







 本文深入探讨Transformer模型,重点解析Attention机制,包括QKV矩阵、multi-head Attention及位置编码,阐述其在Encoder-Decoder框架中的作用,并提供部分代码实现。
本文深入探讨Transformer模型,重点解析Attention机制,包括QKV矩阵、multi-head Attention及位置编码,阐述其在Encoder-Decoder框架中的作用,并提供部分代码实现。
一文读懂「Attention is All You Need」
1. 介绍
核心Transformer,下面我们介绍下Transformer
2. 模型架构
Transformer的抽象结构图

Transformer内部是encoder-decoder框架。
2.1 模型框架
每一个Transformer结构,由6个encoder和decoder构成。最后一个encoder连接到各个decoder。
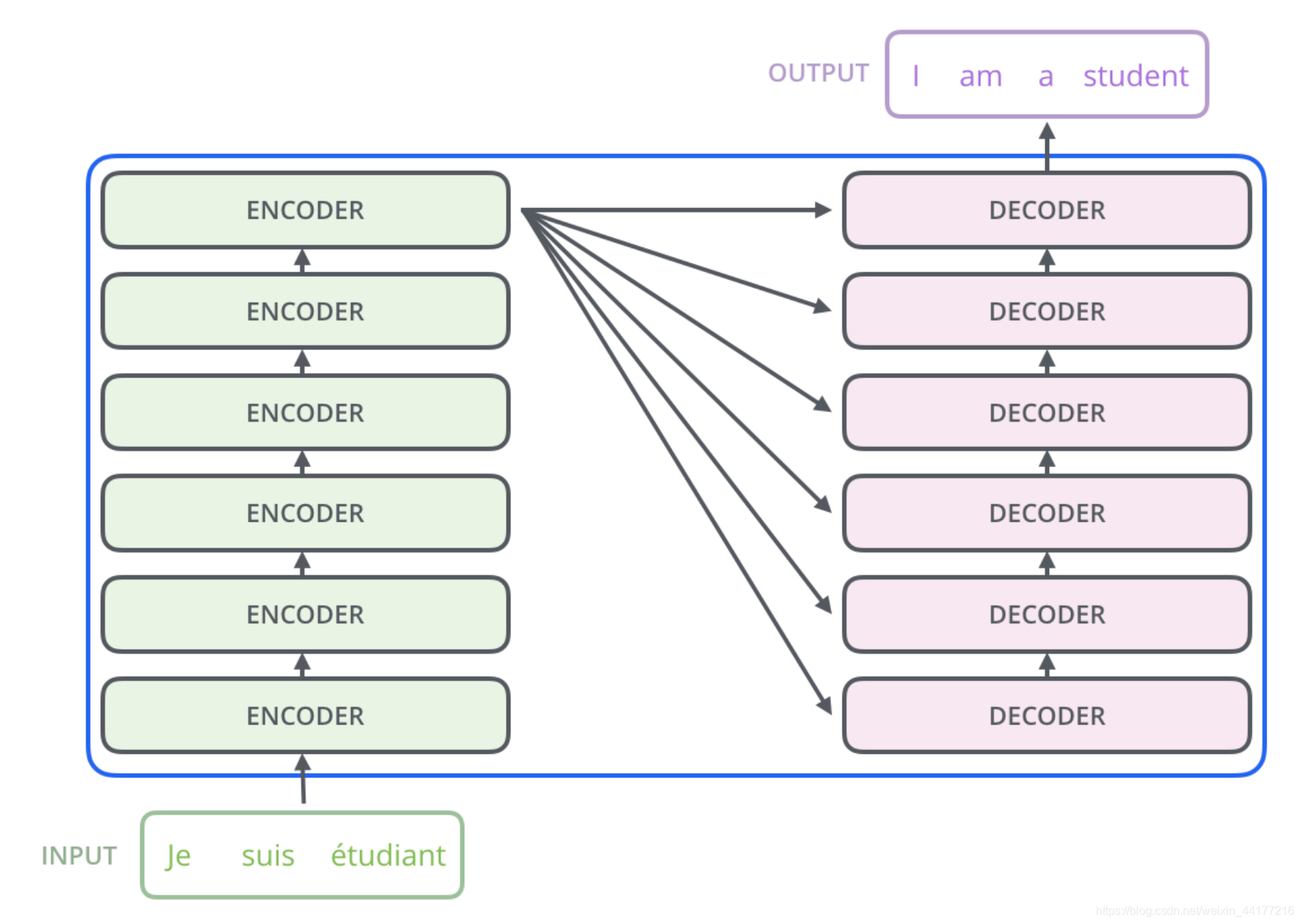
展开后如下图,其中N=6

transformer中decoder和encoder的内部网络结构
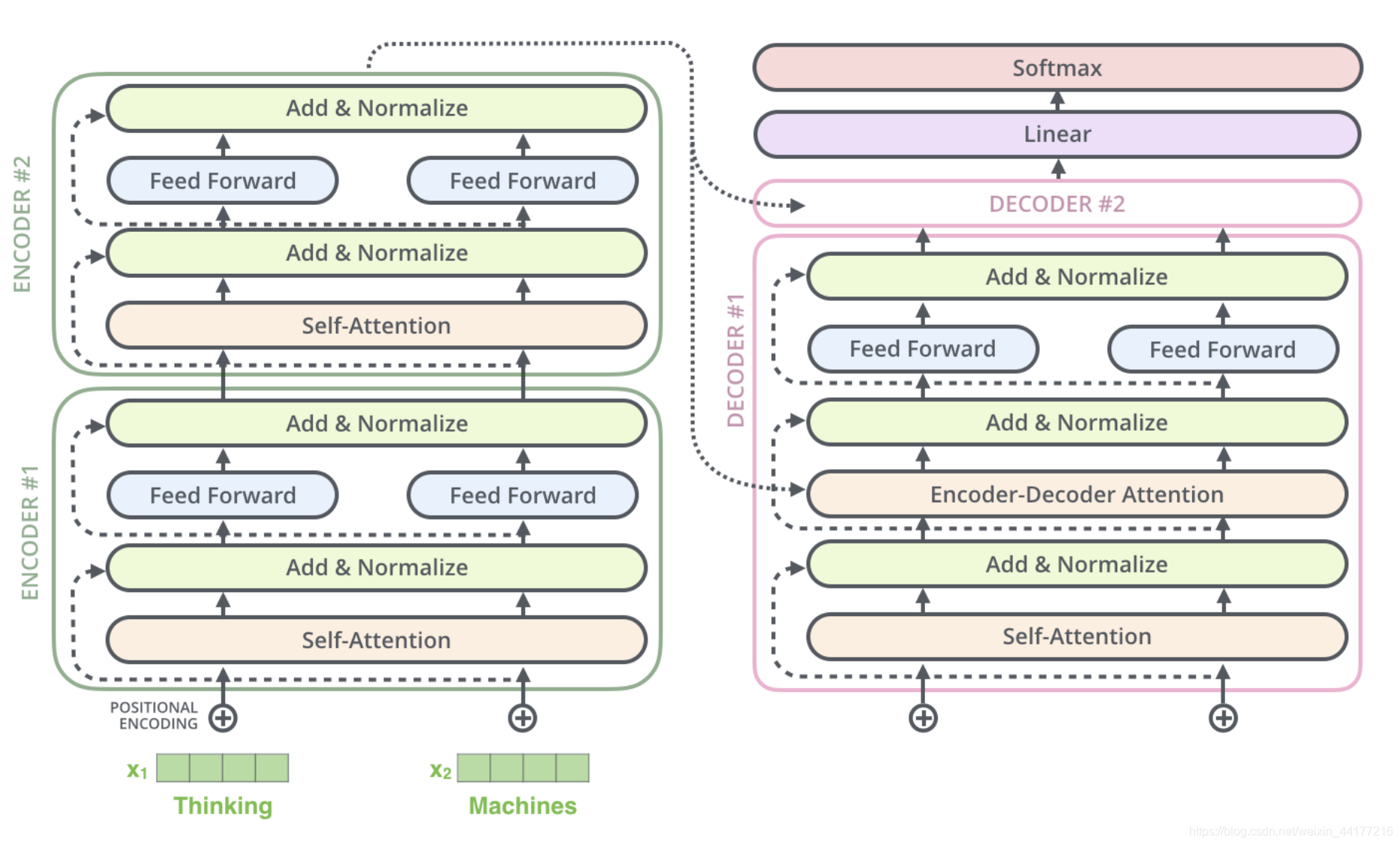
Encoder input X = ( x 1 , x 2 . . . x n ) Decoder output Y = ( y 1 , y 2 . . . y n ) o u t p u t {\text{Encoder input }} X=(x_{1}, x_{2}...x_{n}) \\ {\text{Decoder output }} Y=(y_{1}, y_{2}...y_{n}) \\ output Encoder input X=(x1,x2...xn)Decoder output Y=(y1,y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









