





原文:He K, Chen X, Xie S, et al. Masked autoencoders are scalable vision learners[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16000-16009.
源码:https://github.com/facebookresearch/mae
本文证明了掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习方法。MAE方法很简单:我们对输入图像的patches进行随机掩码,然后重建缺失的像素。MAE基于两个核心设计。首先,我们开发了一个非对称的编码器-解码器架构,其中编码器仅对可见的patches子集(没有掩码的tokens)进行操作,同时还有一个轻量级的解码器,可以从潜在表示和掩码tokens重建原始图像。其次,我们发现对输入图像进行高比例的掩码,例如75%,会产生一项非凡的、有意义的自监督任务。我们将这两种设计结合起来,就能高效地训练大模型:加快模型训练速度(3倍甚至更多)并提高精度。我们的可扩展方法能够训练出具有良好泛化性能的高容量模型。例如,在仅使用ImageNet-1K数据的方法中,MAE训练的ViT-Huge模型达到了最高精度(87.8%)。MAE在下游任务上的迁移性能优于有监督的预训练方法,并且显示出有前景的可扩展性能。
1.论文故事
深度学习见证了能力和容量不断增长的模型架构的爆发。借助于硬件的快速增长,如今的模型可以轻松地过拟合100万张图像,并开始需要数以亿计的有标签的图像(通常无法公开获取)。
这种对数据的渴望在自然语言处理(NLP)中已经通过自监督预训练成功地解决了。这些基于自回归语言建模(GPT)和掩码自编码(BERT)方法的解决方案在概念上很简单:它们删除一部分数据,并学习预测被删除的内容。目前,这些方法可以训练超过1000亿参数的NLP模型。
掩码自编码器的思想是去噪自编码器的一种形式,这种想法很自然,也适用于计算机视觉。事实上,与视觉密切相关的这方面的研究还要早于BERT。然而,尽管BERT的成功引起了人们对这一想法的极大兴趣,但视觉自编码方法的进展却落后于自然语言处理。我们不禁要问,是什么让掩码自编码方法在视觉和语言之间有如此差异?我们试图从以下几个方面回答这个问题:
(1)直到最近,模型架构都是不同的。在视觉领域,卷积网络在过去十年占主导地位。卷积通常在规则的网格上运算,将掩码token或位置嵌入等“indicators”集成到卷积网络中并不容易。然而,随着Vision Transformer (ViT)的引入,这种架构上的差距已经得到解决,不应再构成障碍。
(2)语言和视觉的信息密度不同。语言是人类产生的信号,具有高度的语义和信息密度。当训练一个模型来预测每句话中缺失的几个单词时,这项任务似乎会诱发复杂的语言理解。相反,图像是具有高度空间冗余的自然信号,例如,一个缺失的patch可以从邻近的patches中恢复,而不需要对部分、对象、场景有什么高级的理解。为了克服这种差异并鼓励模型学习有用的特征,我们提出了一个简单的策略,并且在计算机视觉中很有效:随机掩码大比例的patches。这种策略在很大程度上减少了冗余,并创建了一个具有挑战性的自监督任务。为了对我们的重建任务有一个定性的认识,请参见图2-4。

图2. MAE在ImageNet验证集图像上的重建效果。对于每个三元组,我们显示掩码图像(左)、MAE重建图像(中)和真实图像(右)。掩码率为80%,196个patches只剩下39个。

图3. 使用ImageNet训练的MAE(与图2中的模型权重相同),在COCO验证集图像上的重建效果。观察最右边的两个例子,虽然重建图像与真实图像不同,但在语义上是合理的。

图4. 使用75%掩码率预训练的MAE重建ImageNet验证集图像,但应用于更高掩码率(85%、95%)的输入图像。预测结果与原始图像似是而非,表明该方法可以泛化。
(3)自编码器的解码器将潜在表示映射回输入,在重建文本和图像之间起着不同的作用。在视觉中,解码器重建像素,因此其输出的语义级别低于普通的识别任务。相反,在语言中,解码器预测包含丰富语义信息的缺失单词。在BERT中,解码器可能是微不足道的(一个MLP),但我们发现,对于图像,解码器的设计在确定学习到的潜在表示的语义级别方面起着关键作用。
在以上分析的驱动下,我们提出了一种简单、有效、可扩展的掩码自编码器(MAE),用于视觉表示学习。MAE从输入图像中随机掩码patches,并在像素空间中重建缺失的patches。MAE采用非对称的编码器-解码器设计。编码器只对可见的patches(没有掩码的tokens)进行操作,解码器是轻量级的,可以从潜在表示和掩码tokens重建输入图像(图1)。在非对称的编码器-解码器架构中,将掩码tokens转移到小型解码器可以大大减少计算量。在这种设计下,高掩码率(如75%)可以实现双赢:一方面优化了精度,另一方面使编码器仅处理一小部分(如25%)patches。这可以将总体预训练时间减少3倍或更多,还可以减少内存消耗,使我们能够轻松地将MAE扩展到大模型。
MAE可以学到泛化性很好的大容量模型。通过MAE的预训练,我们可以在ImageNet-1K上训练ViT-Large/Huge这样需要大量数据(data-hungry)的模型,并提高模型的泛化性。在ImageNet-1K上进行微调时,MAE使用ViT-Huge模型实现了87.8%的准确率,这比之前所有只使用ImageNet-1K的模型结果都要好。我们还在目标检测、实例分割和语义分割任务上评估了MAE的迁移学习性能。在这些任务中,MAE的预训练比有监督的预训练取得了更好的结果。更重要的是,我们观察到,通过扩大模型可以带来显著的收益。这与NLP自监督预训练中观察到的结果一致,我们希望这将使计算机视觉领域能够探索类似的轨迹。
2.相关工作
VideoMAE:掩码自编码器是用于自监督视频预训练的高效利用数据的学习者
掩码语言建模和自回归语言建模方法,如BERT和GPT,是NLP中非常成功的预训练方法。这些方法保留输入序列的部分内容,并训练模型来预测缺失的内容。这些方法已被证明具有很好的可扩展性。大量证据表明,通过这些方法预训练的表示可以很好地泛化到各种下游任务上。
自编码是学习表示的一种经典方法。它有一个将输入映射到潜在表示的编码器和一个重建输入的解码器。例如,PCA和k-means都是自编码器。去噪自编码器(DAE)是一类破坏输入信号并学习重建原始的未损坏信号的自编码器。移除颜色通道或对像素进行掩码等方法可以被视为广义上的DAE。我们的MAE也是一种去噪自编码器,但在许多方面与经典的DAE不同。
掩码图像编码方法从掩码损坏的图像中学习表示。Vincent等人的开创性工作将掩码作为DAE中的一种噪声类型。Context编码器使用卷积网络修补大的缺失区域。近期相关的方法都是基于Transformer的。iGPT对像素序列进行操作,并预测未知像素。ViT论文研究了用于自监督学习的掩码patch预测。最近,BEiT提出了预测离散token的任务。
自监督学习方法已经在计算机视觉领域引起了极大的兴趣,通常侧重于利用不同的代理任务进行预训练。最近,对比学习已经很流行了,它可以对两个或多个视图之间的相似性和非相似性(或仅相似性)进行建模。对比学习和相关方法在很大程度上依赖于数据增强。自编码方法在概念上有所不同,下面详细介绍。
3.模型方法
掩码自编码器(MAE)是一种简单的自编码方法,它可以根据原始信号的部分观测结果重建原始信号。与所有的自编码器一样,我们的方法有一个编码器,将观察到的信号映射到潜在表示,而解码器负责从潜在表示重建原始信号。与传统的自编码器不同,我们采用了非对称设计,使编码器仅对部分观察信号(无掩码token)进行操作,并采用轻量级解码器,从潜在表示和掩码token重建完整信号,详细内容见图1。
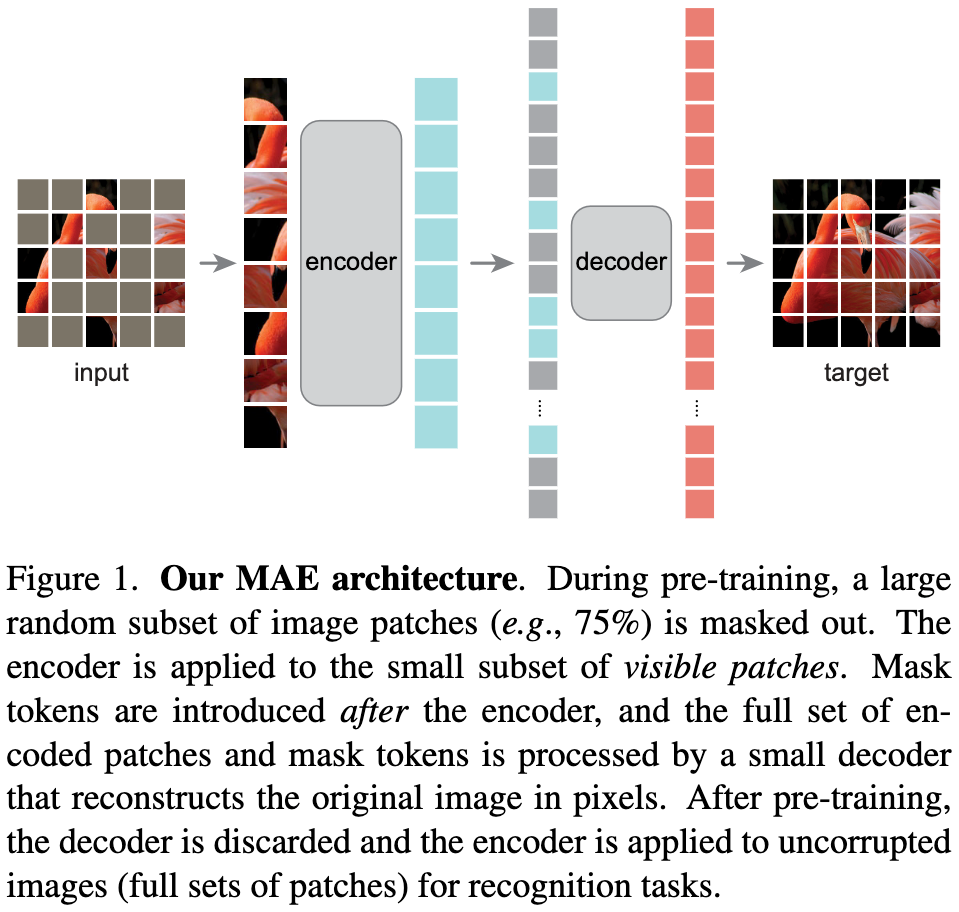
图1. MAE的架构。在预训练期间,对输入图像的patches进行随机掩码,例如掩码率为75%。编码器应用于可见patches这个小子集上。在编码器之后引入掩码tokens,所有已编码的patches和掩码tokens由一个小型解码器处理,该解码器以像素为单位重建原始图像。在预训练之后,解码器被丢弃,编码器被应用于未损坏的图像,为识别任务生成图像表示。
掩码。我们参照ViT将图像切分为规则的不重叠的patches。然后,我们按照均匀分布的原则随机采样部分patches,并掩码(删除)其余的patches。我们称之为“随机采样”。高掩码率的随机采样在很大程度上消除了冗余,从而创建了一个挑战性的任务,使模型不能轻松的通过外推法从可见patches重建掩码patches,详细内容见图2-4。均匀分布避免了潜在的中心偏移(即图像中心附近出现更多的掩码patches)。最后,高度稀疏的输入为设计高效的编码器创造了机会,下面详细介绍。
MAE编码器。我们的编码器是一个ViT,但只应用于可见的、未掩码的patches。就像在标准的ViT中一样,编码器通过线性投影嵌入patches,并添加位置嵌入,然后通过一系列Transformer块来处理嵌入序列。然而,我们的编码器只操作整个patches集合的一小部分(如25%)可见patches,而不使用被删除的掩码patches(掩码tokens)。这使我们能够训练非常大的编码器,而只需较少的计算和内存成本。完整的集合由一个轻量级的解码器处理,下面详细介绍。
MAE解码器。MAE解码器的输入是:可见patches编码后的结果和掩码tokens组成的完整tokens集合,详见图1。每个掩码token是一个共享的、习得的向量,表示存在一个需要预测的缺失的patch。我们向这个完整集合中的所有tokens添加位置嵌入,如果没有这一点,掩码tokens将缺少关于其在图像中的位置信息。解码器由一系列Transformer块组成。
MAE解码器仅在预训练期间用于执行图像重建任务。因此,我们能够独立于编码器灵活地设计解码器。我们用非常小的解码器进行了实验,这里的解码器比编码器更窄、更浅。例如,解码器对每个token的计算量在编码器的10%以下。采用这种非对称设计,全套tokens仅由轻量级解码器处理,大大减少了预训练的时间。
重建目标。MAE通过预测每个掩码patch的像素值来重建输入。解码器输出的每个元素都是一个表示patch的像素值向量。解码器的最后一层是线性投影层,其输出通道数等于一个patch中的像素值数量。MAE对解码器的输出进行重构,形成重建图像。我们的损失函数计算重建图像和原始图像在像素空间中的均方误差(MSE)。MAE只计算掩码patch的损失,类似于BERT。
我们还研究了一种变体,其重建目标是每个掩码patch的归一化像素值。具体来说,我们计算patch中所有像素的平均值和标准差,并用它们对这个patch进行归一化。在我们的实验中,使用归一化像素作为重建目标可以提高表示的质量。
简单的实现。MAE不需要任何专门的稀疏操作就能高效实现。首先,我们通过线性投影为每个输入的patch生成一个token,并添加位置嵌入。接着,我们随机洗牌token列表,并根据掩码率删除列表后面的部分。这个过程为编码器生成了一个小的tokens子集,相当于不放回采样patches。编码后,我们将掩码tokens列表添加到已编码的patches列表中,并对这个完整的列表进行反洗牌,使所有的tokens与其目标对齐。我们将解码器应用于这个添加了位置嵌入的完整列表。如上所述,不需要稀疏操作。这个简单的实现带来的开销可以忽略不计,因为洗牌和反洗牌的操作速度很快。
4.实验结果
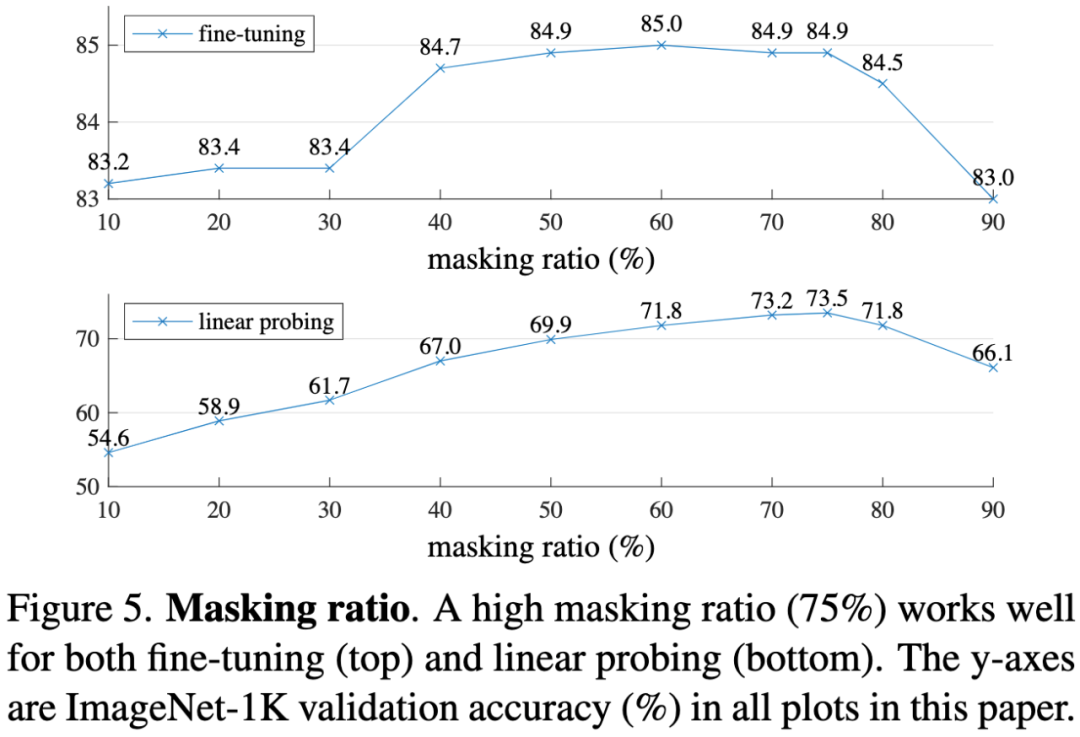
图5. 掩码率。高掩码率(75%)在微调(上图)和线性评估(下图)实验中都很有效。本文所有图的y轴为ImageNet-1K验证集上的准确率(%)。

表1. 使用ViT-L/16在ImageNet-1K上进行MAE的消融实验。我们报告了微调(ft)和线性评估(lin)的准确率(%)。

表2. MAE的训练时间(800轮),用TensorFlow在128个TPU-v3内核上进行基准测试。

图6. 掩码采样策略决定了代理任务的难度,影响了重建质量和表示(表1f)。每个输出都来自一个使用指定掩码策略训练的MAE。左:随机采样(我们的默认设置)。中:随机删除大块的采样。右:网格采样,每四个patch保留一个。图像来自验证集。
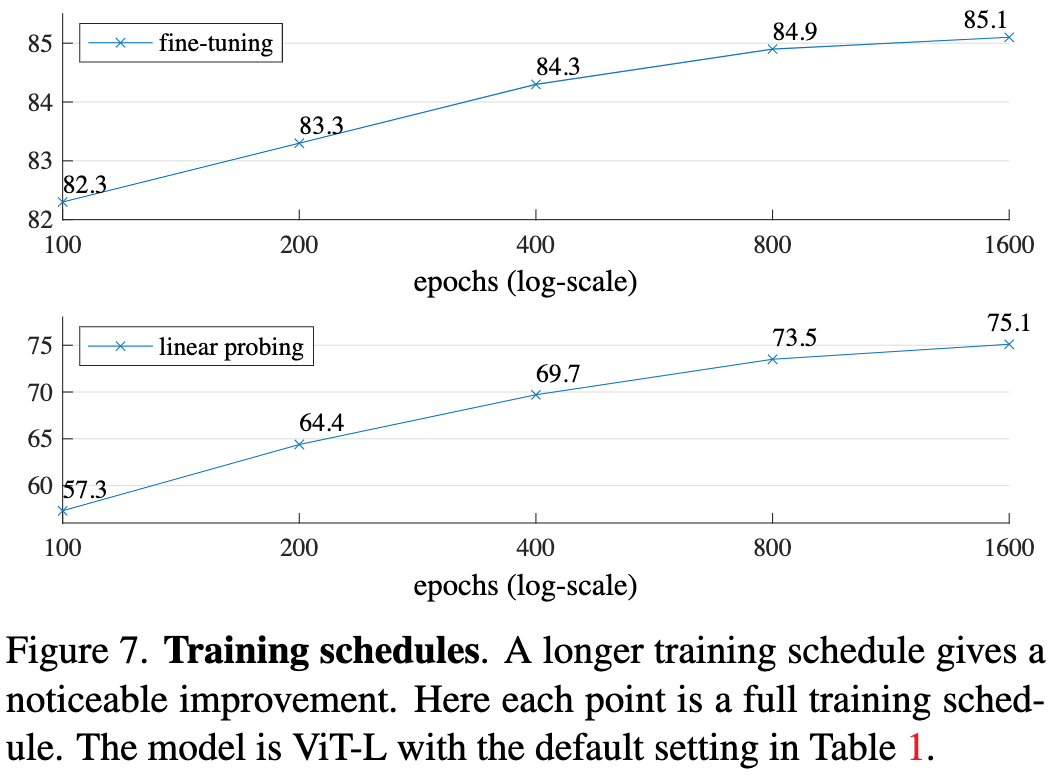
图7. 训练进度。较长的训练轮数会带来显著改善。这里使用的模型为ViT-Large,默认设置如表1所示。
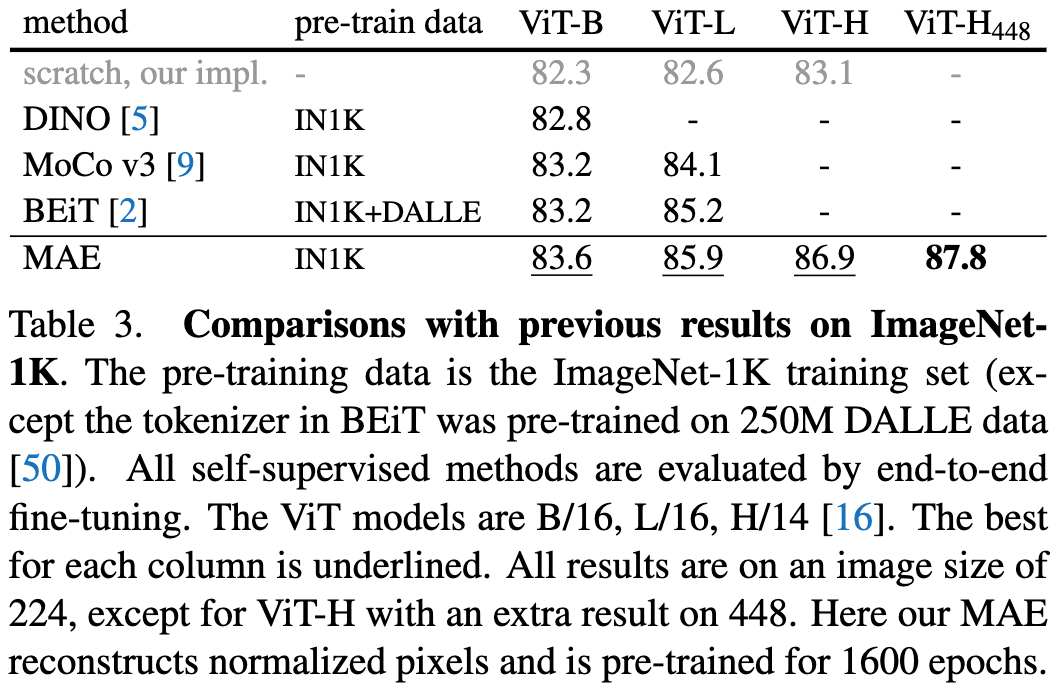
表3. MAE与DINO、MoCo v3、BEiT的比较。预训练数据是ImageNet-1K训练集。所有的自监督方法都通过端到端微调进行评估。ViT的型号为Base/16、Large/16、Huge/14。每列的最佳值都加了下划线。
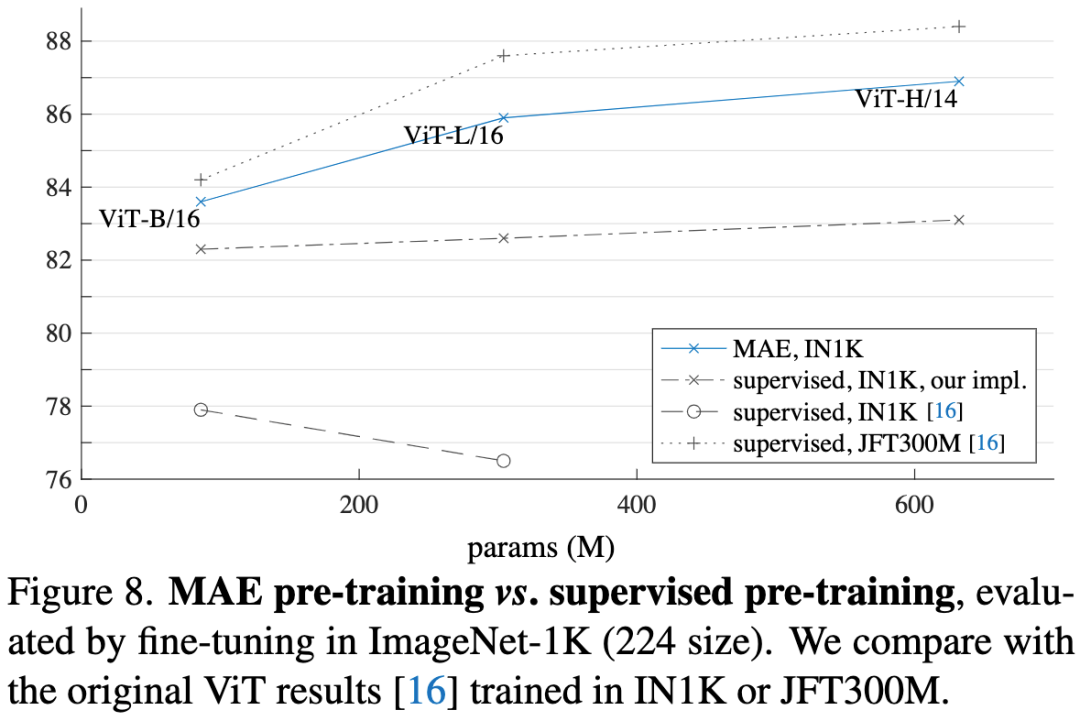
图8. MAE预训练与有监督预训练的对比,通过在ImageNet-1K上微调进行评估。我们比较了MAE的结果与IN1K或JFT300M训练的原始ViT的结果。
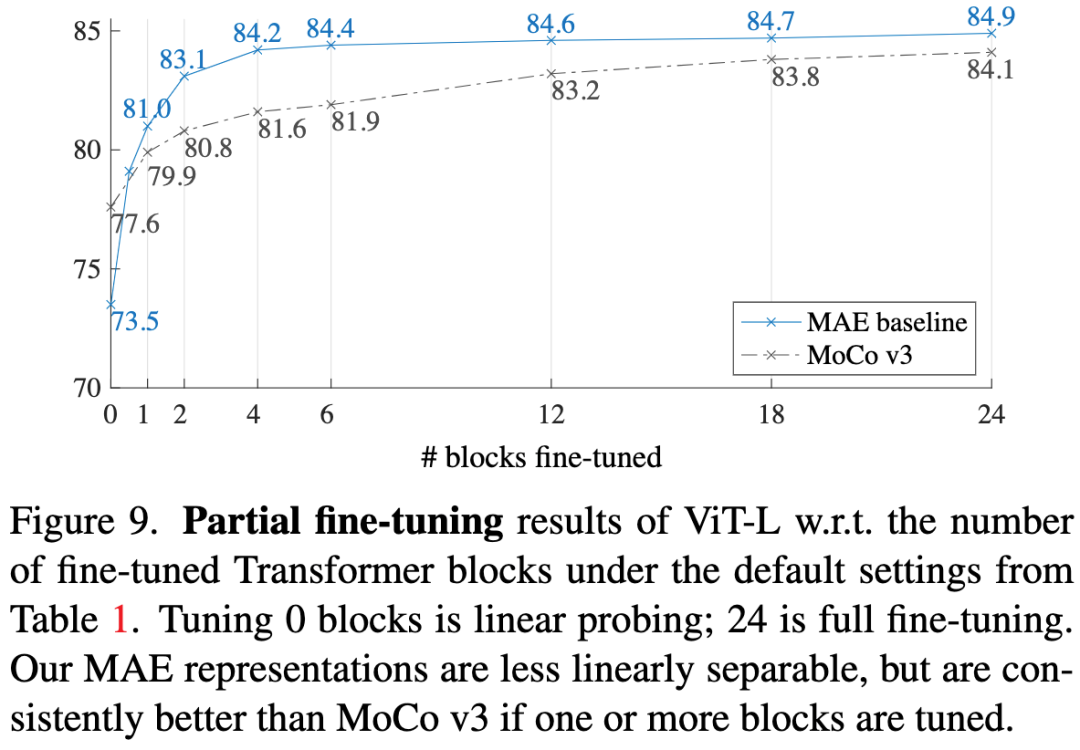
图9. 在表1的默认设置下,ViT-Large关于Transformer块数量的微调结果。MAE表示的线性可分性较差,但如果对一个或多个块进行微调,则始终优于MoCo v3。
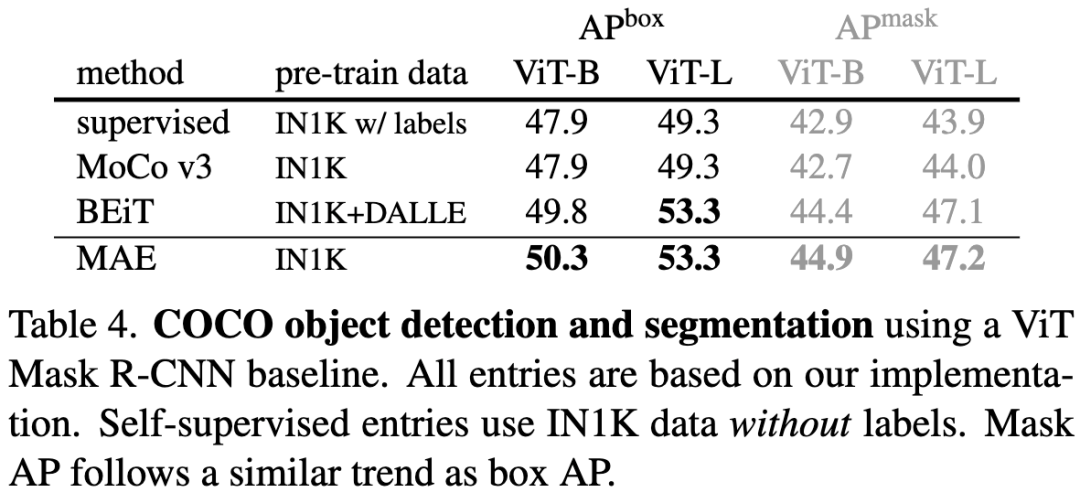
表4. 使用ViT Mask R-CNN基线进行COCO目标检测和分割实验的结果。
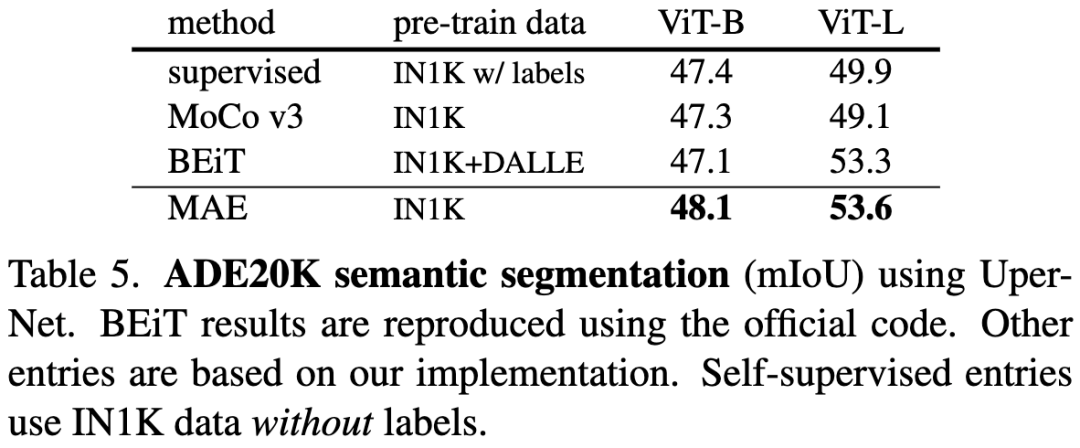
表5. 使用UperNet进行ADE20K语义分割实验的结果。
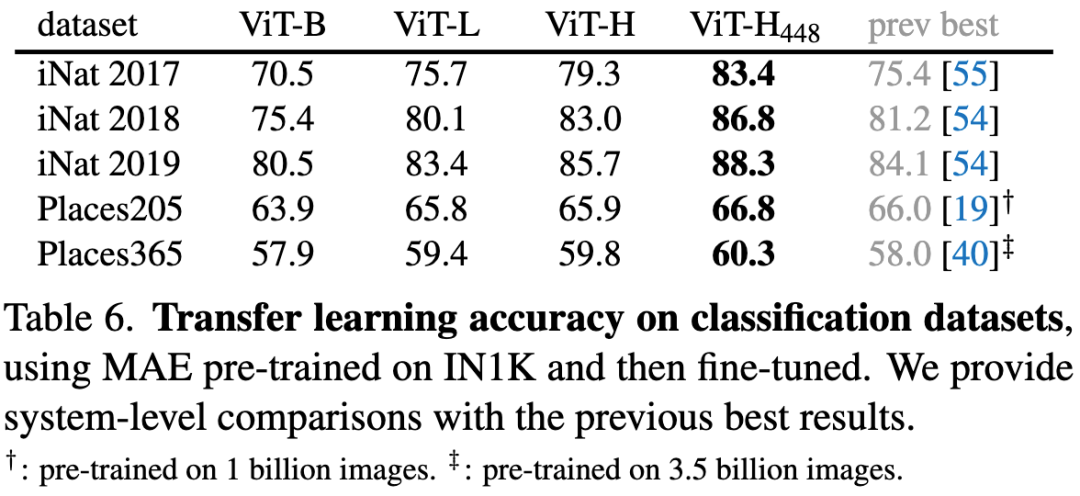
表6. MAE在ImageNet-1k上进行预训练,然后迁移到iNat、Places数据集上的微调结果。
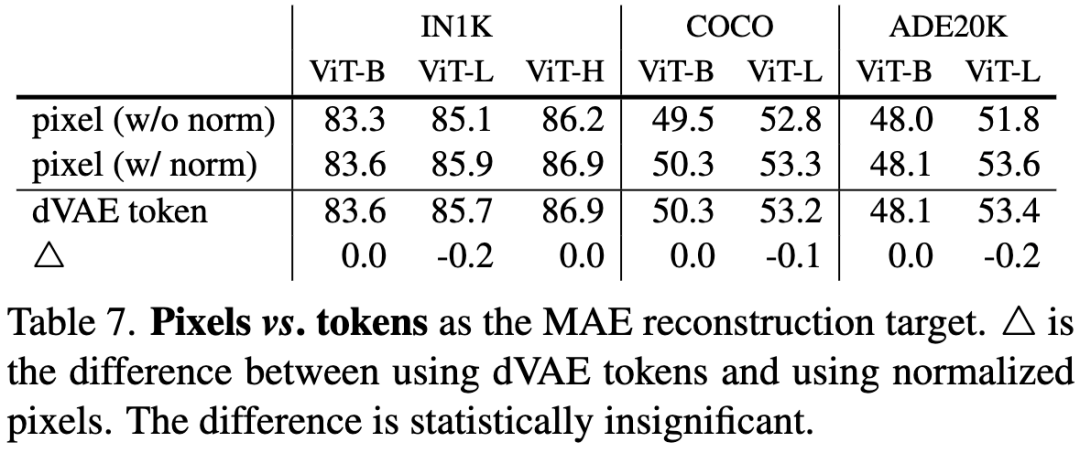
表7. 将pixels或tokens作为MAE重建目标的对比。
表8. 预训练的设置。
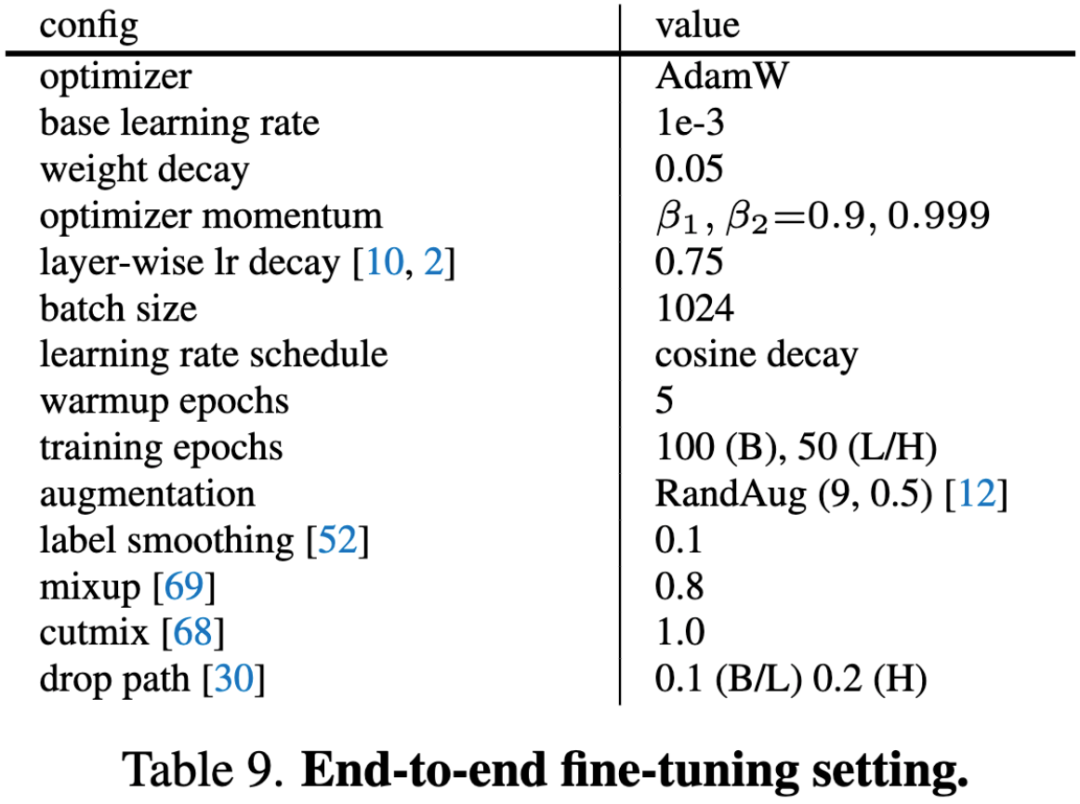
表9. 端到端微调的设置。

表10. 线性评估的设置。
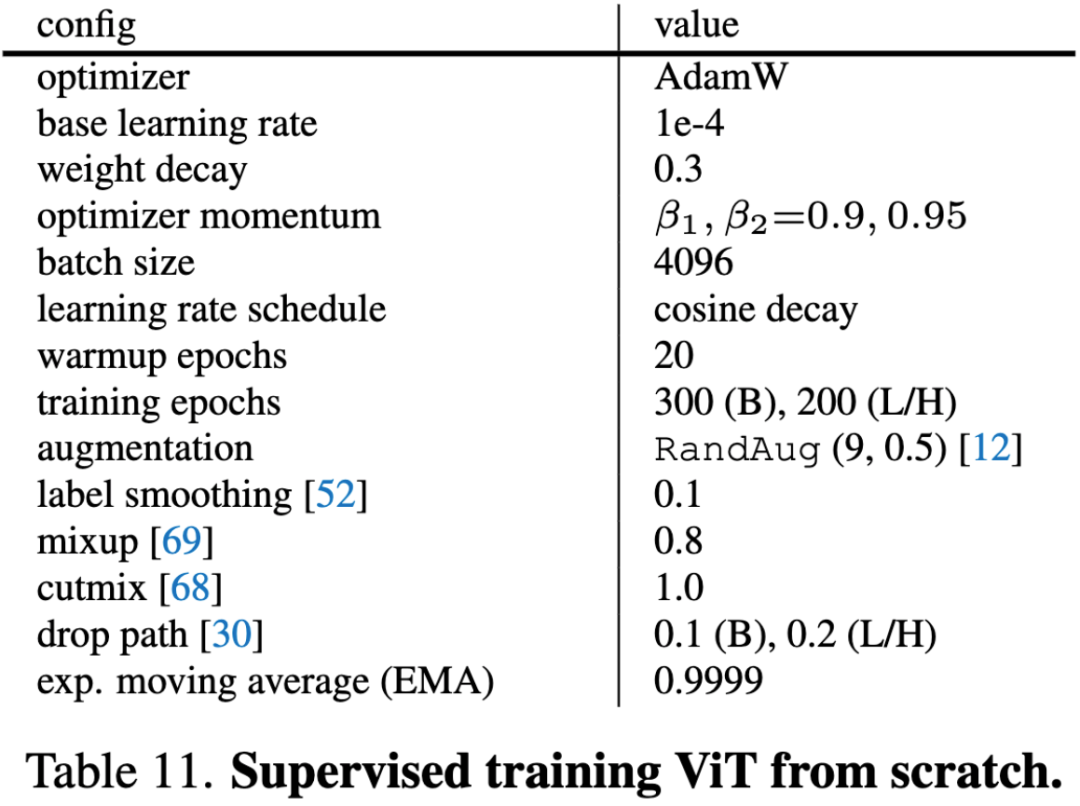
表11. 从头开始训练ViT(有监督)的设置。
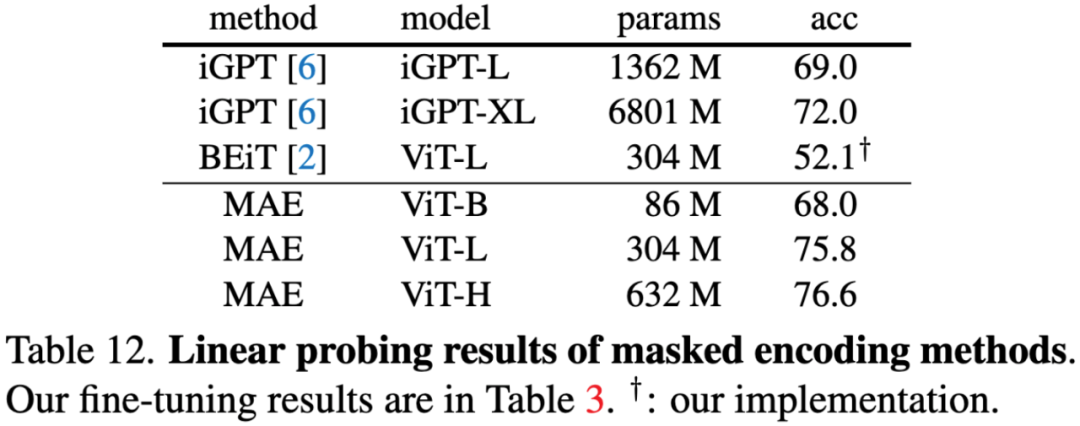
表12. 掩码编码方法的线性评估结果。我们的微调结果如表3所示。
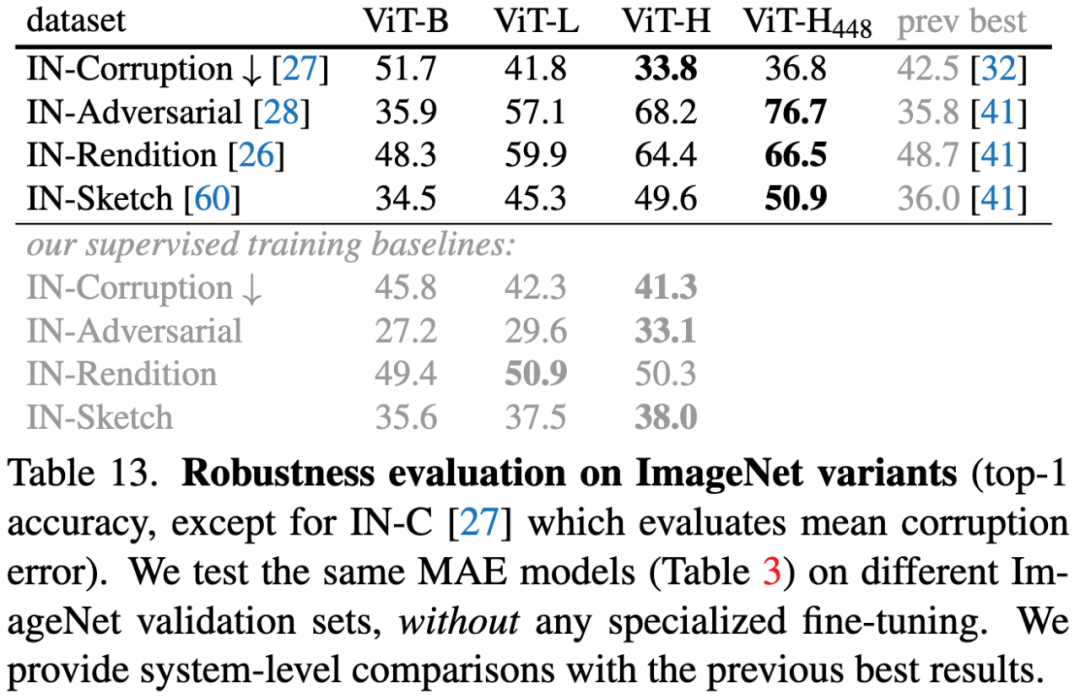
表13. 利用不同的ImageNet验证集评估MAE的鲁棒性。

图10. MAE在ImageNet验证集图像上的重建效果(随机选取)。对于每个三元组,我们显示掩码图像(左)、MAE重建图像(中)和真实图像(右)。掩码率为75%。

图11. 使用ImageNet训练的MAE,在COCO验证集图像上的重建效果(随机选取)。对于每个三元组,我们显示掩码图像(左)、MAE重建图像(中)和真实图像(右)。掩码率为75%。
5.总结讨论
扩展性好的简单算法是深度学习的核心。在自然语言处理中,简单的自监督学习方法可以从指数级扩展的模型中获益。在计算机视觉中,尽管在自监督学习方面取得了一定进展,但实用的预训练范式主要是有监督的。在这项研究中,我们观察到,自编码器能够提供可扩展的好处。视觉中的自监督学习有可能正在走上与NLP类似的轨道。
另一方面,我们注意到,图像和语言是不同性质的信号,必须细心处理这种差异。图像只是光的记录。我们随机删除最有可能不形成语义片段的patches。同样地,我们的MAE重建像素,这些像素不是语义实体。然而,我们观察到(如图4所示),MAE能够推断出复杂的、整体的重建,表明它已经学会了许多视觉概念,即语义。我们假设这种行为是通过MAE内部丰富的隐藏表示产生的。我们希望这一观点将启发未来的工作。
更广泛的影响。MAE是基于训练数据集的统计信息来预测内容的,因此将反映这些数据中的偏见,包括具有负面社会影响的偏见。我们的模型可能会生成不存在的内容。基于MAE生成图像时,这些问题需要进一步研究和考虑。
多模态人工智能
为人类文明进步而努力奋斗^_^↑
欢迎关注“多模态人工智能”公众号,一起进步^_^↑

















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









