




 本文深入解析深度学习在房价预测和手写数字识别的应用,涵盖数据处理、模型设计、训练配置等关键步骤,强调数学原理与实践相结合的重要性。
本文深入解析深度学习在房价预测和手写数字识别的应用,涵盖数据处理、模型设计、训练配置等关键步骤,强调数学原理与实践相结合的重要性。
首先感谢百度飞浆为我提供这一次零基础实践深度学习的机会。
本次有房价预测和手写数字识别两个案例,以着重讨论房价预测并结合手写数字识别进行分析
分析案例过程及核心代码实现
数据处理
数据处理需经过读入数据、数据形状变换、划分测试集和训练集数据、归一化处理(MNIST已进行归一化)等步骤,而归一化的好处:
1、模型训练更高效。
2、特征前的权重大小可以代表该变量对预测结果的贡献度。
实现如下:
# 计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
模型设计
模型设计需实现Init()和forward()函数,Init()函数需确定权重w及偏执b,forward()函数则需要计算predict,以便计算Loss,采用线性回归公式即可:z=wx+bz = wx+bz=wx+b。针对手写数字识别则需卷积神经网络、softmax激活函数等。
代码如下:
class Network(object):
def __init__(self, num_of_weights):
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
训练配置
模型设计完后,需要通过训练配置寻找最优值,即采用Loss函数的指标来衡量模型的好坏,这里采用均方误差:Loss=(y−z)2Loss = (y-z)^2Loss=(y−z)2,而针对所有样本的Loss用平均值的描述更为准确:Loss=1N∑i=1N(y−z)2Loss = \frac{1}{N}\sum_{i=1}^\N(y-z)^2Loss=N1∑i=1N(y−z)2。
核心代码如下:
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
训练过程
找到一个参数解 w和b,使得损失函数取得极小值,基于微积分的知识,即函数的极值点是导数为0的点,解σLσw=0\frac{\sigma L}{\sigma w} = 0σwσL=0和σLσb=0\frac{\sigma L}{\sigma b} = 0σbσL=0的方程组,来求解参数w、b,但是一般只对线性回归这样简单的任务有效,当存在非线性变换时,则很难通过上式求解,所以会采用一种更加普适的数值求解方法:梯度下降法。
我理解的梯度下降法类似一种模拟,即一种向下试探的过程,满足Loss(w′,b′)<Loss(w,b)Loss(w',b') < Loss(w,b)Loss(w′,b′)<Loss(w,b),并且使得下降趋势尽可能的快,(按梯度反方向)反复以至求解得到最小的Loss,再反向求解参数 w和b。
公式如下(敲黑板):
-------------------------------------------------------------------------------------------------------------------
-->一个样本损失: Loss=12(yi−zi)2Loss = \frac{1}{2}(y_i-z_i)^2Loss=21(yi−zi)2
-->i= 1,z1展开:z1=x10w0+x11w1+...+x121w12+bz1 = x^0_1w_0+x^1_1w_1+...+x^12_1w_12+bz1=x10w0+x11w1+...+x121w12+b
-->带入损失函数:Loss=12(x10w0+x11w1+...+x112w12+b−y1)2Loss = \frac{1}{2}(x^0_1w_0+x^1_1w_1+...+x^{12}_1w_12+b-y_1)^2Loss=21(x10w0+x11w1+...+x112w12+b−y1)2
-->Loss对w和b进行求偏导:
σLσw0=(x10w0+x11w1+...+x121w12+b−y1)x10=(z1−y1)x10\frac{\sigma L}{\sigma w_0}=(x^0_1w_0+x^1_1w_1+...+x^12_1w_{12}+b-y_1)x^0_1=(z_1-y_1)x^0_1σw0σL=(x10w0+x11w1+...+x121w12+b−y1)x10=(z1−y1)x10
σLσw1=(z1−y1)x11\frac{\sigma L}{\sigma w_1}=(z_1-y_1)x^1_1σw1σL=(z1−y1)x11
σLσw2=(z1−y1)x12\frac{\sigma L}{\sigma w_2}=(z_1-y_1)x^2_1σw2σL=(z1−y1)x12
…
σLσw12=(z1−y1)x112\frac{\sigma L}{\sigma w_{12}}=(z_1-y_1)x^{12}_1σw12σL=(z1−y1)x112
σLσb=(x10w0+x11w1+...+x121w12+b−y1)=(z1−y1)\frac{\sigma L}{\sigma b}=(x^0_1w_0+x^1_1w_1+...+x^12_1w_12+b-y_1)=(z_1-y_1)σbσL=(x10w0+x11w1+...+x121w12+b−y1)=(z1−y1)
而存在大量样本数据时,再对σLσwj\frac{\sigma L}{\sigma w_j}σwjσL和σLσb\frac{\sigma L}{\sigma b}σbσL求平均值即可当成总梯度。
-------------------------------------------------------------------------------------------------------------------
核心代码如下:
def gradient(self, x, y):
z = self.forward(x)
gradient_w = (z-y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (z - y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
由房价预测到手写数字识别
上述的房价预测从数据处理、模式设计、训练配置、训练过程及模型保存的整个流程进行了分析,而针对 手写数字识别 这个不同的应用场景,其实也可以使用该框架以节省时间和成本,在其框架的基础上进行修改和优化,例如网络设计、损失函数、…、方面(具体手写数字识别的分析暂不),下面引用一张基于PaddlePaddle的课程图片:

而PaddlePaddle则是一个很好的深度学习框架,内置了许多数据集和模型库,所以在很大程度上基于该框架的使用,是可以节省大量的时间和成本的,许多内置API的接口也是经过优化的,这里贴一张PaddlePaddle开发组件:
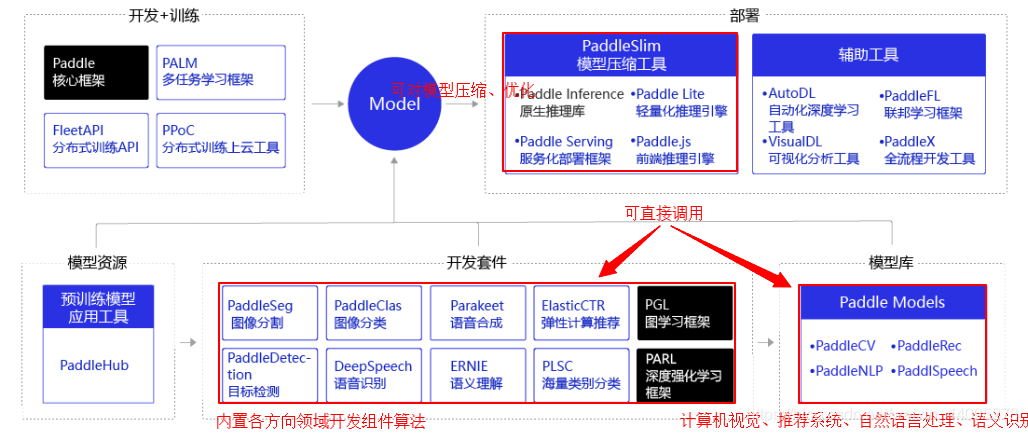
牛顿之所以伟大,是因为他站在巨人的肩膀上。
第一周学习心得体会
本次就好好说一下自己的心得体会和学习方法。
1、首先第一周的学习让我对深度学习的概念、架构以及处理方法有了一定深刻且全面的理解认识。
2、而大多数应用场景均可采用数据处理、模型设计、训练配置、训练过程、模型保存这五步法,基于该框架再去修改细节代码、不断调优,这也就是我们需要使用PaddlePaddle、Tf2等原因,站在巨人的肩膀上,我们也能成为伟人。
3、体会较深的应该是实践,依据项目的整套分析流程,从中学习项目拆解,再到每一步的分析、构思、数学原理以至最后形成代码进行封装,从而让自己在一定程度上拥有了这一整套的逻辑分析思维。
4、最后数学很重要!!!(高数、线性代数、概率论、统计学…)。
大爷给个赞再走呗!

















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









