







Object Detection in 20 Years: A Survey
20年目标检测技术综述

0.论文摘要
摘要—目标检测作为计算机视觉领域最基础且最具挑战性的问题之一,近年来受到极大关注。过去二十年间,我们见证了目标检测技术的快速演进及其对整个计算机视觉领域的深远影响。若将当前以深度学习为驱动的目标检测技术视作一场革命,那么回溯至20世纪90年代,我们便能领略早期计算机视觉研究者独具匠心的思维与极具前瞻性的设计。本文以技术演进为主线,全面回顾了这一快速发展跨越四分之一世纪(从20世纪90年代至2022年)的研究领域,涵盖历史里程碑检测器、检测数据集、评估指标、检测系统基础构建模块、加速技术以及最新前沿检测方法等多项主题。
索引术语—目标检测,计算机视觉,深度学习,卷积神经网络,技术演进。
1.引言
目标检测是计算机视觉领域的一项重要任务,其核心在于识别数字图像中特定类别(如人类、动物或车辆)的视觉对象实例。该技术的目标是开发计算模型与方法,为计算机视觉应用提供最基础的知识要素:场景中存在哪些物体及其位置信息。衡量目标检测性能的两大关键指标是准确率(包括分类准确率和定位准确率)和检测速度。
目标检测是许多其他计算机视觉任务的基础,例如实例分割[1–4]、图像描述[5–7]、目标跟踪[8]等。近年来,深度学习技术的快速发展[9]极大推动了目标检测领域的进步,使其取得显著突破并成为备受关注的研究热点。目前,目标检测已广泛应用于自动驾驶、机器人视觉、视频监控等现实场景。图1展示了近二十年来与"目标检测"相关出版物数量的增长趋势。
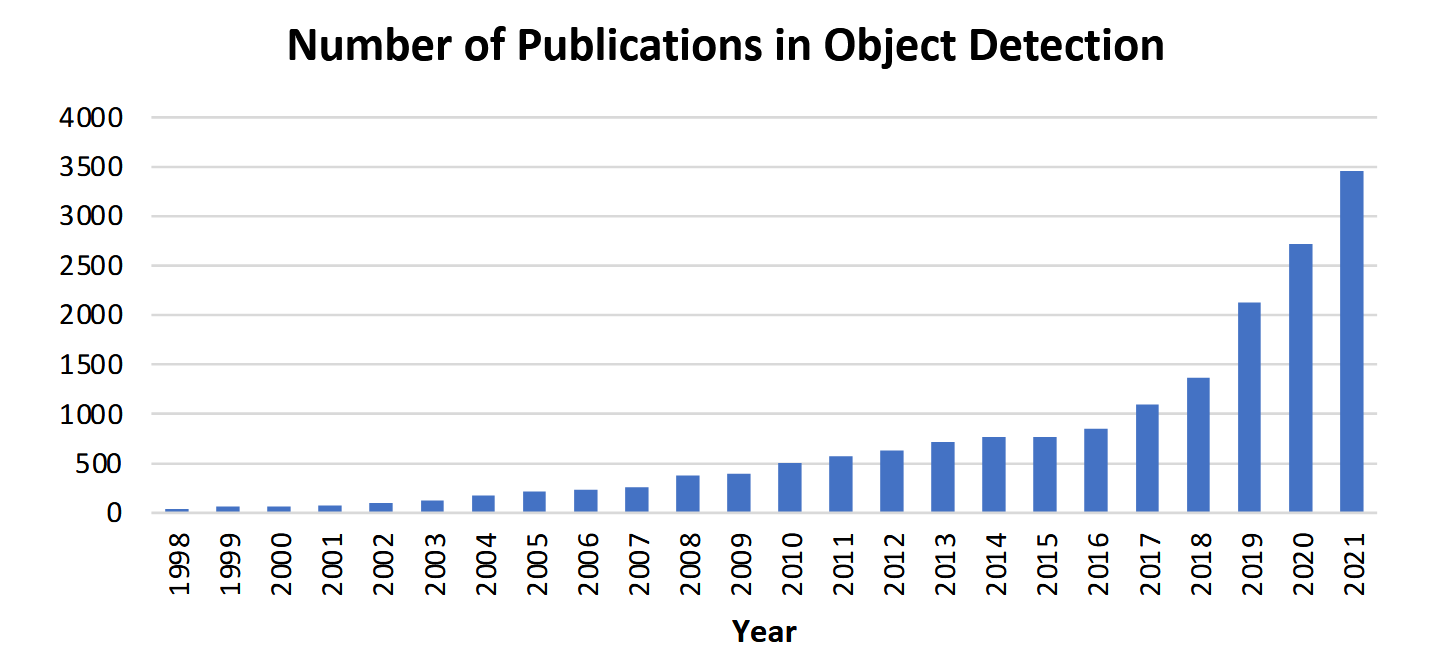
图1:1998至2021年间目标检测领域出版物数量增长趋势。(数据来源:谷歌学术高级检索,检索式:allintitle: “object detection” OR “detecting objects”。)
由于不同检测任务的目标和约束条件存在显著差异,其难度也各不相同。除了物体在不同视角、光照条件和类内差异等计算机视觉任务中的共性挑战外,物体检测还面临以下特定难点(但不限于):物体旋转与尺度变化(如小目标检测)、精确定位、密集遮挡目标检测、检测速度优化等。我们将在第四节对这些议题进行更深入的分析。
本综述旨在从多角度为初学者提供对目标检测技术的完整理解,并着重展现其发展脉络。其主要特点体现在三个方面:基于技术演进脉络的系统性回顾、对关键技术及最新前沿成果的深入探讨,以及对检测加速技术的全面分析。文章主线聚焦于该领域的过去、现在与未来,同时涵盖目标检测中其他必要组成部分,如数据集、评估指标和加速技术等。立足于技术发展的高速公路,本综述致力于呈现相关技术的演进历程,使读者既能掌握核心概念又能发现潜在发展方向,而无需深究其技术细节。
本文其余部分结构如下。第二章回顾了目标检测技术二十年来的发展历程。第三章重点梳理目标检测领域的加速技术。第四章对近三年来的前沿检测方法进行综述。第五章总结全文,并对未来研究方向进行深入分析。
2.20年后的物体检测
在本节中,我们将从多个角度回顾目标检测的发展历程,包括里程碑式的检测器、数据集、评估指标以及关键技术的演进。
A. 目标检测路线图
过去二十年里,目标检测领域的发展历程被普遍划分为两个历史阶段:"传统目标检测时期(2014年前)“和"基于深度学习的检测时期(2014年后)”,如图2所示。下文我们将以时间轴和性能表现为线索,梳理该阶段的里程碑式检测器,重点剖析其背后的驱动技术,具体可见图3。
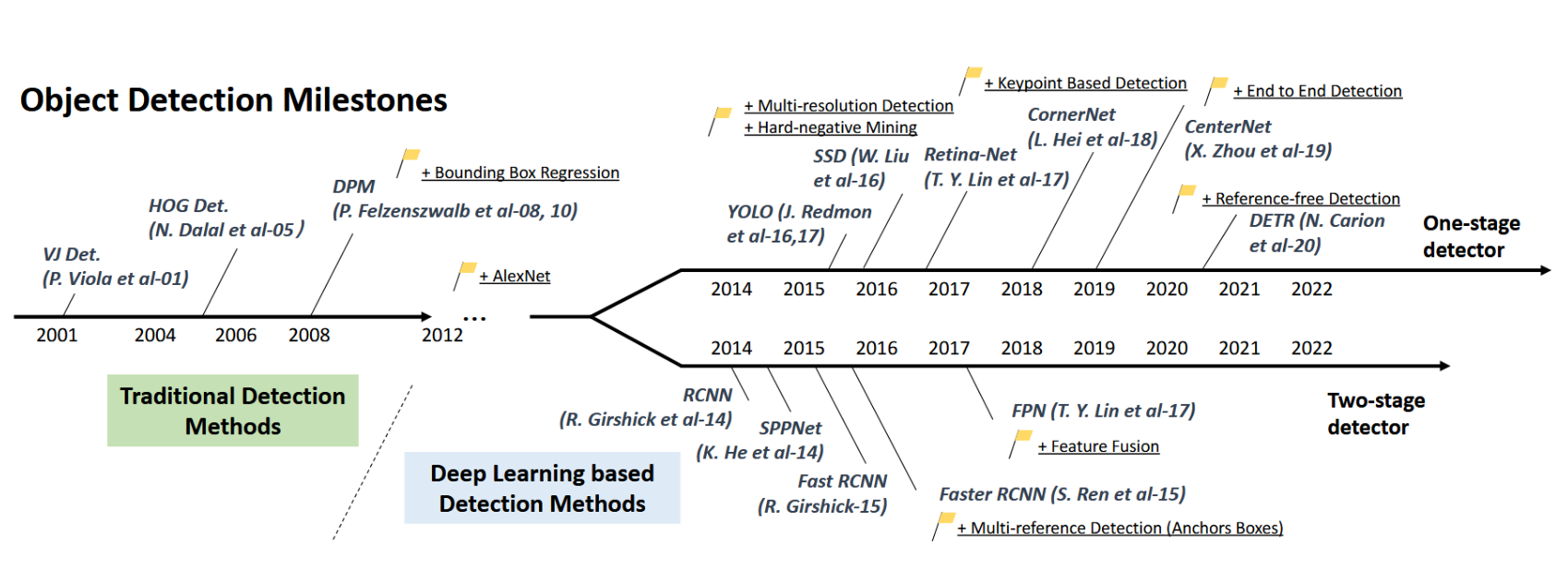
图2:目标检测技术发展路线图。本图中标注的里程碑检测器包括:VJ检测器[10,11]、HOG检测器[12]、DPM[13-15]、RCNN[16]、SPPNet[17]、Fast RCNN[18]、Faster RCNN[19]、YOLO[20-22]、SSD[23]、FPN[24]、RetinaNet[25]、CornerNet[26]、CenterNet[27]、DETR[28]。
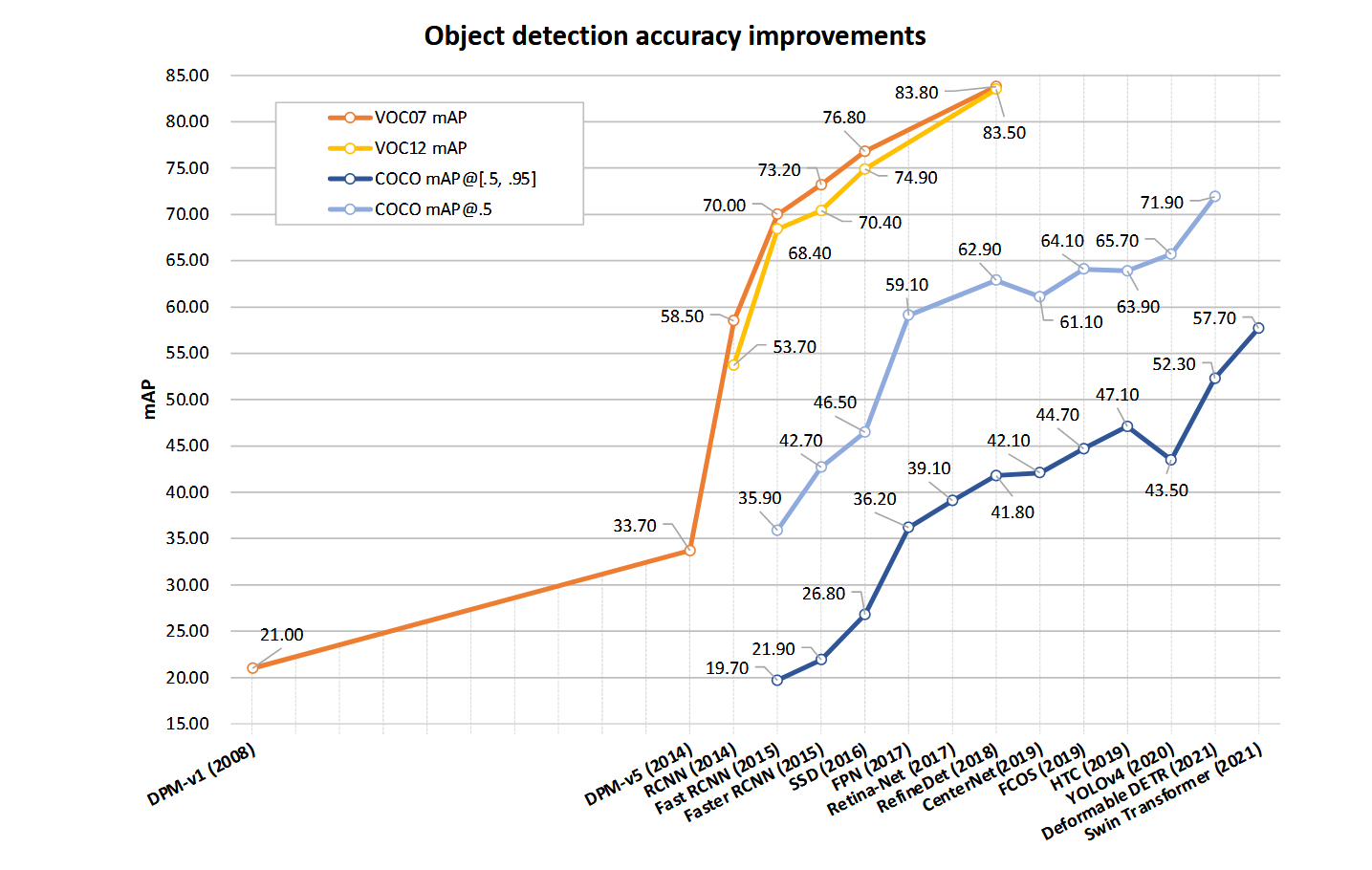
图3:在VOC07、VOC12和MS-COCO数据集上目标检测精度的提升。本图涉及的检测器包括:DPM-v1 [13]、DPM-v5 [37]、RCNN [16]、SPPNet [17]、Fast RCNN [18]、Faster RCNN [19]、SSD [23]、FPN [24]、RetinaNet [25]、RefineDet [38]、TridentNet [39]、CenterNet [40]、FCOS [41]、HTC [42]、YOLOv4 [22]、Deformable DETR [43]、Swin Transformer [44]。
- 里程碑:传统检测器:若将当今的目标检测技术视为深度学习驱动的革命,那么回溯到1990年代,我们便能领略早期计算机视觉的精妙设计与长远视野。早期的目标检测算法大多基于手工设计特征构建。由于当时缺乏有效的图像表征方法,研究者不得不设计复杂的特征表示体系与多种加速技巧。
Viola-Jones检测器:2001年,P. Viola和M. Jones首次在无任何约束条件(如肤色分割)的情况下实现了人脸的实时检测[10,11]。该检测器在700MHz奔腾III处理器上运行时,在同等检测精度下,其速度比同期其他算法快数十甚至数百倍。VJ检测器采用最直接的滑动窗口检测方式:遍历图像中所有可能的位置和尺度,判断是否存在包含人脸的窗口。虽然这一过程看似简单,但其背后的计算量远超当时计算机的运算能力。通过整合三项关键技术——“积分图”、“特征选择"和"检测级联”(详见第三节),VJ检测器显著提升了检测速度。
HOG检测器:2005年,N. Dalal与B. Triggs提出了方向梯度直方图(HOG)特征描述子[12]。HOG可视为对其所处时代的尺度不变特征变换[29,30]与形状上下文[31]的重要改进。为平衡特征不变性(包括平移、尺度、光照等)与非线性特性,HOG描述子被设计为在均匀间隔单元格的密集网格上计算,并采用重叠局部对比度归一化(基于"块"结构)。虽然HOG可用于检测多类物体,但其最初研发动机主要针对行人检测问题。为检测不同尺寸目标,HOG检测器在保持检测窗口尺寸不变的前提下对输入图像进行多次缩放。多年来,HOG检测器已成为众多物体检测器[13,14,32]及各类计算机视觉应用的重要基础。
可变形部件模型(DPM):作为PASCAL VOC 2007、2008和2009检测挑战赛的冠军,DPM是传统目标检测方法的典范。该模型由P. Felzenszwalb于2008年提出[13],是对HOG检测器的扩展。它遵循"分而治之"的检测理念:训练可简单视为学习物体的合理分解方式,推理则可视为对不同部件检测结果的集成。例如,“汽车"检测问题可分解为车窗、车身和车轮的检测。这部分工作(即"星型模型”)由P. Felzenszwalb等人提出[13]。随后,R. Girshick将星型模型扩展为"混合模型"以应对现实场景中物体的显著变化,并做出了一系列其他改进[14, 15, 33, 34]。
尽管当今的目标检测器在检测精度上已远超DPM(可变形部件模型),但许多方法仍深受其宝贵洞见的深远影响,例如混合模型、难例挖掘、边界框回归、上下文启动等。2010年,P. Felzenszwalb和R. Girshick因其贡献被PASCAL VOC授予"终身成就奖"。
- 里程碑:基于CNN的两阶段检测器:随着手工设计特征的性能趋于饱和,2010年后目标检测研究一度陷入停滞。2012年,卷积神经网络迎来复兴[35]。鉴于深度卷积网络能够学习图像鲁棒的高层特征表示,一个自然的问题随之产生:能否将其引入目标检测领域?2014年,R. Girshick等人率先突破僵局,提出了基于CNN特征的区域检测方法(RCNN)[16,36],自此目标检测开始以前所未有的速度发展。深度学习时代的检测器主要分为两类:“两阶段检测器"与"一阶段检测器”——前者将检测视为"由粗到精"的过程,后者则将其视为"一步到位"的流程。
RCNN的核心思想很简单:首先通过选择性搜索[45]提取一组物体提议(即候选目标框),然后将每个提议区域缩放为固定尺寸的图像,输入到预训练的CNN模型(如AlexNet[35])中提取特征。最后使用线性SVM分类器预测每个区域是否存在目标并识别物体类别。RCNN在VOC07数据集上实现了显著性能提升,将平均精度均值(mAP)从DPM-v5[46]的33.7%大幅提高到58.5%。尽管RCNN取得了重大进展,但其缺陷也很明显:由于需要对大量重叠提议区域(每张图像超过2000个候选框)进行冗余特征计算,导致检测速度极慢(GPU处理单张图像需14秒)。同年提出的SPPNet[17]成功解决了这一问题。
SPPNet:2014年,何恺明等人提出了空间金字塔池化网络(SPPNet)[17]。此前的CNN模型(如AlexNet[35])需要固定尺寸的输入(例如224×224像素的图像)。SPPNet的核心贡献在于引入了空间金字塔池化(SPP)层,使得CNN无需调整图像/感兴趣区域尺寸即可生成固定长度的特征表示。将该网络用于目标检测时,仅需对整张图像计算一次特征图,之后即可为任意区域生成固定长度的特征表示用于训练检测器,从而避免重复计算卷积特征。在不牺牲检测精度(VOC07 mAP=59.2%)的前提下,SPPNet的速度比R-CNN快20倍以上。尽管SPPNet显著提升了检测速度,但仍存在不足:一是训练流程仍需多阶段进行,二是网络仅微调全连接层而忽略之前所有层的参数优化。次年提出的Fast RCNN[18]成功解决了这些问题。
Fast RCNN:2015年,R. Girshick提出了Fast RCNN检测器[18],这是对R-CNN和SPPNet[16,17]的进一步改进。Fast RCNN能够在相同网络配置下同步训练检测器和边界框回归器。在VOC07数据集上,Fast RCNN将mAP从58.5%(RCNN)提升至70.0%,同时检测速度比R-CNN快200倍以上。尽管Fast RCNN成功整合了R-CNN和SPPNet的优势,但其检测速度仍受限于候选区域生成环节(详见第II-C1节)。这自然引出一个问题:"能否用CNN模型生成目标候选框?"随后提出的Faster R-CNN[19]解答了这一问题。
Faster RCNN:2015年,S. Ren等人在Fast RCNN提出后不久发表了Faster RCNN检测器[19,47]。该模型是首个接近实时的深度学习检测器(COCO mAP@.5=42.7%,VOC07 mAP=73.2%,基于ZF-Net[48]的帧率为17fps)。其核心贡献在于引入区域提议网络(RPN),实现了近乎零计算成本的候选区域生成。从R-CNN到Faster RCNN,目标检测系统的各个独立模块(如候选区域提取、特征计算、边界框回归等)被逐步整合为统一的端到端学习框架。尽管Faster RCNN突破了Fast RCNN的速度瓶颈,但在后续检测阶段仍存在计算冗余。后续研究者提出了RFCN[49]和Light head RCNN[50]等多种改进方案。(详见第三节技术细节)
- 里程碑:基于CNN的单阶段检测器:大多数两阶段检测器遵循由粗到精的处理范式。粗检测旨在提升召回能力,而精检测则在粗检测基础上优化定位,更侧重判别能力。这类检测器无需复杂技巧即可实现高精度,但因速度缓慢和结构复杂,鲜少应用于工程实践。相比之下,单阶段检测器通过单次推理即可检出所有目标,其实时性和易部署特性深受移动设备青睐,但在检测密集小目标时性能显著下降。
You Only Look Once (YOLO):YOLO由R. Joseph等人于2015年提出,是深度学习时代首个单阶段检测器[20]。其速度优势显著:快速版YOLO在VOC07数据集上达到155帧/秒(mAP=52.7%),增强版则为45帧/秒(mAP=63.4%)。该算法采用与两阶段检测器完全不同的范式——将单一神经网络作用于整幅图像,通过网格划分区域并同步预测各区域的边界框与概率。尽管检测速度大幅提升,但YOLO的定位精度较两阶段检测器有所下降,尤其对小目标检测效果欠佳。后续推出的YOLO改进版本[21,22,51]及SSD算法[23]均着力改善此问题。近期,YOLOv4团队提出的YOLOv7[52]通过动态标签分配、模型结构重参数化等优化设计,在5-160FPS范围内实现了速度与精度的双重突破,成为当前性能领先的目标检测器。
单次多框检测器(SSD):SSD[23]由W. Liu等人于2015年提出。该算法的主要贡献在于引入了多参考与多分辨率检测技术(详见第II-C1节),显著提升了一阶段检测器的精度,尤其对小物体检测效果突出。SSD在检测速度与精度上均具优势(COCO mAP@.5=46.5%,快速版可达59帧/秒)。其与先前检测器的核心差异在于:SSD在网络不同层级上检测不同尺度的目标,而传统方法仅在顶层进行检测。
RetinaNet:尽管单阶段检测器速度快且结构简单,但其检测精度多年来始终落后于两阶段检测器。T.-Y. Lin等人通过研究发现了问题根源,并于2017年提出RetinaNet解决方案[25]。他们指出,密集检测器训练过程中面临的极端前景-背景类别不平衡是主要原因。为此,RetinaNet创新性地提出了"焦点损失函数",通过重塑标准交叉熵损失,使检测器在训练时更聚焦于难以分类的误检样本。该损失函数使得单阶段检测器在保持高速检测优势的同时(COCO mAP@.5=59.1%),达到了与两阶段检测器相当的精度水平。
CornerNet:此前的检测方法主要依赖锚框(anchor boxes)作为分类与回归的参考基准。由于物体在数量、位置、尺寸、长宽比等方面存在显著差异,传统方法不得不设置大量参考框以更好地匹配真实标注框(ground truths),从而获得较高性能。但这会导致类别不平衡问题加剧、需要大量人工设计超参数,且收敛时间较长。为解决这些问题,H. Law等人[26]摒弃了传统检测范式,将目标检测任务转化为关键点(边界框的角点)预测问题。在获取关键点后,模型通过额外的嵌入信息对角点进行解耦与重组,最终形成检测框。CornerNet在当时以57.8%的COCO mAP@.5指标超越了多数单阶段检测器。
CenterNet:周旭(X. Zhou)等人于2019年提出CenterNet[40]。该方法同样采用基于关键点的检测范式,但摒弃了分组式关键点分配(如CornerNet[26]、ExtremeNet[53]等)和非极大值抑制(NMS)这类高成本后处理流程,构建了完全端到端的检测网络。CenterNet将目标视为单个点(即目标中心点),并基于该中心参考点回归所有属性(如尺寸、方向、位置、姿态等)。该模型结构简洁优雅,可将三维目标检测、人体姿态估计、光流学习、深度估计等任务统一至单一框架。尽管采用如此简洁的检测理念,CenterNet仍能取得具有竞争力的检测结果(COCO mAP@.5=61.1%)。
近年来,Transformer架构对深度学习领域产生了深远影响,尤其在计算机视觉领域。为突破卷积神经网络的局限并获得全局感受野,该架构摒弃传统卷积算子,完全采用注意力机制进行计算。2020年,N. Carion等人提出DETR模型[28],将目标检测视为集合预测问题,构建了基于Transformer的端到端检测网络。至此,目标检测进入无需锚框或锚点的新时代。随后X. Zhu等人提出可变形DETR[43],有效解决了原模型收敛速度慢和小目标检测性能受限的问题,在MSCOCO数据集上取得71.9% COCO mAP@.5的领先性能。
B. 目标检测数据集与评估指标
- 数据集:构建规模更大、偏差更小的数据集对于开发先进检测算法至关重要。过去十年间已发布多个知名检测数据集,包括PASCAL VOC挑战赛数据集[54,55](如VOC2007、VOC2012)、ImageNet大规模视觉识别挑战赛数据集(如ILSVRC2014)[56]、MS-COCO检测挑战赛数据集[57]、Open Images数据集[58,59]、Objects365[60]等。表I列出了这些数据集的统计信息。图4展示了这些数据集的部分图像示例,图3则呈现了2008至2021年间VOC07、VOC12和MS-COCO数据集上检测精度的提升情况。
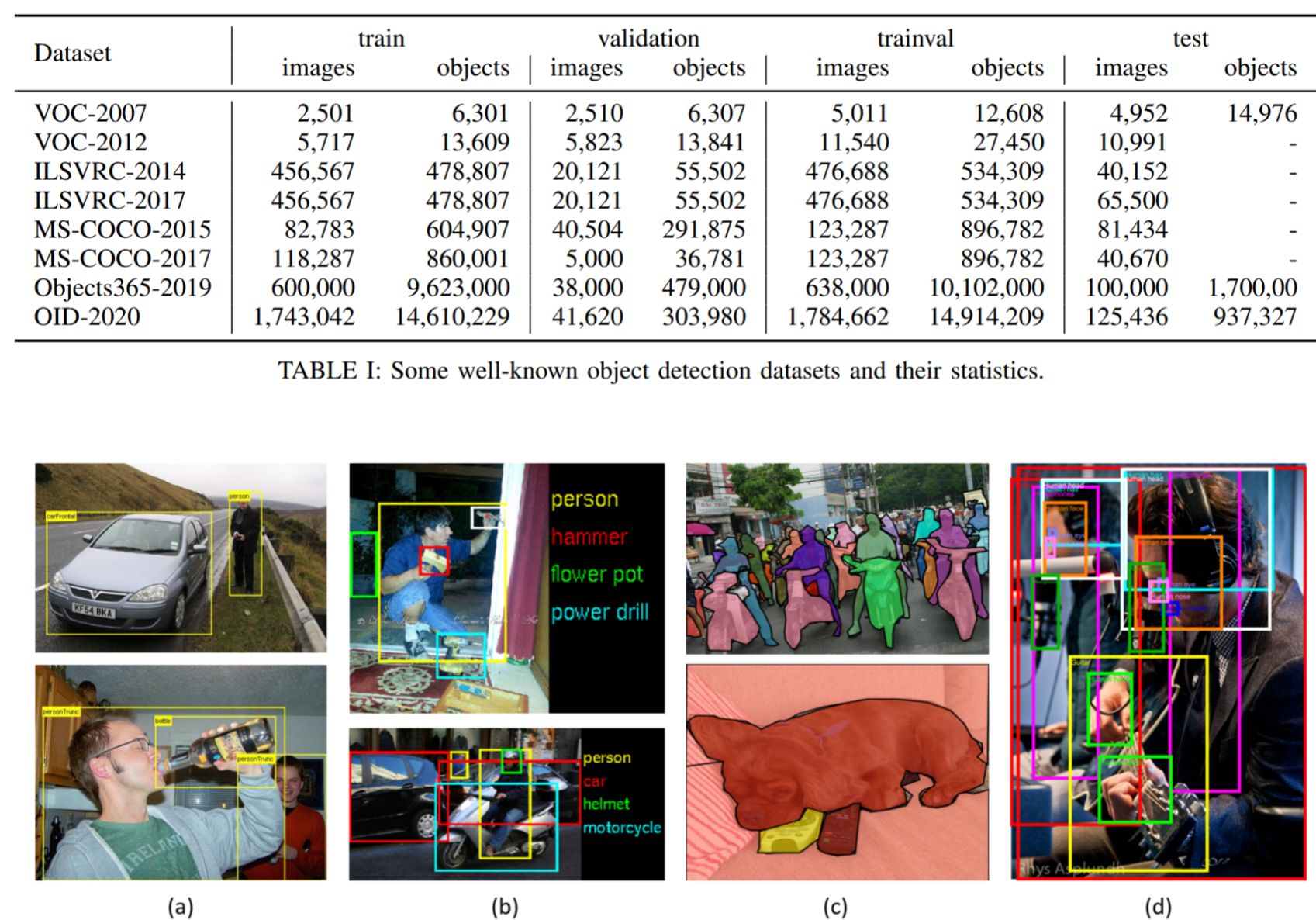
图4:(a) PASCAL-VOC07、(b) ILSVRC、© MS-COCO和(d) Open Images数据集中的示例图像及标注。
PASCAL VOC:PASCAL视觉对象分类挑战赛(2005年至2012年)[54, 55]是早期计算机视觉领域最重要的竞赛之一。目标检测领域最常使用的两个版本是VOC07和VOC12,其中前者包含5千张训练图像和1.2万个标注对象,后者包含1.1万张训练图像和2.7万个标注对象。这两个数据集标注了20类日常生活中常见的物体,例如"人"、“猫”、“自行车”、"沙发"等。
ILSVRC:ImageNet大规模视觉识别挑战赛(ILSVRC)2 [56] 推动了通用物体检测领域的技术发展。该赛事自2010年至2017年每年举办,包含基于ImageNet图像[61]的检测任务。ILSVRC检测数据集涵盖200类视觉对象,其图像/物体实例数量比VOC数据集高两个数量级。
MS-COCO数据集:MS-COCO[57]是当前最具挑战性的目标检测数据集之一。自2015年起,基于该数据集的年度竞赛持续举办。其目标类别数量虽少于ILSVRC,但包含更多目标实例。以MS-COCO-17为例,该数据集包含16.4万张图像、80个类别的89.7万个标注对象。相较于VOC和ILSVRC,MS-COCO的最大进步在于:除边界框标注外,每个对象还通过实例分割标签实现精确定位。此外,该数据集包含更多小目标(面积小于图像1%)和密集分布目标。正如当年ImageNet的地位,MS-COCO已成为目标检测领域事实上的基准数据集。
开放图像数据集:2018年推出的开放图像检测挑战赛(OID)[62]继承了MS-COCO的理念,但达到了前所未有的规模。该数据集包含两项任务:1)标准目标检测;2)视觉关系检测(检测特定关系中的成对物体)。在标准检测任务中,数据集包含191万张图像,涵盖600个物体类别,标注框总数达1544万个。
2)指标:如何评估检测器的准确性?这个问题在不同时期可能有不同的答案。在早期的检测研究中,关于检测准确性的评估指标尚未形成广泛共识。例如,在行人检测的早期研究中[12],普遍采用“漏检率 vs. 每窗口误报数(FPPW)”作为衡量标准。但这种基于窗口的测量方式存在缺陷,无法准确预测完整图像的性能[63]。2009年,Caltech行人检测基准被提出[63,64],此后评估指标从FPPW转变为每图像误报数(FPPI)。
近年来,目标检测领域最常用的评估指标是"平均精度(Average Precision, AP)“,该指标最初由VOC2007竞赛引入。AP被定义为不同召回率下的平均检测精度,通常按类别分别计算。所有类别AP的平均值(即mAP)常被用作最终性能衡量标准。为评估目标定位准确性,系统会计算预测框与真实框的交并比(IoU),并判断该值是否超过预设阈值(如0.5)。若超过阈值则判定为"成功检测”,否则视为"漏检"。基于0.5 IoU阈值的mAP指标由此成为目标检测领域事实上的标准评估方法。
2014年后,随着MS-COCO数据集的引入,研究者们开始更加关注目标定位的精确度。MS-COCO的平均精度(AP)不再采用固定的交并比(IoU)阈值,而是在0.5至0.95之间的多个IoU阈值上取平均值。这种做法促使目标定位更加精准,对于某些实际应用(例如机器人试图抓取扳手的场景)可能具有重要意义。
C. 目标检测的技术演进
在本节中,我们将介绍检测系统中的若干重要构建模块及其技术演进历程。首先阐述模型设计中的多尺度与上下文 priming 机制,随后说明训练过程中的样本选择策略与损失函数设计,最后讨论推理阶段的非极大值抑制技术。图表及文本中的时间标记均采用论文发表时间,图中所示的演进顺序主要为便于读者理解,实际可能存在时间重叠。
多尺度检测的技术演进
- 多尺度检测的技术演进:针对“不同尺寸”和“不同长宽比”目标的多尺度检测是物体检测的主要技术挑战之一。过去20年间,多尺度检测经历了多个历史发展阶段,如图5所示。
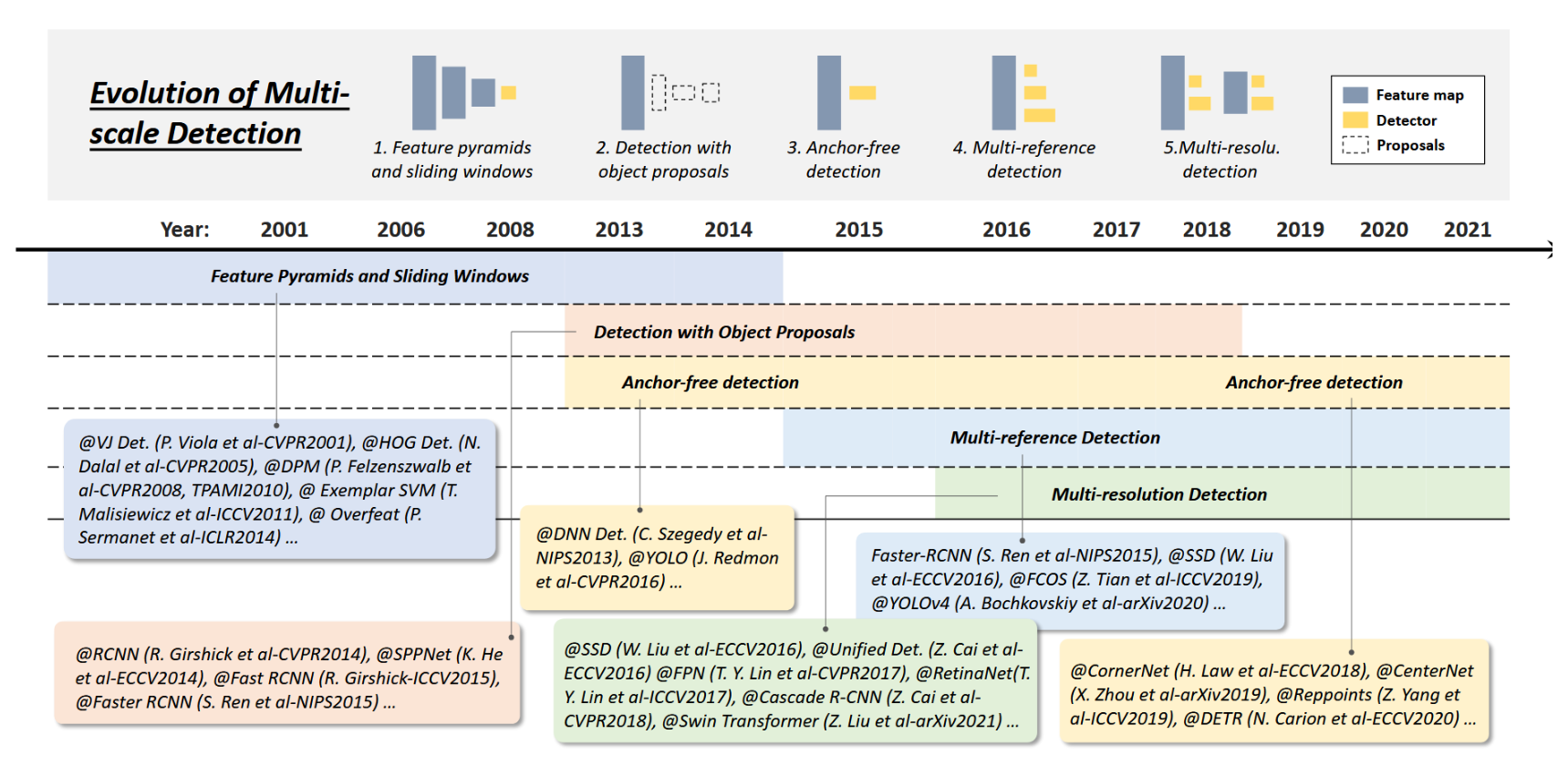
图5:目标检测中多尺度检测技术的演进。本图包含的检测器:VJ检测器[10]、HOG检测器[12]、DPM[13]、Exemplar SVM[32]、Overfeat[65]、RCNN[16]、SPPNet[17]、Fast RCNN[18]、Faster RCNN[19]、DNN检测器[66]、YOLO[20]、SSD[23]、Unified检测器[67]、FPN[24]、RetinaNet[25]、RefineDet[38]、Cascade R-CNN[68]、Swin Transformer[44]、FCOS[41]、YOLOv4[22]、CornerNet[26]、CenterNet[40]、Reppoints[69]、DETR[28]。
特征金字塔+滑动窗口:在VJ检测器之后,研究者们开始关注一种更直观的检测方式,即构建"特征金字塔+滑动窗口"的检测框架。自2004年起,基于这一范式诞生了包括HOG检测器、DPM等在内的一系列里程碑式检测器。这类方法通常采用固定尺寸的检测窗口在图像上滑动,却很少关注"不同长宽比"的问题。为检测外观更复杂的物体,R. Girshick等人开始寻求特征金字塔之外的解决方案。“混合模型”[15]是当时的解决方案之一,即为不同长宽比的物体训练多个检测器。除此之外,基于范例的检测方法[32,70]提供了另一种思路——为每个物体实例(范例)单独训练模型。
基于目标提议的检测方法:目标提议是指一组与类别无关的参考框,这些框可能包含任意目标物体。采用目标提议的检测方法有助于避免对图像进行穷举式的滑动窗口搜索。关于该主题的全面综述,建议读者参阅文献[71, 72]。早期的提议检测方法遵循自下而上的检测理念[73, 74]。2014年后,随着深度卷积神经网络在视觉识别中的普及,基于学习的自上而下方法在该问题上逐渐显现优势[19, 75, 76]。当前,随着单阶段检测器的兴起,提议检测方法已逐渐淡出研究视野。
深度回归与无锚框检测:近年来,随着GPU算力的提升,多尺度检测变得越来越直接且暴力。利用深度回归解决多尺度问题的思路变得简单明了——即直接基于深度学习特征预测边界框坐标[20, 66]。2018年后,研究者开始从关键点检测的角度重新思考目标检测问题。这类方法通常遵循两种思路:一种是基于分组的方法,先检测关键点(角点、中心点或代表点)再进行目标级分组[26, 53, 69, 77];另一种是无分组方法,将目标视为单个/多个参考点,并在这些点的基准上回归目标属性(尺寸、比例等)[40, 41]。
多参考/多分辨率检测:多参考检测是目前最常用的多尺度检测方法[19,22,23,41,47,51]。其核心思想是在图像的每个位置预先定义一组参考(即锚点,包括边界框和点),然后基于这些参考预测检测框。另一种常用技术是多分辨率检测[23,24,44,67,68],即在网络的不同层级检测不同尺度的目标。多参考检测与多分辨率检测已成为现代目标检测系统的两大基础构建模块。
上下文启动的技术演进
2)上下文启动的技术演进:视觉物体通常嵌入在具有周围环境的典型上下文中。人类大脑利用物体与环境之间的关联性来促进视觉感知与认知[96]。长期以来,上下文启动技术一直被用于提升检测效果。图6展示了目标检测中上下文启动技术的演进过程。
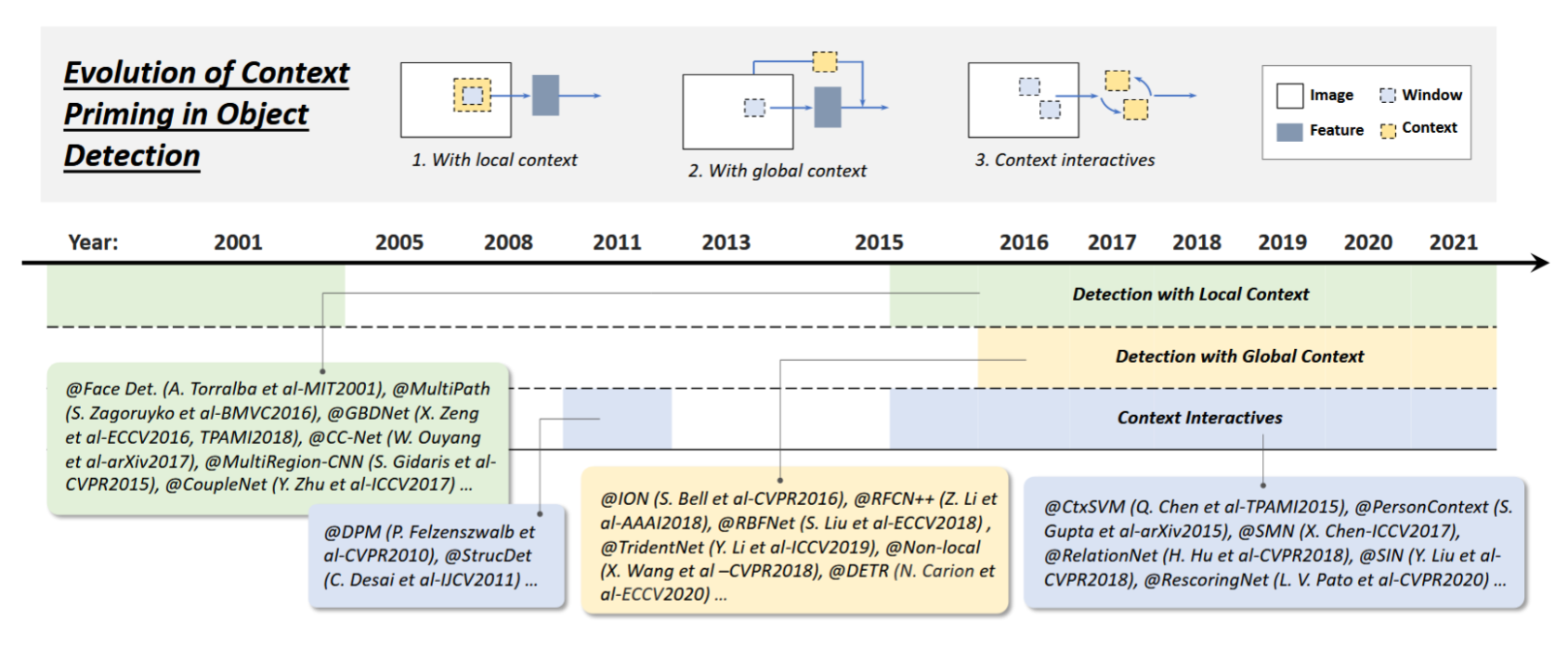
图6:目标检测中上下文启发的演进。本图涉及的检测器包括:人脸检测器[78]、多路径网络[79]、GBDNet[80, 81]、CC-Net[82]、多区域CNN[83]、耦合网络[84]、DPM[14, 15]、结构化检测器[85]、ION[86]、RFCN++[87]、RBFNet[88]、三叉戟网络[39]、非局部网络[89]、DETR[28]、上下文支持向量机[90]、人物上下文模型[91]、SMN[92]、关系网络[93]、SIN[94]、重评分网络[95]。
局部上下文检测:局部上下文指待检测物体周边区域的视觉信息。长期以来,学界公认局部上下文有助于提升物体检测效果。21世纪初,Sinha和Torralba[78]发现引入面部边界轮廓等局部上下文区域能显著提高人脸检测性能;Dalal与Triggs也证实加入少量背景信息可提升行人检测准确率[12]。最新基于深度学习的检测器通过简单扩大网络感受野或目标提议框尺寸,同样能借助局部上下文提升性能[79–84, 97]。
全局上下文检测:全局上下文利用场景配置作为物体检测的额外信息来源。对于早期检测器,整合全局上下文的常见方法是集成场景构成元素的统计摘要,例如Gist[96]。对于现代检测器,主要有两种整合全局上下文的方法。第一种方法是利用深度卷积、空洞卷积、可变形卷积或池化操作[39,87,88]来获取大感受野(甚至大于输入图像)。如今研究者们进一步探索了基于注意力机制(非局部网络、Transformer等)的潜力,通过实现全图像感受野取得了显著成果[28,89]。第二种方法是将全局上下文视为序列信息,通过循环神经网络进行学习[86,98]。
上下文交互:上下文交互指的是视觉元素之间传递的约束与依赖关系。近期研究表明,通过考虑上下文交互可以改进现代检测器的性能。相关改进方法可分为两类:第一类旨在探索个体对象之间的关系[15, 85, 90, 92, 93, 95],第二类则研究对象与场景之间的依赖关系[91, 94]。
难负样本挖掘的技术演进
- 难负样本挖掘的技术演进:检测器的训练本质上是一个不平衡学习问题。对于基于滑动窗口的检测器而言,背景与目标之间的不平衡比例可能高达 1 0 7 : 1 10^7:1 107:1[71]。这种情况下,使用所有背景样本会损害训练效果,因为海量的简单负样本会淹没学习过程。难负样本挖掘(HNM)正是为解决该问题而生,其技术演进路径如图7所示。

图7:目标检测中难负样本挖掘技术的演进。本图涉及的检测器包括:人脸检测[99]、Haar检测[100]、VJ检测[10]、HOG检测[12]、DPM[13,15]、RCNN[16]、SPPNet[17]、Fast RCNN[18]、Faster RCNN[19]、YOLO[20]、SSD[23]、FasterPed[101]、OHEM[102]、RetinaNet[25]、RefineDet[38]、FCOS[41]、YOLOv4[22]。
引导训练:在目标检测中,引导训练指的是一类从少量背景样本开始训练,随后逐步添加误分类样本的迭代训练技术。早期检测器常采用该方法来降低对海量背景数据的计算负担[10, 99, 100]。后来其成为DPM和HOG检测器[12, 13]中解决数据不平衡问题的标准技术。
深度学习检测器中的难样本挖掘:在深度学习时代,由于算力的提升,2014至2016年间目标检测领域曾短暂摒弃了自举法[16–20]。为缓解训练时的数据不平衡问题,Faster RCNN和YOLO等检测器仅简单平衡正负样本窗口的权重。但后续研究发现这无法彻底解决样本失衡问题[25]。为此,2016年后自举法被重新引入目标检测领域[23, 38, 101, 102]。另一种改进方案是设计新型损失函数[25],通过重构标准交叉熵损失,使其更聚焦于难以分类的错误样本[25]。
损失函数的技术演进
4)损失函数的技术演进:损失函数用于衡量模型与数据的匹配程度(即预测结果与真实标签之间的偏差)。通过计算损失可获得模型权重的梯度,随后通过反向传播更新权重以使模型更适配数据。分类损失和定位损失构成了目标检测问题的监督信号,参见公式1。损失函数的通用形式可表述如下:
L ( p , p ∗ , t , t ∗ ) = L c l s . ( p , p ∗ ) + β I ( t ) L l o c . ( t , t ∗ ) I ( t ) = { 1 I o U { a , a ∗ } > η 0 e l s e ( 1 ) \begin{aligned}L(p,p^*,t,t^*)&=L_{cls.}(p,p^*)+\beta I(t)L_{loc.}(t,t^*)\\I(t)&=\begin{cases}1&\mathrm{IoU}\{a,a^*\}>\eta\\0&\mathrm{else}&\end{cases}&\mathrm{(1)}\end{aligned} L(p,p∗,t,t∗)I(t)=Lcls.(p,p∗)+βI(t)Lloc.(t,t∗)={10IoU{a,a∗}>ηelse(1)
其中 t t t和 t ∗ t^* t∗分别表示预测边界框和真实边界框的位置坐标, p p p和 p ∗ p^* p∗表示它们的类别概率。 I o U { a , a ∗ } IoU\{a, a^*\} IoU{a,a∗}是参考框/点 a a a与其真实标注 a ∗ a^* a∗之间的交并比。 η η η表示交并比阈值(例如0.5)。若某个锚框/锚点未匹配到任何目标物体,则其定位损失不计入最终损失函数。
分类损失:分类损失用于评估预测类别与实际类别的偏离程度。在YOLOv1[20]和YOLOv2[51]等早期研究中,该指标未得到充分探讨,这些工作采用MSE/L2损失(均方误差)。后续研究[21,23,47]通常改用交叉熵损失(CE)。L2损失是欧氏空间中的度量,而交叉熵损失能衡量分布差异(称为似然的一种形式)。由于分类预测本质是概率问题,交叉熵损失相比L2损失具有误分类成本更高、梯度消失效应更弱的优势。为提升分类效率,研究者提出标签平滑技术以增强模型泛化能力,解决噪声标签导致的过度自信问题[103,104];针对类别不平衡和分类难度差异问题,则设计了焦点损失(Focal loss)[25]。
定位损失:定位损失用于优化位置和尺寸的偏差。L2损失在早期研究中较为常见[16, 20, 51],但它易受异常值影响且容易出现梯度爆炸。为结合L1损失和L2损失的优点,研究者提出了平滑L1损失[18],其计算公式如下所示,
S m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 e l s e ( 2 ) \mathrm{Smooth}_{L1}(x)=\begin{cases}0.5x^2&\mathrm{if~}|x|<1\\|x|-0.5&\mathrm{else}&\end{cases}\quad(2) SmoothL1(x)={0.5x2∣x∣−0.5if ∣x∣<1else(2)
其中 x x x表示目标值与预测值之间的差异。在计算误差时,上述损失函数将表征边界框的四个数值 ( x 、 y 、 w 、 h ) (x、y、w、h) (x、y、w、h)视为独立变量,然而这些参数之间存在相关性。此外在评估阶段,交并比(IoU)被用于判定预测框是否匹配真实标注框。相同的Smooth L1损失值可能对应完全不同的IoU值,因此研究者提出了如下IoU损失函数[105]:
I o U l o s s = − log ( I o U ) \mathrm{IoU~loss}=-\log(\mathrm{IoU}) IoU loss=−log(IoU)
此后,多种算法对IoU损失函数进行了改进。GIoU(广义交并比)[106]解决了当IoU损失无法优化无重叠边界框(即IoU=0)的情况。根据Distance-IoU[107]的研究,一个成功的检测回归损失应满足三个几何度量指标:重叠面积、中心点距离和宽高比。因此,在IoU损失和GIoU损失的基础上,DIoU(距离交并比)被定义为预测框与真实框中心点之间的距离,而CIoU(完整交并比)[107]则在DIoU的基础上进一步考虑了宽高比差异。
非极大值抑制的技术演进
- 非极大值抑制的技术演进:由于相邻窗口通常具有相似的检测得分,非极大值抑制被用作后处理步骤以去除重复的边界框,从而获得最终检测结果。在目标检测的早期阶段,非极大值抑制并未被普遍集成[121],这主要是因为当时对目标检测系统的预期输出尚未完全明确。图8展示了近20年来非极大值抑制的技术发展历程。
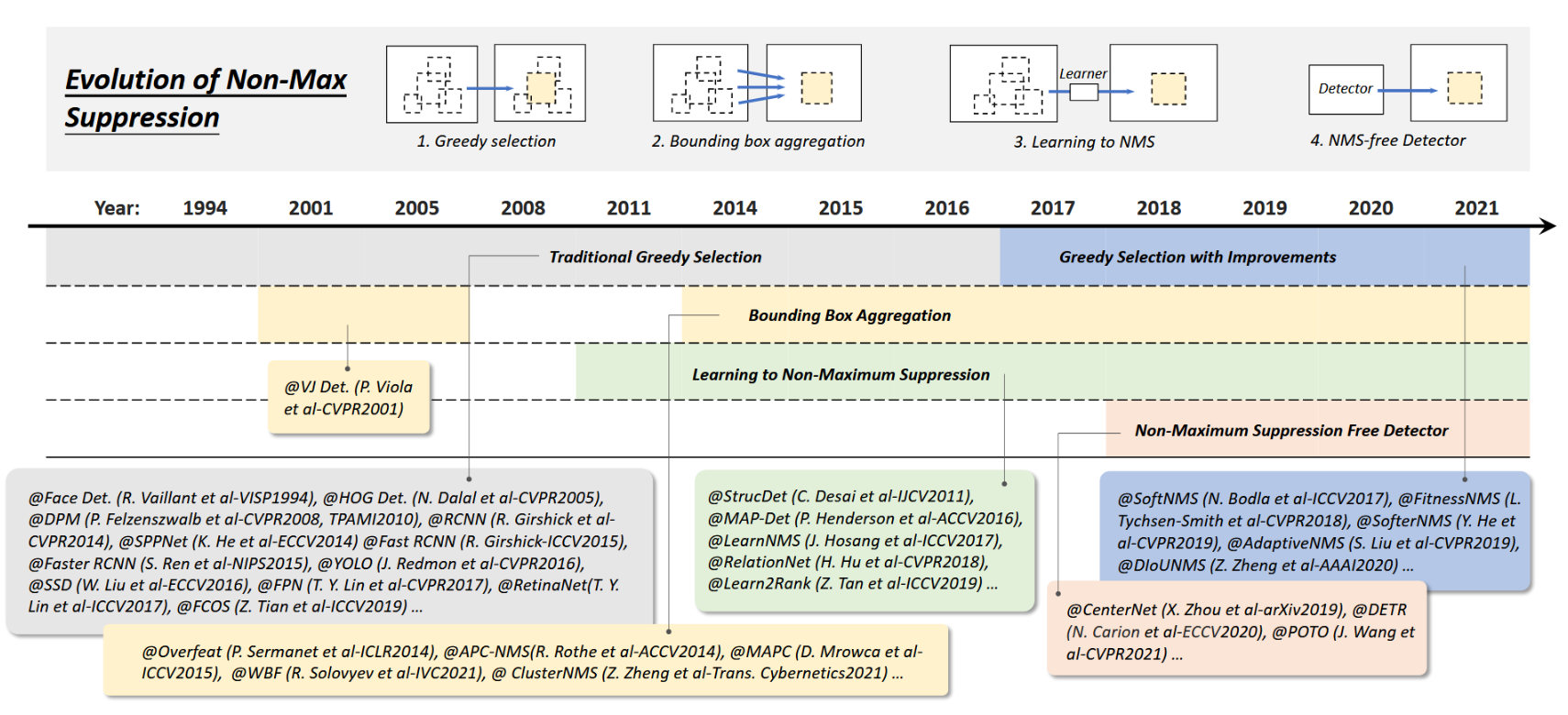
图8:1994至2021年目标检测中非极大值抑制(NMS)技术的演进:1)贪婪选择,2)边界框聚合,3)学习式NMS,4)无NMS检测。本图涉及的检测器包括:人脸检测[108]、HOG检测[12]、DPM[13,15]、RCNN[16]、SPPNet[17]、Fast RCNN[18]、Faster RCNN[19]、YOLO[20]、SSD[23]、FPN[24]、RetinaNet[25]、FCOS[41]、StrucDet[85]、MAP-Det[109]、LearnNMS[110]、RelationNet[93]、Learn2Rank[111]、SoftNMS[112]、FitnessNMS[113]、SofterNMS[114]、AdaptiveNMS[115]、DIoUNMS[107]、Overfeat[65]、APC-NMS[116]、MAPC[117]、WBF[118]、ClusterNMS[119]、CenterNet[40]、DETR[28]、POTO[120]。
贪婪选择法:贪婪选择是一种传统但最流行的非极大值抑制(NMS)实现方式。其核心思想简单直观:对于一组重叠的检测框,选择置信度得分最高的边界框,同时根据预设的重叠阈值移除其相邻框。尽管贪婪选择已成为NMS的事实标准方法,但仍存在改进空间。首先,最高分框未必是最佳匹配框;其次,该方法可能抑制邻近物体;最后,它无法有效抑制误检[116]。针对上述问题,已有大量改进方案被提出[107, 112, 114, 115]。
边界框聚合:BB聚合是另一类非极大值抑制(NMS)技术[10, 65, 116, 117],其核心思想是将多个重叠的边界框合并或聚类成一个最终检测结果。这类方法的优势在于充分考虑了目标间的相互关系及其空间分布[118, 119]。一些著名检测器采用了该方法,例如VJ检测器[10]和Overfeat(ILSVRC-13定位任务冠军)[65]。
基于学习的NMS:近期受到广泛关注的一类NMS改进方法是基于学习的非极大值抑制技术[85, 93, 109–111, 122]。其核心思想是将NMS视为对原始检测结果进行重新评分的过滤器,通过端到端方式将NMS作为网络的一部分进行训练,或训练网络模仿NMS的行为。与传统手工设计的NMS方法相比,这些方法在改善遮挡场景和密集目标检测方面展现出显著优势。
无NMS检测器:为摆脱非极大值抑制(NMS)并实现完全端到端的物体检测训练网络,研究者们开发了一系列方法来完成一对一标签分配(即一个物体仅对应一个预测框)[28,40,120]。这些方法通常遵循一条核心准则:通过选用最高质量的预测框进行训练,从而实现无NMS检测。无NMS检测器更接近人类视觉感知系统,也可能代表着物体检测技术的未来发展方向。
3.检测加速
检测器的加速问题长期以来一直是个挑战。目标检测中的加速技术可分为三个层次:"检测流程"加速、"检测器主干网络"加速以及"数值计算"加速,如图9所示。更详细的版本请参阅文献[123]。
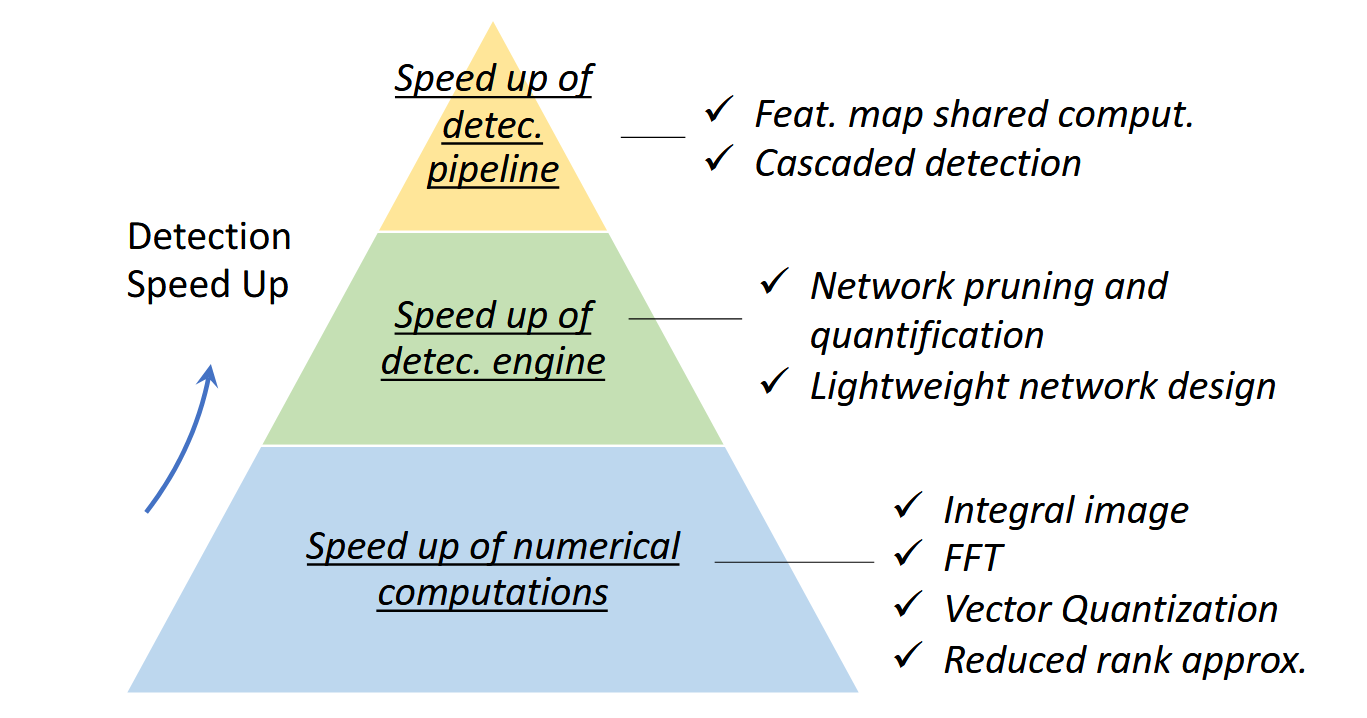
图9:目标检测中的加速技术概览。
A. 特征图共享计算
在检测器的不同计算阶段中,特征提取通常占据了最主要的计算量。当前降低特征计算冗余度最常用的方法是仅对整幅图像计算一次特征图[18, 19, 124],这种方法已实现数十倍甚至上百倍的加速效果。
B. 级联检测
级联检测是一种常用技术[10,125]。其采用由粗到精的检测理念:先通过简单计算过滤掉大部分容易识别的背景窗口,再对少数复杂窗口进行精细处理。近年来,级联检测尤其适用于"大场景中小目标"的检测任务,例如人脸检测[126,127]、行人检测[101,124,128]等。
C. 网络剪枝与量化
“网络剪枝”和“网络量化”是加速CNN模型的两种常用方法。前者指对网络结构或权重进行修剪,后者则是减少其编码长度。“网络剪枝”的研究最早可追溯至20世纪80年代[129]。近期的网络剪枝方法通常采用迭代训练与剪枝的流程,即在每一阶段训练后仅移除少量不重要的权重,并重复这一过程[130]。当前网络量化的研究主要集中在网络二值化,其目标是通过将激活值或权重量化为二元变量(如0/1)来压缩网络,从而将浮点运算转换为逻辑运算。
D. 轻量级网络设计
加速基于CNN的检测器的最后一类方法是直接设计轻量级网络。除“减少通道数、增加层数”等通用设计原则[131]外,近年来还提出了其他一些方法[132–136]。
-
卷积分解:分解卷积是构建轻量级CNN模型最直接的方法。现有方法主要分为两类:第一类是将大卷积核分解为多个小卷积核[50, 87, 137],如图10(b)所示。例如,可将7x7卷积核分解为三个3x3卷积核,两者感受野相同但后者计算效率更高;第二类是在通道维度进行卷积分解[138, 139],如图10©所示。
-
分组卷积:分组卷积旨在通过将特征通道划分为不同组别,并在每组内独立进行卷积运算来减少卷积层的参数量[140, 141],如图10(d)所示。若将特征均匀划分为m组且保持其他配置不变,理论计算量将降至原先的1/m。
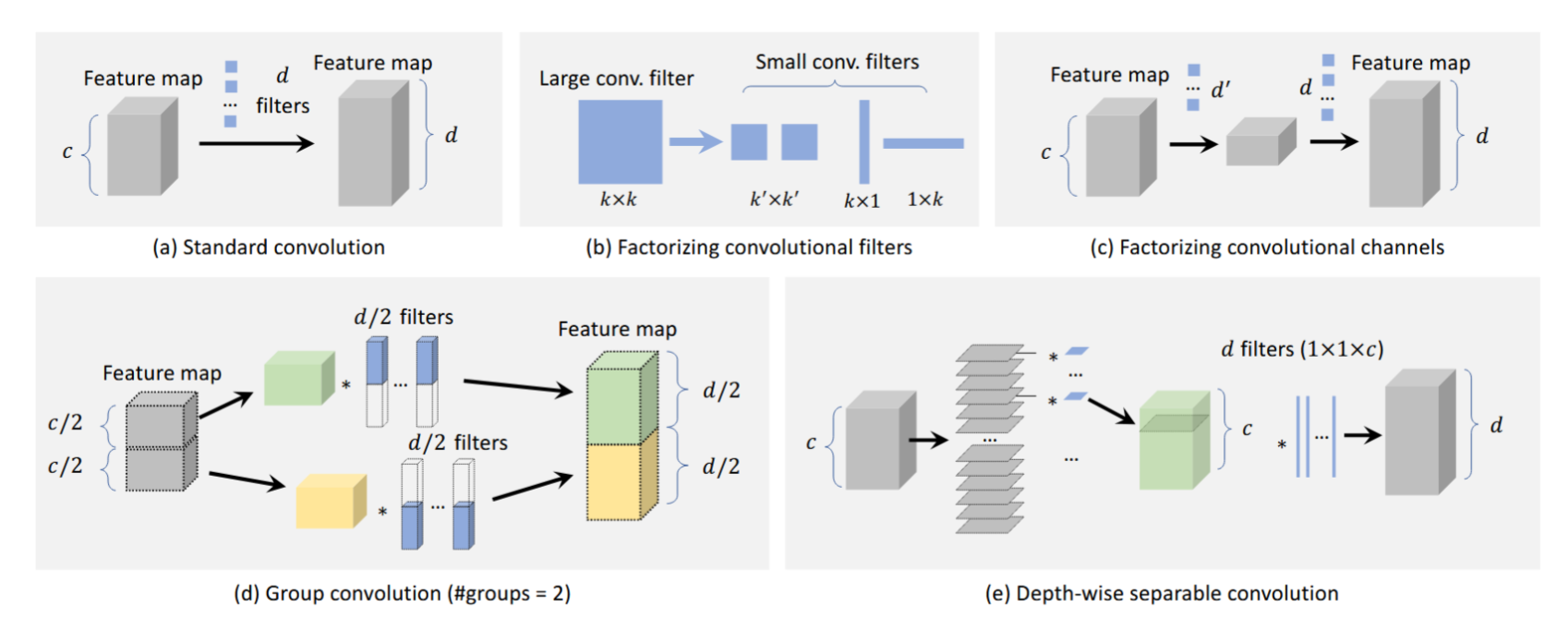
图10:CNN卷积层加速方法概述及其计算复杂度对比:(a) 标准卷积: O ( d k 2 c ) O(dk²c) O(dk2c);(b) 卷积核分解 ( k × k → ( k ′ × k ′ ) 2 (k×k→(k'×k')^2 (k×k→(k′×k′)2或 1 × k 、 k × 1 ): O ( d k 2 c ) 1×k、k×1):O(dk'²c) 1×k、k×1):O(dk2c)或 O ( d k c ) O(dkc) O(dkc);© 通道分解: O ( d ′ k 2 c ) + O ( d k 2 d ′ ) O(d'k²c) + O(dk²d') O(d′k2c)+O(dk2d′);(d) 分组卷积(组数=m): O ( d k 2 c / m ) O(dk²c/m) O(dk2c/m);(e) 深度可分离卷积: O ( c k 2 ) + O ( d c ) O(ck^2) + O(dc) O(ck2)+O(dc)。
-
深度可分离卷积:如图10(e)所示,深度可分离卷积[142]可视为分组卷积的一种特例,其分组数设置为与通道数相等。通常使用若干1x1卷积核进行维度变换,使最终输出具有目标通道数。通过采用深度可分离卷积,计算量可从 O ( d k 2 c ) O(dk²c) O(dk2c)降至 O ( c k 2 ) + O ( d c ) O(ck²)+O(dc) O(ck2)+O(dc)。该技术近期已被应用于目标检测和细粒度分类领域[143–145]。
-
瓶颈设计:神经网络中的瓶颈层节点数量远少于前序层。近年来,瓶颈设计被广泛用于轻量化网络构建[50, 133, 146–148]。这类方法中,检测器的输入层可被压缩以从检测初始阶段就减少计算量[133, 146, 147];也可通过压缩特征图使其变薄,从而加速后续检测过程[50, 148]。
-
基于神经架构搜索的检测:基于深度学习的检测器日益复杂化,其性能高度依赖于人工设计的网络架构与训练参数。神经架构搜索(NAS)的核心任务在于定义合理的候选网络空间、优化快速精准的搜索策略,并以低成本验证搜索结果。在设计检测模型时,NAS能减少人工对网络主干结构和锚框设计的干预需求[149–155]。
E. 数值加速
数值加速旨在从实现底层加速目标检测器。
- 积分图加速法:积分图是图像处理中的重要方法,它能快速计算图像子区域的求和运算。积分图的核心本质源于信号处理中卷积的积分-微分可分离性:
f ( x ) ∗ g ( x ) = ( ∫ f ( x ) d x ) ∗ ( d g ( x ) d x ) , f(x)*g(x)=(\int f(x)dx)*(\frac{dg(x)}{dx}), f(x)∗g(x)=(∫f(x)dx)∗(dxdg(x)),
若 d g ( x ) / d x dg(x)/dx dg(x)/dx为稀疏信号,则根据该等式右侧部分可加速卷积运算[10, 156]。
积分图像还可用于加速目标检测中更通用的特征计算,例如颜色直方图、梯度直方图[124, 157–159]等。典型应用是通过计算积分HOG图来加速HOG特征提取[124, 157],如图11所示。积分HOG图已应用于行人检测领域,在保持精度零损失的前提下实现了数十倍的加速效果[124]。
- 频域加速:卷积是目标检测中一类重要的数值运算。由于线性检测器的检测过程可视为特征图与检测器权重的窗口逐点内积运算,这类操作可通过卷积实现。傅里叶变换是加速卷积运算的实用方法,其理论基础是信号处理中的卷积定理——在适当条件下,两个信号I∗W卷积后的傅里叶变换F,等于它们傅里叶空间中的逐点乘积:
I ∗ W = F − 1 ( F ( I ) ⊙ F ( W ) ) I*W=F^{-1}(F(I)\odot F(W)) I∗W=F−1(F(I)⊙F(W))
其中F表示傅里叶变换, F − 1 F^{-1} F−1表示傅里叶逆变换, ⨀ \bigodot ⨀代表逐点乘积运算。通过采用快速傅里叶变换(FFT)和快速傅里叶逆变换(IFFT)算法[160–163],上述计算过程可获得显著加速。
- 向量量化:向量量化(VQ)是信号处理中的经典量化方法,旨在通过少量原型向量来近似表示大规模数据群的分布。该方法可用于数据压缩以及加速目标检测中的内积运算[164, 165]。
4.目标检测技术的最新进展
过去二十年新技术的不断涌现对目标检测产生了深远影响,但其基本原理和底层逻辑始终未变。前文我们以宏观时间跨度介绍了近二十年的技术演进,帮助读者理解目标检测的发展脉络;本节将聚焦近年来的前沿算法,通过微观时间跨度帮助读者把握技术前沿。其中既有对前文技术路线的延伸拓展(如第IV-A至IV-E节),也有融合多领域概念的全新交叉方向(如第IV-F至IV-H节)。
A. 滑动窗口检测之外
由于图像中的物体可通过其真实标注框的左上角和右下角唯一确定,因此检测任务可等效转化为成对关键点的定位问题。近期一种实现方案是预测角点热力图[26]。其他方法沿袭这一思路,利用更多关键点(角点与中心点[77]、极值点与中心点[53]、代表性点[69])来提升性能。另一种范式将物体视为单点/多点,直接预测物体属性(如高度和宽度)而无需分组。该方法的优势在于可在语义分割框架下实现,且无需设计多尺度锚框。此外,DETR[28,43]通过将目标检测视为集合预测问题,在基于参考的框架中彻底解放了这一任务。
B. 旋转与尺度变化的鲁棒检测
近年来,针对旋转和尺度变化的鲁棒检测研究已取得诸多进展。
-
旋转鲁棒性检测:物体旋转现象在人脸检测、文本检测和遥感目标检测中十分常见。解决该问题最直接的方法是进行数据增强,通过扩充数据分布覆盖所有可能朝向的物体[166],或为不同朝向单独训练独立检测器[167,168]。设计旋转不变损失函数是近年流行方案,通过给检测损失添加约束使旋转物体的特征保持稳定[169–171]。另一新近方案是学习候选物体的几何变换[172–175]。在两阶段检测器中,ROI池化旨在为任意位置和尺寸的候选目标提取固定长度的特征表示。由于特征池化通常在笛卡尔坐标系进行,其对旋转变换不具备不变性。最新改进方案采用极坐标系进行ROI池化,使特征对旋转变化具有鲁棒性[167]。
-
尺度鲁棒性检测:近期研究在训练和检测阶段均针对尺度鲁棒性检测进行了探索。
尺度自适应训练:现代检测器通常会将输入图像调整为固定尺寸,并对所有尺度目标的损失进行反向传播。这种做法的弊端在于会产生"尺度不平衡"问题。在检测阶段构建图像金字塔虽能缓解该问题,但并未从根本上解决[49, 178]。最新改进方案是图像金字塔尺度归一化(SNIP)[176],该方法在训练和检测阶段同时构建图像金字塔,仅对选定尺度的损失进行反向传播,如图12所示。研究者们进一步提出了更高效的训练策略:高效重采样的SNIP(SNIPER)[177],即通过裁剪图像并重采样为若干子区域,从而利用大批量训练的优势。
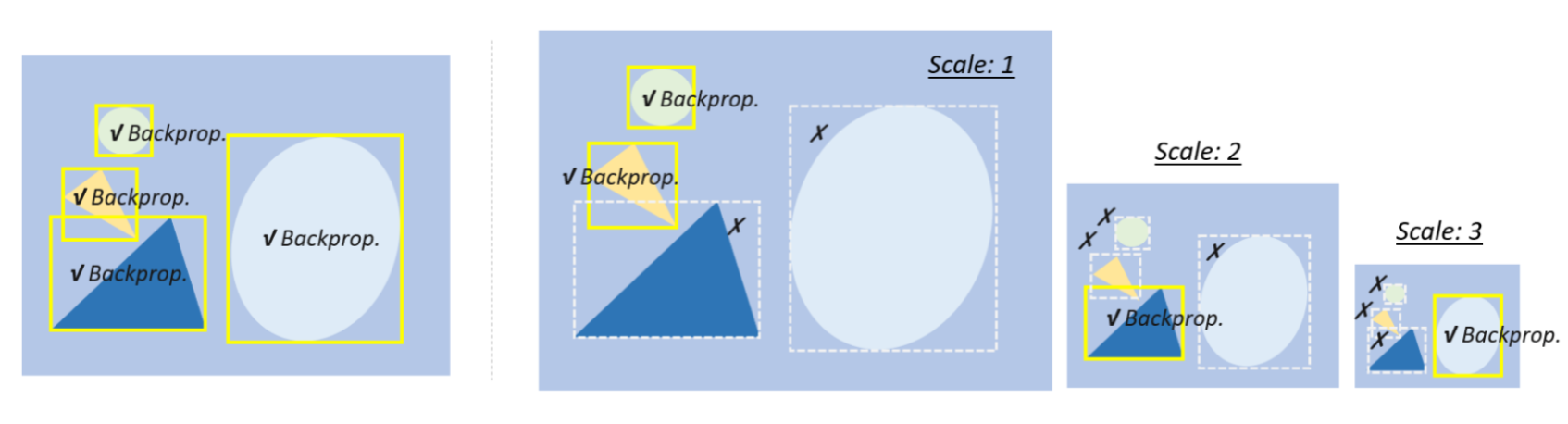
图12:多尺度目标检测的不同训练策略:(a) 在单一分辨率图像上训练,反向传播所有尺度的目标[17–19, 23]。(b) 在多分辨率图像(图像金字塔)上训练,仅反向传播选定尺度的目标。若目标过大或过小,其梯度将被丢弃[39, 176, 177]。
尺度自适应检测:在基于CNN的检测器中,锚框的尺寸和长宽比通常需要精心设计。这种方法的缺点在于配置无法适应意外的尺度变化。为提升小目标检测性能,近期一些检测器提出了"自适应放大"技术,通过将小目标自适应地放大为"较大目标"[179, 180]。另一项最新改进是预测图像中目标的尺度分布,并据此对图像进行自适应重缩放[181, 182]。
C. 基于更优骨干网络的检测
检测器的精度/速度很大程度上取决于特征提取网络(即骨干网络),例如ResNet[178]、CSPNet[183]、Hourglass[184]和Swin Transformer[44]。关于深度学习时代一些重要检测骨干网络的详细介绍,读者可参阅以下综述文献[185]。图13展示了三种知名检测系统(Faster RCNN[19]、RFCN[49]和SSD[23])搭配不同骨干网络时的检测精度对比[186]。目标检测领域近期受益于Transformer强大的特征提取能力——在COCO数据集上,检测性能前十的方法均基于Transformer架构5。Transformer与CNN之间的性能差距正在逐渐拉大。
D. 定位改进
为提高定位精度,当前检测器主要采用两类方法:1) 边界框精细化调整,2) 用于精确定位的新型损失函数。
-
边界框优化:提升定位精度的最直观方法是边界框优化,这可以视为检测结果的后处理。近期的一种方法是迭代地将检测结果输入边界框回归器,直至预测收敛至正确的位置和尺寸[187–189]。然而,也有研究者指出,这种方法无法保证定位精度的单调递增性[187],且多次迭代优化可能导致定位性能退化。
-
精准定位的新损失函数:在多数现代检测器中,目标定位被视为坐标回归问题。然而这种范式的缺陷显而易见:首先,回归损失与定位的最终评估标准不匹配,尤其对长宽比极大的物体;其次,传统边界框回归方法无法提供定位置信度。当多个边界框相互重叠时,可能导致非极大值抑制失败。通过设计新的损失函数可缓解上述问题。最直观的改进是直接采用交并比(IoU)作为定位损失[105–107, 190]。此外,也有研究者在概率推断框架下改进定位[191]——不同于直接预测框坐标的传统方法,该方案通过预测边界框位置的概率分布来实现定位。
E. 基于分割损失的学习
目标检测与语义分割是计算机视觉领域的两大基础任务。最新研究表明,通过结合语义分割损失进行学习,可以提升目标检测的性能。
通过分割提升检测性能的最简单方法,是将分割网络视为固定特征提取器,并将其作为辅助特征整合到检测器中[83, 192, 193]。这种方法的优势在于易于实现,缺点则是分割网络可能带来额外的计算开销。
另一种方法是在原始检测器基础上引入额外的分割分支,并通过多任务损失函数(分割+检测)训练该模型[4, 42, 192]。这种方法的优势在于推理阶段可以移除分割分支,因此检测速度不会受到影响。然而其劣势在于训练过程需要像素级的图像标注数据。
F. 对抗训练
生成对抗网络(GAN)[194]由A. Goodfellow等人于2014年提出,在图像生成[194, 195]、图像风格迁移[196]和图像超分辨率[197]等众多任务中获得了广泛关注。
近来,对抗训练也被应用于目标检测领域,特别是在提升小目标和遮挡目标的检测性能方面。针对小目标检测,生成对抗网络(GAN)可通过缩小小目标与大目标之间的特征差异来增强小目标的特征表征[198, 199]。为改善遮挡目标的检测效果,最新研究提出利用对抗训练生成遮挡掩模的思路[200]。不同于在像素空间生成样本,该对抗网络直接通过修改特征来模拟遮挡效果。
G. 弱监督目标检测
训练基于深度学习的物体检测器通常需要大量人工标注数据。弱监督物体检测(WSOD)旨在通过仅使用图像级标注(而非边界框)来训练检测器,从而减轻对数据标注的依赖[201]。
多示例学习是一组监督学习算法,在弱监督目标检测(WSOD)领域得到了广泛应用[202–209]。与处理单独标注的实例集合不同,多示例学习模型接收的是一组带标签的包,每个包包含多个实例。若将图像中的候选对象视为包、图像级标注视为标签,那么弱监督目标检测就可以被表述为一个多示例学习过程。
类别激活映射是弱监督目标检测领域的另一类新兴方法[210, 211]。关于CNN可视化的研究表明,即便在没有物体位置监督的情况下,卷积神经网络的卷积层仍具有物体检测器的特性。类别激活映射揭示了如何让仅使用图像级标签训练的CNN具备定位能力的内在机制[212]。
除上述方法外,另有研究者将弱监督目标检测(WSOD)视为提案排序过程,通过筛选信息量最丰富的区域,再利用图像级标注对这些区域进行训练[213]。其他学者提出对图像不同区域进行掩蔽处理,若检测分数急剧下降,则被掩蔽区域很可能包含目标物体[214]。近期还有研究将生成对抗训练应用于弱监督目标检测领域[215]。
H. 基于域适应的检测
大多数目标检测器的训练过程本质上可视为独立同分布数据假设下的似然估计过程。面对非独立同分布数据的目标检测(尤其在某些实际应用中)仍具挑战性。除收集更多数据或采用适当数据增强外,域适应提供了缩小域间差距的可能性。为获取域不变特征表示,研究者在图像、类别或物体层面探索了基于特征正则化和对抗训练的方法[216–221]。循环一致性变换[222]也被应用于弥合源域与目标域间的差异[223,224]。另有方法融合上述思路[225]以获得更优性能。
5.结论与未来方向
在过去的20年中,目标检测领域取得了显著成就。本文全面回顾了这20年发展历程中的一些里程碑式检测器、关键技术、加速方法、数据集和评价指标。为帮助读者获得超越上述框架的更深层次见解,未来可能的研究方向包括但不限于以下几个方面。
轻量化目标检测:轻量化目标检测旨在加速检测推理过程,使其能够在低功耗边缘设备上运行。其重要应用场景包括移动增强现实、自动驾驶、智慧城市、智能摄像头、人脸验证等。尽管近年来已取得显著进展,但机器与人类视觉的检测速度差距仍然较大,尤其是在检测微小目标或多源信息检测时[226, 227]。
端到端目标检测:尽管已有方法通过一对一标签分配训练实现了完全端到端(从图像输入到网络直接输出检测框)的物体检测,但大多数研究仍采用一对多标签分配策略,并需额外设计非极大值抑制操作。该领域的未来研究或将聚焦于构建同时保持高检测精度与效率的端到端检测框架[228]。
小目标检测:在大场景中检测小尺寸目标一直是项技术难题。该研究方向的应用潜力包括统计人群密集区域的客流量、露天环境中的动物数量,以及通过卫星图像识别军事目标等。未来可能的发展方向包括融合视觉注意力机制,以及设计高分辨率的轻量化网络架构[229, 230]。
三维物体检测:尽管二维物体检测技术近期取得了进展,但自动驾驶等应用需要获取物体在三维世界中的位置和姿态。未来物体检测技术将更聚焦于三维场景,并充分利用多源多视角数据(例如来自多个传感器的RGB图像和三维激光雷达点云)[231, 232]。
视频中的检测:高清视频的实时目标检测与跟踪对于视频监控和自动驾驶至关重要。传统目标检测器通常针对单帧图像设计,往往忽略了视频帧间的关联性。在计算资源受限的条件下,通过挖掘时空相关性来提升检测性能是一个重要的研究方向[233, 234]。
跨模态检测:利用多种数据源/模态(如RGB-D图像、激光雷达、光流、声音、文本、视频等)进行物体检测,对于构建更精准、类人类感知的检测系统具有重要意义。该领域仍存在若干开放性问题,例如:如何将训练好的检测器迁移至不同模态数据,如何通过信息融合提升检测性能等[235, 236]。
迈向开放世界检测:跨域泛化、零样本检测与增量检测正成为目标检测领域的新兴研究方向。现有方法多致力于缓解灾难性遗忘或利用辅助信息。人类天生具备发现环境中未知类别物体的本能——当获得相应知识(标签)时,人类能从中学习新知识并保持已有认知模式。然而当前目标检测算法难以掌握未知类别物体的检测能力。开放世界目标检测旨在监督信号未明确或部分给定的情况下发现未知类别物体,该技术在机器人、自动驾驶等领域具有广阔应用前景[237, 238]。
站在技术演进的高速公路上,我们相信本文能帮助读者构建完整的物体检测技术路线图,并在这个快速发展的研究领域中探寻未来方向。
6.引用文献
- [1] B. Hariharan, P. Arbela ́ez, R. Girshick, and J. Malik, “Simultaneous detection and segmentation,” in ECCV. Springer, 2014, pp. 297–312.
- [2] ——, “Hypercolumns for object segmentation and finegrained localization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 447–456.
- [3] J. Dai, K. He, and J. Sun, “Instance-aware semantic segmentation via multi-task network cascades,” in CVPR, 2016, pp. 3150–3158.
- [4] K. He, G. Gkioxari, P. Dolla ́r, and R. Girshick, “Mask r-cnn,” in ICCV. IEEE, 2017, pp. 2980–2988.
- [5] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in CVPR, 2015, pp. 3128–3137.
- [6] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in ICML, 2015, pp. 2048–2057.
- [7] Q. Wu, C. Shen, P. Wang, A. Dick, and A. van den Hengel, “Image captioning and visual question an swering based on attributes and external knowledge,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1367–1381, 2018.
- [8] K. Kang, H. Li, J. Yan, X. Zeng, B. Yang, T. Xiao, C. Zhang, Z. Wang, R. Wang, X. Wang et al., “T-cnn: Tubelets with convolutional neural networks for object detection from videos,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 10, pp. 2896–2907, 2018.
- [9] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, p. 436, 2015.
- [10] P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in CVPR, vol. 1. IEEE, 2001, pp. I–I.
- [11] P. Viola and M. J. Jones, “Robust real-time face detection,” International journal of computer vision, vol. 57, no. 2, pp. 137–154, 2004.
- [12] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in CVPR, vol. 1. IEEE, 2005, pp. 886–893.
- [13] P. Felzenszwalb, D. McAllester, and D. Ramanan, “A discriminatively trained, multiscale, deformable part model,” in CVPR. IEEE, 2008, pp. 1–8.
- [14] P. F. Felzenszwalb, R. B. Girshick, and D. McAllester, “Cascade object detection with deformable part models,” in CVPR. IEEE, 2010, pp. 2241–2248.
- [15] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, “Object detection with discriminatively trained part-based models,” IEEE transactions on pattern analysis and machine intelligence, vol. 32, no. 9, pp. 1627–1645, 2010.
- [16] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in CVPR, 2014, pp. 580–587.
- [17] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in ECCV. Springer, 2014, pp. 346–361.
- [18] R. Girshick, “Fast r-cnn,” in ICCV, 2015, pp. 14401448.
- [19] S. Ren, K. He, R. Girshick, and J. Sun, “Faster rcnn: Towards real-time object detection with region proposal networks,” in Advances in neural information processing systems, 2015, pp. 91–99.
- [20] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in CVPR, 2016, pp. 779–788.
- [21] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [22] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [23] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in ECCV. Springer, 2016, pp. 21–37.
- [24] T.-Y. Lin, P. Dolla ́r, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie, “Feature pyramid networks for object detection.” in CVPR, vol. 1, no. 2, 2017, p. 4.
- [25] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dolla ́r, “Focal loss for dense object detection,” IEEE transactions on pattern analysis and machine intelligence, 2018.
- [26] H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 734750.
- [27] Z.-Q. Zhao, P. Zheng, S.-t. Xu, and X. Wu, “Object detection with deep learning: A review,” IEEE transactions on neural networks and learning systems, vol. 30, no. 11, pp. 3212–3232, 2019.
- [28] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European Conference on Computer Vision. Springer, 2020, pp. 213–229.
- [29] D. G. Lowe, “Object recognition from local scaleinvariant features,” in ICCV, vol. 2. Ieee, 1999, pp. 1150–1157.
- [30] ——, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004.
- [31] S. Belongie, J. Malik, and J. Puzicha, “Shape matching and object recognition using shape contexts,” CALIFORNIA UNIV SAN DIEGO LA JOLLA DEPT OF COMPUTER SCIENCE AND ENGINEERING, Tech. Rep., 2002.
- [32] T. Malisiewicz, A. Gupta, and A. A. Efros, “Ensemble of exemplar-svms for object detection and beyond,” in ICCV. IEEE, 2011, pp. 89–96.
- [33] R. B. Girshick, P. F. Felzenszwalb, and D. A. Mcallester, “Object detection with grammar models,” in Advances in Neural Information Processing Systems, 2011, pp. 442–450.
- [34] R. B. Girshick, From rigid templates to grammars: Object detection with structured models. Citeseer, 2012.
- [35] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
- [36] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Region-based convolutional networks for accurate object detection and segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 1, pp. 142–158, 2016.
- [37] M. A. Sadeghi and D. Forsyth, “30hz object detection with dpm v5,” in ECCV. Springer, 2014, pp. 65–79.
- [38] S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li, “Singleshot refinement neural network for object detection,” in CVPR, 2018.
- [39] Y. Li, Y. Chen, N. Wang, and Z. Zhang, “Scale-aware trident networks for object detection,” arXiv preprint arXiv:1901.01892, 2019.
- [40] X. Zhou, D. Wang, and P. Kra ̈henbu ̈hl, “Objects as points,” arXiv preprint arXiv:1904.07850, 2019.
- [41] Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional one-stage object detection,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9627–9636.
- [42] K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang et al., “Hybrid task cascade for instance segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4974–4983.
- [43] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-toend object detection,” arXiv preprint arXiv:2010.04159, 2020.
- [44] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” arXiv preprint arXiv:2103.14030, 2021.
- [45] J. R. Uijlings, K. E. Van De Sande, T. Gevers, and A. W. Smeulders, “Selective search for object recognition,” International journal of computer vision, vol. 104, no. 2, pp. 154–171, 2013.
- [46] R. B. Girshick, P. F. Felzenszwalb, and D. McAllester, “Discriminatively trained deformable part models, release 5,” http://people.cs.uchicago.edu/ rbg/latentrelease5/.
- [47] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 6, pp. 1137–1149, 2017.
- [48] M. D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in ECCV. Springer, 2014, pp. 818–833.
- [49] J. Dai, Y. Li, K. He, and J. Sun, “R-fcn: Object detection via region-based fully convolutional networks,” in Advances in neural information processing systems, 2016, pp. 379–387.
- [50] Z. Li, C. Peng, G. Yu, X. Zhang, Y. Deng, and J. Sun, “Light-head r-cnn: In defense of two-stage object detector,” arXiv preprint arXiv:1711.07264, 2017.
- [51] J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger,” arXiv preprint, 2017.
- [52] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, “Yolov7: Trainable bag-of-freebies sets new state-ofthe-art for real-time object detectors,” arXiv preprint arXiv:2207.02696, 2022.
- [53] X. Zhou, J. Zhuo, and P. Krahenbuhl, “Bottom-up object detection by grouping extreme and center points,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 850–859.
- [54] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” International journal of computer vision, vol. 88, no. 2, pp. 303–338, 2010.
- [55] M. Everingham, S. A. Eslami, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,” International journal of computer vision, vol. 111, no. 1, pp. 98–136, 2015.
- [56] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015.
- [57] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ́ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in ECCV. Springer, 2014, pp. 740–755.
- [58] A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov, T. Duerig, and V. Ferrari, “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,” IJCV, 2020.
- [59] R. Benenson, S. Popov, and V. Ferrari, “Large-scale interactive object segmentation with human annotators,” in CVPR, 2019.
- [60] S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, X. Zhang, J. Li, and J. Sun, “Objects365: A large-scale, highquality dataset for object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8430–8439.
- [61] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in CVPR. Ieee, 2009, pp. 248–255.
- [62] I. Krasin and T. e. a. Duerig, “Openimages: A public dataset for large-scale multi-label and multiclass image classification.” Dataset available from https://storage.googleapis.com/openimages/web/index.html, 2017.
- [63] P. Dolla ́r, C. Wojek, B. Schiele, and P. Perona, “Pedestrian detection: A benchmark,” in CVPR. IEEE, 2009, pp. 304–311.
- [64] P. Dollar, C. Wojek, B. Schiele, and P. Perona, “Pedestrian detection: An evaluation of the state of the art,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 4, pp. 743–761, 2012.
- [65] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun, “Overfeat: Integrated recognition, localization and detection using convolutional networks,” arXiv preprint arXiv:1312.6229, 2013.
- [66] C. Szegedy, A. Toshev, and D. Erhan, “Deep neural networks for object detection,” in Advances in neural information processing systems, 2013, pp. 2553–2561.
- [67] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos, “A unified multi-scale deep convolutional neural network for fast object detection,” in ECCV. Springer, 2016, pp. 354–370.
- [68] Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6154–6162.
- [69] Z. Yang, S. Liu, H. Hu, L. Wang, and S. Lin, “Reppoints: Point set representation for object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9657–9666.
- [70] T. Malisiewicz, Exemplar-based representations for object detection, association and beyond. Carnegie Mellon University, 2011.
- [71] J. Hosang, R. Benenson, P. Dolla ́r, and B. Schiele,“What makes for effective detection proposals?” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 4, pp. 814–830, 2016.
- [72] J. Hosang, R. Benenson, and B. Schiele, “How good are detection proposals, really?” arXiv preprint arXiv:1406.6962, 2014.
- [73] B. Alexe, T. Deselaers, and V. Ferrari, “What is an object?” in CVPR. IEEE, 2010, pp. 73–80.
- [74] ——, “Measuring the objectness of image windows,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 11, pp. 2189–2202, 2012.
- [75] M.-M. Cheng, Z. Zhang, W.-Y. Lin, and P. Torr, “Bing: Binarized normed gradients for objectness estimation at 300fps,” in CVPR, 2014, pp. 3286–3293.
- [76] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, “Scalable object detection using deep neural networks,” in CVPR, 2014, pp. 2147–2154.
- [77] K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and Q. Tian, “Centernet: Keypoint triplets for object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6569–6578.
- [78] A. Torralba and P. Sinha, “Detecting faces in impoverished images,” MASSACHUSETTS INST OF TECH CAMBRIDGE ARTIFICIAL INTELLIGENCE LAB, Tech. Rep., 2001.
- [79] S. Zagoruyko, A. Lerer, T.-Y. Lin, P. O. Pinheiro, S. Gross, S. Chintala, and P. Dolla ́r, “A multipath network for object detection,” arXiv preprint arXiv:1604.02135, 2016.
- [80] X. Zeng, W. Ouyang, B. Yang, J. Yan, and X. Wang, “Gated bi-directional cnn for object detection,” in ECCV. Springer, 2016, pp. 354–369.
- [81] X. Zeng, W. Ouyang, J. Yan, H. Li, T. Xiao, K. Wang, Y. Liu, Y. Zhou, B. Yang, Z. Wang et al., “Crafting gbdnet for object detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 9, pp. 2109–2123, 2018.
- [82] W. Ouyang, K. Wang, X. Zhu, and X. Wang, “Learning chained deep features and classifiers for cascade in object detection,” arXiv preprint arXiv:1702.07054, 2017.
- [83] S. Gidaris and N. Komodakis, “Object detection via a multi-region and semantic segmentation-aware cnn model,” in ICCV, 2015, pp. 1134–1142.
- [84] Y. Zhu, C. Zhao, J. Wang, X. Zhao, Y. Wu, H. Lu et al., “Couplenet: Coupling global structure with local parts for object detection,” in ICCV, vol. 2, 2017.
- [85] C. Desai, D. Ramanan, and C. C. Fowlkes, “Discriminative models for multi-class object layout,” International journal of computer vision, vol. 95, no. 1, pp. 1–12, 2011.
- [86] S. Bell, C. Lawrence Zitnick, K. Bala, and R. Girshick, “Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks,” in CVPR, 2016, pp. 2874–2883.
- [87] Z. Li, Y. Chen, G. Yu, and Y. Deng, “R-fcn++: Towards accurate region-based fully convolutional networks for object detection.” in AAAI, 2018.
- [88] S. Liu, D. Huang et al., “Receptive field block net for accurate and fast object detection,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 385–400.
- [89] X. Wang, R. Girshick, A. Gupta, and K. He, “Nonlocal neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7794–7803.
- [90] Q. Chen, Z. Song, J. Dong, Z. Huang, Y. Hua, and S. Yan, “Contextualizing object detection and classification,” IEEE transactions on pattern analysis and machine intelligence, vol. 37, no. 1, pp. 13–27, 2015.
- [91] S. Gupta, B. Hariharan, and J. Malik, “Exploring person context and local scene context for object detection,” arXiv preprint arXiv:1511.08177, 2015.
- [92] X. Chen and A. Gupta, “Spatial memory for context reasoning in object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 4086–4096.
- [93] H. Hu, J. Gu, Z. Zhang, J. Dai, and Y. Wei, “Relation networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3588–3597.
- [94] Y. Liu, R. Wang, S. Shan, and X. Chen, “Structure inference net: Object detection using scene-level context and instance-level relationships,” in CVPR, 2018, pp. 6985–6994.
- [95] L. V. Pato, R. Negrinho, and P. M. Q. Aguiar, “Seeing without looking: Contextual rescoring of object detections for ap maximization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [96] S. K. Divvala, D. Hoiem, J. H. Hays, A. A. Efros, and M. Hebert, “An empirical study of context in object detection,” in CVPR. IEEE, 2009, pp. 1271–1278.
- [97] C. Chen, M.-Y. Liu, O. Tuzel, and J. Xiao, “R-cnn for small object detection,” in Asian conference on computer vision. Springer, 2016, pp. 214–230.
- [98] J. Li, Y. Wei, X. Liang, J. Dong, T. Xu, J. Feng, and S. Yan, “Attentive contexts for object detection,” IEEE Transactions on Multimedia, vol. 19, no. 5, pp. 944954, 2017.
- [99] H. A. Rowley, S. Baluja, and T. Kanade, “Human face detection in visual scenes,” in Advances in Neural Information Processing Systems, 1996, pp. 875–881.
- [100] C. P. Papageorgiou, M. Oren, and T. Poggio, “A general framework for object detection,” in ICCV. IEEE, 1998, pp. 555–562.
- [101] L. Zhang, L. Lin, X. Liang, and K. He, “Is faster rcnn doing well for pedestrian detection?” in ECCV. Springer, 2016, pp. 443–457.
- [102] A. Shrivastava, A. Gupta, and R. Girshick, “Training region-based object detectors with online hard example mining,” in CVPR, 2016, pp. 761–769.
- [103] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
- [104] R. Mu ̈ller, S. Kornblith, and G. E. Hinton, “When does label smoothing help?” Advances in neural information processing systems, vol. 32, 2019.
- [105] J. Yu, Y. Jiang, Z. Wang, Z. Cao, and T. Huang, “Unitbox: An advanced object detection network,” in Proceedings of the 2016 ACM on Multimedia Conference. ACM, 2016, pp. 516–520.
- [106] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 658–666.
- [107] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, “Distance-iou loss: Faster and better learning for bounding box regression,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12 993–13 000.
- [108] R. Vaillant, C. Monrocq, and Y. Le Cun, “Original approach for the localisation of objects in images,” IEE Proceedings-Vision, Image and Signal Processing, vol. 141, no. 4, pp. 245–250, 1994.
- [109] P. Henderson and V. Ferrari, “End-to-end training of object class detectors for mean average precision,” in Asian Conference on Computer Vision. Springer, 2016, pp. 198–213.
- [110] J. H. Hosang, R. Benenson, and B. Schiele, “Learning non-maximum suppression.” in CVPR, 2017, pp. 64696477.
- [111] Z. Tan, X. Nie, Q. Qian, N. Li, and H. Li, “Learning to rank proposals for object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8273–8281.
- [112] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis, “Soft-nms—improving object detection with one line of code,” in ICCV. IEEE, 2017, pp. 5562–5570.
- [113] L. Tychsen-Smith and L. Petersson, “Improving object localization with fitness nms and bounded iou loss,” arXiv preprint arXiv:1711.00164, 2017.
- [114] Y. He, C. Zhu, J. Wang, M. Savvides, and X. Zhang, “Bounding box regression with uncertainty for accurate object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2888–2897.
- [115] S. Liu, D. Huang, and Y. Wang, “Adaptive nms: Refining pedestrian detection in a crowd,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6459–6468.
- [116] R. Rothe, M. Guillaumin, and L. Van Gool, “Nonmaximum suppression for object detection by passing messages between windows,” in Asian Conference on Computer Vision. Springer, 2014, pp. 290–306.
- [117] D. Mrowca, M. Rohrbach, J. Hoffman, R. Hu, K. Saenko, and T. Darrell, “Spatial semantic regularisation for large scale object detection,” in ICCV, 2015, pp. 2003–2011.
- [118] R. Solovyev, W. Wang, and T. Gabruseva, “Weighted boxes fusion: Ensembling boxes from different object detection models,” Image and Vision Computing, vol. 107, p. 104117, 2021.
- [119] Z. Zheng, P. Wang, D. Ren, W. Liu, R. Ye, Q. Hu, and W. Zuo, “Enhancing geometric factors in model learning and inference for object detection and instance segmentation,” IEEE Transactions on Cybernetics, 2021.
- [120] J. Wang, L. Song, Z. Li, H. Sun, J. Sun, and N. Zheng, “End-to-end object detection with fully convolutional network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 849–15 858.
- [121] C. Papageorgiou and T. Poggio, “A trainable system for object detection,” International journal of computer vision, vol. 38, no. 1, pp. 15–33, 2000.
- [122] L. Wan, D. Eigen, and R. Fergus, “End-to-end integration of a convolution network, deformable parts model and non-maximum suppression,” in CVPR, 2015, pp. 851–859.
- [123] Z. Zou, Z. Shi, Y. Guo, and J. Ye, “Object detection in 20 years: A survey,” arXiv preprint arXiv:1905.05055, 2019.
- [124] Q. Zhu, M.-C. Yeh, K.-T. Cheng, and S. Avidan, “Fast human detection using a cascade of histograms of oriented gradients,” in CVPR, vol. 2. IEEE, 2006, pp. 1491–1498.
- [125] F. Fleuret and D. Geman, “Coarse-to-fine face detection,” International Journal of computer vision, vol. 41, no. 1-2, pp. 85–107, 2001.
- [126] H. Li, Z. Lin, X. Shen, J. Brandt, and G. Hua, “A convolutional neural network cascade for face detection,” in CVPR, 2015, pp. 5325–5334.
- [127] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao, “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE Signal Processing Letters, vol. 23, no. 10, pp. 1499–1503, 2016.
- [128] Z. Cai, M. Saberian, and N. Vasconcelos, “Learning complexity-aware cascades for deep pedestrian detection,” in ICCV, 2015, pp. 3361–3369.
- [129] Y. LeCun, J. S. Denker, and S. A. Solla, “Optimal brain damage,” in Advances in neural information processing systems, 1990, pp. 598–605.
- [130] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
- [131] K. He and J. Sun, “Convolutional neural networks at constrained time cost,” in CVPR, 2015, pp. 5353–5360.
- [132] Z. Qin, Z. Li, Z. Zhang, Y. Bao, G. Yu, Y. Peng, and J. Sun, “Thundernet: Towards real-time generic object detection on mobile devices,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6718–6727.
- [133] R. J. Wang, X. Li, and C. X. Ling, “Pelee: A real-time object detection system on mobile devices,” in Advances in Neural Information Processing Systems 31, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. CesaBianchi, and R. Garnett, Eds. Curran Associates, Inc., 2018, pp. 1967–1976.
- [134] R. Huang, J. Pedoeem, and C. Chen, “Yolo-lite: a real time object detection algorithm optimized for non-gpu computers,” in 2018 IEEE International Conference on Big Data (Big Data). IEEE, 2018, pp. 2503–2510.
- [135] H. Law, Y. Teng, O. Russakovsky, and J. Deng, “Cornernet-lite: Efficient keypoint based object detection,” arXiv preprint arXiv:1904.08900, 2019.
- [136] G. Yu, Q. Chang, W. Lv, C. Xu, C. Cui, W. Ji, Q. Dang, K. Deng, G. Wang, Y. Du et al., “Pp-picodet: A better real-time object detector on mobile devices,” arXiv preprint arXiv:2111.00902, 2021.
- [137] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in CVPR, 2016, pp. 2818–2826.
- [138] X. Zhang, J. Zou, X. Ming, K. He, and J. Sun, “Efficient and accurate approximations of nonlinear convolutional networks,” in CVPR, 2015, pp. 1984–1992.
- [139] X. Zhang, J. Zou, K. He, and J. Sun, “Accelerating very deep convolutional networks for classification and detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 38, no. 10, pp. 1943–1955, 2016.
- [140] X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” 2017.
- [141] G. Huang, S. Liu, L. van der Maaten, and K. Q. Weinberger, “Condensenet: An efficient densenet using learned group convolutions,” group, vol. 3, no. 12, p. 11, 2017.
- [142] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” arXiv preprint, pp. 161002 357, 2017.
- [143] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [144] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in CVPR. IEEE, 2018, pp. 4510–4520.
- [145] Y. Li, J. Li, W. Lin, and J. Li, “Tiny-dsod: Lightweight object detection for resource-restricted usages,” arXiv preprint arXiv:1807.11013, 2018.
- [146] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size,” arXiv preprint arXiv:1602.07360, 2016.
- [147] B. Wu, F. N. Iandola, P. H. Jin, and K. Keutzer, “Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving.” in CVPR Workshops, 2017, pp. 446–454.
- [148] T. Kong, A. Yao, Y. Chen, and F. Sun, “Hypernet: Towards accurate region proposal generation and joint object detection,” in CVPR, 2016, pp. 845–853.
- [149] Y. Chen, T. Yang, X. Zhang, G. Meng, C. Pan, and J. Sun, “Detnas: Neural architecture search on object detection,” arXiv preprint arXiv:1903.10979, 2019.
- [150] H. Xu, L. Yao, W. Zhang, X. Liang, and Z. Li, “Autofpn: Automatic network architecture adaptation for object detection beyond classification,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6649–6658.
- [151] G. Ghiasi, T.-Y. Lin, and Q. V. Le, “Nas-fpn: Learning scalable feature pyramid architecture for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7036–7045.
- [152] J. Guo, K. Han, Y. Wang, C. Zhang, Z. Yang, H. Wu, X. Chen, and C. Xu, “Hit-detector: Hierarchical trinity architecture search for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 405–11 414.
- [153] N. Wang, Y. Gao, H. Chen, P. Wang, Z. Tian, C. Shen, and Y. Zhang, “Nas-fcos: Fast neural architecture search for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 943–11 951.
- [154] L. Yao, H. Xu, W. Zhang, X. Liang, and Z. Li, “Smnas: structural-to-modular neural architecture search for object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12 661–12 668.
- [155] C. Jiang, H. Xu, W. Zhang, X. Liang, and Z. Li, “Sp-nas: Serial-to-parallel backbone search for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 863–11 872.
- [156] P. Simard, L. Bottou, P. Haffner, and Y. LeCun, “Boxlets: a fast convolution algorithm for signal processing and neural networks,” in Advances in Neural Information Processing Systems, 1999, pp. 571–577.
- [157] X. Wang, T. X. Han, and S. Yan, “An hog-lbp human detector with partial occlusion handling,” in ICCV. IEEE, 2009, pp. 32–39.
- [158] F. Porikli, “Integral histogram: A fast way to extract histograms in cartesian spaces,” in CVPR, vol. 1. IEEE, 2005, pp. 829–836.
- [159] P. Doll ́ar, Z. Tu, P. Perona, and S. Belongie, “Integral channel features,” 2009.
- [160] M. Mathieu, M. Henaff, and Y. LeCun, “Fast training of convolutional networks through ffts,” arXiv preprint arXiv:1312.5851, 2013.
- [161] H. Pratt, B. Williams, F. Coenen, and Y. Zheng, “Fcnn: Fourier convolutional neural networks,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2017, pp. 786–798.
- [162] N. Vasilache, J. Johnson, M. Mathieu, S. Chintala, S. Piantino, and Y. LeCun, “Fast convolutional nets with fbfft: A gpu performance evaluation,” arXiv preprint arXiv:1412.7580, 2014.
- [163] O. Rippel, J. Snoek, and R. P. Adams, “Spectral representations for convolutional neural networks,” in Advances in neural information processing systems, 2015, pp. 2449–2457.
- [164] M. A. Sadeghi and D. Forsyth, “Fast template evaluation with vector quantization,” in Advances in neural information processing systems, 2013, pp. 2949–2957.
- [165] I. Kokkinos, “Bounding part scores for rapid detection with deformable part models,” in ECCV. Springer, 2012, pp. 41–50.
- [166] H. Zhu, X. Chen, W. Dai, K. Fu, Q. Ye, and J. Jiao, “Orientation robust object detection in aerial images using deep convolutional neural network,” in ICIP. IEEE, 2015, pp. 3735–3739.
- [167] B. Cai, Z. Jiang, H. Zhang, Y. Yao, and S. Nie, “Online exemplar-based fully convolutional network for aircraft detection in remote sensing images,” IEEE Geoscience and Remote Sensing Letters, no. 99, pp. 1–5, 2018.
- [168] G. Cheng, J. Han, P. Zhou, and L. Guo, “Multiclass geospatial object detection and geographic image classification based on collection of part detectors,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 98, pp. 119–132, 2014.
- [169] G. Cheng, P. Zhou, and J. Han, “Rifd-cnn: Rotationinvariant and fisher discriminative convolutional neural networks for object detection,” in CVPR, 2016, pp. 2884–2893.
- [170] ——, “Learning rotation-invariant convolutional neural networks for object detection in vhr optical remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 54, no. 12, pp. 7405–7415, 2016.
- [171] G. Cheng, J. Han, P. Zhou, and D. Xu, “Learning rotation-invariant and fisher discriminative convolutional neural networks for object detection,” IEEE Transactions on Image Processing, vol. 28, no. 1, pp. 265–278, 2018.
- [172] X. Shi, S. Shan, M. Kan, S. Wu, and X. Chen, “Realtime rotation-invariant face detection with progressive calibration networks,” in CVPR, 2018, pp. 2295–2303.
- [173] M. Jaderberg, K. Simonyan, A. Zisserman et al., “Spatial transformer networks,” in Advances in neural information processing systems, 2015, pp. 2017–2025.
- [174] D. Chen, G. Hua, F. Wen, and J. Sun, “Supervised transformer network for efficient face detection,” in ECCV. Springer, 2016, pp. 122–138.
- [175] J. Ding, N. Xue, Y. Long, G.-S. Xia, and Q. Lu, “Learning roi transformer for oriented object detection in aerial images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2849–2858.
- [176] B. Singh and L. S. Davis, “An analysis of scale invariance in object detection–snip,” in CVPR, 2018, pp. 3578–3587.
- [177] B. Singh, M. Najibi, and L. S. Davis, “Sniper: Efficient multi-scale training,” arXiv preprint arXiv:1805.09300, 2018.
- [178] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
- [179] M. Gao, R. Yu, A. Li, V. I. Morariu, and L. S. Davis, “Dynamic zoom-in network for fast object detection in large images,” in CVPR, 2018.
- [180] Y. Lu, T. Javidi, and S. Lazebnik, “Adaptive object detection using adjacency and zoom prediction,” in CVPR, 2016, pp. 2351–2359.
- [181] S. Qiao, W. Shen, W. Qiu, C. Liu, and A. L. Yuille, “Scalenet: Guiding object proposal generation in supermarkets and beyond.” in ICCV, 2017, pp. 1809–1818.
- [182] Z. Hao, Y. Liu, H. Qin, J. Yan, X. Li, and X. Hu, “Scaleaware face detection,” in CVPR, vol. 3, 2017.
- [183] C.-Y. Wang, H.-Y. M. Liao, Y.-H. Wu, P.-Y. Chen, J.W. Hsieh, and I.-H. Yeh, “Cspnet: A new backbone that can enhance learning capability of cnn,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 390–391.
- [184] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in European conference on computer vision. Springer, 2016, pp. 483–499.
- [185] J. Gu, Z. Wang, J. Kuen, L. Ma, A. Shahroudy, B. Shuai, T. Liu, X. Wang, L. Wang, G. Wang et al., “Recent advances in convolutional neural networks,” arXiv preprint arXiv:1512.07108, 2015.
- [186] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama et al., “Speed/accuracy trade-offs for modern convolutional object detectors,” in CVPR, vol. 4, 2017.
- [187] Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” in CVPR, vol. 1, no. 2, 2018, p. 10.
- [188] R. N. Rajaram, E. Ohn-Bar, and M. M. Trivedi, “Refinenet: Iterative refinement for accurate object localization,” in ITSC. IEEE, 2016, pp. 1528–1533.
- [189] M.-C. Roh and J.-y. Lee, “Refining faster-rcnn for accurate object detection,” in Machine Vision Applications (MVA), 2017 Fifteenth IAPR International Conference on. IEEE, 2017, pp. 514–517.
- [190] B. Jiang, R. Luo, J. Mao, T. Xiao, and Y. Jiang, “Acquisition of localization confidence for accurate object detection,” in Proceedings of the ECCV, Munich, Germany, 2018, pp. 8–14.
- [191] S. Gidaris and N. Komodakis, “Locnet: Improving localization accuracy for object detection,” in CVPR, 2016, pp. 789–798.
- [192] S. Brahmbhatt, H. I. Christensen, and J. Hays, “Stuffnet: Using ‘stuff’to improve object detection,” in Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on. IEEE, 2017, pp. 934–943.
- [193] A. Shrivastava and A. Gupta, “Contextual priming and feedback for faster r-cnn,” in ECCV. Springer, 2016, pp. 330–348.
- [194] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672–2680.
- [195] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint arXiv:1511.06434, 2015.
- [196] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” arXiv preprint, 2017.
- [197] C. Ledig, L. Theis, F. Husza ́r, J. Caballero, A. Cunningham, A. Acosta, A. P. Aitken, A. Tejani, J. Totz, Z. Wang et al., “Photo-realistic single image superresolution using a generative adversarial network.” in CVPR, vol. 2, no. 3, 2017, p. 4.
- [198] J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, and S. Yan, “Perceptual generative adversarial networks for small object detection,” in CVPR, 2017.
- [199] Y. Bai, Y. Zhang, M. Ding, and B. Ghanem, “Sodmtgan: Small object detection via multi-task generative adversarial network,” Computer Vision-ECCV, pp. 8–14, 2018.
- [200] X. Wang, A. Shrivastava, and A. Gupta, “A-fast-rcnn: Hard positive generation via adversary for object detection,” in CVPR, 2017.
- [201] D. Zhang, J. Han, G. Cheng, and M.-H. Yang, “Weakly supervised object localization and detection: A survey,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 9, pp. 5866–5885, 2021.
- [202] T. G. Dietterich, R. H. Lathrop, and T. Lozano-Pe ́rez, “Solving the multiple instance problem with axisparallel rectangles,” Artificial intelligence, vol. 89, no. 1-2, pp. 31–71, 1997.
- [203] S. Andrews, I. Tsochantaridis, and T. Hofmann, “Support vector machines for multiple-instance learning,” in Advances in neural information processing systems, 2003, pp. 577–584.
- [204] R. G. Cinbis, J. Verbeek, and C. Schmid, “Weakly supervised object localization with multi-fold multiple instance learning,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 1, pp. 189203, 2017.
- [205] D. P. Papadopoulos, J. R. Uijlings, F. Keller, and V. Ferrari, “We don’t need no bounding-boxes: Training object class detectors using only human verification,” in CVPR, 2016, pp. 854–863.
- [206] D. Zhang, W. Zeng, J. Yao, and J. Han, “Weakly supervised object detection using proposal-and semanticlevel relationships,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [207] P. Tang, X. Wang, S. Bai, W. Shen, X. Bai, W. Liu, and A. Yuille, “Pcl: Proposal cluster learning for weakly supervised object detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 1, pp. 176–191, 2018.
- [208] E. Sangineto, M. Nabi, D. Culibrk, and N. Sebe, “Self paced deep learning for weakly supervised object detection,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 3, pp. 712–725, 2018.
- [209] D. Zhang, J. Han, L. Zhao, and D. Meng, “Leveraging prior-knowledge for weakly supervised object detection under a collaborative self-paced curriculum learning framework,” International Journal of Computer Vision, vol. 127, no. 4, pp. 363–380, 2019.
- [210] Y. Zhu, Y. Zhou, Q. Ye, Q. Qiu, and J. Jiao, “Soft proposal networks for weakly supervised object localization,” in ICCV, 2017, pp. 1841–1850.
- [211] A. Diba, V. Sharma, A. M. Pazandeh, H. Pirsiavash, and L. Van Gool, “Weakly supervised cascaded convolutional networks.” in CVPR, vol. 1, no. 2, 2017, p. 8.
- [212] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in CVPR, 2016, pp. 2921–2929.
- [213] H. Bilen and A. Vedaldi, “Weakly supervised deep detection networks,” in CVPR, 2016, pp. 2846–2854.
- [214] L. Bazzani, A. Bergamo, D. Anguelov, and L. Torresani, “Self-taught object localization with deep networks,” in Applications of Computer Vision (WACV), 2016 IEEE Winter Conference on. IEEE, 2016, pp. 1–9.
- [215] Y. Shen, R. Ji, S. Zhang, W. Zuo, and Y. Wang, “Generative adversarial learning towards fast weakly supervised detection,” in CVPR, 2018, pp. 5764–5773.
- [216] Y. Chen, W. Li, C. Sakaridis, D. Dai, and L. Van Gool, “Domain adaptive faster r-cnn for object detection in the wild,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3339–3348.
- [217] Y. Wang, R. Zhang, S. Zhang, M. Li, Y. Xia, X. Zhang, and S. Liu, “Domain-specific suppression for adaptive object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9603–9612.
- [218] L. Hou, Y. Zhang, K. Fu, and J. Li, “Informative and consistent correspondence mining for cross-domain weakly supervised object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9929–9938.
- [219] X. Zhu, J. Pang, C. Yang, J. Shi, and D. Lin, “Adapting object detectors via selective cross-domain alignment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 687696.
- [220] K. Saito, Y. Ushiku, T. Harada, and K. Saenko, “Strongweak distribution alignment for adaptive object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6956–6965.
- [221] C.-D. Xu, X.-R. Zhao, X. Jin, and X.-S. Wei, “Exploring categorical regularization for domain adaptive object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 724–11 733.
- [222] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 22232232.
- [223] T. Kim, M. Jeong, S. Kim, S. Choi, and C. Kim, “Diversify and match: A domain adaptive representation learning paradigm for object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12 456–12 465.
- [224] N. Inoue, R. Furuta, T. Yamasaki, and K. Aizawa, “Cross-domain weakly-supervised object detection through progressive domain adaptation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5001–5009.
- [225] H.-K. Hsu, C.-H. Yao, Y.-H. Tsai, W.-C. Hung, H.Y. Tseng, M. Singh, and M.-H. Yang, “Progressive domain adaptation for object detection,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 749–757.
- [226] B. Bosquet, M. Mucientes, and V. M. Brea, “Stdnetst: Spatio-temporal convnet for small object detection,” Pattern Recognition, vol. 116, p. 107929, 2021.
- [227] C. Yang, Z. Huang, and N. Wang, “Querydet: Cascaded sparse query for accelerating high-resolution small object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 668–13 677.
- [228] P. Sun, Y. Jiang, E. Xie, W. Shao, Z. Yuan, C. Wang, and P. Luo, “What makes for end-to-end object detection?” in International Conference on Machine Learning. PMLR, 2021, pp. 9934–9944.
- [229] X. Zhou, X. Xu, W. Liang, Z. Zeng, S. Shimizu, L. T. Yang, and Q. Jin, “Intelligent small object detection for digital twin in smart manufacturing with industrial cyber-physical systems,” IEEE Transactions on Industrial Informatics, vol. 18, no. 2, pp. 1377–1386, 2021.
- [230] G. Cheng, X. Yuan, X. Yao, K. Yan, Q. Zeng, and J. Han, “Towards large-scale small object detection: Survey and benchmarks,” arXiv preprint arXiv:2207.14096, 2022.
- [231] Y. Wang, V. C. Guizilini, T. Zhang, Y. Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” in Conference on Robot Learning. PMLR, 2022, pp. 180–191.
- [232] Y. Wang, T. Ye, L. Cao, W. Huang, F. Sun, F. He, and D. Tao, “Bridged transformer for vision and point cloud 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 114–12 123.
- [233] X. Cheng, H. Xiong, D.-P. Fan, Y. Zhong, M. Harandi, T. Drummond, and Z. Ge, “Implicit motion handling for video camouflaged object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 864–13 873.
- [234] Q. Zhou, X. Li, L. He, Y. Yang, G. Cheng, Y. Tong, L. Ma, and D. Tao, “Transvod: End-to-end video object detection with spatial-temporal transformers,” arXiv preprint arXiv:2201.05047, 2022.
- [235] R. Cong, Q. Lin, C. Zhang, C. Li, X. Cao, Q. Huang, and Y. Zhao, “Cir-net: Cross-modality interaction and refinement for rgb-d salient object detection,” IEEE Transactions on Image Processing, 2022.
- [236] Y. Wang, L. Zhu, S. Huang, T. Hui, X. Li, F. Wang, and S. Liu, “Cross-modality domain adaptation for freespace detection: A simple yet effective baseline,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 4031–4042.
- [237] C. Feng, Y. Zhong, Z. Jie, X. Chu, H. Ren, X. Wei, W. Xie, and L. Ma, “Promptdet: Expand your detector vocabulary with uncurated images,” arXiv preprint arXiv:2203.16513, 2022.
- [238] Y. Zhong, J. Yang, P. Zhang, C. Li, N. Codella, L. H. Li, L. Zhou, X. Dai, L. Yuan, Y. Li et al., “Regionclip: Region-based language-image pretraining,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 793–16 803.


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











