







1.Learning Convolutional Networks for Content-weighted Image Compression
2.Lossy Image Compression with Compressive Autoencoders
3.Soft-to-Hard Vector Quantization for End-to-End Learning Compressible Representations
4.Towards Image Understanding from Deep Compression without Decoding
5.End-to-end optimized image compression
Learning Convolutional Networks for Content-weighted Image Compression
2017年5月
香港理工大学
李沐
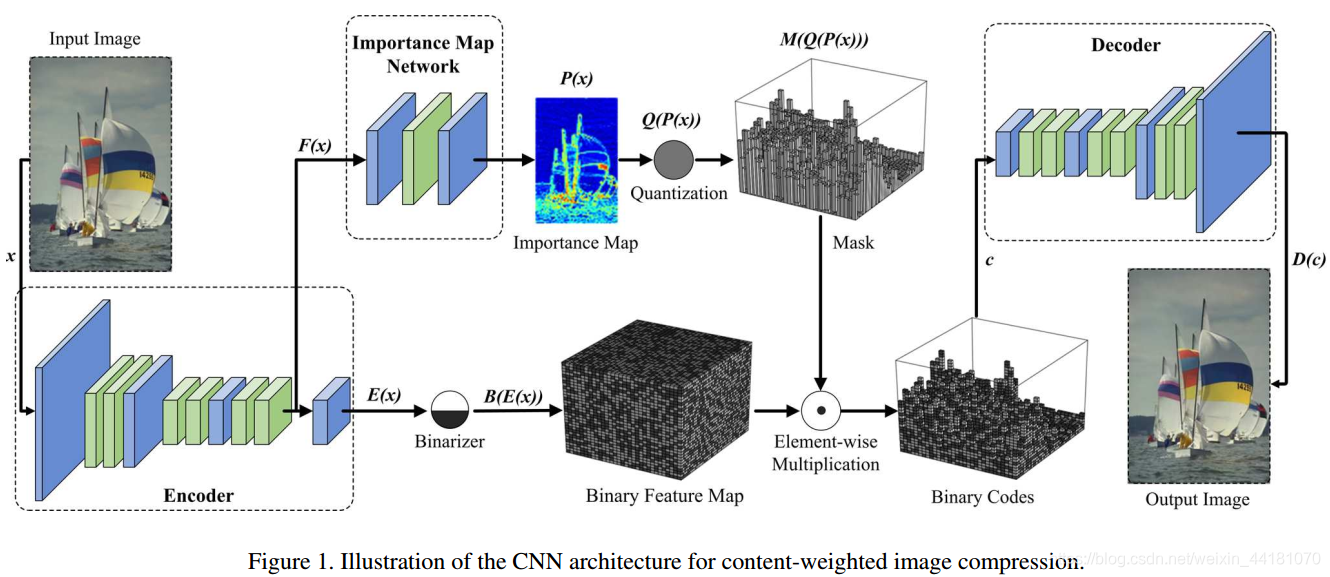
CNN图像压缩挑战在于不可微量化器和离散熵率估计的问题。本文贡献在于引进内容权重重要性图和二值化量化,其中重要性图的和可以作为离散熵率估计的连续替代,而且可以指导每个位置上的码率分配。利用二值化量化和近似函数,实现整个网络(编码、解码、量化以及重要性图)端对端优化。此外,利用传统的熵编码对重要性图和二进制编码进行压缩。
- [25,26,3]中对每个位置分配同样长度的编码。
- 我们的内容加权图像压缩系统在率损失、量化和连续近似方面与[3,23,1,19]不同。为了避免四舍五入和熵(本文不是用熵进行率控制),我们在重要性图上定义了我们的率损失,并采用一个简单的二值化器进行量化。此外,在[3,23,1,19,10]中,量化后的码长在空间上是不变的。相比之下,我们模型中的码长是内容感知的,在提高视觉质量方面非常有用。
- 主要框架:
Lossy Image Compression with Compressive Autoencoders:有损图像压缩自编码器
ICLR2017
Lucas Theis
德国蒂宾根大学
文章在其他文献的基础上,提出了一种基于传统卷积神经网络结构的有损图像自编码器(CAE),且对量化、熵率估计模块以及神经网络训练模块做了相应的改进(增量训练策略),文章的目标是直接优化由自编码器产生的失真率权衡(用于神经网路的训练),且可实现高分辨率的图像在低分辨率的终端上显示,且图像压缩结果在SSIM,MOS分数等指标上可以和JPEG2000的结果媲美。
CAE有三个部分组成:编码器f、解码器g、概率模型Q(分配熵编码比特数):
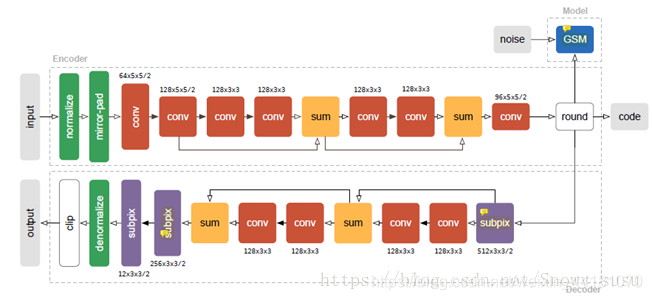
具体流程:
Encoder:规范化—镜像填充—图像卷积—空间下采样—量化(就近取整)—code 编码输出
Model:高斯尺度混合GSM(控制量化系数分布)+noise
Decoder: 卷积—上采样(在子像素卷积的情况下)—去标准化—clip.
规范化:规范化以每个通道值的分布为中心,并确保其具有近似单位方差;
镜像填充:使得图像编码器输出具有和8倍下采样相同的空间范围;解决图像的边缘问题;
卷积和空间下采样(并将图像通道从64个增加到128个,卷积神经网络的内容)之后是三个剩余块,前两个剩余块都有两个含有128个filter的卷积层,最后一个剩余块卷积层之后对系数进行下采样。
量化:量化采用就近取整函数,且做了相应的改进,
Sub-pix卷积层:有卷积和系数重组构成,系数重组是将一个多通道张量变为一个少通道,空间扩展的张量。
Clip :将图像灰度值控制在0-255之间。
本文优化部分:
1)量化: 由于量化是不可微的,文章正向传播时量化采用就近取整的方法。
在反向传播中梯度采用采用近似的方法即 r(y)=y, 其梯度为:
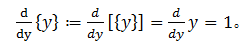
2)熵率估计: Q是离散函数,影响编码器的梯度计算。使用一个连续的、可微分的近似来解决这个问题。我们首先用概率密度q表示模型的分布Q:

其中u为添加的均匀噪声。
第二步:根据Jensen不等式(Theis et al., 2016)估计熵的上界:
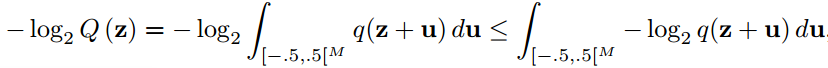
上界的无偏估计是通过从单位立方体[-.5,.5[M中采样u实现的。如果我们使用可微密度q,这个估计在z上是可微的,因此可以用来训练编码器。
变比特率:
在实践中,我们常常希望对所使用的比特数进行精确的控制。实现这一点的一种方法是训练一个自动编码器,以适应不同的率失真权衡。但这将需要我们训练和存储大量潜在的模型。为了降低这些成本,我们通过引入比例参数λ(M维的)对一个预先训练的不同压缩率的自编码器进行了微调
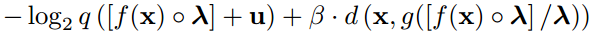
上式是逐点相乘,逐点相除,为了减少可训练尺度的数量,它们可以进一步跨维度共享。例如,当f和g是卷积的时候,我们共享跨空间维度的尺度参数,但不共享跨通道的尺度参数。
图3A显示了一个学习尺度参数的示例。为了对比特率进行更细粒度的控制,可以插入优化的刻度。
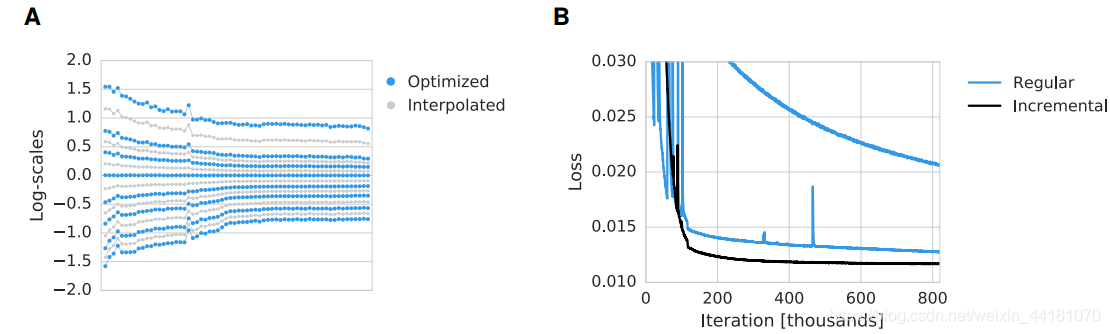
图3:A:微调压缩自动编码器(蓝色)得到的刻度参数。通过插值尺度(灰度)可以实现对比特率的更细粒度控制。每个点对应一个系数的尺度参数,用于特定的率失真权衡。这些系数是根据增量训练程序排序的。B:增量训练与非增量训练的比较。在116,000次迭代之后,学习率降低了(下面两行)。非增量训练最初不太稳定,并且在以后的迭代中表现出更差的性能。从一开始就使用一个小的学习率可以稳定非增量训练,但是要慢得多(最上面一条线)。
相关工作:
也许与我们的工作最密切相关的是Balle等人(2016)的工作。主要的区别在于我们处理量化(见2.1节)和熵率估计的方式。Balle等人(2016)所使用的变换由单一线性层和一种对比度增益控制形式组成,而我们的框架依赖于更标准的深度卷积神经网络。
Toderici等(2016a)提出使用递归神经网络(RNNs)进行压缩。与我们工作中的熵编码不同,网络试图将给定比特数的失真最小化。图像以迭代方式编码,并在每个步骤中执行解码,以便能够在下一次迭代中考虑残差。这种设计的一个优点是它允许图像的渐进编码。缺点是压缩比我们的方法要耗费更多的时间,因为我们使用高效的卷积神经网络,并且在编码阶段不需要解码。
Gregor等人(2016)探索了使用变分自编码器与循环编解码器对小图像进行压缩。这种类型的自编码器被训练来最大化对数似然的下界,或者等价地最小化
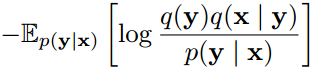
其中p(y|x)为编码器,q(x|y)为解码器。Gregor等人(2016)对编码器使用高斯分布,通过假设它是均匀的p(y|x) = f(x) + u,我们可以将他们的方法与Balle等人(2016)的工作联系起来。如果我们也假设一个固定方差的高斯似然
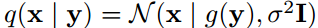
目标函数可以写为:
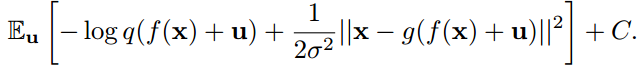
这里C是一个常数,它包含编码器的负熵和高斯似然的归一化常数。注意,这个方程等价于β=σexp(−2) /2的率失真权衡与和加性均匀噪声代替的量化。然而,并不是所有的失真都有一个等价的公式作为变分自动编码器(Kingma & Welling, 2014)。只有当exp[-d(x,y)]在x中可归一化,且归一化常数不依赖于y时,这才成立,否则C就不是常数。附录A.5提供了我们的方法与变分自编码器的直接经验比较。
Ollivier(2015)讨论了用于无损压缩的变分自编码器,以及自编码器去噪的连接。
3实验
我们使用普通的卷积神经网络(LeCun et al.,1998)作为压缩自编码器。我们的架构灵感来自于Shi等人(2016)的工作,他们证明了在低分辨率空间中操作可以更有效地实现超分辨率,即通过对图像进行卷积然后上采样,而不是先上采样然后再卷积图像。
编码器的前两层执行预处理,即镜像填充和固定像素方向的标准化。选择镜像填充使编码器的输出具有与8次下采样的图像相同的空间范围。归一化集中了每个通道值的分布,并确保其具有近似单位方差。然后,对图像进行卷积和空间下采样,同时将通道数增加到128。接下来是三个残差块(He et al.,2015),其中每个块由额外的两个卷积层组成,每个卷积层有128个滤波器。使用卷积层下采样后,最后通过量化,即四舍五入将系数变为最接近的整数。
解码器是编码器结构的镜像(图9)。我们使用零填充卷积代替了镜像填充和有效卷积。上采样是通过卷积,然后重组系数实现的。这种重组将一个有很多通道的张量变成了一个同样维度的张量,但是通道更少,空间范围更大(详见Shi等人,2016)。卷积和系数重组一起形成sub-pixel卷积层。接下来的三个残差块,两个sub-pixel卷积层上采样图像到输入的分辨率。最后,在去归一化之后,将像素值裁剪到0到255之间。与处理舍入函数的梯度类似,我们将剪切函数的梯度重新定义为在剪切范围之外的1。这确保即使解码后的像素不在此范围内,训练信号也非零(附录A.1)。
为了模拟系数的分布并估计比特率,我们使用了独立高斯尺度混合(GSMs),
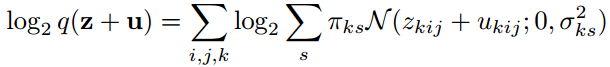
其中i和j迭代空间位置,k迭代单个图像z的系数通道。GSMs被很好地建立为建模自然图像的滤波响应的有用构建块(例如,Portilla et al., 2003)。我们在每个GSM中使用了6个尺度。我们没有使用上面更常见的参数化方法,而是对GSM进行参数化,这样它就可以很容易地使用基于梯度的方法,优化对数权值和对数精度,而不是权值和方差。我们注意到GSMs (Andrews &Mallows(1974)的尖峰性质意味着率项鼓励系数的稀疏性。
所有网络都是使用Theano(2016)和Lasagne (Dieleman et al., 2015)用Python实现的。对于量化系数的熵编码,我们首先创建了一个拉普拉斯平滑直方图来估计整个训练集的系数分布。然后将估计的概率与一个公开可用的BSD许可的范围编码器实现一起使用。
3.2增量训练
所有模型均使用Adam (Kingma & Ba, 2015)对32张128×128像素大小的图像批依次进行训练。我们发现以增量方式优化系数是有益的(图3B)。这是通过引入一个额外的二进制掩码m来实现的,
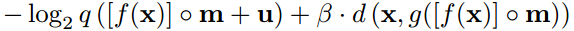
最初,掩码中除2项外的所有项都设置为零。对网络进行训练,直到性能改进达到阈值以下,然后通过将二进制掩码项设置为1启用另一个系数。在启用所有系数后,学习率从初始值10(-4)降低到10(-5)。训练进行了多达10(6)次更新,但通常很早就达到良好的性能。
在已经训练了一个固定的率失真权衡(β)的模型后,我们引进和精调尺度参数(方程9)对β的其他值,同时保持所有其他参数固定。这里我们使用一个初始学习率10(−3)和不断减少学习率的一个因子τexp(κ)=(τ+ t)exp(κ),其中t是当前执行的更新数量,κ=:8,τ= 1000。尺度优化为10,000次迭代。为了对比特率进行更细粒度的控制,我们在为附近的率失真权衡优化的尺度之间插值。
3.3自然图像
我们从flickr.com上获得了434张知识共享协议授权的高质量的图片,并根据对其进行了压缩自动编码器的训练。图像被降采样到低于1536x1536像素,并作为无损png存储,以避免压缩痕迹。从这些图像中,我们提取了128x128的图像块来训练网络。在训练过程中使用均方误差作为失真度的测量指标。影响网络结构和训练的超参数的评估是在一组小的提取出Flickr图像上。为了进行测试,我们使用了常用的Kodak PhotoCD数据集,其中包含24张未压缩的768x512像素图像。
我们将我们的方法与JPEG (Wallace, 1991)、jpeg2000 (Skodras et al.,2001)和基于RNN的方法(Toderici et al.,2016b)进行了比较。头信息的比特数不计入JPEG和jpeg2000的比特率。在JPEG的不同变体中,我们发现采用4:2:0色度子采样的优化JPEG通常效果最好(附录A.2)。
虽然微调单个压缩自动编码器以适应各种比特率的效果很好,但针对特定率失真权衡优化网络的所有参数仍能更好地工作。我们在这里选择了一种折衷方案,即结合为低、中、高比特率而训练的自动编码器(详见附录A.4)。
对于每个图像和比特率,我们选择产生最小失真的自动编码器。这增加了压缩图像所需的时间,因为必须对图像进行多次编码和解码。然而,解码图像仍然是快速的,因为它只需要选择和运行一个解码器网络。一个更有效但可能性能降低的解决方案是,始终为给定的率失真权衡选择相同的自动编码器。我们在编码成本中增加了一个字节来编码使用集成中哪个自动编码器。
所有测试图像的平均率失真曲线如图4所示。我们从PSNR、SSIM (Wang et al., 2004a)和多尺度SSIM (MS-SSIM;wang等,2004b)来评估不同的方法。我们使用van der Walt等人(2014)对SSIM的实现,以及Toderici等人(2016b)对MS-SSIM的实现。我们发现,在PSNR方面,我们的方法的性能与jpeg2000相似,但在低和中等比特率时略差,在高比特率时略好。在SSIM方面,我们的方法优于所有其他测试方法。MS-SSIM为所有方法生成非常相似的分数,除了非常低的比特率。然而,我们也发现这些结果高度依赖于图像。个别图像的结果作为补充材料提供。
在图5中,我们显示了压缩到低比特率的图像。根据定量结果,我们发现jpeg2000重构在视觉上比其他方法更接近CAE重构。然而,jpeg2000生成的人工痕迹似乎比CAE的更嘈杂,CAE的更平滑,有时看起来像Gabor滤波器。
为了量化压缩图像的主观质量,我们进行了平均意见评分(MOS)测试。虽然MOS测试有其局限性,但它是一种广泛使用的评价感知质量的标准(Streijl et al.,2014)。我们的MOS测试集包括来自Kodak数据集的24个未压缩的全分辨率原始图像,以及使用四种算法以每像素0:25、0:372和0:5位或接近3种不同比特率压缩的相同图像。只有低比特率的CAE被包括在这个测试中。
对于每幅图像,我们选择产生最高的比特率,但不超过目标比特率的CAE设置。CAE压缩图像的平均比特率分别为0.24479、0.36446和0.48596。然后,我们为JPEG和jpeg2000选择了最小的质量因子,其比特率超过了CAE。JPEG的平均比特率为0.25221、0.37339和0.49534,而JPEG 2000为0.24631、0.36748和0.49373。对于某些图像,CAE在最低设置下的比特率仍然高于目标比特率。将这些图像排除在最终结果之外,分别留下15、21和23幅图像。
结果273幅图像的感知质量由24名非专家评价者评分。一个评估者没有完成实验,所以她的数据被丢弃了。这些图像以随机的顺序呈现给每个人。评价者对每张图片给出一个离散的意见评分,范围从1(差)到5(好)。在评估开始之前,研究人员向受试者展示了与测试图像尺寸相同的未压缩校准图像(但不是来自Kodak数据集)。然后向他们展示四种不同版本的校准图像,使用四种压缩方法中质量最差的设置,并给出说明,这些是压缩图像的示例。这些是一些质量最差的例子。
图6显示了每个算法在每个比特率下的平均MOS结果。95%置信区间通过bootstrapping(引导,自举法)计算。我们发现CAE和jpeg2000在我们测试的所有比特率下都比JPEG或Toderici等人(2016b)的方法获得更高的MOS。我们还发现CAE在0.375 bpp (p < 0.05)和0.5 bpp (p < 0.001)时的性能明显优于JPEG 2000。
3)**增量式训练:**引进一个附加二进制掩模m,相当于一个微调系数,针对不同的熵率微调之前的自编码器模型。
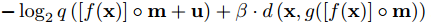
讨论:
我们介绍了一种简单而有效的方法来处理不可微性训练自编码器的有损压缩。再加上增量训练策略,这使我们能够在SSIM和MOS评分方面获得比jpeg2000更好的性能。值得注意的是,这种性能是通过高效的卷积架构、简单的基于舍入的量化和简单的熵编码方案实现的。现有的编解码器常常受益于硬件支持,使它们能够以较低的能源成本运行。然而,为卷积神经网络优化的硬件芯片可能很快就会得到广泛应用,因为这些网络现在是在如此多的应用中取得良好性能的关键。
而其他经过训练的算法已经被证明可以提供与jpeg2000类似的结果(例如van den Oord &Schrauwen, 2014),据我们所知,这是第一次证明端到端训练的架构能够在高分辨率图像上实现这种级别的性能。端到端训练的自动编码器的优点是可以针对任意指标进行优化。不幸的是,对于适合于优化的感知相关度量的研究仍然处于起步阶段(例如,Dosovitskiy &Brox, 2016;Balle等,2016)。而感知矩阵的存在与人类对某些类型失真的感知有很好的相关性(如Wang et al., 2004a;Laparra et al,2016),开发一个可优化的感知指标是一个更具挑战性的任务,因为这需要该指标对更大的多种失真和图像对上表现良好。
在未来的工作中,我们希望探索不同指标下压缩自编码器的优化。Bruna等人(2016)提出了一个很有前景的方向,他们使用训练过的用于图像分类的基于神经网络的度量获得了有趣的超分辨率结果。Gatys等人(2016)使用了类似的表示方法,在感知意义风格迁移方面实现了突破。感知度量的另一种选择可能是使用生成的对抗网络(GANs;Goodfellow等,2014)。基于Bruna等人(2016)和Dosovitskiy &的工作Brox (2016), Ledig等人(2016)最近通过将GANs与基于特征的度量标准相结合,展示了令人印象深刻的超分辨率结果。
End-to-end Optimized Image Compression
对这篇文章的讨论:
https://openreview.net/forum?id=rJxdQ3jeg¬eId=rJxdQ3jeg
Soft-to-Hard Vector Quantization for End-to-End Learning Compressible Representations
2017年
Eirikur Agustsson
苏黎世联邦理工学院
摘要:
提出了一种利用端到端训练策略学习深层架构中可压缩表示的新方法。我们的方法是基于量化和熵的软(连续)松弛,我们在整个训练过程中将其退火为离散的对应项。我们的软到硬量化方法给出的结果与最先进结果具有竞争力。
贡献:
1.我们提供了第一个统一的端到端学习框架,该框架可用于图像压缩和深度神经网络模型压缩。到目前为止,这两个问题在文献研究中基本上是独立的。
2.我们的方法简单直观,依赖于对给定标量或向量进行量化到量化级别的软任务。一个参数控制任务的“硬度”,并允许在训练期间从软任务逐渐过渡到硬任务。与基于四舍五入或随机量化方案相比,我们的编码方案是直接可微的,因此可以端到端的训练。
3.我们的方法不强迫网络适应特定的(给定的)量化输出(例如整数),而是与权重一起学习量化级别,使应用程序能够处理更广泛的问题。特别地,我们在学习压缩的上下文中首次探讨了向量量化,并演示了向量量化相对于标量量化的好处。
4.与以往的所有工作本质上不同的是,我们没有依赖于文献中常用的参数模型,没有假设量化特征或模型参数的边原分布,而是依赖于分配概率的直方图来对特征或模型参数的边际分布进行量化。
5.我们的方法应用于32层ResNet模型压缩[13]和使用[30]中提出压缩自编码器的变体实现全分辨率图像压缩。在这两种情况下,我们都获得了与最先进水平相竞争的性能,同时与原始工作相比,我们做出了更少的模型假设,并显著简化了训练流程[30,5]。
结论:
通过软到硬退火方案的训练,逐步从样本熵和网络离散化过程的软松弛过渡到实际的不可微量化过程,优化了原始网络损耗和熵之间的率失真权衡。
Towards Image Understanding from Deep Compression without Decoding
2018年3月
苏黎世联邦理工学院
提出无需解码的深度压缩图像理解框架,在未解码的情况下利用压缩表示进行分类、分割等图像理解任务,减少了计算成本。降低了计算复杂度。并且可以联合优化压缩网络和分类网络。只需要在原始的压缩和分类网络上做一些小的改动。
优点:
节省时间:节省了解码时间和DNN推理时间,因为DNN自适应模型可以比使用解码后的RGB图像的模型具有更小的深度。
节省内存:适用于实时应用。
鲁棒性:该方法在特定DNN模型变化最小的情况下,成功地进行了图像分类和语义分割,使我们相信该方法可以扩展到大部分相关的图像理解任务。
协同训练:压缩和推理DNN模型的联合训练导致了压缩质量和分类/分割精度的协同改进。
性能:根据实验最高性能,对于在图像理解任务中大量使用解码图像作为起点的任务来说,压缩表示是一种很有前途的替代方案。
缺点:
复杂度:与目前的标准压缩方法(如JPEG、JPEG2000)相比,我们使用的深度编码器和学习过程具有更高的时间和内存复杂性。
性能:该方法特别适用于高压缩率以及内存约束和存储非常关键的情况。(但压缩率一般是越小越好)
未来工作:
扩展压缩表示模型到其他视觉任务,以及更好地理解图像压缩网络学习的特性/压缩表示形式,可能会在无监督/半监督学习环境中产生有趣的应用.
注:
有DeepLab-ResNet-TensorFlow的代码https://github.com/DrSleep/tensorflow-deeplab-resnet
End-to-end optimized image compression
2017年
Johannes Balle
纽约大学的














 4013
4013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









