







前言
在深度学习任务中,我们通常会定义一个损失函数,其表征的是预测值与实际值的差距,然后通过一定的优化算法来减少损失函数计算出来的损失值
在这个优化环节上,算法起到了至关重要的作用,我们需要通过算法来快速降低我们的训练误差,同时还要防止过拟合现象的出现
在深度学习中挑战
在深度学习中,优化各个参数其实就是对损失函数求最小值。
而我们在一个二次函数中,很明显就能知道哪个是最小值
但是深度学习中,特征数多,构造的计算公式复杂,导致我们的函数并不能从直观的角度来得到最小值,更多的是我们求得一个数值解,即在一定范围内它是最小值,但不能保证在全局上是最小值
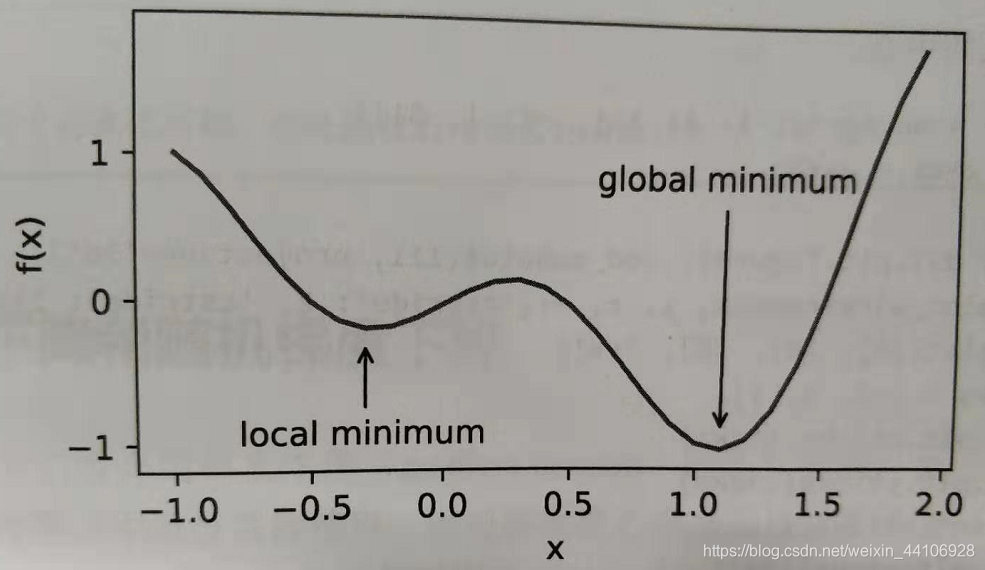
另外一个则是鞍点的问题
前面我们提到特征多,总的图形是一个多维的
现在我们来考虑一个简单的三维模型
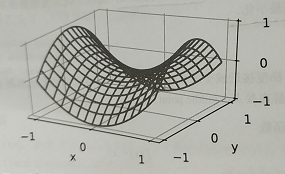
如果此时我们函数停在(0,0, 0)这个点
这个点沿着x轴方向确实是最小值了
但是在Y方向上仍然可以进行优化
这仅仅只是三维的情况
深度学习中常常是高维的
所以出现鞍点的概率常常比落在局部最小值的情况更常见
这篇博文基于动手学深度学习书上的例子,加上一定的公式推导来阐述各个优化算法的思想
梯度下降
可以说各个优化算法的基础都是梯度下降法
下面进行一下公式的推导

我们以y = x^2来作为例子进行梯度优化,代码来自动手学深度学习
%matplotlib inline
import d2lzh as d2l
import math
from 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3236
3236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









