






大数据需要存储的数据比较多,如果直接存储原始数据,将会占用较多的硬盘空间,于是就有了存储方式和压缩方式,以一定的算法降低数据占用的空间,并且保证数据不丢失,从而提高空间的利用率。
1.存储格式定义
1.1单行/列式存储
所谓行式存储,指存储结构化数据时,在底层的存储介质上,数据是以行的方式来组织的,即存储完一条记录的所有字段,再存储下一条数据的全部字段,即:行式存储的情况下,每一行的数据都是连续存储的。它适用于个体或事件场景的存储,称为OLTP(Online Transaction Processing)。
所谓列式存储,指存储结构化数据时,在底层的存储介质上,数据时以列的方式来组织的,即存储完若干条记录的首个字段后,再存储这些记录的第二个字段,然后是这些记录的第三个字段,当这些记录的所有字段存储完毕后,再按照这种方式,组织存储下一批若干条记录的所有字段。它适用于数据的统计和分析常见存储,称为OLAP(Online Analytical Processing)。
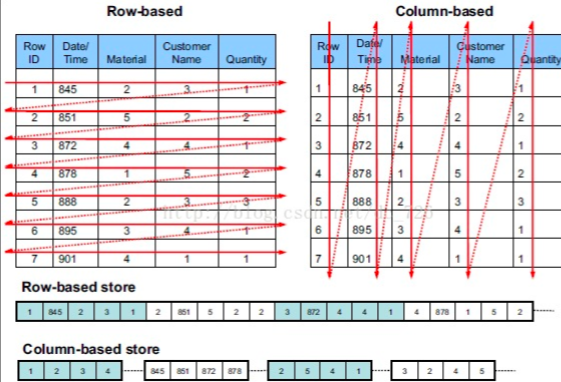
行列式存储示意图
1.2混合行列式存储
混合存储又称行列混合存储,TP 和 AP 仰赖不同的存储格式:行存对应 OLTP,列存对应 OLAP,混合存储简单理解就是AP+TP混合存储。
OLTP需要处理涉及频繁写操作的事务型查询,OLAP侧重于处理涉及大量读操作的分析型查询。列存储在读操作中有较大的优势,适合OLAP查询,但不适合OLTP查询。
1.3行列式存储比较
| 行式存储 | 列式存储 |
|---|---|
| 因为按行写和读取数据,因此读取数据时往往需要读取那些不必要的列。 | 特别适合分析时只查询部分列的场景,因为不需要扫描/读取不需要查询的列。 |
| 易于按记录读写数据,适合数据有频繁更新的场景 | 列存储由于数据更新成本较高,一般适合读多写少的场景。 |
| 适合 OLTP 系统 | 适合 OLAP 系统 |
| 不利于大数据集的聚合统计操作 | 利于大数据集的数据聚合操作 |
| 一行中各字段数据类型不同的概率较大,压缩率更低 | 由于连续存储在一起的列的数据类型都一样,所以数据压缩率更高,更省存储空间 |
1.4常见存储格式
1、Parquet文件
Parquet 是一种开源的面向列存存储的文件格式,它提供各种存储优化,尤其适合数据分析。Parquet提供列压缩从而可以节省空间,它提供按列读取,而非整个文件地读取。数据写到Parquet以便长期存储,因为从Parquet文件读取始终比从JSON文件或CSV文件效率更高。Parquet的另一个优点是它支持复杂类型,也就是说如果列是一个数组,map映射或struct结构体,仍可以正常读取或写入,不会出现任何问题。
Parquet 主要使用场景在Impala和Hive共享数据和元数据的场景。
2、ORC文件
ORCFile是RCFile的优化版本,hive特有的数据存储格式,存储方式为行列存储,具体操作是将数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引,自身支持切片,数据加载导入方式可以通过INSERT方式加载数据。
支持两种压缩ZLIB和SNAPPY,其中ZLIB压缩率比较高,常用于数据仓库的ODS层,SNAPPY压缩和解压的速度比较快,常用于数据仓库的DW层相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
3、TextFile
TextFile 是 Hive 默认文件存储方式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大,数据不支持分片,数据加载导入方式可以通过LOAD和INSERT两种方式加载数据。
结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用gzip方式,hive不会对数据进行切分,从而无法对数据进行并行操作,但压缩后的文件不支持split。在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
TEXTFILE主要使用场景在数据贴源层 ODS 或 STG 层,针对需要使用脚本load加载数据到Hive数仓表中的情况。
4、SequenceFile
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。
Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值,这样是为了避免MR 在运行map 阶段的排序过程。
5、AVRO
AVRO,是指数据序列化的系统,有丰富的数据结构类型、快速可压缩的二进制数据形式。它可以提供:
1、 丰富的数据结构类型
2 、快速可压缩的二进制数据形式
3、存储持久数据的文件容器
4 、远程过程调用RPC
5 、简单的动态语言结合功能,Avro和动态语言结合后,读写数据文件和使用RPC协议都不需要生成代码,而代码生成作为一种可选的优化只值得在静态类型语言中实现
2.压缩格式定义
2.1 压缩格式定义及意义
大数据中常见的压缩方式常用的有Deflate,Snappy,ZLib,Gzib、Bzip2、LZ4、LZO,不同的压缩方式效率不同。
(1) 从压缩比来说,Bzip2 > ZLib > Gzip > deflate > Snappy,除了Snappy之外的压缩方式可以保证最小的压缩,但是在运算过程中时间消耗较大。
(2)从压缩性能上来说, Snappy > Deflate > Gzip > Bzip2,其中,Snappy压缩和解压缩速度快,压缩比低。通常生产环境中,经常会采用snappy压缩,以保证运算效率。
压缩方式的选择主要是由压缩比、压缩速度、是否支持分片来决定的。另外,因为压缩比和压缩速度是成反比的,所以比较了压缩比实际上也就比较了压缩速度。
| 压缩格式 | 原始文件大小(byte) | 压缩文件大小(byte) | 压缩时间(ms) | 解压时间(ms) | 最大CPU(%) |
| bzip2 | 35984 | 8677 | 11591 | 2362 | 29.5 |
| gzip | 35984 | 8804 | 2179 | 389 | 26.5 |
| deflate | 35984 | 9704 | 680 | 344 | 20.5 |
| lzo | 35984 | 13069 | 581 | 230 | 22 |
| lz4 | 35984 | 16355 | 327 | 147 | 12.6 |
| snappy | 35984 | 13602 | 424 | 88 | 11 |
2.2 常见的压缩格式
1、 GZIP
gzip的实现算法还是deflate,只是在deflate格式上增加了文件头和文件尾,同样jdk也对gzip提供了支持,分别是GZIPOutputStream和GZIPInputStream类,同样可以发现GZIPOutputStream是继承于DeflaterOutputStream的,GZIPInputStream继承于InflaterInputStream,并且可以在源码中发现writeHeader和writeTrailer方法。
优点:压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split
2、 LZO
LZO是致力于解压速度的一种数据压缩算法,LZO是Lempel-Ziv-Oberhumer的缩写,这个算法是无损算法。
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便
缺点:压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)
3、SNAPPY
Snappy(以前称Zippy)是Google基于LZ77的思路用C++语言编写的快速数据压缩与解压程序库,并在2011年开源。它的目标并非最大压缩率或与其他压缩程序库的兼容性,而是非常高的速度和合理的压缩率。
优点:压缩速度快;支持hadoop native库。
缺点:不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令
4、 BZIP2
bzip2是Julian Seward开发并按照自由软件/开源软件协议发布的数据压缩算法及程序。Seward在1996年7月第一次公开发布了bzip2 0.15版,在随后几年中这个压缩工具稳定性得到改善并且日渐流行,Seward在2000年晚些时候发布了1.0版。bzip2比传统的gzip的压缩效率更高,但是它的压缩速度较慢。
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
5、LZ4
LZ4是一种无损数据压缩算法,着重于压缩和解压缩速度。
6、Deflater
DEFLATE是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个无损数据压缩算法,DEFLATE压缩与解压的源代码可以在自由、通用的压缩库zlib上找到。zlib官网:http://www.zlib.net/ ,jdk中对zlib压缩库提供了支持,压缩类Deflater和解压类Inflater,Deflater和Inflater都提供了native方法。
2.3 数据分层的压缩方式选择
根据每个数据分层的作用,选择不同的压缩方式,从而提高执行的效率;
(1)ODS层(源数据层)适合ZLIB、GZIP和BZIP2的压缩方式,该层需要存储较多的数据,所以选择压缩比较高的压缩方式,可以节省空间,从而存储更多的数据。
(2)DW层(数据仓层)和DA(数据应用层)层适合Snappy压缩方式,这两层数据的查询较为频繁,数据存储量不大,所以适合压缩和解压缩效率较高的Snappy压缩方式。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









