







 对比学习是一种无监督学习方法,通过使正样本相似、负样本远离来解决问题。从2018年的Inst disc、CPC到双雄格局的MOCO、SimCLR,再到简化版的BYOL和SimSiam,以及Transformer的应用,如MOCO v3和DINO,不断解决训练稳定性和效率问题,逐渐逼近有监督学习的效果。
对比学习是一种无监督学习方法,通过使正样本相似、负样本远离来解决问题。从2018年的Inst disc、CPC到双雄格局的MOCO、SimCLR,再到简化版的BYOL和SimSiam,以及Transformer的应用,如MOCO v3和DINO,不断解决训练稳定性和效率问题,逐渐逼近有监督学习的效果。
对比学习
介绍
对比学习是一种由有监督的思路去解决无监督的问题的一种方法。主流的思路是将一个样本进行变换,变换后的样本为正样本,样本集中其他样本及其他样本的变换定义为负样本。然后让正样本尽可能相似,与负样本尽可能远。
发展史
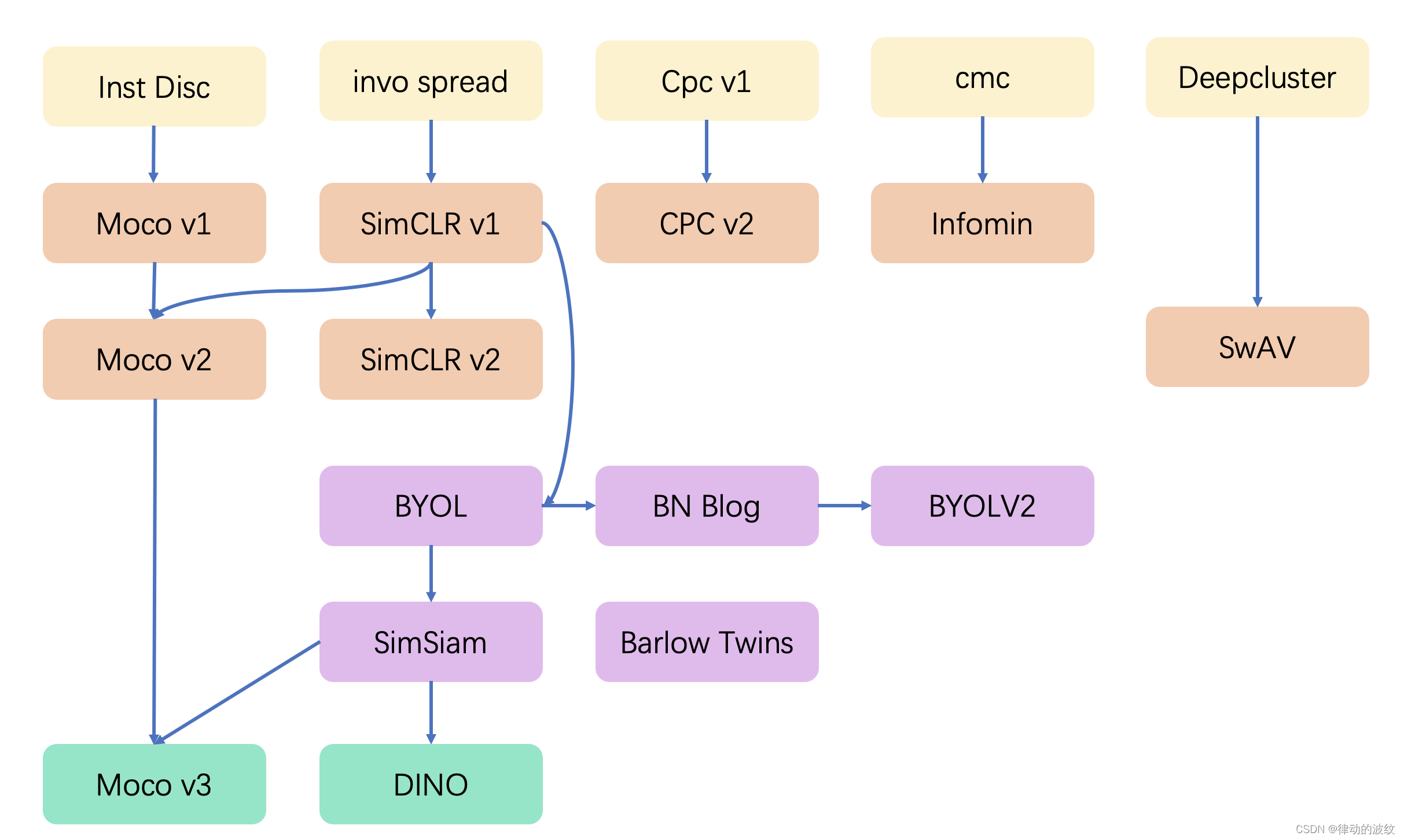
梳理下发展史,不同算法的有点等待梳理下。对这个图进行了解,就能对整个对比学习的发展核心节点和方向有一个初步的概念。
从18年开始,整个对比学习分成4个阶段,
- 争相斗艳。代表作有instdis、cpc、cmc等。这个阶段方法模型、目标函数、代理任务都未统一。
- 双雄割据。代表作有MOCO v1、SimCLR v1、 MOCO v2、SimCLR v2、 SwAV等。这个阶段非常卷, imagenet分数每个月都被刷新。
- 化繁为简。代表作BYOL、SimSiam。BYOL提出不使用负样本,SimSiam把所有方法都归纳总结,融入到该框架中。
- Transformer。代表作MOCO v3、DINO。主要是解决vision transformer训练不稳定的问题。
争相斗艳
Inst disc(2018)
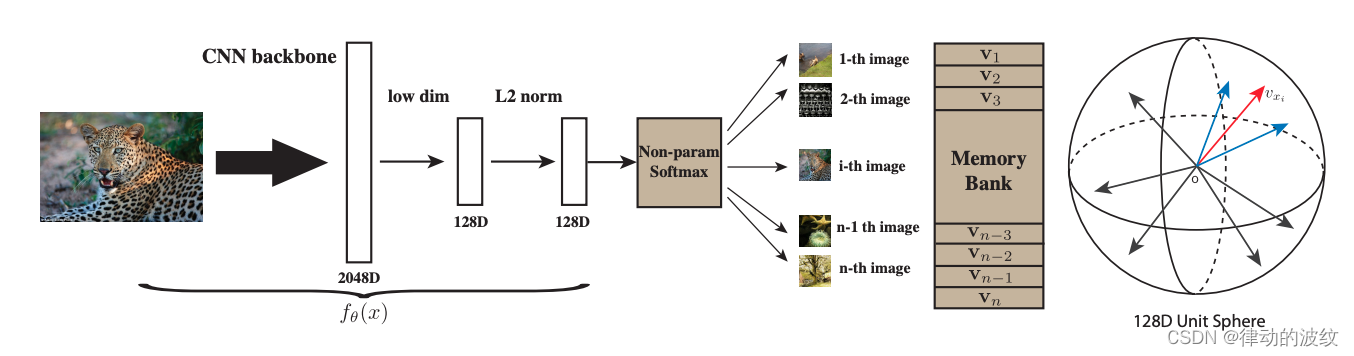
对比学习正样本是同一图片,负样本是其他所有图片,对ImageNet数据来说有128万的负样本。
- 个体判别的代理任务
通过个体的特征来进行特征空间的区分。算法将一个图片通过cnn表示成一个128维的特征,使得图片特征在特征空间里尽可能分开,相同标签的尽量近,不同标签尽量远。 - memory bank
这个学习过程中,需要大量的负样本,而算法结构中很难使用所有的负样本。因此作者提出使用外部存储memory bank。算法使用的batch size是256,有256个正样本,负样本从memorybank中随机抽取4096个。得到新的特征后,再去更新到memory bank。 - NCE loss。把多分类问题,变成一个二分类问题。
- 负样本动量更新,提升了算法的稳定性。
InvaSpread(2019)
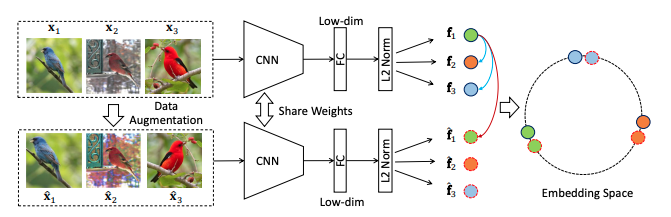
- 使用了数据增强,图片和其增强数据为正样本,其他图片及其增强为负样本。
- 没有使用额外结构存储负样本,正负样本来自同一个minibatch。这样造成一个缺点就是负样本不足,导致整体的效果不佳。
- 使用同一个编码器。原始图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









