










基于用户画像的商品推荐挑战赛baseline
一、赛事背景
讯飞AI营销云基于深耕多年的人工智能和大数据技术,赋予营销智慧创新的大脑,以健全的产品矩阵和全方位的服务,帮助广告主用AI+大数据实现营销效能的全面提升,打造数字营销新生态。

评估指标:

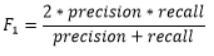
最简单的baseline:
import pandas as pd
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from pylab import *
from sklearn.preprocessing import OneHotEncoder
## 模型预测的
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import accuracy_score,f1_score,roc_auc_score,recall_score,precision_score
train = pd.read_csv('dataset/train.txt',header = None)
test = pd.read_csv('dataset/apply_new.txt',header = None)
submit = pd.read_csv('submit_sample.csv')
col = ['pid','label','gender','age','appid','time','province','city','make','model']
col_test = ['pid','gender','age','appid','time','province','city','make','model']
train.columns = col
test.columns = col_test
df = pd.concat([train,test]) #合并train和test,并且用is_train进行标记
df
df['appid_nunique'] = df.loc[:,['appid']]['appid'].apply(len)
df['time_nunique'] = df.loc[:,['time']]['time'].apply(len)
df.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
df.fillna(0, inplace=True)
train_data = df[df['label'] != 2]
test_data = df[df['label'] == 2]
onehotencoder = OneHotEncoder()
province_oht_train = pd.get_dummies(train_data[['province']])
province_oht_test = pd.get_dummies(test_data[['province']])
train_data = pd.merge(train_data,province_oht_train,left_index=True, right_index=True,how='inner')
test_data = pd.merge(test_data,province_oht_test, left_index=True, right_index=True,how='inner')
col = ['pid','appid','time','province','city','make','model']
df_train = pd.DataFrame()
for c in train_data.columns:
if c not in col:
df_train[c] = train_data[c]
col = ['pid','label','appid','time','province','city','make','model']
df_test = pd.DataFrame()
for c in test_data.columns:
if c not in col:
df_test[c] = test_data[c]
X_train = df_train[df_train['label'].notnull()].drop(['label'],axis=1)
Y_train = df_train[df_train['label'].notnull()]['label']
x_train,x_val,y_train,y_val = train_test_split(X_train,Y_train,test_size=0.3)
def build_model_xgb(x_train,y_train):
model = xgb.XGBClassifier(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
auc = roc_auc_score(y_val,val_xgb, average='macro')
print('auc with xgb:',auc)
p = precision_score(y_val,val_xgb, average='macro')
print('precision with xgb:',p)
R = recall_score(y_val,val_xgb, average='macro')
print('recall with xgb:',R)
#auc with xgb: 0.60756207427427
#precision with xgb: 0.6084775623548617
#recall with xgb: 0.60756207427427
sub = pd.DataFrame()
sub['user_id'] = test.pid
sub['category_id'] = test_xgb
sub.to_csv('submit0624.csv',index = False)
好多天没做了,争取上分!!!















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









