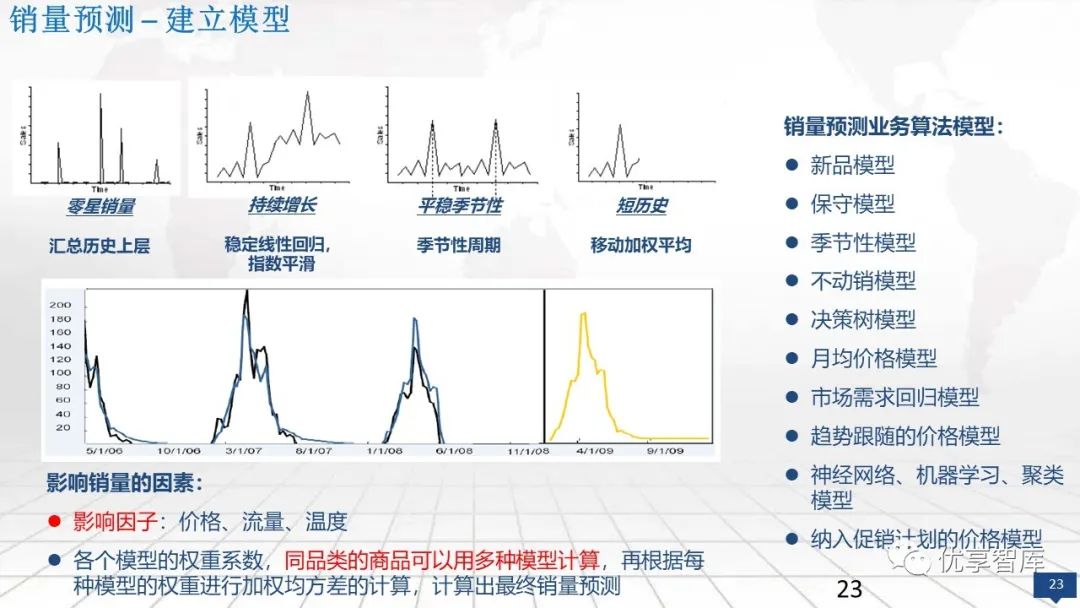
智能供应链分析
-
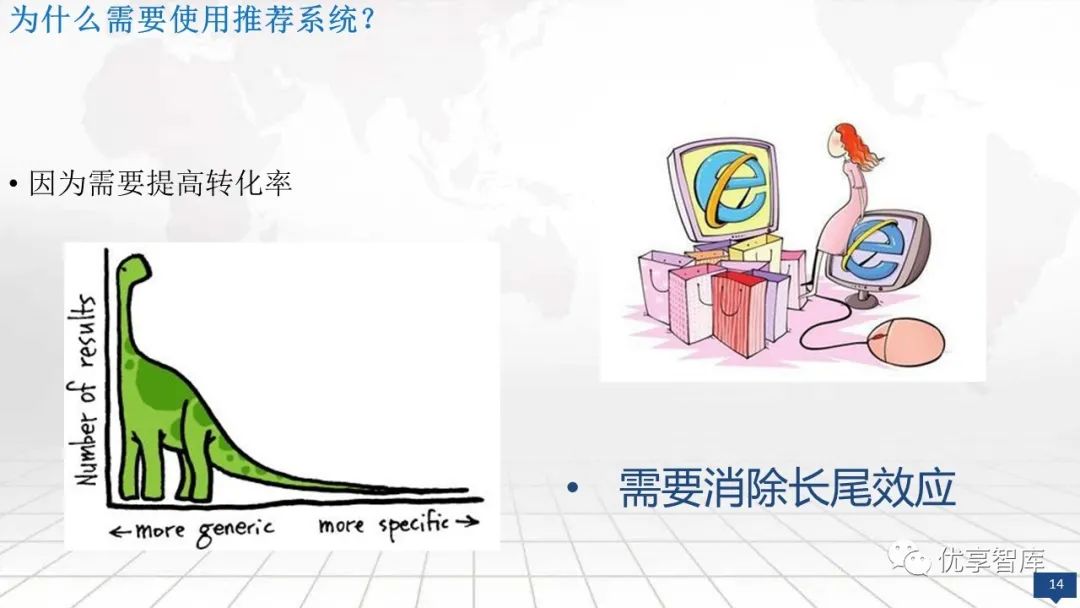
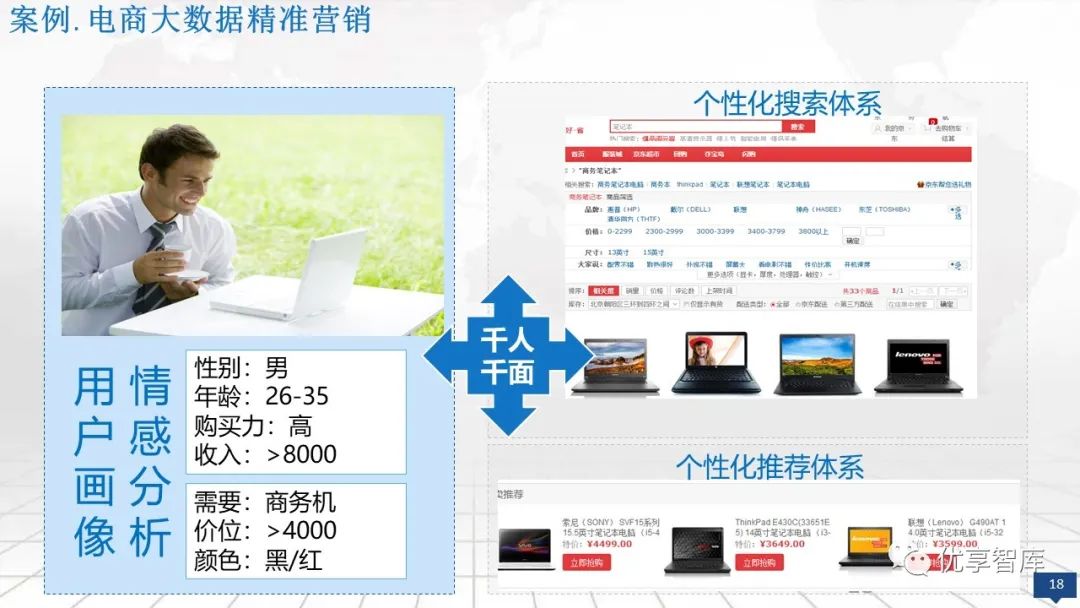
个性化推荐系统
-
互联网金融征信
首先大数据平台能够帮助企业构建一个大数据的开发运行环境,解决大数据的抽取、存储、组织、计算框架等需求;
其次,提供一款基于大数据技术的日志平台产品,解决机器数据日志的监控、报警、查询、故障定位等问题,也就是提供了一个智能化运维产品;
再有,基于零售电商和物流行业,提供3个大数据应用,分别是运营指标分析、智能供应链管理、个推;

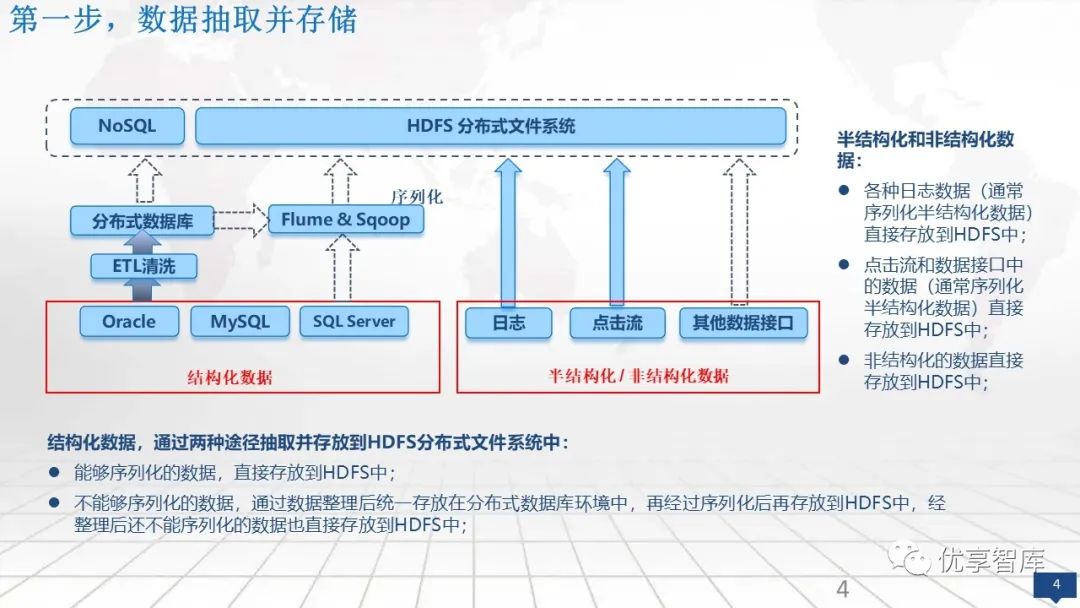
第一步,数据抽取并存储
第一步,抽取并存储,多元的数据存放在异构的关系型数据库中,结构化数据进行清洗和序列化后放到分布式文件系统里面,半结构化数据可以直接通过序列化存放到分布式文件系统里面。
结构化数据,通过两种途径抽取并存放到HDFS分布式文件系统中:
l能够序列化的数据,直接存放到HDFS中;
l不能够序列化的数据,通过数据整理后统一存放在分布式数据库环境中,再经过序列化后再存放到HDFS中,经整理后还不能序列化的数据也直接存放到HDFS中;
半结构化和非结构化数据:
l各种日志数据(通常序列化半结构化数据)直接存放到HDFS中;
l点击流和数据接口中的数据(通常序列化半结构化数据)直接存放到HDFS中;
l非结构化的数据直接存放到HDFS中;
数据处理
•数据处理包括数据清洗、数据转化、数据提取、数据计算等处理方法。
•数据处理最基本的目的是从大量杂乱无章、难以理解的数据中,抽取并推导出对解决问题有价值、有意义的数据。

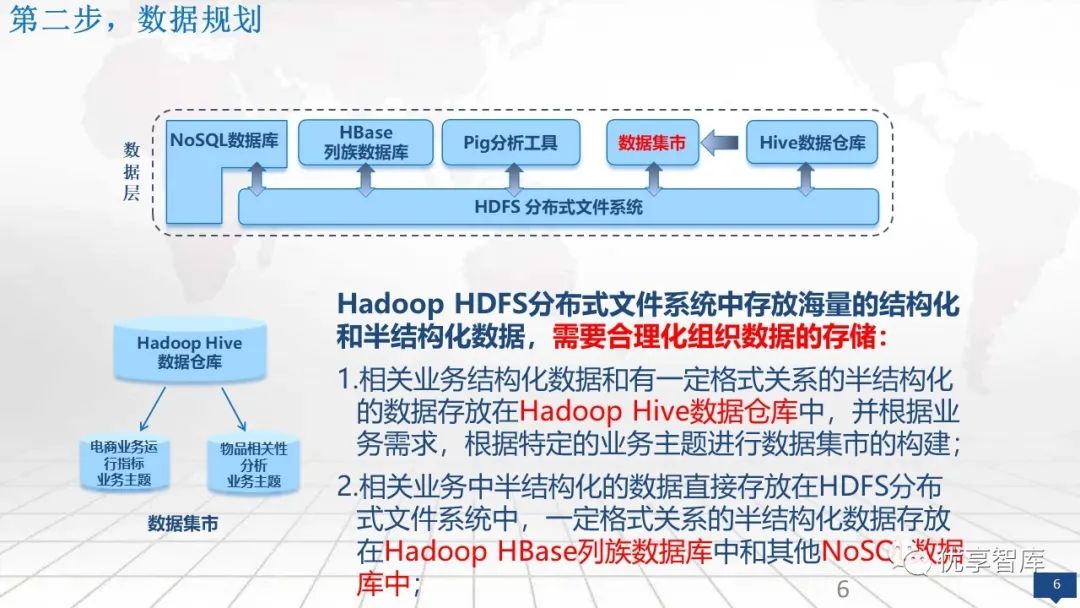
第二步,数据规划
这些结构化和半结构化数据存上来以后,可以放到分布式文件系统里面或者NoSQL里面。进行一个数据化的组织。弱格式的数据可以存放到hadoop hbase里面。
Hadoop HDFS分布式文件系统中存放海量的结构化和半结构化数据,需要合理化组织数据的存储:
1.相关业务结构化数据和有一定格式关系的半结构化的数据存放在Hadoop Hive数据仓库中,并根据业务需求,根据特定的业务主题进行数据集市的构建;
2.相关业务中半结构化的数据直接存放在HDFS分布式文件系统中,一定格式关系的半结构化数据存放在Hadoop HBase列族数据库中和其他NoSQL数据库中;
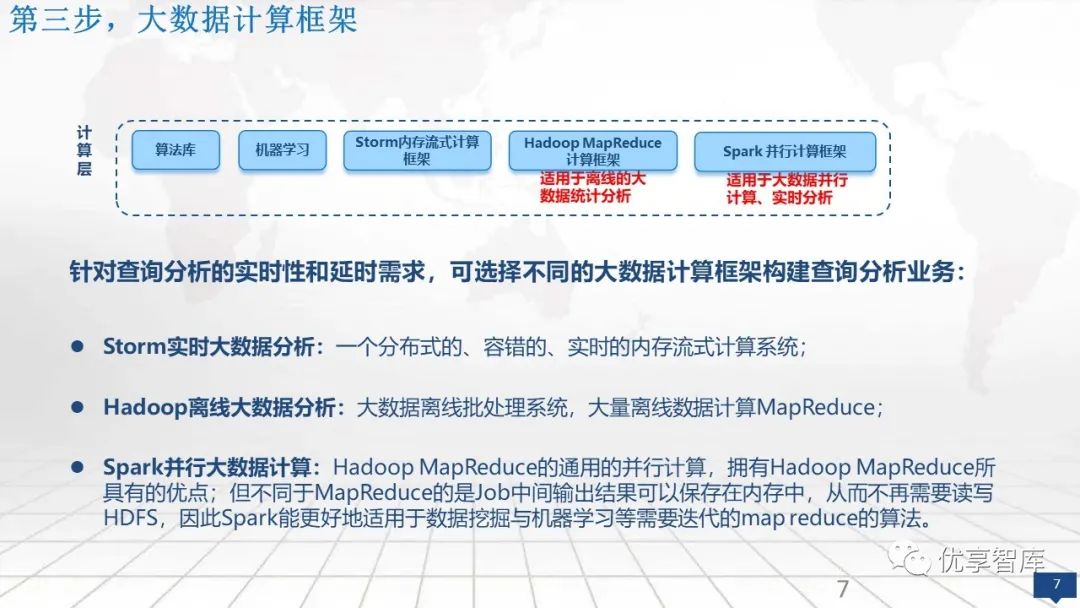
第三步,大数据计算框架
计算层可以根据用户的一些大数据统一查询分析的需求:
对于实时性要求很强的,延时要求很低的情况可以用内存的这种storm实时大数据分析。
对于并行的数据可以用spark的大数据计算。
第四步,大数据分析引擎
第四步大数据分析引擎,分为业务引擎和非业务引擎。
业务引擎是不同行业的业务数据,包括行业属性、不同行业算法和建模。
非业务数据是一些机器数据,像日志,设备产生的数据等这些冷数据,这些数据算法相对会固定一些。
最终分析出来的数据会给其他的一些持久层。做一些数据展现。
l行业属性 + 算法 = 业务数据分析引擎(帮助用户自动化分析大数据)
l基础设施数据引擎(机器数据引擎、日志数据引擎)
l行业业务属性决定计算的逻辑,计算数学是实现计算逻辑的方法(利用数学领域的算法和理论)
l数据分析不仅仅指运算数据,还包括全面了解数据分析所处的背景和环境
l数据分析结果可以保存在多种结构中
l数据也可以在不同的分布式集群之间进行传输、复制、同步
l数据分析结果可以通过多种展现形式(表格、各种展现图)进行数据展现

三、大数据平台应用案例解析





































 2873
2873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











