







用于精确场景文本检测的序列变形模块
一、引言
- 文本作为一个整体是同构的,其中一个文本实例由相似的组件组成。因此,一些方法预测的是文本组件,而不是整个文本实例。但错误的组件预测可能会让错误传播,而且缺乏端到端的优化。
- 标准卷积的接收域固定,对大的几何变换处理能力有限,使得其性能和泛化能力大打折扣。
受上述观察结果的启发,文章提出了一种端到端的可训练序列变形模块(SDM),用于精确的场景文本检测,该模块利用文本的同质性,有效地扩展了文本几何配置的建模能力,并沿着文本行学习信息丰富的实例级语义表示。通过按顺序的方式进行采样,可以获得比标准卷积层更大的有效接收域。然后,SDM通过对所有采样特征加权求和来聚合特征,获取自适应的实例级表示。
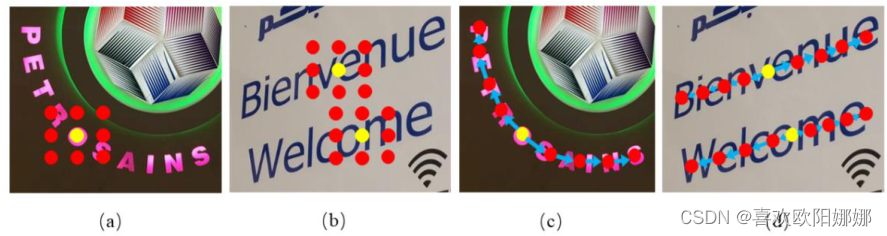
此外,文章引入了一种辅助的字符计数监督(ACC)来指导SDM的序列偏移预测。将字符计数任务建模为一个序列对序列的问题,计数网络接收所有采样的特征,期望预测出一个特定长度的有效序列,该长度等于相应文本实例的字符数。额外的字符级监督同时允许网络学习通用特征。
论文的主要工作有三个方面:1. 提出了一种新颖的端到端序列变形模块SAM,用于精确检测任意形状的场景文本,该模块自适应增强了文本几何配置的建模能力,并学习了实例级语义表示;2. 引入了一种辅助的字符计数监督ACC,以促进序列偏移预测和通用特征的学习;3. 将序列变形模块和辅助字符计数集成到Mask R-CNN中,采用端到端多任务方式优化网络,无需进行复杂的分组后处理。
二、相关工作
实例级检测方法
这一类方法将文本实例视为特定类型的对象。这些方法在标准基准上取得了出色的性能,但面临着CNN接受域有限和不能进行几何变换等问题。
组件级方法
利用文本的同质性,将实例分解为组件,解决了实例级建模面临的问题。这些方法需要进行分组后处理,错误分量预测的误差传播和缺乏端到端训练会损害鲁棒性。
空间变形方法
使网络能够自适应地捕获几何变换。
序列变形模块
基于文本的同质性,我们提出了序列变形模块和辅助字符计数监督来有效地解决现有检测方法存在的问题。该模块为文本量身定制,可以序列预测采样位置,并适当感知整个文本实例。辅助字符计数监督进一步辅助序列采样和信息特征表示。
三、方法论
3.1序列可变形模块SDM
由于固定接收域和文本实例的形状和大小不匹配,标准卷积在场景文本检测中存在不足。
- 为了捕获整个实例,需要固定的矩形接收域完全覆盖文本的外接矩形,但这样又会包含许多不需要的背景信息;
- 固定大小的接受域不能很好地提取具有不同尺度和宽高比的实例的表示,导致不精确的分类和回归。
为了解决上述问题,可以检测空间更小、几何变换更少的文本分量。SDM首先按序列进行采样,然后像标准卷积一样,通过对所有采样特征加权求和进行特征聚合,获取自适应的实例级表示。
SDM与可变性卷积的区别:
1、可变形卷积从固定的规则网格中增加采样位置,因此更适用于形状与网格大致相同的物体(如方形)的模型几何变换。相比之下,SDM生成采样路径,并有效地对线条形状的对象(如文本)进行建模转换。
2、可变形卷积在单次前向传播中预测偏移量,因此变形受到相对较小的接收场的限制,而SDM通过偏移量积累可以显著扩大其采样范围。
定义
- SDM的输入为 x x x,输出为 y y y, x ( p ) x(\boldsymbol{p}) x(p)表示在位置p处的输入
- d d d:方向。对于每个起始点,应当沿两个方向进行采样,因此用下标 d d d来表示, d = 1 , 2 d=1,2 d=1,2
- T:采样数,是一个超参数
- p d , t \boldsymbol{p_{d,t}} pd,t:在位置 p \boldsymbol{p} p处沿方向 d d d的第 t t t个采样位置
- p d , t + 1 = p d , t + Δ p d , t , t = 0 , 1 , ⋅ ⋅ ⋅ , T − 1 ; d = 1 , 2 \boldsymbol{p_{d,t+1}}=\boldsymbol{p_{d,t}}+\Delta \boldsymbol{p_{d,t}}, \quad t=0,1,···,T-1;d=1,2 pd,t+1=pd,t+Δpd,t,t=0,1,⋅⋅⋅,T−1;d=1,2
- p d , 0 = ( 0 , 0 ) \boldsymbol{p_{d,0}=(0,0)} pd,0=(0,0)
- 采样区域 S d = { p d , t ∣ d = 1 , 2 ; t = 0 , 1 , ⋅ ⋅ ⋅ , T − 1 } S_d=\{\boldsymbol{p_{d,t}}|d=1,2;t=0,1,···,T-1\} Sd={pd,t∣d=1,2;t=0,1,⋅⋅⋅,T−1}
偏置 Δ p d , t \Delta \boldsymbol{p_{d,t}} Δpd,t的学习
采用RNN+线性层(全卷积层)来学习;在每一个方向上都有这样一个网络来学习偏置。
Δ
p
d
,
t
\Delta \boldsymbol{p_{d,t}}
Δpd,t由当前及先前采样的特征得到,即:
h
d
,
t
=
R
N
N
d
(
h
d
,
t
−
1
,
x
(
p
+
p
d
,
t
)
)
,
Δ
p
d
,
t
=
L
i
n
e
a
r
d
(
h
d
,
t
−
1
)
h_{d,t}=RNN_d(h_{d,t-1},x(\boldsymbol{p}+\boldsymbol{p_{d,t}})),\\ \Delta \boldsymbol{p_{d,t}}=Linear_d(h_{d,t-1})
hd,t=RNNd(hd,t−1,x(p+pd,t)),Δpd,t=Lineard(hd,t−1)
得到输出的结果
m
(
p
)
=
C
o
n
c
a
t
(
{
x
(
p
+
p
d
,
t
)
∣
d
=
1
,
2
;
t
=
1
,
2
,
⋅
⋅
⋅
,
T
}
∪
{
x
(
p
)
}
)
,
y
(
p
)
=
C
o
n
v
1
×
1
(
m
(
p
)
)
m(\boldsymbol{p})=Concat(\{ x(\boldsymbol{p}+\boldsymbol{p_{d,t}})|d=1,2;t=1,2,···,T\}\cup \{x(\boldsymbol{p})\}),\\ y(\boldsymbol{p})=Conv_{1\times 1}(m(\boldsymbol{p}))
m(p)=Concat({x(p+pd,t)∣d=1,2;t=1,2,⋅⋅⋅,T}∪{x(p)}),y(p)=Conv1×1(m(p))
如果
x
x
x的通道数为
C
C
C,则
m
m
m的通道数为
(
2
T
+
1
)
C
(2T+1)C
(2T+1)C。
3.2辅助字符计数监督ACC
在许多常见的数据集中,提供了文本标签,可以由文本标签方便地得到字符个数标签。文本识别任务的搜索空间较大,需要更多的训练样本,通过将文本识别减少到字符数,能够大大减少搜索空间,优化更加容易,并且可以直接在真实数据集上训练模型,而无需任何额外的大规模合成数据集或预先训练的识别模型。
因此可以考虑用字符个数做监督,这同时使模型能够学习字符级语义信息。
字符计数监督的输入:
{
x
(
p
+
p
d
,
t
)
∣
d
=
1
,
2
;
t
=
1
,
2
,
⋅
⋅
⋅
,
T
}
\{x(\boldsymbol{p}+\boldsymbol{p_{d,t}})|d=1,2;t=1,2,···,T\}
{x(p+pd,t)∣d=1,2;t=1,2,⋅⋅⋅,T}
基于seq2seq的模型期望预测出一个具有特定长度的有效序列,该长度等于对应文本实例的字符数。
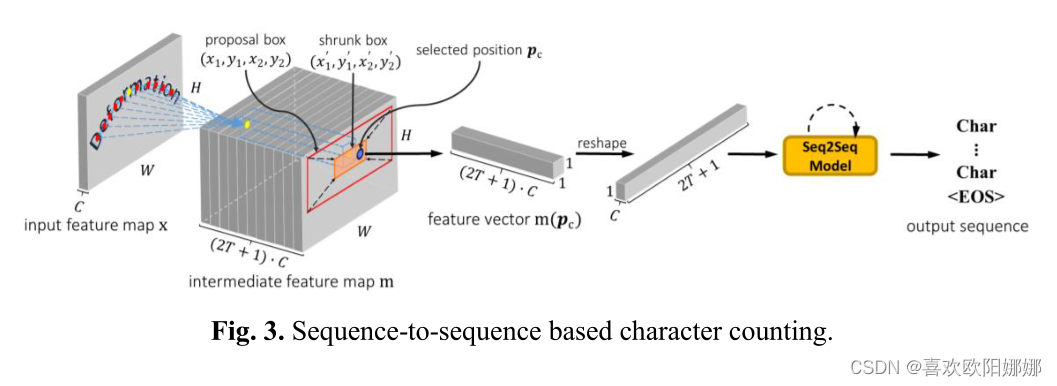
在这项工作中,SDM集成在Mask R-CNN中,SDM被插入到区域建议网络(RPN)之前,因此有效的方案是采用RPN中正建议框中心区域周围的特征向量作为训练样本。
实现步骤
- 我们首先计算所有建议的前景/背景分配,并从所有正例中随机选取K个建议。
- 对于选中的正例检测框 ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2)进行中心收缩,比例为 σ \sigma σ。收缩后的检测框位于提议框的中心区域,因此有更高的概率检测到全局存在的文本实例。
- 在收缩的框中随机选取一个初始点 p c \boldsymbol{p_c} pc,以此得到特征向量 m ( p c ) m(\boldsymbol{p_c}) m(pc);然后,对 m ( p c ) m(\boldsymbol{p_c}) m(pc)进行尺度变换,使其成为长为 2 T + 1 2T+1 2T+1,通道数为 C C C的序列,组成一个用于字符计数的训练样本。
- 最后,利用一种轻型单层转换器预测字符数,并在每个时间步对4个符号进行分类,包括序列开始符号“SOS”、序列结束符号“EOS”、填充符号“PAD”和一个“Char”符号。“Char”符号表示一个字符的存在。
- 接收一个“”符号和重构后的 m ( p c ) m(\boldsymbol{p_c}) m(pc)后,模型将目标序列s的对数概率最大化。
- s s s由连续的“Char”符号组成,其数量等于对应文本实例的字符数,以“EOS”符号结束。
- 计数损失为: L c n t = l o g p ( s ∣ r e s h a p e ( m ( p c ) ) ) L_{cnt}=log{p(s|reshape(m(\boldsymbol{p_c}))}) Lcnt=logp(s∣reshape(m(pc)))
- 通过强制网络在每一步区分不同的字符,辅助计数任务可以简单地扩展到场景文本识别任务。这可以为检测带来较大的改进,并可用于端到端单阶段的文本定位。作者计划在未来的工作中研究这种方法。
3.3集成SDM的Mask R-CNN
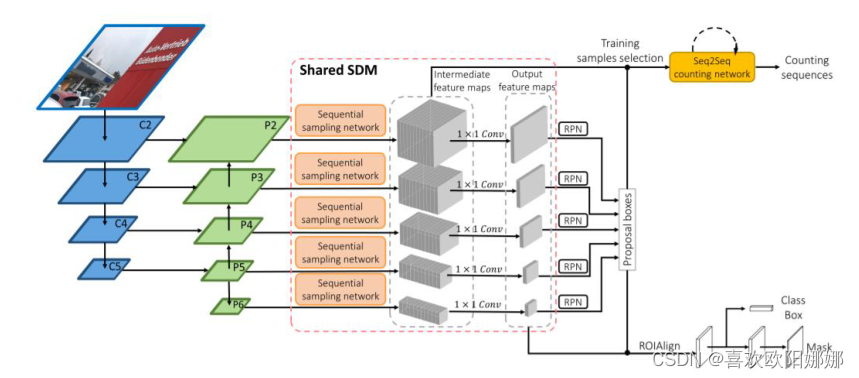
SDM被插入到RPN和FPN之间,在不同级别之间共享。
- 在第 i i i个层次,一个建议框通过对应的第 i i i个中间层特征 m i m_i mi取得计数训练样本;
- seq2seq字符技术网络在不同层次的特征之间共享;
- RoIAlign层从SDM的输出特征中提取区域内特征。
- 总的损失函数 L = L c l s + L b o x + L m a s k + γ L c n t L=L_{cls}+L_{box}+L_{mask}+ \gamma L_{cnt} L=Lcls+Lbox+Lmask+γLcnt
四、实验结果
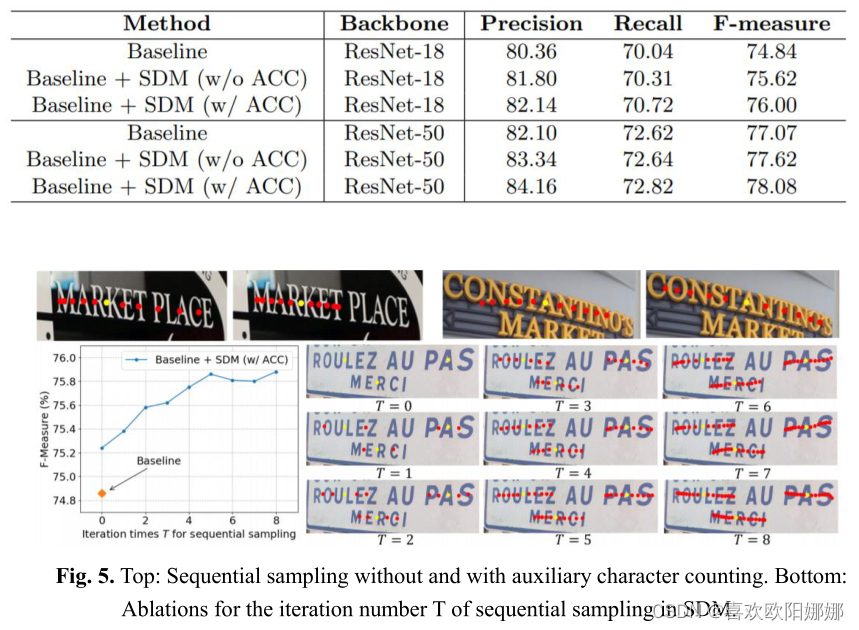
- 对于迭代次数而言,从图5中可见,即便 T = 0 T=0 T=0,模型也会取得一定的增益,因此作者认为ACC模块从本质上说对文字检测是有益的。
- 从图7的可视化可以清楚地看出:1)采样范围会自动扩大和缩小,以适应不同的实例。同时,如果起始位置偏离文本中心区域,一个采样分支会扩大步长到达相应的端点,而另一个采样分支会缩短步长以避免走出实例;2)对于更具挑战性的曲线文本,SDM仍然能够胜任捕捉曲线形状;3)即使从文本区域之外的起始位置开始,SDM也会尝试遵循文本中心线。这意味着SDM会对自身进行动态校准,尽可能获取文本实例,具有较高的适应性和鲁棒性,丰富了CNN对几何变换建模的能力。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









