







文章目录
一、PCA相关资源
网上讲解PCA的资源很多,讲的好的也很多,我的数学基础也不比在座的各位高到哪里去,就不班门弄斧了。下面得这篇知乎高赞很值得推荐:
【机器学习】降维——PCA(非常详细)
那我为什么还要再搞一篇博客呢?大概有以下几个原因吧:
- 别人的终究是别人的,自己写出来才是自己的,所以这篇博客更多是写给自己看的。但我尽量让看到这篇博客的人在看完我推荐的网页能够看懂这篇博客。既然写出来肯定有我自己的东西在里面。
- 补充一些使用PCA的原因。
- 表现的形式会跟推荐得资源里面不同,具体的后面再看吧。
二、使用降维算法的原因
1.去除观测变量之间的相关性
只考虑最简单的线性回归:
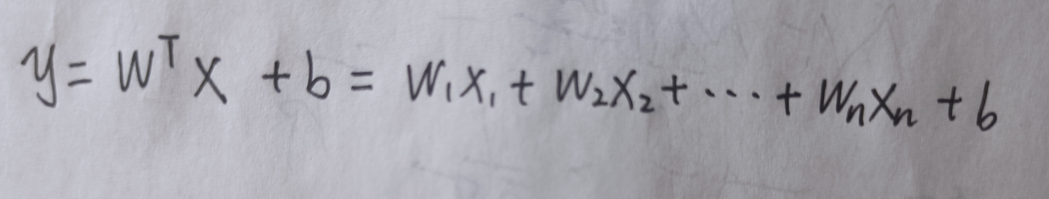
假设X一共有1000维,如果前200维的x都是相关的,那么其中任意一个x改变,就其他199个x也会变化,那么这个线性回归模型就会不稳定。延伸到其他机器学习模型也是一样的。
即使可以消除不稳定,相关变量太多也会过于强调模型的某一部分,因为这些部分被重复计算。
2.模型需要的样本数量随着变量(特征)数量指数增加
高维空间的数据本质上是稀疏的,一维正态分布中,68%的数据处于均值的上下一个方差的范围内,在10维正态分布中,只有2%的数据处于均值一个方差的超球范围内。
比如你想要你的机器模型学习到10维空间中的正态分布样本,那么就需要更多的样本来供她学习。
3.变量太多,难以解释
4.变量太多,容易过拟合
综上,就可以看到,观测变量如果太多,是很不利于机器学习模型的,所以要降维。
三、PCA的推导
1.向量表示与基变换
1.1 内积
在学习时,更倾向于将向量表示为列向量。故内积表示成如下形式:
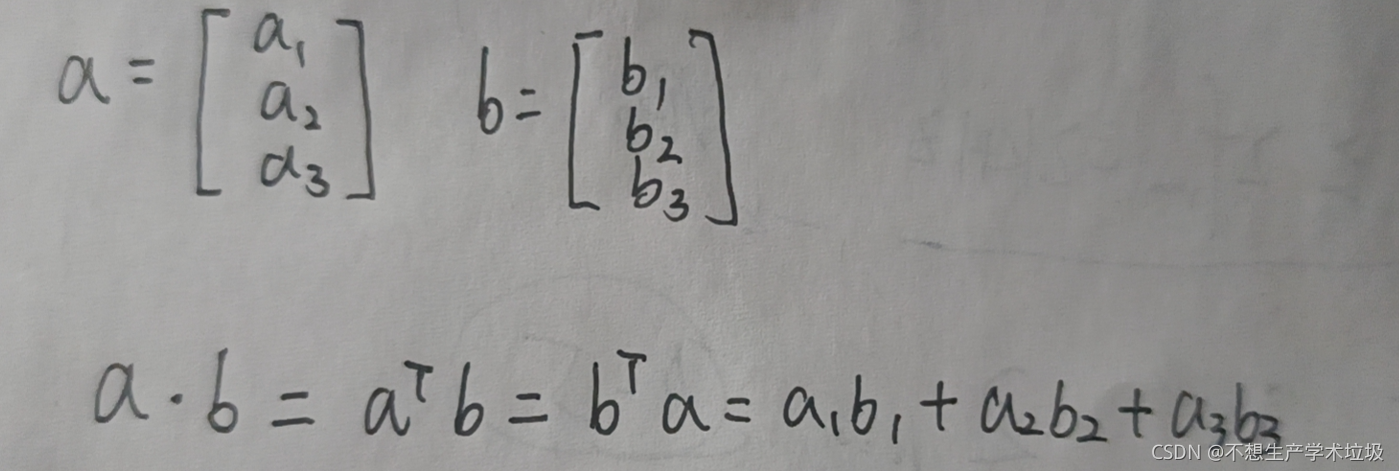
1.2 基
这个概念不多说。
1.3 基变换的矩阵表示
我们看下资料中的变换:
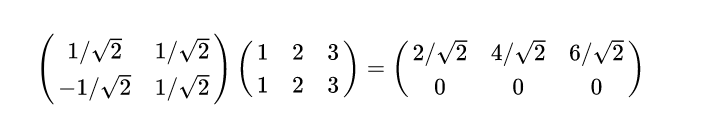 左边第一个矩阵每一行是一个基,左边第二个矩阵每一列是一个点(换句话说就是在原来坐标系下的向量),那么相乘后,同样每一列就是在新的基下的新的向量表示,注意是每一列代表一个新向量表示。
左边第一个矩阵每一行是一个基,左边第二个矩阵每一列是一个点(换句话说就是在原来坐标系下的向量),那么相乘后,同样每一列就是在新的基下的新的向量表示,注意是每一列代表一个新向量表示。
但是在机器学习中,我们喜欢把batch_size放在第一个维度,也就是说我们希望第一个维度也就是一行,代表一个点,那么就变换一种变换形式,两边同时转置一下就好:
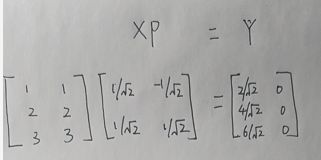
2. 最大可分性
回头看我们的X矩阵,每一列代表一个特征,每一行是一个观测向量,我们按列进行零均值化,那么其协方差矩阵如下:
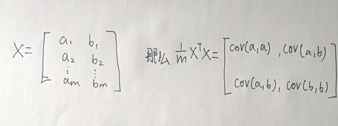
对高维情况同样适用,那么Y也是一样,根据最大可分性,我们希望Y的协方差矩阵是一个对角矩阵,即对角线有值,而且我们规定从左上到右下依次变小,不是对角线的地方值为0(这标志着不同观测变量直接线性不相关)。
但是等等,我们得首先确定变换后的Y每一列是否是零均值的,不然协方差矩阵就没有意义了。
这一点可以这么解释:因为Y=XP,新的Y每一列都是X各列的线性组合,组合之前各观测变量都是零均值化的,组合后的也一定都是零均值化的,所以Y的协方差矩阵有意义。
我们把Y的协方差矩阵表示出来:
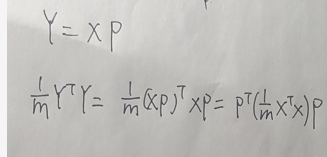
这样优化目标就来了,我们的X的协方差矩阵是已知的,只有P未知,我们要做的就是找到P将X的协方差矩阵相似对角化就好了。
这里要注意,对角化后的特征值就是Y的协方差矩阵中的元素,特征值就对应其特征向量上(或者叫基)的方差。我们选取前K个就好了。
接下来的问题参考最开始推荐的资料就行了。
四、PCA结果的解释
我们现在已经求出了P,我们来看看它们的结构吧:
Y=XP,
X.shape = m*n(m个样本,n个观测变量)
P.shape = n* k(n是降维前的维度,k为降维后的维度)
Y.shape = m*k(m个样本,k个观测变量)
单独抽出P的第一列,也就是最大的特征值对应的特征向量,这个特征向量每个值的大小,就代表相应的原观测变量,在新的主成分向量中所占的比重。
后面做大数据作业,展示PCA。
大数据作业三:降维PCA

















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









